AMD 디바이스에서 INT8 최적화를 통한 딥 러닝
AMD 통합 DSP 아키텍처는 INT8 딥 러닝 작업에서 다른 FPGA DSP 아키텍처 대비 1.75배 높은 솔루션 수준의 성능을 달성할 수 있습니다.

고유한 유연성을 갖춘 AMD 적응형 SoC 및 FPGA는 하드웨어 병렬화를 활용할 수 있는 고성능 또는 다중 채널 DSP(Digital Signal Processing) 애플리케이션에 이상적입니다. AMD 적응형 SoC 및 FPGA는 이러한 처리 대역폭을 하드웨어 설계자, 소프트웨어 개발자 및 시스템 설계자가 쉽게 사용할 수 있는 설계 도구를 비롯한 종합 솔루션과 결합합니다.
하드웨어 병렬 처리
표준 폰 노이만 DSP 아키텍처는 256탭 FIR 필터를 완성하는 데 256주기가 필요하지만 적응형 SoC 및 FPGA는 클럭 주기 1회 만에 동일한 결과를 얻을 수 있습니다.
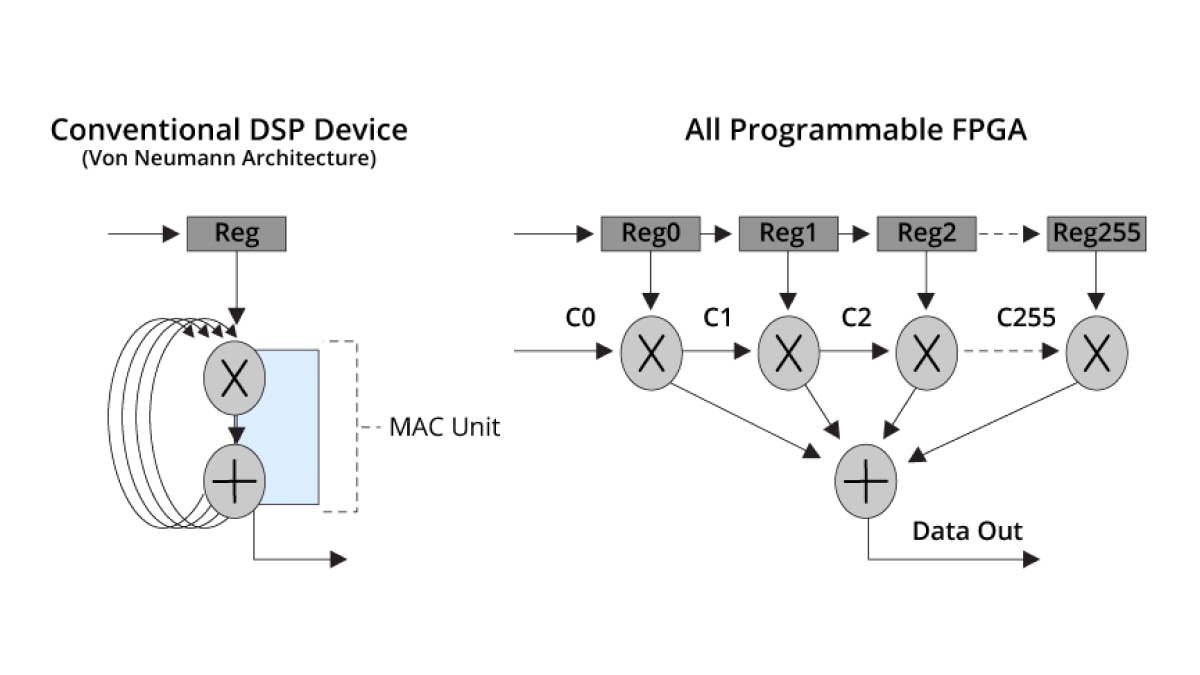
이러한 대규모 병렬화를 통해 탁월한 수준의 DSP 성능을 달성할 수 있습니다.
종합 DSP 솔루션
AMD DSP 솔루션에는 실리콘, IP, 참조 설계, 개발 보드, 도구, 문서 및 교육 등이 포함되어 있어 무선 통신, 데이터 센터, 항공우주 및 방위 산업을 비롯한 다양한 시장에서 광범위한 응용 분야를 지원할 수 있습니다.
포괄적인 개발 흐름
다양한 사용 모델 및 다양한 수준의 설계 추상화에 대해 다양한 도구 흐름을 사용할 수 있습니다.
