Versal AI Engine: satisfacer las demandas de procesamiento DSP de alto rendimiento de las aplicaciones de última generación
En muchos mercados DSP dinámicos y en evolución, como el aeroespacial, de defensa, automotor/industrial, y de pruebas/mediciones, las aplicaciones están presionando para aumentar la aceleración de procesamiento DSP y mantener al mismo tiempo el ahorro de energía.
Dado que la ley de Moore y la escala de Dennard ya no siguen su trayectoria tradicional, pasar al nodo de chip de última generación por sí solo no puede ofrecer los beneficios de menor consumo de energía y menor costo con un mejor rendimiento, como en las generaciones anteriores.
En respuesta a este aumento no lineal de la demanda de aplicaciones DSP de última generación, como la canalización polifásica y la formación de haces, AMD desarrolló una nueva tecnología de procesamiento innovadora, el motor de IA, como parte de la arquitectura AMD Versal™.
Una mirada más cercana a Versal AI Engine:
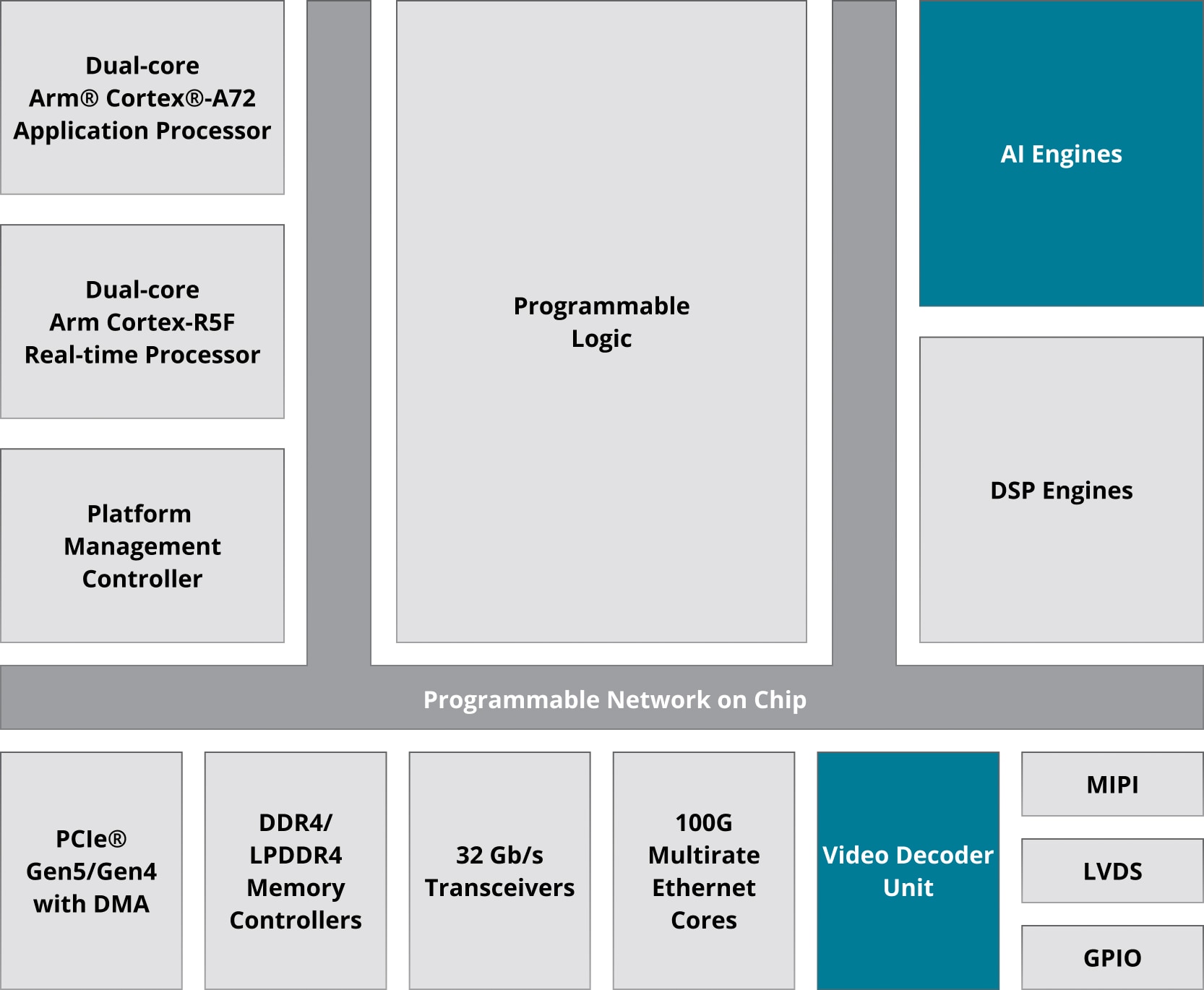
Arquitectura de motor de IA
Los motores de IA están diseñados como matrices 2D compuestas por múltiples mosaicos de motor de IA y permiten una solución muy escalable en toda la cartera de productos Versal, que abarca de 10s a 100s de motores de IA en un solo dispositivo, lo que satisface las necesidades de procesamiento de una amplia gama de aplicaciones.
