在 AMD 器件上進行 INT8 最佳化的深度學習
相較於其他 FPGA DSP 架構,AMD 整合式 DSP 架構可在 INT8 深度學習運算中,達成高出 1.75 倍的解決方案層級效能。

AMD 自適應 SoC 與 FPGA 得天獨厚的優異彈性,可發揮硬體平行處理能力,正是高效能或多通道數位訊號處理 (DSP) 應用的理想選擇。AMD 自適應 SoC 與 FPGA 將這種處理頻寬,與全方位解決方案相結合,包括易於硬體設計人員、軟體開發人員和系統架構師使用的設計工具。
硬體平行處理能力
標準 Von Neumann DSP 架構需要 256 個週期,才能完成 256 抽頭有限脈衝響應 (finite impulse response, FIR) 過濾,然而自適應 SoC 與 FPGA 可以在單一時脈週期內,就達到相同結果。
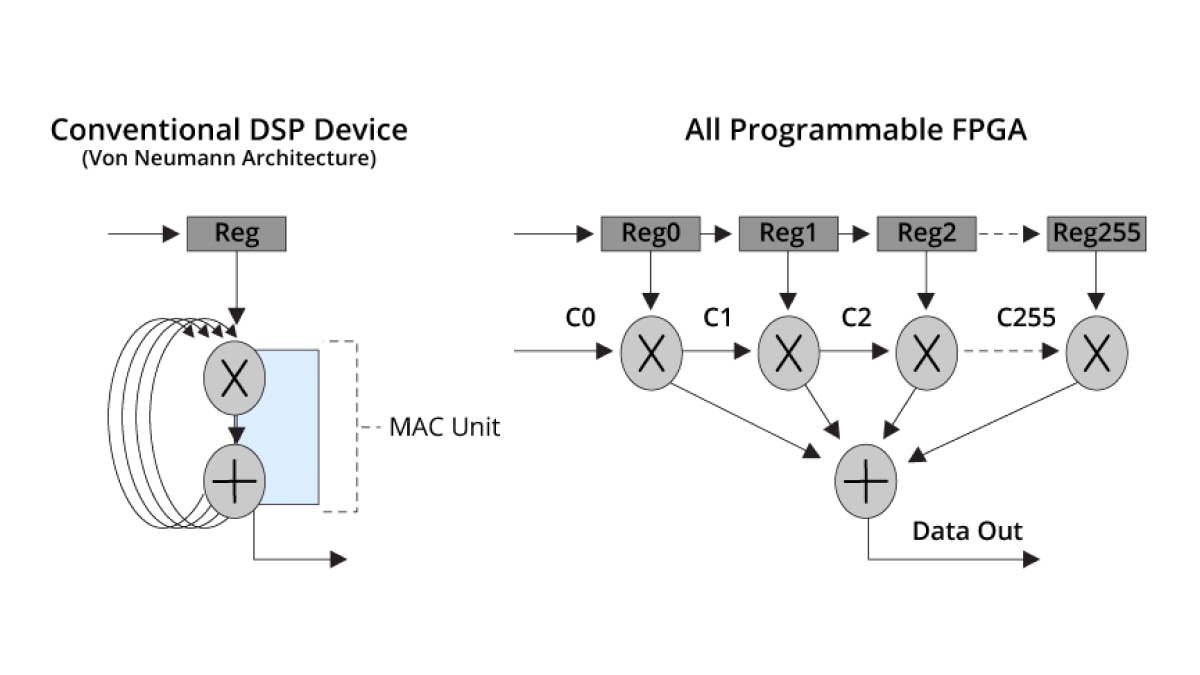
這種龐大平行處理能力,化為水準卓越的 DSP 效能:
全方位 DSP 解決方案
AMD DSP 解決方案包括晶片、IP、參考設計、開發板、工具、文件和訓練,可在廣大市場中實現大範圍應用,包括但不限於無線通訊、資料中心、航太與國防。
全面開發流程
提供多種工具流程,搭配不同使用模型和相異層級的設計抽象化:
硬體設計人員可在以下層級進行設計:
習慣使用 C/C++ 著手開發的軟體開發人員,可使用以下工具進行設計:
系統架構師可使用以下工具,迅速評估新的演算法:
設計人員透過 AMD 自適應 SoC 與 FPGA,可以視其設計方法和抽象化層級,使用多個流程部署其 DSP 應用。
在許多不斷變遷演進的 DSP 市場(例如航太、國防、汽車/工業,以及測試/測量),相關應用持續推動著 DSP 運算加速能力屢創高峰,同時保持能效。
隨著摩爾定律和登納德縮放比例定律不再依循傳統的軌跡,我們無法再像前幾代產品一般,單靠遷移到新一代晶片節點,就能提供更低功耗、更低成本和更佳效能的優勢。
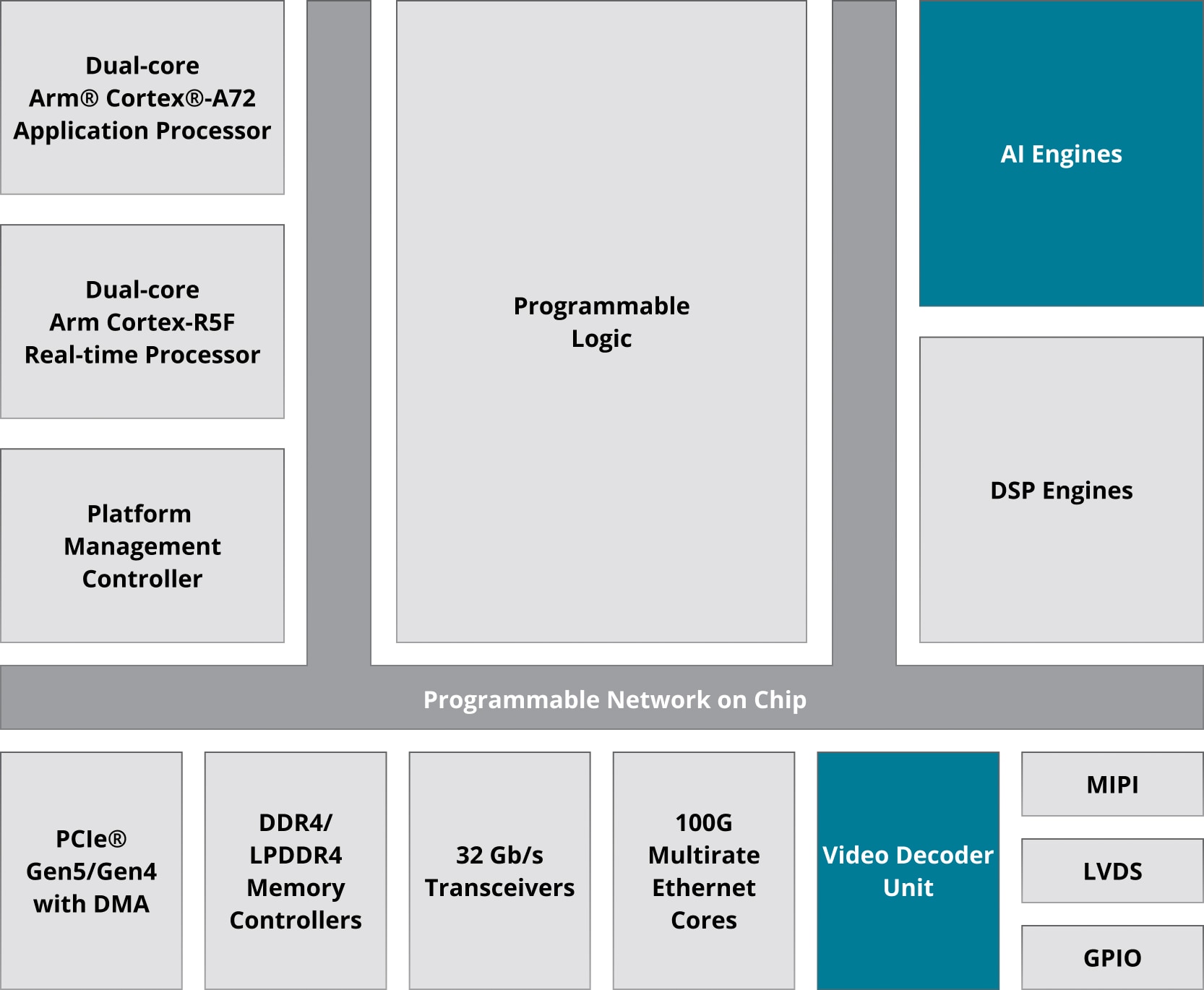
AMD 為了因應新一代 DSP 應用(例如多相通道化和波束成形)的非線性成長需求,已著手開發創新處理技術,即 AI 引擎,作為 AMD Versal™ 架構的一部分。
AI 引擎是由多個 AI 引擎磚組建而成的 2D 陣列,由於這樣的解決方案深具可擴充性,因而成就了高低不同級別的 Versal 產品,在單一器件提供數十個到數百個 AI 引擎,以滿足各種應用的運算需求。
其優勢包括:
AMD 自適應 SoC 和 FPGA 採用特殊應用積體電路 (Application-Specific Integrated Circuit, ASIC) 級架構,將每秒數百 Gigabit 的 I/O 頻寬和超過 49 TeraMACS 的固定點 DSP 效能,結合到 Versal™ Premium 系列中。AMD DSP slice 及其平行處理能力,是最新一代 AMD FPGA 得以實現 DSP 效能的關鍵。
