
AMD 助力智利 NLHPC 高效开展科研工作
智利高性能计算国家实验室 (NLHPC) 利用 AMD EPYC(霄龙)CPU 和 AMD Instinct GPU,将性能功耗比提升一倍,高效开展科研工作。


高能效始终是 AMD 在产品设计上的一大核心指导原则,与 AMD 技术发展规划与产品战略深度契合。十余年来,我们坚持制定并公开具有时限性的能效目标,致力于大幅提升各种产品的能效表现,而且始终如期达到甚至超越所制定的目标。
随着 AI 部署规模持续扩展,我们加速设计打造覆盖全面的端到端 AI 系统,这使得对创新型能效解决方案的需求日益增长,而这一需求在数据中心或许更为迫切。
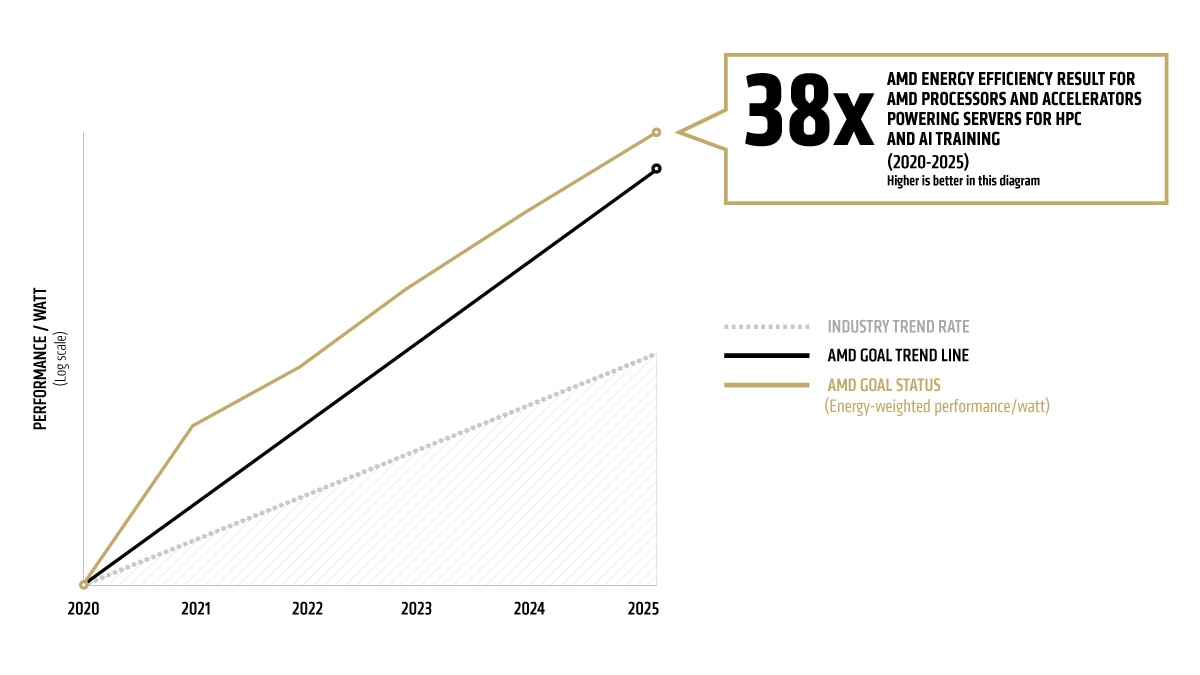
我们的目标是,从 2020 年到 2025 年,将 AMD 处理器和加速器的能效提高 30 倍,全面赋能服务器的 AI 模型训练与高性能计算。1 这些关键且不断发展的计算领域面临着极为严苛的工作负载挑战。根据这些计算领域的全球能源消耗来衡量,这一目标是 2015-2020 年行业能效提升趋势的 2.5 倍以上。2
我们的 30 倍能效提升目标相当于从 2020 年到 2025 年将计算的能耗减少 97%。如果全球所有的 AI 和高性能计算服务器节点都能实现相似的提升,相对于基准趋势,到 2025 年可节省数十亿千瓦时的电力。
截至 2025 年中期,通过采用四个 AMD Instinct MI355X GPU 与一个第五代 AMD EPYC(霄龙)CPU 的配置,我们实现了较基准系统 38 倍3 的性能提升。我们的进度报告采用经过著名计算能效研究专家 Jonathan Koomey 博士验证的权威测量方法2。
随着工作负载的不断扩展与需求的持续攀升,节点级能源效率提升已难以跟上发展步伐。系统级优化才是实现能效显著提升的关键所在。正因如此,我们设定了一个极具突破性的新目标:以 2024 年为基准年,到 2030 年,将 AI 训练与推理场景下的机架级能效提升 20 倍。4
我们坚信,从 2024 年至 2030 年,我们可以成功将 AI 训练与推理场景下的机架级能效提升 20 倍,提升幅度是 2018 至 2025 年行业平均能效提升水平的近 3 倍之多。这一目标基于我们的全新设计与发展规划而设定,体现了整个机架层面的性能功耗比优化,涵盖 CPU、GPU、内存、网络、存储以及软硬件协同设计。这种从节点级到机架级的能效优化跃迁,由我们快速演进的端到端 AI 战略所驱动,现已成为以更可持续的方式推进数据中心 AI 部署扩展的关键所在。
这一 20 倍能效提升目标植根于我们可直接把控的核心要素:硬件与系统级设计。但是我们深知,随着软件开发人员持续探索更智能的算法,并以当前速度推进低精度计算方法创新,在目标周期内,所交付 AI 模型的能源效率有望实现更大幅度的提升,最高可达 5 倍。若将这些因素纳入考量,到 2030 年,训练标准 AI 模型时的整体能效可提升高达 100 倍。5

机架级能效实现 20 倍提升,达到此前行业平均能效提升水平的近 3 倍之多,具有重大意义。以 2025 年典型 AI 模型训练为基准测试场景,预计能够实现以下方面的提升:6
上述预测基于 AMD 芯片与系统设计规划,以及经过能效专家 Jonathan Koomey 博士验证的测量方法。
