
概观
凭借与生俱来的灵活性,AMD 自适应 SoC 和 FPGA 器件非常适合用于高性能及多通道数字信号处理 (DSP) 等应用,能够充分发挥硬件并行计算的优势。AMD 自适应 SoC 和 FPGA 提供卓越的处理带宽,更配套完整的解决方案,包括面向硬件设计工程师、软件开发人员和系统架构师的易用型设计工具。
硬件并行性
一个标准 Von Neumann DSP 架构需要 256 个周期才能完成一个 256 个抽头的 FIR 滤波器,而自适应 SoC 和 FPGA 只需要一个时钟周期即可实现同等处理效果。
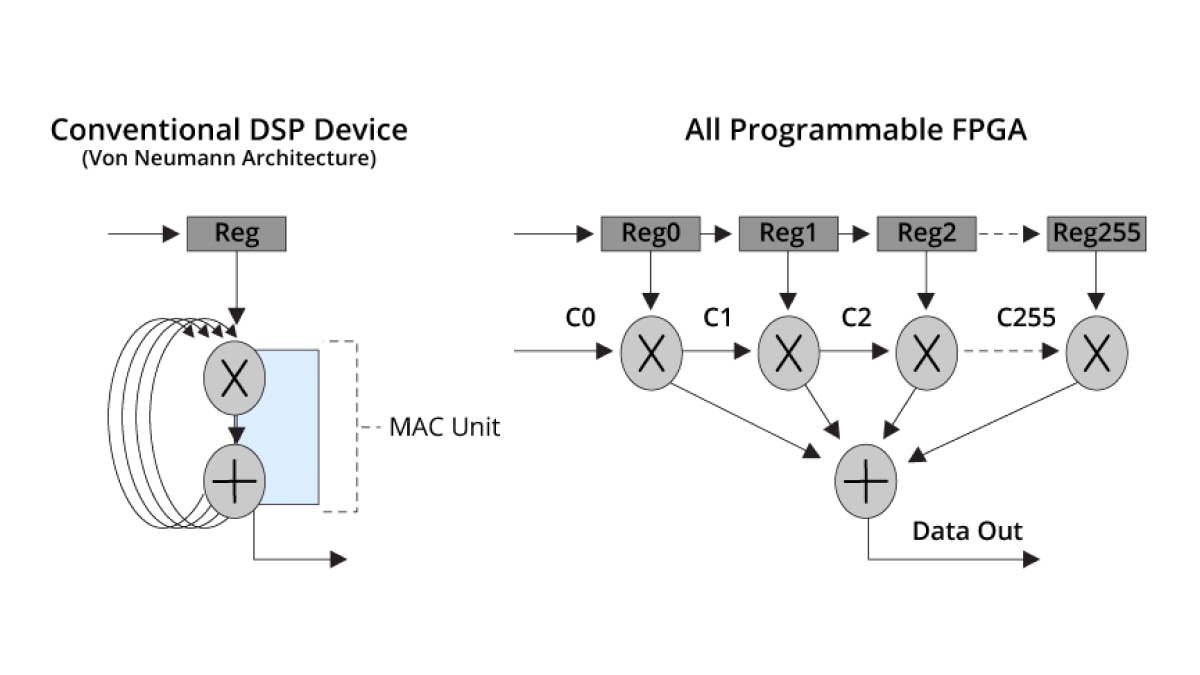
这种高度并行的架构带来了 DSP 性能的突破性提升:
- 49.5 TeraMAC 的定点性能(8 位)
- 单精度浮点的 23.1 万亿次浮点运算
综合 DSP 解决方案
AMD 的 DSP 解决方案涵盖芯片、IP、参考设计、开发板、工具、文档及培训资源,全方位支持无线通信、数据中心等广泛市场领域的多样化应用需求(具体应用场景不限于上述领域)。
综合开发流程
针对不同的应用场景和设计抽象层级,AMD 提供多样化的工具流程支持:
硬件设计人员可进行以下设计:
- 使用 Vivado™ Design Suite 完成 RTL 和系统级设计
- C/C++
- 使用 Vitis™ Model Composer 的 MATLAB® 和 Simulink® 环境
习惯于用 C/C++ 进行开发的软件开发人员可以使用以下工具进行设计:
系统架构师可以使用以下工具快速评估新算法:
- Vitis Model Composer,用于在 MATLAB 或 Simulink 环境中进行系统建模
- Vitis HLS 支持基于 C/C++ 的算法探索与硬件实现
选择您的解决方案
基于 AMD 自适应 SoC 和 FPGA,设计人员可根据具体设计方法和抽象层级,灵活选用多种开发流程部署数字信号处理应用。
Versal AI Engine:满足新一代应用的高性能 DSP 计算需求
在航空航天、汽车/工业及测试测量等诸多快速发展的 DSP 应用市场中,各类应用正不断追求更高性能的 DSP 计算加速,同时仍需保持优异的能效表现。
随着摩尔定律和登纳德缩放比例定律不再遵循其传统发展规律,在仅依靠新一代芯片制程工艺的情况下,已无法像前几代产品一样,以更低的成本实现更出色的性能和能效。
为应对多相信道化、波束成形等新一代 DSP 应用的非线性需求增长,AMD 基于 Versal™ 自适应计算架构,创新性开发了 AI Engine 处理技术。
详细了解 Versal AI Engine:
AI 引擎架构
AI 引擎采用模块化二维阵列架构,由多个 AI 引擎计算单元组成,可在 Versal 产品组合中实现高度可扩展的解决方案,单个器件可集成数十至上百个 AI 引擎,全面满足各类应用场景的计算需求。
它具有如下优势:
软件可编程
- 可通过 Vitis 统一软件平台进行 C 编程
- 通过 Vitis Model Composer 进行基于模型的编程
- 了解有关 AI 引擎 DSP 设计流程的更多信息
确定性
- 专用指令及数据存储器
- 采用专用互连通道与 DMA 引擎协同工作,通过 AI 引擎阵列单元间的定向连接实现可编程数据调度传输
效率
- 与传统的可编程逻辑相比,提供更高的 DSP 计算密度,同时降低动态功耗。如需了解更多信息,请单击此处。