Versal 器件 slice 中的 DSP58,是 AMD 架構的第 6 代 DSP slice。
此專用 DSP 處理區塊在完全客製的晶片中實作,為晶片帶來優異的功耗/效能,讓設計人員能夠有效率地實作常用的 DSP 運算,例如乘積累加 (MACC)、乘法加法 (MADD) 或複數乘法。
這款 slice 還提供執行不同邏輯運算類型的能力,例如 AND、OR 和 XOR 運算。
Versal 器件 DSP58 架構建立在 UltraScale™ FPGA DSP48E2 的成功基礎之上,並進一步強化提升:
上述增強之處有助於 DSP 關鍵應用,在進入 FPGA 結構之前,先在 DSP48E2 slice 中執行更多運算,最終達到節省資源和用電的效果。
| 功能 | UltraScale | Versal |
|---|---|---|
| DSP 磚/Slice 類型 | DSP48E2 | DSP58 |
| 多重加/減/累加運算 |  |
|
| 乘法器和 MACC | 27x18 | 27x24 |
| 平方: [(A 或 B) +/- D]2 | |
|
| WMUX 回饋超高效率複數乘法 CMACC | 3 個 DSP48E2 | 2 個 DSP58 |
| SIMD 支援 | |
|
| 整合式模式偵測電路 | |
|
| 整合邏輯單元 | |
|
| 寬多工器功能 | 48 位元 | 58 位元 |
| 寬 XOR | 96 位元 | 116 位元 |
| 單精確度浮點乘法器 | |
|
| 選配 96 位元輸出 | |
|
| 串聯路由 | |
|
| 管道暫存器 | |
|
| D 預加器 | |
|
| 連續複數乘法,AB 動態存取 | |
|
| 已改善 AB 暫存器管道平衡 | |
|
精選影片:
AMD 按照您的設計偏好提供了各種工具,以支援暫存器傳輸層 (Register Transfer Level, RTL)、C/C++ 和以模型為基礎的設計輸入。設計流程具備這種彈性,加上內容豐富的數位訊號處理 (digital signal processing, DSP) IP 目錄,有助於更輕鬆採用 AMD 工具和器件。
如需更多資訊,請造訪工具、程式庫與架構。
下表顯示的是 7 系列、UltraScale™ 和 UltraScale+™ 系列的一些關鍵 DSP 效能指標。有關自適應 SoC 器件效能,請參閱「軟體開發人員」一節。
| Kintex UltraScale | Kintex UltraScale+ | Virtex UltraScale | Virtex UltraScale+ | Versal AI Core | Versal AI Edge | Versal AI Prime | Versal AI Premium | |