하드웨어 설계자는 다음과 같은 환경에서 설계할 수 있습니다.
C/C++ 개발에 익숙한 소프트웨어 개발자는 다음을 사용하여 설계할 수 있습니다.
시스템 설계자는 다음을 통해 새로운 알고리즘을 신속하게 평가할 수 있습니다.
AMD 적응형 SoC 및 FPGA를 사용하면 설계자는 설계 접근 방식 및 추상화 수준에 따라 여러 흐름을 사용하여 DSP 애플리케이션을 배포할 수 있습니다.
항공우주, 국방, 자동차/산업, 테스트/측정 등 역동적이고 진화하고 있는 DSP 시장에서 애플리케이션은 전력 효율을 유지하면서 DSP 컴퓨팅 가속화를 지속적으로 요구하고 있습니다.
무어의 법칙과 데너드 스케일링이 더 이상 기존의 추세를 따르지 않기 때문에 차세대 실리콘 노드로 이동하는 것만으로는 이전 세대에서와 같이 더 낮은 전력과 비용으로 더 나은 성능을 얻을 수 없습니다.
AMD는 다상 채널화 및 빔포밍과 같은 차세대 DSP 애플리케이션의 이러한 비선형 수요 증가에 대응하여 AMD Versal™ 아키텍처의 일부로 새로운 혁신적인 프로세싱 기술인 AI Engine을 개발했습니다.
AI Engine은 여러 개의 AI 엔진 타일로 구성된 2D 어레이로 설계되어 있으며, Versal 포트폴리오 전반에 걸쳐 수십 개에서 수백 개에 이르는 AI 엔진을 단일 디바이스에 활용하는 확장성이 매우 뛰어난 솔루션을 가능하게 하여 광범위한 애플리케이션의 컴퓨팅 요구를 충족할 수 있습니다.
장점은 다음과 같습니다.
ASIC급 아키텍처를 기반으로 하는 AMD 적응형 SoC 및 FPGA는 Versal™ Premium 시리즈에서 초당 수백 기가비트의 I/O 대역폭과 49TeraMAC 이상의 고정 소수점 DSP 성능을 결합합니다. AMD DSP 슬라이스 및 병렬화는 최신 AMD FPGA에서 달성 가능한 DSP 성능을 달성하기 위한 핵심 비결입니다.
Versal 디바이스 슬라이스의 DSP58은 AMD 아키텍처의 6세대 DSP 슬라이스입니다.
이 전용 DSP 처리 블록은 곱셈-누산기(MACC), 곱셈-덧셈기(MADD) 또는 복합 곱셈과 같은 일반적인 DSP 기능을 효율적으로 구현할 수 있는 최고의 전력/성능을 제공하는 완전한 맞춤형 실리콘으로 구현됩니다.
또한 슬라이스는 AND, OR 및 XOR 연산과 같은 다양한 종류의 논리 연산을 수행하는 기능을 제공합니다.
Versal 디바이스 DSP58 아키텍처는 UltraScale™ FPGA DSP48E2의 성공을 기반으로 더욱 향상된 기능을 제공합니다.
DSP 중요 애플리케이션은 이렇게 향상된 기능을 통해 FPGA 패브릭으로 이동하기 전에 DSP48E2 슬라이스 내에서 더 많은 연산을 수행하여 궁극적으로 리소스 및 전력 절감 효과를 얻을 수 있습니다.
| 기능 | UltraScale | Versal |
|---|---|---|
| DSP 타일/슬라이스 유형 | DSP48E2 | DSP58 |
| 다중 덧셈/뺄셈/곱셈 연산 |  |
|
| 배수 및 MACC | 27x18 | 27x24 |
| 제곱: [(A 또는 B) +/- D]2 | |
|
| WMUX 피드백 초효율 복합 곱셈 CMACC | 3 x DSP48E2 | 2 x DSP58 |
| SIMD 지원 | |
|
| 통합 패턴 감지 회로 | |
|
| 통합 로직 유닛 | |
|
| 광범위한 Mux 함수 | 48비트 | 58비트 |
| 광범위한 XOR | 96비트 | 116비트 |
| 단일 정밀 부동 소수점 배수 | |
|
| 96비트 출력 옵션 | |
|
| 캐스케이드 라우팅 | |
|
| 파이프라인 레지스터 | |
|
| D 사전 덧셈기 | |
|
| 순차 복합 곱셈, AB 동적 액세스 | |
|
| AB 레지스터 파이프라인 균형 개선 | |
|
추천 동영상:
AMD는 설계 선호도에 따라 RTL, C/C++ 및 모델 기반 설계 항목을 지원하는 도구를 갖추고 있습니다. 설계 흐름의 이러한 유연성과 광범위한 DSP IP 카탈로그 덕분에 AMD 도구 및 디바이스를 보다 쉽게 채택할 수 있습니다.
