AMD デバイスでの INT8 に最適化した深層学習の実装
AMD の統合型 DSP アーキテクチャは、INT8 の深層学習処理において、ほかの FPGA の DSP アーキテクチャと比べて、ソリューション レベルで最大 1.75 倍の性能を実現できます。

柔軟性に優れた AMD アダプティブ SoC/FPGA は、ハードウェアの並列性を利用する高性能/マルチチャネル デジタル信号処理 (DSP) アプリケーションに最適です。AMD アダプティブ SoC では、このプロセッシング帯域幅を実現できると同時に、ハードウェア設計者、ソフトウェア開発者、システム設計者が使いやすい設計ツールなどを含む包括的なソリューションを利用できます。
ハードウェアの並列性
一般的なノイマン型の DSP アーキテクチャでは、256 タップの FIR フィルターを処理するのに 256 サイクルを要しますが、アダプティブ SoC や FPGA では、同じ処理を 1 クロック サイクルで実行することが可能です。
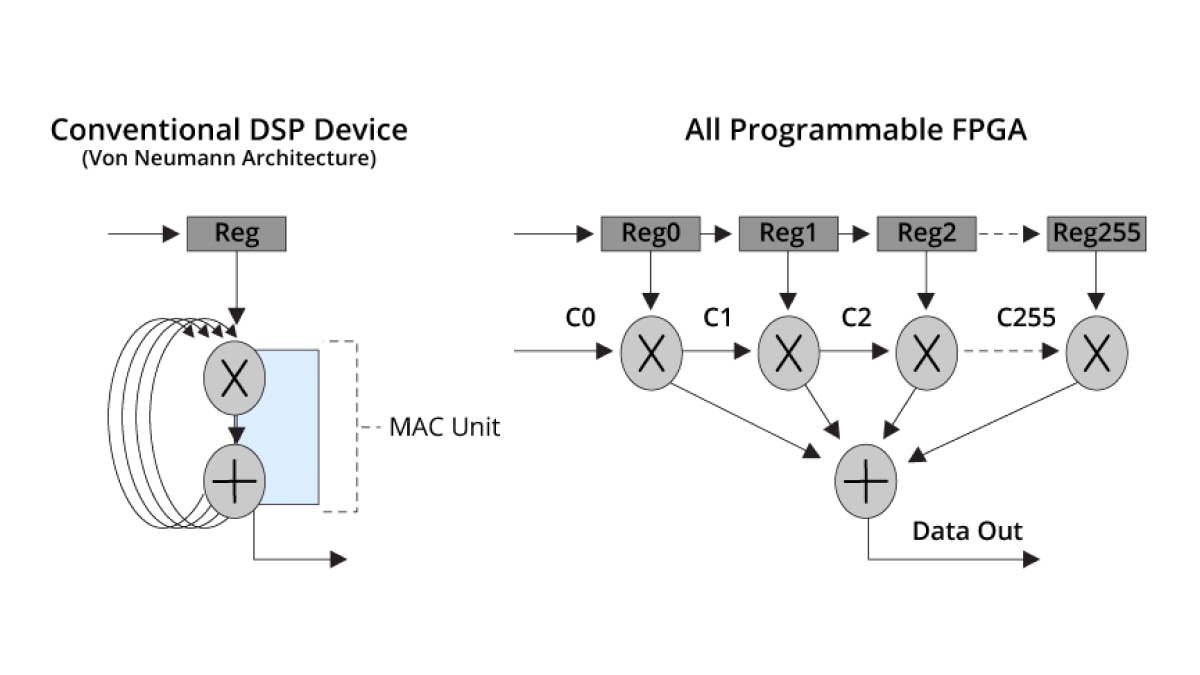
この大規模な並列性により、非常に高いレベルの DSP 性能が実現します。
包括的な DSP ソリューション
AMD の DSP ソリューションには、ワイヤレス通信、データセンター、航空宇宙/防衛をはじめとした広範な市場のさまざまなアプリケーションをサポートする、シリコン、IP、リファレンス デザイン、開発ボード、ツール、資料、トレーニングが含まれます。
包括的な開発フロー
異なる使用モデル、異なるデザインの抽象化レベルに対応するさまざまなツール フロー:
ハードウェア設計者は次の環境での設計が可能:
C/C++ を使用する開発環境に慣れているソフトウェア開発者は、次の環境での設計が可能:
システム アーキテクトは次の環境で新しいアルゴリズムの迅速な評価が可能:
AMD アダプティブ SoC および FPGA を利用する場合、DSP アプリケーションを運用するには設計アプローチやデザインの抽象化レベルに依存するさまざまなフローがあります。
航空宇宙、防衛、オートモーティブ/産業機器、テスト/計測機器など、急速に進化する DSP 市場の多くのアプリケーションでは、電力効率を維持しつつ、DSP 演算処理のさらなる高速化が求められています。
ムーアの法則やスケーリング則が限界を迎えた現在では、次世代シリコン ノードへ進化するだけでは、かつての世代のように高性能、低コスト、低消費電力のメリットを得ることができません。
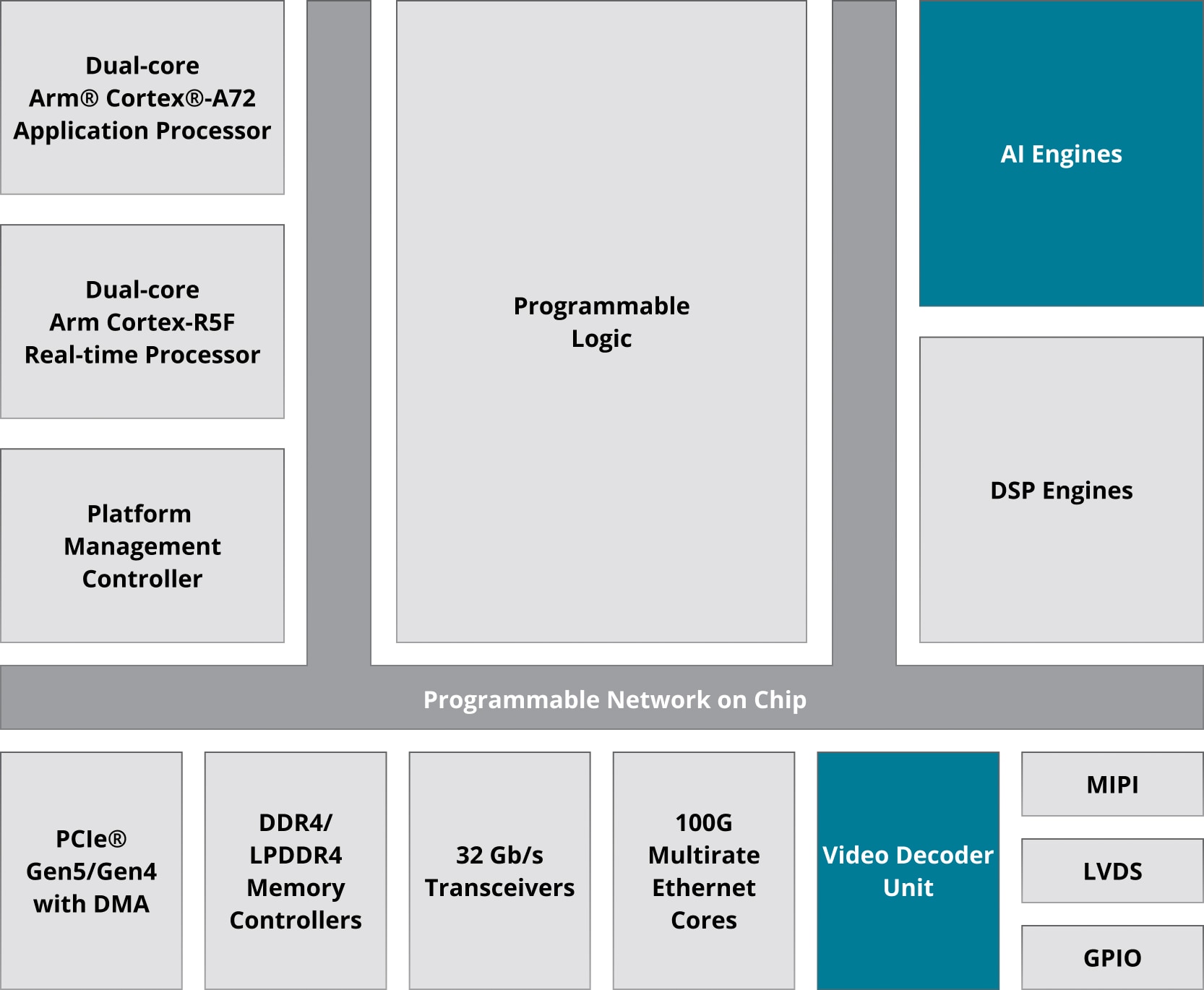
ポリフェーズ チャネライゼーションやビームフォーミングといった次世代 DSP アプリケーションにより急増する処理需要に対応するため、AMD は Versal™ アーキテクチャに統合されている革新的なプロセッシング技術「AI エンジン」を開発しました。
AI エンジンは、複数の AI エンジン タイルを二次元に配列したものです。単一デバイスに数十から数百個の AI エンジンを搭載した Versal ポートフォリオを利用することで、多様なアプリケーションの演算要件に応えることができ、拡張性も備えることができます。
サポート内容は以下のとおりです。
ASIC クラスのアーキテクチャをベースとする AMD のアダプティブ SoC/FPGA は、Versal™ プレミアム シリーズで、49 TeraMAC 以上の固定小数点 DSP 性能と数百 Gbps の I/O 帯域幅を提供します。最新世代 AMD FPGA で実現できる DSP 性能の鍵となるのは、AMD の DSP スライスとその並列性です。