|---|---|---|---|---|---|---|---|---|
| 系統邏輯元素數量 (K) | 318–1,451 | 356–1,143 | 783–5,541 | 862–3,780 | 540 - 1,968 | 44 - 1,139 | 329 - 2,233 | 833 - 7,352 |
| DSP 配量 | 768–5,520 | 1,368–3,528 | 600–2,880 | 2,280–12,288 | 928 - 1,968 | 90 - 1,312 | 464 - 3,984 | 1,140 - 14,352 |
| 27 x 18 乘法器 | 768–5,520 | 1,368–3,528 | 600–2,880 | 2,280–12,288 | 928 - 1,968 | 90 - 1,312 | 464 - 3,984 | 1,140 - 14,352 |
| INT8 GOPS1 | 1,774–14,315 | 4,263–11,000 | 1,554–7,469 | 7,108–38,318 | 6,403 - 13,579 | 62 - 9,052 | 3,201 - 27,489 | 7,866 - 99,029 |
| INT16 GOPS | 1,014–8,180 | 2,436–6,286 | 888–4,268 | 4,062–21,896 | 2,134 - 4,526 | 21 - 3,017 | 1,067 - 9,163 | 2,622 - 33,010 |
| 複數 INT18 GOPS | 676 - 5,453 | 1,624 - 4,191 | 592 - 2,845 | 2708 - 14,597 | 913 - 1,937 | 8 - 1,291 | 456 - 3,920 | 1,122 - 14,122 |
| 單精確度浮點 (GFLOPS)2 | 320–2,685 | 800–1,673 | 294–1,411 | 1,354–7,299 | 1,494 - 3,168 | 14 - 2112 | 747 - 6,414 | 1,835 - 23,107 |
我們導入軟體開發環境,以及一系列為人熟悉且功能強大的工具、程式庫與方法,讓軟體開發人員易於以 AMD 自適應 SoC 與 FPGA 為目標。透過 Vitis™ 統一軟體平台的高階抽象化環境,我們可以為 C、C++ 和/或 OpenCL 開發,提供類似顯示卡和熟悉的嵌入式應用程式開發和執行階段體驗。
Zynq™ UltraScale+™ MPSoC 和 Versal 架構結合功能強大的處理系統 (PS),將 Arm® Cortex® 處理器和使用者可程式化邏輯 (PL),整合至單一器件。
Vitis 統一軟體平台有能力分析特定應用,方便開發人員設計出能在可程式化邏輯 (PL) 中提升執行效率的硬體加速器,善用 FPGA 的彈性和平行處理能力,大幅改善效能。如有需要,還可以在處理系統 (PS) 中,平行執行應用程式的其他功能。