자세한 내용은 도구, 라이브러리 및 프레임워크를 참조하세요.
다음 표는 7 시리즈, UltraScale™ 및 UltraScale+™ 제품군의 주요 DSP 성능 수치를 보여줍니다. 적응형 SoC 디바이스 성능에 대한 자세한 내용은 소프트웨어 개발자 섹션을 참조하세요.
| Kintex UltraScale | Kintex UltraScale+ | Virtex UltraScale | Virtex UltraScale+ | Versal AI Core | Versal AI Edge | Versal AI Prime | Versal AI Premium | |
|---|---|---|---|---|---|---|---|---|
| 시스템 로직 요소(K) | 318~1,451 | 356~1,143 | 783~5,541 | 862~3,780 | 540~1,968 | 44~1,139 | 329~2,233 | 833~7,352 |
| DSP 슬라이스 | 768~5,520 | 1,368~3,528 | 600~2,880 | 2,280~12,288 | 928~1,968 | 90~1,312 | 464~3,984 | 1,140~14,352 |
| 27x18 배수 | 768~5,520 | 1,368~3,528 | 600~2,880 | 2,280~12,288 | 928~1,968 | 90~1,312 | 464~3,984 | 1,140~14,352 |
| INT8 GOP1 | 1,774~14,315 | 4,263~11,000 | 1,554~7,469 | 7,108~38,318 | 6,403~13,579 | 62~9,052 | 3,201~27,489 | 7,866~99,029 |
| INT16 GOP | 1,014~8,180 | 2,436~6,286 | 888~4,268 | 4,062~21,896 | 2,134~4,526 | 21~3,017 | 1,067~9,163 | 2,622~33,010 |