Versal デバイスに搭載されている DSP58 は、AMD アーキテクチャで 6 世代目の DSP スライスです。
業界一の消費電力と性能を実現するために、この専用 DSP プロセッシング ブロックがフルカスタムのシリコンにインプリメントされるため、乗算累算 (MACC)、乗算加算 (MADD)、または複素乗算などの一般的な DSP 機能を効率的に実装できます。
また、このスライスは、AND、OR、XOR などさまざまなロジック動作を実行する機能も提供します。
Versal デバイス DSP58 アーキテクチャは、実績ある UltraScale™ FPGA DSP48E2 をベースとして構築され、機能が強化されたものです。
これらの機能強化によって、DSP のパフォーマンスを重視するアプリケーションでは FPGA ファブリックの消費を抑えてDSP48E2 スライス内で多くの演算を実行できるため、結果的にリソースや消費電力を削減できます。
| 機能 | UltraScale | Versal |
|---|---|---|
| DSP タイル/スライスの種類 | DSP48E2 | DSP58 |
| 複数の加算/減算/累算動作 |  |
|
| 乗算/MACC | 27x18 | 27x24 |
| 自乗演算: [(A または B) +/- D]2 | |
|
| WMUX フィードバックを使用する超高効率な複素乗算 CMACC | 3 x DSP48E2 | 2 x DSP58 |
| SIMD サポート | |
|
| インテグレイテッド パターン検出回路 | |
|
| インテグレイテッド ロジック ユニット | |
|
| ワイド MUX 機能 | 48 ビット | 58 ビット |
| ワイド XOR | 96 ビット | 116 ビット |
| 単精度浮動小数点乗算器 | |
|
| オプションの 96 ビット出力 | |
|
| カスケード配線 | |
|
| パイプライン レジスタ | |
|
| D 前置加算器 | |
|
| シーケンシャル複素乗算、AB ダイナミック アクセス | |
|
| AB レジスタのパイプライン バランシング向上 | |
|
関連ビデオ:
AMD は、ユーザーの好みに合わせて RTL、C/C++、およびモデルベースのデザイン入力に対応するさまざまなツールを提供しています。この柔軟な設計フローで広範な DSP IP カタログを活用することで、AMD のツールやデバイスの適用がよりスムーズになります。
詳細は、ツール、ライブラリ、フレームワークを参照してください。
次の表に 7 シリーズ、UltraScale™ および UltraScale+™ ファミリの主な DSP 性能の測定基準を示します。アダプティブ SoC デバイスの性能は、「ソフトウェア開発者」のセクションを参照してください。
| Kintex UltraScale | Kintex UltraScale+ | Virtex UltraScale | Virtex UltraScale+ | Versal AI コア | Versal AI エッジ | Versal AI プライム | Versal AI プレミアム | |
|---|---|---|---|---|---|---|---|---|