AMD 自适应 SoC 和 FPGA 基于 ASIC 级架构,在 Versal™ Premium 系列中实现了数百 Gb/s 级 I/O 带宽与超过 49 TeraMAC 定点 DSP 性能的卓越组合。在最新一代 AMD FPGA 中,AMD DSP 切片及其并行性是实现 DSP 性能的关键。
DSP 切片架构
Versal 器件中的 DSP58 切片是 AMD 架构中的第 6 代 DSP 切片。
该专用 DSP 处理模块采用全定制芯片技术,能够提供卓越的功耗/性能表现,从而高效地实现乘累加器 (MACC)、乘加器 (MADD) 或复数乘法等常用 DSP 功能。
此外,切片也可提供执行各种逻辑运算(如 AND、OR 和 XOR 运算)的功能。
Versal 器件 DSP58 架构在 UltraScale™ FPGA DSP48E2 的成功基础上进行了全面升级,主要增强特性包括:
- 更宽的乘法器(27 x 24 位)
- 单精度浮点乘法器
- 18x18 复数乘法使用两个背靠背的 DSP
- INT8 矢量点积模式
这些增强功能有助于 DSP 关键应用在进入 FPGA 逻辑结构之前,于 DSP48E2 切片内完成更多计算,从而显著节省资源并降低功耗。
DSP48E2 (UltraScale) 与 DSP58 (Versal) 切片功能对比
| 功能 | UltraScale | Versal |
|---|---|---|
| DSP 模块/切片类型 | DSP48E2 | DSP58 |
| 多重 Add/Sub/Acc 运算 |  |
|
| 乘法器和 MACC | 27x18 | 27x24 |
| 平方: [(A or B) +/- D]2 | |
|
| WMUX 反馈超高效复数乘法 CMACC | 3 x DSP48E2 | 2 x DSP58 |
| SIMD 支持 | |
|
| 集成型模式检测电路 | |
|
| 集成型逻辑单元 | |
|
| 宽多路复用器功能 | 48 位 | 58 位 |
| 宽 XOR | 96 位 | 116 位 |
| 单精度浮点乘法器 | |
|
| 可选 96 位输出 | |
|
| 级联布线 | |
|
| 流水线寄存器 | |
|
| D 预加法器 | |
|
| 连续复数乘法,AB 动态访问 | |
|
| 改进的 AB 寄存器流水线平衡 | |
|
精选视频:
工具与流程
针对不同开发者的设计偏好,AMD 提供全面支持 RTL、C/C++ 语言以及基于模型设计流程的开发工具。这种灵活的设计流程,配合丰富的 DSP IP 核资源库,显著降低了开发者采用 AMD 工具与器件的技术门槛。
有关更多信息,请访问工具、库和框架。
DSP 性能指标
下表是 7 系列、UltraScale™ 和 UltraScale+™ 系列的部分重要 DSP 性能指标。如需了解 SoC 器件性能,敬请查看“软件开发人员”部分。
| Kintex UltraScale | Kintex UltraScale+ | Virtex UltraScale | Virtex UltraScale+ | Versal AI Core | Versal AI Edge | Versal AI Prime | Versal AI Premium | |
|---|---|---|---|---|---|---|---|---|
| 系统逻辑单元 (K) | 318–1,451 | 356–1,143 | 783–5,541 | 862–3,780 | 540 - 1,968 | 44 - 1,139 | 329 - 2,233 | 833 - 7,352 |