| 복합 INT18 GOP | 676~5,453 | 1,624~4,191 | 592~2,845 | 2,708~14,597 | 913~1,937 | 8~1,291 | 456~3,920 | 1,122~14,122 |
| 단일 정밀 부동 소수점(GFLOP)2 | 320~2,685 | 800~1,673 | 294~1,411 | 1,354~7,299 | 1,494~3,168 | 14~2,112 | 747~6,414 | 1,835~23,107 |
AMD는 소프트웨어 개발 환경과 소프트웨어 개발자가 AMD 적응형 SoC 및 FPGA를 쉽게 타겟팅할 수 있도록 지원하는 친숙하고 강력한 도구, 라이브러리 및 방법론으로 구성된 종합 솔루션을 제공해 왔습니다. 높은 수준의 추상화 환경인 Vitis™ 통합 소프트웨어 플랫폼 제공. AMD는 C, C++ 및/또는 OpenCL 개발을 위해 GPU와 유사하며 친숙한 임베디드 애플리케이션 개발 및 런타임 경험을 제공할 수 있습니다.
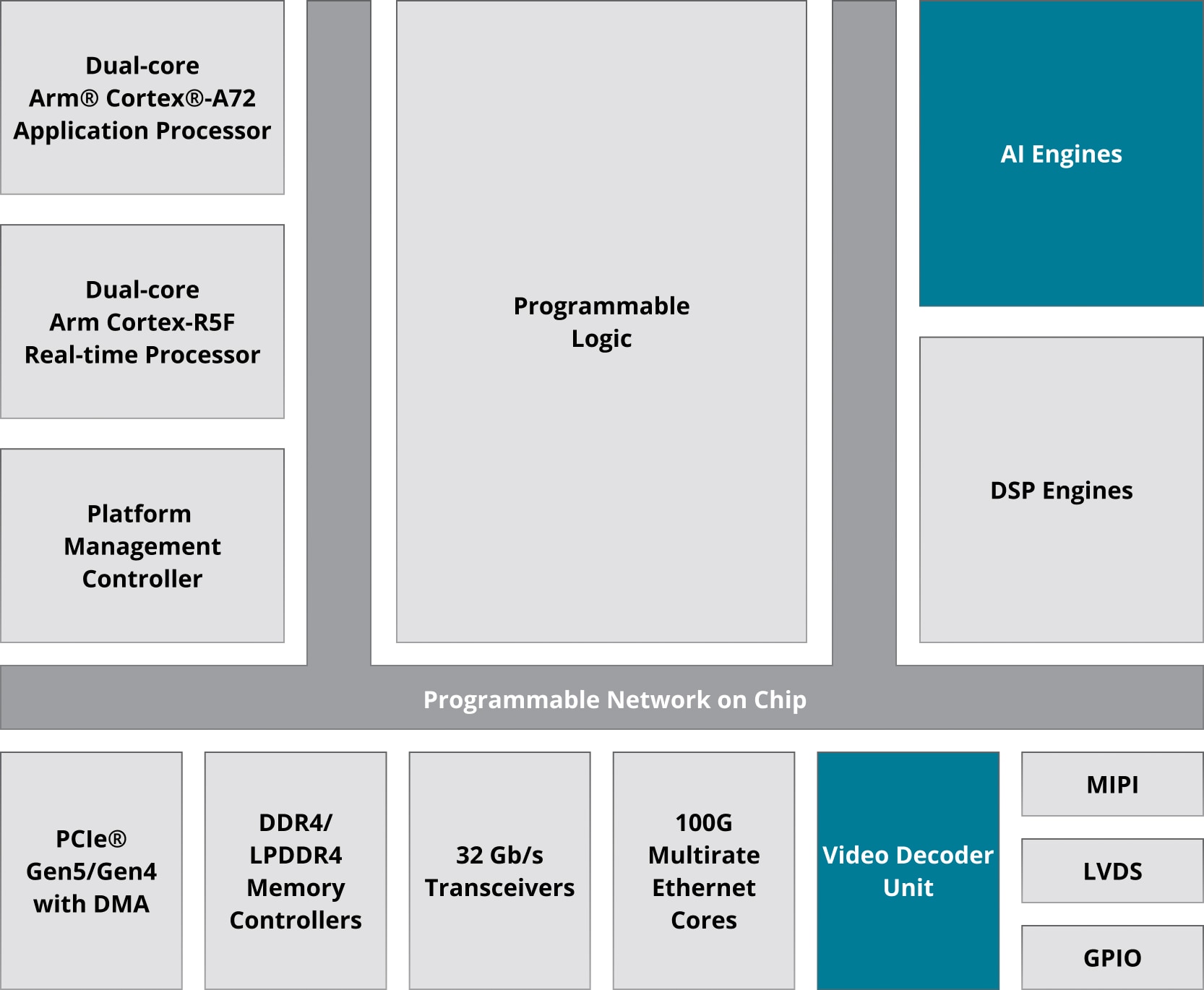
Zynq™ UltraScale+™ MPSoC와 Versal 아키텍처는 Arm® Cortex® 프로세서와 사용자 프로그래밍 가능 로직(PL)을 통합한 강력한 처리 시스템(PS)을 하나의 디바이스에 결합합니다.
Vitis 통합 소프트웨어 플랫폼은 특정 애플리케이션의 프로파일링 기능을 제공하며, FPGA의 유연성과 병렬화를 활용하여 성능을 크게 향상하는 프로그래밍 가능 로직(PL)에서 보다 효율적으로 실행되도록 하드웨어 가속기 생성을 지원합니다. 또한 원하는 경우 애플리케이션의 다른 기능을 처리 시스템(PS)에서 병렬로 실행할 수 있도록 지원합니다.
AMD 적응형 SoC 및 FPGA를 타겟팅함으로써 많은 DSP 및 임베디드 애플리케이션의 효율성을 높이고 전력 소비를 줄일 수 있습니다.
다음 표는 AMD Zynq UltraScale+ MPSoC 제품군 및 Versal™ 디바이스의 주요 기능 및 DSP 성능 수치를 보여줍니다. 비SoC 디바이스의 성능에 대한 자세한 내용은 하드웨어 설계자 섹션을 참조하세요.