透過將 AMD 自適應 SoC 與 FPGA 視為目標,許多 DSP 和嵌入式應用,即可增進其應用效率且降低耗電量。
下表顯示的是 AMD Zynq UltraScale+ MPSoC 系列和 Versal™ 器件的一些關鍵功能和 DSP 效能指標。至於非 SoC 器件的效能,請見「硬體設計人員」一節。
| 處理系統 | Zynq 7000 SoC | Zynq UltraScale+ MPSoC |
|---|---|---|
| 應用程式 處理單元 (APU) |
|
|
| 即時 處理單元 (RPU) |
- |
|
| 多媒體處理 | - |
|
| 動態記憶體介面 | DDR3、DDR3L、DDR2、LPDDR2 | DDR4、LPDDR4、DDR3、DDR3L、LPDDR3 |
| 高速周邊設備 | USB 2.0、Gigabit 乙太網路、SD/SDIO | PCIe® Gen2、USB3.0、SATA 3.1、DisplayPort、Gigabit 乙太網路、SD/SDIO |
| 安全性 | RSA、AES,以及 SHA、ARM TrustZone® | RSA、AES,以及 SHA、ARM TrustZone |
| 最大 I/O 針腳數 | 128 | 214 |
| 可程式化邏輯 | Zynq 7000 SoC | Zynq UltraScale+ MPSoC |
|---|---|---|
| 系統邏輯元素數量 (K) | 23–444 | 103–1,045 |
| 最大記憶體 (Mb) | 1.8–26.5 | 5.3–70.6 |
| 最大 I/O 針腳數 | 100–362 | 252–668 |
| DSP 配量 | 60–2,020 | 240–3,528 |
| 18 x 18 乘法器 | 60–2,020 | 240–3,528 |
| 固定點效能 (GMACS) (1) | 42–1,313 | 213–3,143 |
| 對稱濾波器固定點效能 (GMACS) (1) (2) | 84–2,626 | 426–6,286 |
| INT8 GOPS (1) (3) | 84–2,626 | 745–11,000 |
| INT16 GOPS (1) | 84–2,626 | 426–6,286 |
| 單精確度浮點 (GFLOPS) (1) (4) | 23–716 | 142–1,673 |
| 單精確度浮點 (GFLOPs) (1) (5) | 17–537 | 106–1,571 |
| 半精確度浮點 (GFLOPS) (1) (6) | 34–1,074 | 212–3,142 |
附註:
若要瞭解更多關於 AMD 自適應 SoC 和 MPSoC 的資訊,請前往:
處理系統 (PS) 透過不同的 ARM 處理核心,提供 DSP 處理功能。