| システム ロジック エレメント (K) | 318 ~ 1,451 | 356 ~ 1,143 | 783 ~ 5,541 | 862 ~ 3,780 | 540 ~ 1,968 | 44 ~ 1,139 | 329 ~ 2,233 | 833 ~ 7,352 |
| DSP スライス | 768 ~ 5,520 | 1,368 ~ 3,528 | 600 ~ 2,880 | 2,280 ~ 12,288 | 928 ~ 1,968 | 90 ~ 1,312 | 464 ~ 3,984 | 1,140 ~ 14,352 |
| 27x18 乗算器 | 768 ~ 5,520 | 1,368 ~ 3,528 | 600 ~ 2,880 | 2,280 ~ 12,288 | 928 ~ 1,968 | 90 ~ 1,312 | 464 ~ 3,984 | 1,140 ~ 14,352 |
| INT8 GOP1 | 1,774 ~ 14,315 | 4,263 ~ 11,000 | 1,554 ~ 7,469 | 7,108 ~ 38,318 | 6,403 ~ 13,579 | 62 ~ 9,052 | 3,201 ~ 27,489 | 7,866 ~ 99,029 |
| INT16 GOP | 1,014 ~ 8,180 | 2,436 ~ 6,286 | 888 ~ 4,268 | 4,062 ~ 21,896 | 2,134 ~ 4,526 | 21 ~ 3,017 | 1,067 ~ 9,163 | 2,622 ~ 33,010 |
| Complex INT18 GOP | 676 ~ 5,453 | 1,624 ~ 4,191 | 592 ~ 2,845 | 2708 ~ 14,597 | 913 ~ 1,937 | 8 ~ 1,291 | 456 ~ 3,920 | 1,122 ~ 14,122 |
| 単精度浮動小数点 (GFLOPS)2 | 320 ~ 2,685 | 800 ~ 1,673 | 294 ~ 1,411 | 1,354 ~ 7,299 | 1,494 ~ 3,168 | 14 ~ 2112 | 747 ~ 6,414 | 1,835 ~ 23,107 |
AMD は、ソフトウェア開発環境と、使い慣れた優れたツール、ライブラリ、設計手法を含む包括的なソリューションを提供しているため、ソフトウェア開発者は AMD のアダプティブ SoC および FPGA をターゲットとする開発を簡単に始めることができます。Vitis™ 統合ソフトウェア プラットフォームによる高レベル抽象化環境を通じて、C、C++、および/または OpenCL による開発において、GPU のような使い慣れたエンベデッド アプリケーションの開発/実行環境を提供します。
Zynq™ UltraScale+™ MPSoC および Versal アーキテクチャは、Arm® Cortex® プロセッサを搭載した高性能なプロセッシング システム (PS) と、ユーザーがプログラム可能なロジック (PL) を 1 つのチップに統合しています。
Vitis 統合ソフトウェア プラットフォームは、特定のアプリケーションのプロファイリングが可能であり、プログラマブル ロジック (PL) でより効率に動作させるためのハードウェア アクセラレータを作成できます。FPGA の柔軟性と並列性によって大幅な性能向上を期待できます。また、必要に応じて、プロセッシング システム (PS) でアプリケーションのほかの機能を同時に実行することもできます。