| DSP Slice | 768–5,520 | 1,368–3,528 | 600–2,880 | 2,280–12,288 | 928 - 1,968 | 90 - 1,312 | 464 - 3,984 | 1,140 - 14,352 |
| 27x18 乘法器 | 768–5,520 | 1,368–3,528 | 600–2,880 | 2,280–12,288 | 928 - 1,968 | 90 - 1,312 | 464 - 3,984 | 1,140 - 14,352 |
| INT8 GOPs1 | 1,774–14,315 | 4,263–11,000 | 1,554–7,469 | 7,108–38,318 | 6,403 - 13,579 | 62 - 9,052 | 3,201 - 27,489 | 7,866 - 99,029 |
| INT16 GOP | 1,014–8,180 | 2,436–6,286 | 888–4,268 | 4,062–21,896 | 2,134 - 4,526 | 21 - 3,017 | 1,067 - 9,163 | 2,622 - 33,010 |
| 复杂的 INT18 GOP | 676 - 5,453 | 1,624 - 4,191 | 592 - 2,845 | 2708 - 14,597 | 913 - 1,937 | 8 - 1,291 | 456 - 3,920 | 1,122 - 14,122 |
| 单一精度浮点 (GFLOPs)2 | 320–2,685 | 800–1,673 | 294–1,411 | 1,354–7,299 | 1,494 - 3,168 | 14 - 2112 | 747 - 6,414 | 1,835 - 23,107 |
我们提供了完善的软件开发环境,以及一系列强大易用的工具、库和方法论,使软件开发人员能够轻松针对 AMD 自适应 SoC 和 FPGA 进行开发。采用高级抽象环境 Vitis™ 统一软件平台。我们可针对 C、C++ 和/或 OpenCL 开发提供类似于 GPU 的熟悉的嵌入式应用开发及运行时体验。
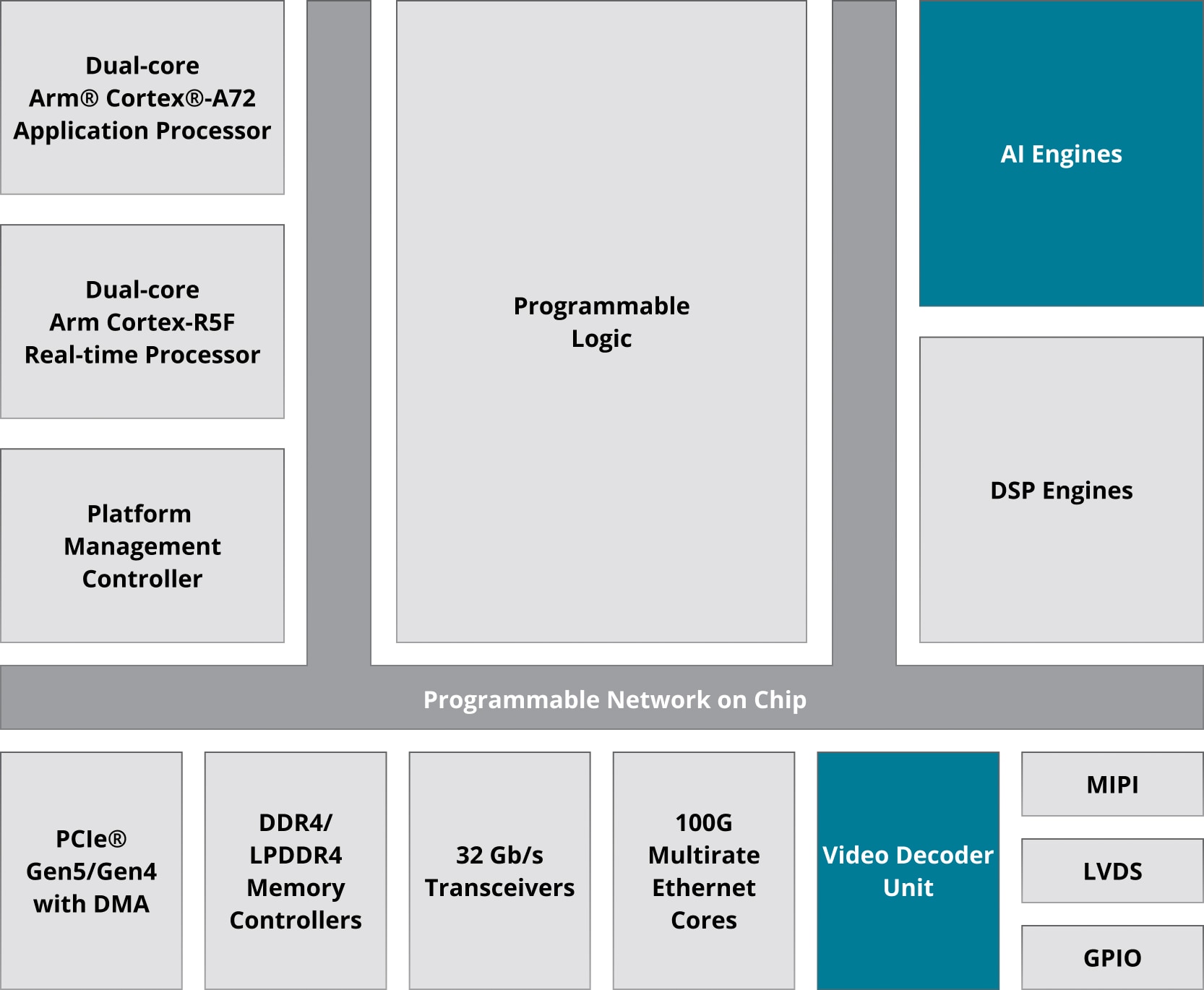
AMD MPSoC 和 Versal 器件
Zynq™ UltraScale+™ MPSoC 和 Versal 架构将强大的处理系统 (PS) 集成于单个器件中,其中融入 Arm® Cortex® 处理器和用户可编程逻辑 (PL)。
支持加速的应用剖析
Vitis 统一软件平台提供应用性能分析功能,并支持创建硬件加速器在可编程逻辑 (PL) 中高效运行,通过充分利用 FPGA 的灵活性与并行计算特性,可实现大幅性能提升。此外,还可实现其他应用功能在必要时在处理系统 (PS) 中并行运行。
通过采用 AMD 自适应 SoC 和 FPGA 方案,各类 DSP 及嵌入式应用将显著提升能效表现并降低系统功耗。
AMD SoC 器件的特性和 DSP 性能
下表是 AMD Zynq UltraScale+ MPSoC 系列和 Versal™ 器件的部分重要特性及 DSP 性能指标。如欲了解非 SoC 器件性能,敬请访问“硬件设计人员”部分。
| 处理系统 | Zynq 7000 SoC | Zynq UltraScale+ MPSoC |
|---|---|---|
| 应用 处理单元 (APU) |
|
|
| 实时 处理单元 (RPU) |