为了使该目标与全球能源使用量密切相关,AMD 与 Koomey Analytics 合作评估可用的研究和数据,其中包括 GPU 高性能计算 (HPC) 和机器学习 (ML) 等特定领域数据中心能源使用效率 (PUE)。AMD CPU 和 GPU 节点功耗包含特定领域使用(活动与空闲)百分比,并乘以 PUE 来确定实际总能耗,从而能够计算出性能功耗比。
能耗基准采用 2015-2020 年数据中观察到的行业单位作业能耗提升率,并根据这一变化率推测至 2025 年。AMD 目标趋势线(表 1)显示到 2025 年实现能效提升 30 倍目标所需的指数级提升。AMD 实际发布产品(表 2)是表 1 AMD 目标能效提升的来源。
2020 年到 2025 年各领域单位作业能耗提升值是由全球预计销量加权得出(根据 IDC - Q1 2021 TrackerHyperion- Q4 2020 Tracker Hyperion 高性能计算市场分析,2021 年 4 月)。将这些销量换算到机器学习训练和高性能计算市场,会得出如下表 3 所示的节点量。然后将这些节点量乘以 2025 年各计算领域的典型能源消耗 (TEC)(表 4),得出一个有意义的全球实际能源使用提升的总体指标。
表 1:预计到 2025 年的能效数据汇总
|
2020 |
2021 |
2022 |
2023 |
2024 |
2025 |
目标趋势线 |
1.00 |
1.97 |
3.98 |
7.70 |
15.20 |
30.00 |
AMD 目标状态(能耗加权后的性能功耗比) |
1.00 |
3.90 |
6.79 |
13.49 |
28.29 |
37.85 |
表 2:AMD 产品
2020 |
2021 |
2022 |
2023 |
2024 |
2025 |
EPYC(霄龙)第一代 CPU + M50 GPU |
EPYC(霄龙)第二代 CPU + MI100 GPU |
EPYC(霄龙)第三代 CPU + MI250 GPU |
MI300A APU(搭载 AMD CDNA 3 计算单元的第四代 AMD EPYC(霄龙)CPU) |
EPYC(霄龙)第五代 CPU + MI300X GPU |
EPYC(霄龙)第五代 CPU + MI355X GPU |
*AMD 产品受最新软件支持,包括 AMD ROCm。
表 3:预测销量(百万/年)
|
2020 |
2021 |
2022 |
2023 |
2024 |
2025 |
高性能计算 GPU 节点销量 |
0.05 |
0.06 |
0.07 |
0.09 |
0.10 |
0.12 |
机器学习 GPU 节点销量 |
0.09 |
0.10 |
0.12 |
0.14 |
0.17 |
0.20 |
表 4:2025 年基准情景所售产品用电量,用于加权能效指数(TWh/年)
|
2025 |
基准高性能计算 |
4.49 |
基准机器学习 |
29.79 |
总体基准 |
34.28 |
*随着高性能计算和机器学习计算节点的功能不断发展,我们将自 2025 年起,在原有预测的基础上每年更新全球能耗估算数据,同时将 AI 发展给机器学习性能指标带来的权重提升纳入其中。
| FLOPS | HBM 带宽 | 扩展带宽 | |
| 培训 | 70.0% | 10.0% | 20.0% |
| 推理 | 45.0% | 32.5% | 22.5% |