AMD のアダプティブ SoC/FPGA を活用すれば、多くの DSP およびエンベデッド アプリケーションで、より高い処理効率と低消費電力を実現できます。
次の表に、AMD Zynq UltraScale+ MPSoC ファミリおよび Versal™ デバイスの主な機能と DSP 性能の測定基準を示します。SoC 以外のデバイス性能は、「ハードウェア設計者」のセクションを参照してください。
| プロセッシング システム | Zynq 7000 SoC | Zynq UltraScale+ MPSoC |
|---|---|---|
| アプリケーション プロセッシング ユニット (APU) |
|
|
| リアルタイム プロセッシング ユニット (RPU) |
- |
|
| マルチメディア処理 | - |
|
| ダイナミック メモリ インターフェイス | DDR3、DDR3L、DDR2、LPDDR2 | DDR4、LPDDR4、DDR3、DDR3L、LPDDR3 |
| 高速ペリフェラル | USB 2.0、Gigabit Ethernet、SD/SDIO | PCIe® Gen2、USB3.0、SATA 3.1、DisplayPort、Gigabit Ethernet、SD/SDIO |
| セキュリティ | RSA、AES、SHA、ARM TrustZone® | RSA、AES、SHA、Arm TrustZone |
| 最大 I/O ピン数 | 128 | 214 |
| プログラマブル ロジック | Zynq 7000 SoC | Zynq UltraScale+ MPSoC |
|---|---|---|
| システム ロジック エレメント (K) | 23 ~ 444 | 103 ~ 1,045 |
| 最大メモリ (Mb) | 1.8 ~ 26.5 | 5.3 ~ 70.6 |
| 最大 I/O ピン数 | 100 ~ 362 | 252 ~ 668 |
| DSP スライス | 60 ~ 2,020 | 240 ~ 3,528 |
| 18x18 乗算器 | 60 ~ 2,020 | 240 ~ 3,528 |
| 固定小数点の性能 (GMAC) (1) | 42 ~ 1,313 | 213 ~ 3,143 |
| 対称フィルターの固定小数点の性能 (GMAC) (1) (2) | 84 ~ 2,626 | 426 ~ 6,286 |
| INT8 GOP (1) (3) | 84 ~ 2,626 | 745 ~ 11,000 |
| INT16 GOP (1) | 84 ~ 2,626 | 426 ~ 6,286 |
| 単精度浮動小数点 (GFLOPS) (1) (4) | 23 ~ 716 | 142 ~ 1,673 |
| 単精度浮動小数点 (GFLOPS) (1) (5) | 17 ~ 537 | 106 ~ 1,571 |
| 半精度浮動小数点 (GFLOPS) (1) (6) | 34 ~ 1,074 | 212 ~ 3,142 |
注記:
AMD アダプティブ SoC および MPSoC の詳細は次のリンクを参照:
プロセッシング システム (PS) は異なる ARM プロセッシング コアを使用して DSP 処理機能を提供します。
ARM プロセッサの DSP 機能の詳細は次のリンクを参照:
次のリンクから、役に立つ例を参照できます。
Zynq UltraScale+ MPSoC については、UG1211 で ARM NEON 命令セットを使用した FFT のデモを確認してください。