- |
|
| 多媒体处理 | - |
|
| 动态内存接口 | DDR3、DDR3L、DDR2、LPDDR2 | DDR4、LPDDR4、DDR3、DDR3L、LPDDR3 |
| 高速外设 | USB 2.0、千兆以太网、SD/SDIO | PCIe® Gen2、USB3.0、SATA 3.1、DisplayPort、千兆以太网、SD/SDIO |
| 安全性 | RSA、AES 和 SHA、ARM TrustZone® | RSA、AES 和 SHA、ARM TrustZone |
| I/O 引脚数上限 | 128 | 214 |
| 可编程逻辑 | Zynq 7000 SoC | Zynq UltraScale+ MPSoC |
|---|---|---|
| 系统逻辑单元 (K) | 23–444 | 103–1,045 |
| 最大存储器 (Mb) | 1.8–26.5 | 5.3–70.6 |
| I/O 引脚数上限 | 100–362 | 252–668 |
| DSP Slice | 60–2,020 | 240–3,528 |
| 18x18 乘法器 | 60–2,020 | 240–3,528 |
| 定点性能 (GMAC) (1) | 42–1,313 | 213–3,143 |
| 对称滤波器 (GMAC) 的定点性能 (1) (2) | 84–2,626 | 426–6,286 |
| INT8 GOP (1) (3) | 84–2,626 | 745–11,000 |
| INT16 GOP (1) | 84–2,626 | 426–6,286 |
| 单精度浮点 (GFLOPs) (1) (4) | 23–716 | 142–1,673 |
| 单精度浮点 (GFLOPs) (1) (5) | 17–537 | 106–1,571 |
| 半精度浮点 (GFLOPs) (1) (6) | 34–1,074 | 212–3,142 |
注意:
- 所有性能计算均基于以下器件速度等级标准:Zynq 7000 自适应 SoC 采用 -2 速度等级器件,Zynq UltraScale+ MPSoC 采用 -3 速度等级器件
- 为对称滤波器使用预加法器,DSP 性能可提高 2 倍
- 请参阅 WP486 – 利用 AMD 器件的 INT8 优化开展深度学习(不适用于 Zynq 器件)
- 利用 3 个 DSP 切片的 Floating Point Operator 核实现的单精度浮点性能
- 利用 4 个 DSP 切片的 Floating Point Operator 核实现的单精度浮点性能
- 利用 2 个 DSP 切片的 Floating Point Operator 核实现的半精度浮点性能
如欲了解有关 AMD 自适应 SoC 及 MPSoC 的更多详情,敬请访问:
处理子系统中的 DSP
该处理系统 (PS) 可通过不同的 ARM 处理内核提供各种 DSP 处理能力。
如欲进一步了解 ARM 处理器的 DSP 能力,敬请访问:
- Cortex-A 系列
- SIMD 和高级 SIMD (NEON) 技术
- ARM 浮点架构
可在以下位置查看一些实用示例:
对于 Zynq UltraScale+ MPSoC,请参阅 UG1211,了解使用 ARM NEON 指令集的 FFT 演示。
针对 Zynq 7000 SoC 的 Cortex-A9 处理器及 ARM SIMD 指令集优化,Xilinx wiki 提供以下实用技术指南:
AMD 数据类型支持
AMD 为其器件提供极其灵活的数据类型支持。AMD 开发工具原生支持多种精度格式的数据处理,包括定点数、浮点数和整数运算,其中浮点运算通过 Floating Point Operator IP 核实现。
在 FPGA 上实现浮点运算设计相较于定点或整数运算总会带来更高的资源占用和功耗开销。如果可能,转化为定点解决方案将带来巨大的优势:
- 更少的 FPGA 资源
- 更低的功耗
- 更低的成本
如需详细了解从浮点数据类型转换为定点数据类型的优势,请参阅 WP491。
基准测试
以下表格展示了部分典型算法在采用 AMD 器件(特别是其可编程逻辑单元 PL 进行硬件加速)后可能获得的性能提升。
| 算法 | CPU/GPU | Zynq UltraScale+ MPSoC | 优势 |
|---|---|---|---|
| Stereo LocalBM @ 2K | ARM:每瓦 0.5FPS nVidia:每瓦 3.5FPS |
每瓦 146FPS | 292x 42x |
| 光流 (Lucas-Kanade) |
ARM:每瓦 0.1FPS nVidia:每瓦 0.8FPS |
每瓦 7.1FPS | 9.3x |
| GoogleNet (Batch=1) |
ARM:0.1Imgs/s/w nVidia:8.8Imgs/s/w |
53Imgs/s/w | 530x 6x |
注意:
- ARM:四核 A53 在 Raspberry Pi @ 1200MHz 上运行
- Nvidia 基准测试是使用 Tegra X1 完成的
- 光流 (LK) – 窗口尺寸 11x1
| 算法 | CPU/DSP | Zynq 7000 | 优势 |
|---|---|---|---|
| 正向投影 | ARM:每帧 3 秒 | 每帧 0.016 秒 | 188x |
| 运动检测 | ARM:0.7 帧每秒 (FPS) | 67 帧每秒 (FPS) | 90x |
| 降噪 - Sobel | ARM:1 帧每秒 (FPS) | 67 帧每秒 (FPS) | 60x |
| Canny 边缘检测 | ARM:0.66 帧每秒 (FPS) | 40 帧每秒 (FPS) | 45x |
| 3D 图像重建 | ARM:75k | 8k | 9x |
| DPD | ARM:506ms | 31.3ms | 16x |
| FIR | TI DSP:64020ns | 1200ns | 53x |
| FFT | TI DSP:1036ns | 128ns | 8x |
注意:
- 在面向 ARM 开发时,Cortex-A9 核心仅被用于 Zynq 器件
- TI 基准测试是使用 C66 DSP 核心完成的
AMD 高端设计工具(如面向 DSP 的 Vitis Model Composer 及高层次综合工具)通过提升设计抽象层级,赋能系统架构师与领域专家快速验证新算法,并专注于核心差异化设计。完整的 AMD DSP 解决方案集成了设计工具、IP、参考设计、开发方法论及硬件评估板等要素,协同实现从概念到量产的最短路径。
其中,Vitis Model Composer 作为基于模型的设计工具,依托 MATLAB 和 Simulink 环境实现专业级 DSP 算法的定义、验证及硬件实现,其开发效率较传统 RTL 方法提升显著。
该工具提供:
- 100 余个经过优化的 DSP 块,其中多数配备 C 语言仿真模型,相较于 RTL 可实现 2 至 3 倍的加速效果