如需有關 ARM 處理器中 DSP 功能的更多資訊,請造訪:
以下資料提供了一些實用範例:
Zynq UltraScale+ MPSoC 的部分,請見 UG1211 示範如何使用 ARM NEON 指令集設計 FFT。
對於如何運用 Zynq 7000 SoC 的 Cortex-A9 和 ARM SIMD,Xilinx Wiki 提供了以下技術秘訣:
AMD 對其器件提供非常彈性的資料類型支援。AMD 工具原生支援不同的固定點、浮點和整數精確度,其中浮點的支援是在 Floating Point Operator IP 核心的協助下實現的。
相較於固定點或整數實作,在 FPGA 上實作的浮點設計,總會造成更高的資源和電力使用量。可能的話,轉換到固定點解決方案將帶來莫大好處:
如需更多詳細資訊,以瞭解從浮點轉換到固定點資料類型的好處,請參閱 WP491。
下表顯示的是使用 AMD 器件(特別是可程式化邏輯 (PL) 的結構)加速設計的幾種特選演算法,以及可能產生的效能改善。
| 演算法 | 處理器/顯示卡 | Zynq UltraScale+ MPSoC | Advantage |
|---|---|---|---|
| Stereo LocalBM @ 2K | ARM:0.5 FPS/瓦 nVidia:3.5 FPS/瓦 |
146 FPS/瓦 | 292x 42x |
| 光流 (盧卡斯-卡納德方法) |
ARM:0.1 FPS/瓦 nVidia:0.8 FPS/瓦 |
7.1 FPS/瓦 | 9.3x |
| GoogleNet (批次大小 = 1) |
ARM:0.1 Imgs/s/w nVidia:8.8 Imgs/s/w |
53 Imgs/s/w | 530x 6x |
附註:
| 演算法 | 處理器/DSP | Zynq 7000 | Advantage |
|---|---|---|---|
| 正向投影 | ARM:3 秒/視景 | 0.016 秒/視景 | 188x |
| 動作偵測 | ARM:0.7 FPS | 67 FPS | 90x |
| 降低雜訊 - Sobel | ARM:1 FPS | 67 FPS | 60x |
| Canny 邊緣偵測 | ARM:0.66 FPS | 40 FPS | 45x |
| 3D 影像重建 | ARM:75k | 8k | 9x |
| DPD | ARM:506 ms | 31.3 ms | 16x |
| 有限脈衝響應 (FIR) | TI DSP:64020 ns | 1200 ns | 53x |
| FFT | TI DSP:1036 ns | 128 ns | 8x |
附註:
AMD 高階設計工具,例如適用於 DSP 的 Vitis 模型編輯器,以及高階合成,提供了一定程度的抽象化,讓系統架構師和領域專家,得以迅速評估新演算法,並專注於開發其設計的差異化部分。這些設計工具、IP、參考設計、方法和開發板共同成就了一套完整的 AMD DSP 解決方案,只要兼採並用,就能在最短時間內,有效達成投產設計。