Los beneficios incluyen las siguientes opciones:
Programabilidad de software
- C programable a través de la plataforma de software unificada de Vitis
- Programación basada en modelos a través de Vitis Model Composer
- Obtén más información sobre el proceso de diseño DSP del motor de IA
Determinista
- Instrucciones y memorias de datos dedicadas
- Conectividad dedicada emparejada con motores de DMA (Direct Memory Access, acceso directo a memoria) para el movimiento de datos programado mediante la conectividad entre los mosaicos del motor de IA
Eficiencia
- Ofrece una mayor densidad de procesamiento DSP en comparación con la lógica programable tradicional, al tiempo que reduce el consumo energético dinámico. Haz clic aquí para obtener más información.
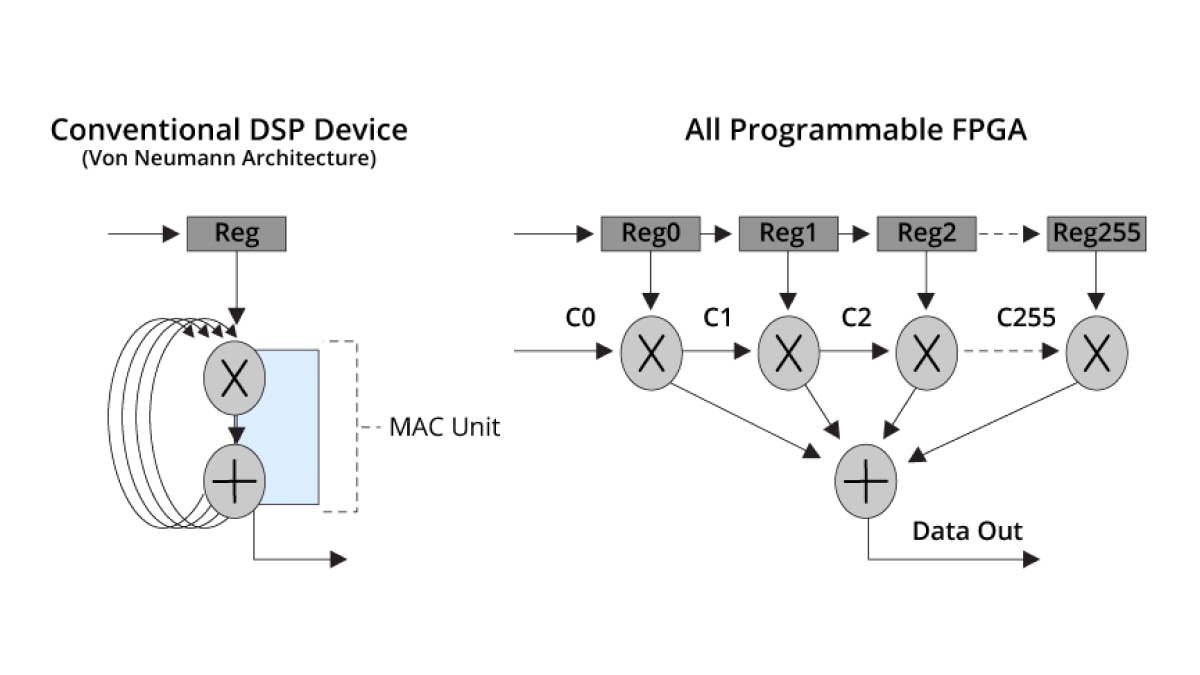
Basados en una arquitectura de clase ASIC (Application-Specific Integrated Circuit, circuito integrado para aplicaciones específicas), los SoC adaptables y FPGA de AMD combinan un ancho de banda de E/S de cientos de gigabits por segundo con más de 49 TeraMAC de rendimiento DSP de punto fijo en la Serie Versal™ Premium. La partición de DSP AMD y su paralelismo es clave para el rendimiento DSP alcanzable en la última generación de FPGA AMD.