- DSP 系统实现 RTL、IP、Simulink、MATLAB 及 C/C++ 组件的全栈集成
- 比特级与周期级精确的浮点/定点混合仿真能力
- 硬件协同仿真,可加速仿真并在实际硬件上验证算法
- 从 Simulink 到可综合 IP 或底层 HDL 的自动生成能力
- 自动生成 HDL 测试激励文件,包括测试矢量
了解有关 Vivado System Generator for DSP 的更多详情:
高层次综合
高层次综合(包括 Vitis 统一软件平台)支持将 C/C++ 和 System C 算法描述直接部署至 AMD FPGA 及自适应 SoC,无需手动编写 RTL 代码。正如 C/C++ 编译器可针对不同处理器架构生成代码一样,HLS 编译器同样实现了从 C/C++ 到 AMD FPGA 及自适应 SoC 的代码转换功能。
了解有关 Vivado 高层次综合的更多信息:
- Vitis 高层次综合入门(视频)
- Vitis 高层次综合用户指南(文档)
工具与生态系统
AMD 提供业界领先的工具,助力开发者在 AMD 自适应 SoC 和 FPGA 平台上高效实现低功耗数字信号处理 (DSP) 应用。无论您采用 RTL、C/C++/SystemC 还是 Matlab/Simulink 设计流程,以下 AMD 工具都能显著简化 DSP 设计并加速产品上市。
库与框架
AMD 提供大量针对性能、资源利用及易用性进行优化的库。
| 库和框架 | 描述 |
应用 |
|---|---|---|
| GitHub 库 | AMD 已在 GitHub 平台建立官方代码库,其中包含丰富的应用示例,特别涵盖 DSP 相关功能实现。 | |
| Vitis 加速库 | AMD 开发了全面的开源高性能优化库,能够为现有应用提供开箱即用的加速功能,且几乎无需修改代码。 | Vitis 库 |
合作伙伴、开发板和套件
AMD 与其合作伙伴紧密协作,生产了各种工具及电路板,用于在众多不同市场领域简化 DSP 应用对 AMD FPGA 及 SoC 的采用。
| 合作伙伴 | 描述 | 解决方案 |
|---|---|---|
| Avnet 以 DSP 为导向的开发套件及模块 | MathWorks 与高速模拟技术领先供应商 Avnet 联合推出面向 DSP 的开发套件及量产级系统模块 (SOM),主要支持嵌入式视觉、软件定义无线电及高性能电机控制等应用场景。 |
Avnet |
| Mathworks 计算软件 | Mathworks MATLAB® 和 Simulink® 可助力用户实现以下功能,从而显著缩短自适应 SoC 和 FPGA 系统的开发时间:
|
Mathworks |
| 模拟器件附加电路板 | AD-FMCDAQ2-EBZ FMC 电路板是一款功能齐全的数据采集及信号综合原型设计平台,其易用性设计可显著加速终端信号处理系统的开发进程。
|
模拟器件 |
资源
随时掌握最新动态
加入自适应 SoC 和 FPGA 通知列表,及时接收最新动态与资讯。
附注
- 请参阅 WP486 – 基于 AMD 器件的 INT8 优化深度学习实现
- 在 UltraScale+ 中利用 3 个 DSP 切片的 Floating Point Operator 核实现的单精度浮点性能
附注
- 请参阅 WP486 – 基于 AMD 器件的 INT8 优化深度学习实现
- 在 UltraScale+ 中利用 3 个 DSP 切片的 Floating Point Operator 核实现的单精度浮点性能