Vitis 模型編輯器是以模型為基礎的設計工具,利用 MATLAB 和 Simulink 環境,在可程式化邏輯中定義、測試和實現具量產品品質的 DSP 演算法,耗費時間遠少於傳統 RTL 開發。
此工具提供:
瞭解更多關於 Vivado System Generator for DSP 的資訊:
高階合成,包括 Vitis 統一軟體平台,讓可攜式 C、C++ 和 SystemC 演算法規格,可直接對應 AMD FPGA 和自適應 SoC,無需建立 RTL。正如同有因應 C/C++ 至不同處理器架構的編譯器,HLS 編譯器也是為 C/C++ 至 AMD FPGA 和自適應 SoC 提供相同功能。
瞭解更多關於 Vivado 高階合成的資訊:
AMD 提供同類最佳的工具,讓數位訊號處理 (DSP) 應用能在 AMD 自適應 SoC 與 FPGA 上,以低功耗高效率實作。無論您是使用 RTL、C/C++/SystemC 或 Matlab/Simulink 進行設計,以下 AMD 工具都可以輕鬆加快 DSP 設計,並縮短上市時間。
程式庫和架構
AMD 提供一系列針對效能、資源使用率和易用性進行最佳化的程式庫。
| 程式庫和架構 | 描述 |
應用程式 |
|---|---|---|
| GitHub 儲存庫 | AMD 已建立 GitHub 儲存庫,內含許多應用(包括 DSP 相關功能)的實用範例。 | |
| Vitis 加速程式庫 | AMD 已建立一組種類多樣的開放原始碼效能最佳化程式庫,可為您現有的應用程式,提供立即可用的加速方案,幾乎或完全無須修改程式碼。 | Vitis 程式庫 |
合作夥伴、開發板和套件
AMD 及其合作夥伴攜手合作,共同製作工具和開發板,協助許多市場部門簡化 DSP 應用採用 AMD FPGA 和 SoC 的過程。
| 合作夥伴 | 描述 | 解決方案 |
|---|---|---|
| Avnet 以 DSP 為中心的開發套件和模組 | MathWorks 和領先高速類比供應商 Avnet,針對嵌入式視覺、軟體定義無線電和高效能馬達控制,提供以 DSP 為中心的開發套件,以及可立即投入運作環境的系統模組 (System-on-Module, SOM)。 |
Avnet |
| Mathworks 運算軟體 | Mathworks MATLAB® 和 Simulink® 讓使用者能夠執行以下作業,大幅減少自適應 SoC 和 FPGA 系統的開發時間:
|
Mathworks |
| Analog Devices 擴充板 | AD-FMCDAQ2-EBZ FMC 板是獨立資料擷取和訊號合成原型設計平台,支援易於使用的操作,並加快終端系統訊號處理開發工作。
|
Analog Devices |
加入自適應 SoC 和 FPGA 通知清單,以接收最新消息與更新。