| 처리 시스템 | Zynq 7000 SoC | Zynq UltraScale+ MPSoC |
|---|---|---|
| 적용 처리 장치(APU) |
|
|
| 실시간 처리 장치(RPU) |
- |
|
| 멀티미디어 처리 | - |
|
| 동적 메모리 인터페이스 | DDR3, DDR3L, DDR2, LPDDR2 | DDR4, LPDDR4, DDR3, DDR3L, LPDDR3 |
| 고속 주변기기 | USB 2.0, 기가비트 이더넷, SD/SDIO | PCIe® Gen2, USB3.0, SATA 3.1, DisplayPort, 기가비트 이더넷, SD/SDIO |
| 보안 | RSA, AES 및 SHA, ARM TrustZone® | RSA, AES 및 SHA, ARM TrustZone |
| 최대 I/O 핀 | 128 | 214 |
| 프로그래밍 가능 로직 | Zynq 7000 SoC | Zynq UltraScale+ MPSoC |
|---|---|---|
| 시스템 로직 요소(K) | 23~444 | 103~1,045 |
| 최대 메모리(Mb) | 1.8~26.5 | 5.3~70.6 |
| 최대 I/O 핀 | 100~362 | 252~668 |
| DSP 슬라이스 | 60~2,020 | 240~3,528 |
| 18x18 배수 | 60~2,020 | 240~3,528 |
| 고정 소수점 성능(GMAC)(1) | 42~1,313 | 213~3,143 |
| 대칭 필터(GMAC)의 고정 소수점 성능(1)(2) | 84~2,626 | 426~6,286 |
| INT8 GOP(1)(3) | 84~2,626 | 745~11,000 |
| INT16 GOP(1) | 84~2,626 | 426~6,286 |
| 단일 정밀 부동 소수점(GFLOP)(1)(4) | 23~716 | 142~1,673 |
| 단일 정밀 부동 소수점(GFLOP)(1)(5) | 17~537 | 106~1,571 |
| 반 정밀 부동 소수점(GFLOP)(1)(6) | 34~1,074 | 212~3,142 |
참고:
AMD 적응형 SoC 및 MPSoC에 대한 자세한 내용은 다음을 참조하세요.
처리 시스템(PS)은 다양한 ARM 처리 코어를 통해 DSP 처리 기능을 제공합니다.
ARM 프로세서의 DSP 기능에 대한 자세한 내용은 다음을 참조하세요.
다음 위치에서 유용한 예시를 찾을 수 있습니다.
Zynq UltraScale+ MPSoC의 경우, ARM NEON 명령어 세트를 사용한 FFT 데모는 UG1211을 참조하세요.
Zynq 7000 SoC의 경우, Cortex-A9 및 ARM SIMD를 대상으로 할 때 Xilinx Wiki에서 다음 기술 팁을 활용할 수 있습니다.
AMD는 디바이스를 통해 매우 유연한 데이터 유형 지원을 제공합니다. 고정 소수점, 부동 소수점 및 정수의 다양한 정밀도는 부동 소수점 연산자 IP 코어의 도움으로 구현되는 부동 소수점이 있는 AMD 도구에서 기본 지원됩니다.
FPGA에 구현된 부동 소수점 설계는 항상 고정 소수점 또는 정수 구현 대비 리소스 및 전력 사용량이 높습니다. 가능한 경우 고정 소수점 솔루션으로 변환하면 다음과 같은 큰 이점을 얻을 수 있습니다.
부동 소수점에서 고정 소수점 데이터 유형으로 변환 시 누릴 수 있는 이점의 세부 내용은 WP491을 참조하세요.
아래 표는 AMD 디바이스, 특히 프로그래밍 가능 로직(PL)의 패브릭을 사용하여 설계를 가속화함으로써 얻을 수 있는 알고리즘 및 성능 개선 결과의 일부를 보여줍니다.
| 알고리즘 | CPU/GPU | Zynq UltraScale+ MPSoC | Advantage |
|---|---|---|---|
| 2K에서 Stereo LocalBM | ARM: 0.5FPS/와트 nVidia: 3.5FPS/와트 |
146FPS/와트 | 292x 42x |
| 광학 흐름 (루카스-카나데) |
ARM: 0.1FPS/와트 nVidia: 0.8FPS/와트 |
7.1FPS/와트 | 9.3x |
| GoogleNet (배치=1) |
ARM: 0.1Imgs/s/w nVidia: 8.8Imgs/s/w |
53Imgs/s/w | 530x 6x |
참고:
| 알고리즘 | CPU/DSP | Zynq 7000 | Advantage |
|---|---|---|---|
| 포워드 프로젝션 | ARM: 3초/보기 | 0.016초/보기 | 188x |
| 동작 감지 | ARM: 0.7FPS | 67FPS | 90x |
| 노이즈 감소-소벨 | ARM: 1FPS | 67FPS | 60x |
| 캐니 에지 감지 | ARM: 0.66FPS | 40FPS | 45x |
| 3D 이미지 재구성 | ARM: 75k | 8k | 9x |
| DPD | ARM: 506ms | 31.3ms | 16x |
| FIR | TI DSP: 64020ns | 1200ns | 53x |
| FFT | TI DSP: 1036ns | 128ns | 8x |
참고:
DSP용 Vitis 모델 컴포저 및 HLS(High-Level Synthesis)와 같은 AMD 고급 설계 도구는 시스템 설계자와 도메인 전문가가 새로운 알고리즘을 신속하게 평가하고 설계의 차별화된 부분을 개발하는 데 집중할 수 있는 추상화 수준을 제공합니다. 완전한 AMD DSP 솔루션은 이러한 설계 도구, IP, 참조 설계, 방법론 및 보드가 결합되어 가능한 한 최단 시간 내에 실행 가능한 생산 설계를 완성합니다.