Arquitectura de partición de DSP
La partición DSP58 en dispositivos Versal es la 6.ª generación de particiones de DSP en las arquitecturas AMD.
Este bloque de procesamiento DSP dedicado se implementa en chip completamente personalizado que ofrece potencia/rendimiento líderes, lo que permite implementaciones eficientes de funciones DSP populares, como MACC (multiply-accumulator, multiplicación-acumulación), MADD (multiply-adder, multiplicación-adición) o multiplicación compleja.
El segmento también ofrece capacidades para realizar diferentes tipos de operaciones lógicas, como AND, OR y operaciones XOR.
La arquitectura DSP58 de los dispositivos Versal se basa en el éxito de la FPGA UltraScale™ DSP48E2 con mejoras adicionales:
- Multiplicador más amplio (27 x 24 bits)
- Multiplicador de punto flotante de precisión simple
- Multiplicación compleja 18 x 18 usando dos DSP consecutivos
- Modo de producto punto de vector INT8
Estas mejoras ayudan a las aplicaciones fundamentales de DSP a realizar más procesamiento dentro del segmento DSP48E2 antes de entrar en la estructura FPGA, lo que en última instancia conduce a ahorros de recursos y energía.
Funciones del segmento DSP48E2 (UltraScale) frente a DSP58 (Versal)
| Función |
UltraScale |
Versal |
|---|
| Tipo de mosaico/segmento DSP |
DSP48E2 |
DSP58 |
| Múltiples operaciones de suma/resta/acumulación |
 |
|
| Multiplicador y MACC |
27x18 |
27x24 |
| Cuadratura: [(A o B) +/- D]2 |
|
|
| CMACC multiplicación compleja ultraeficiente de retroalimentación WMUX |
Tres unidades DSP48E2 |
Dos unidades DSP58 |
| Compatibilidad con SIMD |
|
|
| Circuitos integrados de detector de patrones |
|
|
| Unidad Lógica Integrada |
|
|
| Funciones Mux amplio |
48 bits |
58 bits |
| XOR amplio |
96 bits |
116 bits |
| Multiplicador de punto flotante de precisión simple |
|
|
| Salida opcional de 96 bits |
|
|
| Enrutamiento en cascada |
|
|
| Registros de canalización |
|
|
| D Preadicionador |
|
|
| Multiplicación compleja secuencial, acceso din. AB |
|
|
| Equilibrio de canalización de registro AB mejorado |
|
|
Videos destacados:
- Utilización del MUX de cuadratura en el segmento DSP48E2 (video)
- Utilización de la retroalimentación MUX amplia en el segmento DSP48E2 (video)
Herramientas y flujos
Según tus preferencias de diseño, AMD tiene herramientas compatibles con RTL, C/C++ y entrada de diseño basado en modelos. Esta flexibilidad en el flujo de diseño, junto con un extenso catálogo IP DSP, facilita la adopción de herramientas y dispositivos AMD.