Zynq 7000 SoC で、Cortex-A9 および ARM SIMD をターゲットとする場合、Xilinx Wiki で次のテクニカル ヒントを提供しています。
AMD の デバイスでは非常に柔軟にデータ タイプがサポートされています。AMD ツールは、固定小数点、浮動小数点、整数のさまざまな精度をネイティブでサポートしており、浮動小数点は Floating Point Operator IP コアを用いて実装されます。
FPGA に実装される浮動小数点デザインは、固定小数点や整数の実装と比べて、リソースの使用量と消費電力が高くなります。可能であれば固定小数点ソリューションに変換することで、次のような大きなメリットが得られます。
浮動小数点から固定小数点へデータ型を変換するメリットの詳細は、WP491 を参照してください。
以下の表は、AMD のデバイス、つまりプログラマブル ロジック (PL) のファブリックを使用してデザインを加速する場合の少ないアルゴリズムの選択肢とパフォーマンスの向上を示しています。
| アルゴリズム | CPU/GPU | Zynq UltraScale+ MPSoC | 優位性 |
|---|---|---|---|
| Stereo LocalBM @ 2K | ARM: 0.5 FPS/Watt nVidia: 3.5 FPS/Watt |
146 FPS/Watt | 292 倍 42 倍 |
| オプティカル フロー (Lucas-Kanade) |
ARM: 0.1 FPS/Watt nVidia: 0.8 FPS/Watt |
7.1 FPS/Watt | 9.3 倍 |
| GoogleNet (Batch=1) |
ARM: 0.1 Imgs/s/w nVidia: 8.8 Imgs/s/w |
53 Imgs/s/w | 530 倍 6 倍 |
注記:
| アルゴリズム | CPU/DSP | Zynq 7000 | 優位性 |
|---|---|---|---|
| 順投影 | ARM: 3 sec/view | 0.016 sec/view | 188 倍 |
| 動き検出 | ARM: 0.7 FPS | 67 FPS | 90 倍 |
| ノイズ除去 (ソーベル) | ARM: 1 FPS | 67 FPS | 60 倍 |
| Canny エッジ検出 | ARM: 0.66 FPS | 40 FPS | 45 倍 |
| 3D 画像再構成 | ARM: 75k | 8k | 9 倍 |
| DPD | ARM: 506 ms | 31.3 ms | 16 倍 |
| FIR | TI DSP: 64020 ns | 1200 ns | 53 倍 |
| FFT | TI DSP: 1036 ns | 128 ns | 8 倍 |
注記:
DSP 向けの Vitis Model Composer や高位合成などの AMD の高度な設計ツールは、システム アーキテクトや各分野の専門家が新しいアルゴリズムをすばやく評価し、デザインの差別化に集中できるようサポートする、抽象度の高い設計環境を提供します。包括的な AMD DSP ソリューションは、これらのデザインツール、IP、リファレンスデザイン、メソドロジ、およびボードを組み合わせることで、できるだけ短期間にプロダクション デザインを完成させることができます。
Vitis Model Composer は、MATLAB および Simulink 環境を活用して、プログラマブル ロジック上に量産品質の DSP アルゴリズムを定義、テスト、実装できるモデルベースの設計ツールであり、従来の RTL 開発と比べてはるかに短い時間で開発が可能です。