Vitis 모델 컴포저는 MATLAB 및 Simulink 환경을 활용하여 기존의 RTL 개발 시간보다 훨씬 짧은 시간 내에 프로그래밍 가능한 로직에서 프로덕션 품질 DSP 알고리즘을 정의, 테스트 및 구현하는 모델 기반 설계 도구입니다.
이 도구는 다음을 제공합니다.
DSP용 Vivado System Generator에 대해 자세히 알아보기:
Vitis 통합 소프트웨어 플랫폼을 포함한 HLS(High-Level Synthesis)는 RTL을 생성할 필요 없이 휴대용 C, C++ 및 SystemC 알고리즘 사양을 AMD FPGA 및 적응형 SoC에 직접 적용할 수 있도록 지원합니다. C/C++에서 다른 프로세서 아키텍처까지 컴파일러가 있는 것처럼 HLS 컴파일러는 C/C++에서 AMD FPGA 및 적응형 SoC까지 동일한 기능을 제공합니다.
Vivado HLS(High-Level Synthesis)에 대해 자세히 알아보기:
AMD는 AMD 적응형 SoC 및 FPGA에서 DSP(Digital Signal Processing) 애플리케이션을 고효율 및 저전력으로 구현할 수 있는 동급 최상의 도구를 제공합니다. RTL, C/C++/SystemC로 설계하거나 Matlab/Simulink로 설계하는 경우 모두 아래의 AMD 도구를 사용하면 DSP 설계를 쉽게 촉진하고 출시 시간을 단축할 수 있습니다.
라이브러리 및 프레임워크
AMD는 성능, 리소스 활용 및 사용 편의성에 최적화된 다양한 라이브러리를 제공합니다.
| 라이브러리 및 프레임워크 | 설명 |
적용 |
|---|---|---|
| GitHub 리포지토리 | AMD가 구축한 GitHub 리포지토리에는 DSP 관련 기능을 포함한 많은 애플리케이션에 대한 유용한 예시가 포함되어 있습니다. | |
| Vitis 가속화 라이브러리 | AMD는 기존 애플리케이션에 대한 코드 변경을 최소화하거나 코드 변경을 수행하지 않고 즉시 사용 가능한 가속화를 제공하는 광범위한 오픈 소스, 성능 최적화 라이브러리 세트를 개발했습니다. | Vitis 라이브러리 |
파트너, 보드 및 키트
AMD 및 파트너들은 많은 시장 부문에서 DSP 애플리케이션용 AMD FPGA 및 SoC를 쉽게 채택할 수 있는 도구와 보드를 제작하기 위해 협력하고 있습니다.
| 파트너 | 설명 | 해결책 |
|---|---|---|
| Avnet DSP 중심 개발 키트 및 모듈 | MathWorks 및 선도적인 고속 아날로그 공급업체인 Avnet은 임베디드 비전, 소프트웨어 정의 무선 및 고성능 모터 제어를 위한 DSP 중심 개발 키트 및 프로덕션 지원 SOM(System-On-Module)을 제공합니다. |
Avnet |
| MathWorks 컴퓨팅 소프트웨어 | MathWorks MATLAB® 및 Simulink®는 다음과 같은 기능을 통해 적응형 SoC 및 FPGA 시스템 개발 시간을 대폭 줄일 수 있습니다.
|
Mathworks |
| 아날로그 디바이스 애드온 보드 | AD-FMCDAQ2-EBZ FMC 보드는 자급형 데이터 수집 및 신호 합성 프로토타이핑 플랫폼으로, 사용이 용이하며 최종 시스템 신호 처리 개발을 더욱 빠르게 수행할 수 있습니다.
|
아날로그 디바이스 |
최신 뉴스와 업데이트를 받으려면 적응형 SoC 및 FPGA 알림 목록에 등록하세요.