ツールが提供するもの:
Vivado System Generator for DSP の詳細は、次のリンクを参照:
Vitis 統合ソフトウェア プラットフォームに含まれる高位合成ツールを使用して、C、C++、SystemC で記述されたアルゴリズムを、RTL を作成することなく AMD の FPGA やアダプティブ SoC に直接実装できます。C/C++ から異なるプロセッサ アーキテクチャへのコンパイラと同様に、HLS コンパイラは C/C++ から AMD FPGA およびアダプティブ SoC へ同等の機能を提供します。
Vivado HLS の詳細は、次のリンクを参照:
AMD は、AMD の FPGA またはアダプティブ SoC 上でデジタル信号処理 (DSP) アプリケーションを効率的かつ低消費電力で実装するためのクラス最高のツールを提供しています。以下の AMD ツールは、RTL、C/C++/SystemC、または Matlab/Simulink のいかなる言語を使用する場合でも、DSP 設計を容易にし、市場投入までの時間を短縮します。
ライブラリとフレームワーク
AMD は、性能、リソースの利用率、使いやすさに最適化された豊富なライブラリを提供しています。
| ライブラリ & フレームワーク | 説明 |
アプリケーション |
|---|---|---|
| GitHub レポジトリ | AMD は GitHub リポジトリを作成し、DSP 関連機能を含むさまざまなアプリケーションに役立つサンプル コードを提供しています。 | |
| Vitis アクセラレーション ライブラリ | 既存のアプリケーションにわずかなコード変更を加えるだけですぐに高速化を実現できる、性能に最適化されたオープンソース ライブラリを多数提供しています。 | Vitis ライブラリ |
パートナーのボードおよびキット
AMD とパートナー企業は、さまざまな市場分野の DSP アプリケーションで AMD の FPGA/SoC を簡単に適用できるようにするためにツールやボードを提供しています。
| パートナー | 説明 | ソリューション |
|---|---|---|
| Avnet 社の DSP 中心の開発キットとモジュール | MathWorks 社、および主高速アナログ サプライヤーとの長年にわたる協力により、Avnet 社は DSP 中心の開発キットとエンベデッド ビジョン、ソフトウェア無線および高性能モーター制御向けのプロダクション対応システムオンモジュール (SOM) を提供しています。 |
Avnet 社 |
| Mathworks 社のコンピューティング ソフトウェア | Mathworks 社の MATLAB® および Simulink® は、次のことを可能にして、アダプティブ SoC および FPGA ベースのシステム開発時間を大幅に短縮できます。
|
MathWorks 社 |
| Analog Devices 社のアドオン ボード | AD-FMCDAQ2-EBZ FMC ボードは、操作が簡単な自己完結型のデータ アクイジションおよび信号合成プロトタイピング プラットフォームで、エンド システムの信号処理開発を迅速に行うことができます。
|
Analog Devices 社 |
アダプティブ SoC/FPGA の通知リストに登録された方には、最新情報をいち早くお届けします。