Nous avons introduit des environnements de développement de software et un ensemble complet d'outils, de bibliothèques et de méthodologies familiers et performants qui permettent aux développeurs de software de cibler facilement les SoC adaptatifs et les FPGA d'AMD. Avec la plateforme software unifiée Vitis™, un environnement d'abstraction de haut niveau. Nous pouvons offrir des expériences de développement et d'exécution d'applications intégrées de type GPU et familières pour le développement en C, C++ et/ou OpenCL.
MPSoCS AMD et appareils Versal
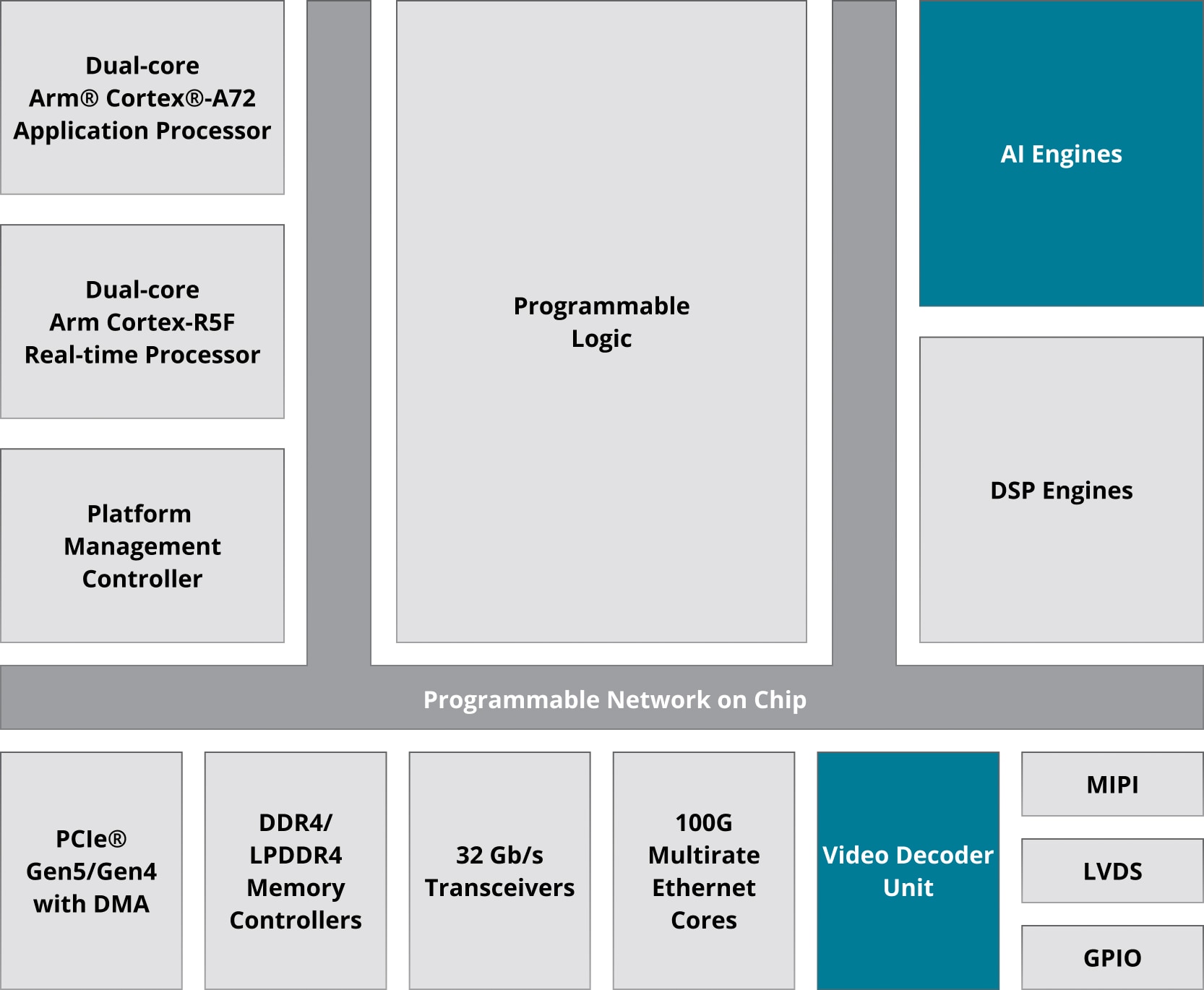
Le MPSoC Zynq™ UltraScale+™ et l'architecture Versal se combinent pour former un système de traitement (PS) puissant, intégrant des processeurs Arm® Cortex®, et une logique programmable par l'utilisateur (PL), dans un seul appareil.
Profilage d'applications pour l'accélération
La plateforme software unifiée Vitis permet de profiler une application donnée et de créer des accélérateurs hardware pour fonctionner plus efficacement dans la logique programmable (PL), où la flexibilité et le parallélisme du FPGA sont exploités pour améliorer les performances. Cela permet également d'exécuter d'autres fonctions de l'application en parallèle dans le système de traitement (PS), si nécessaire.
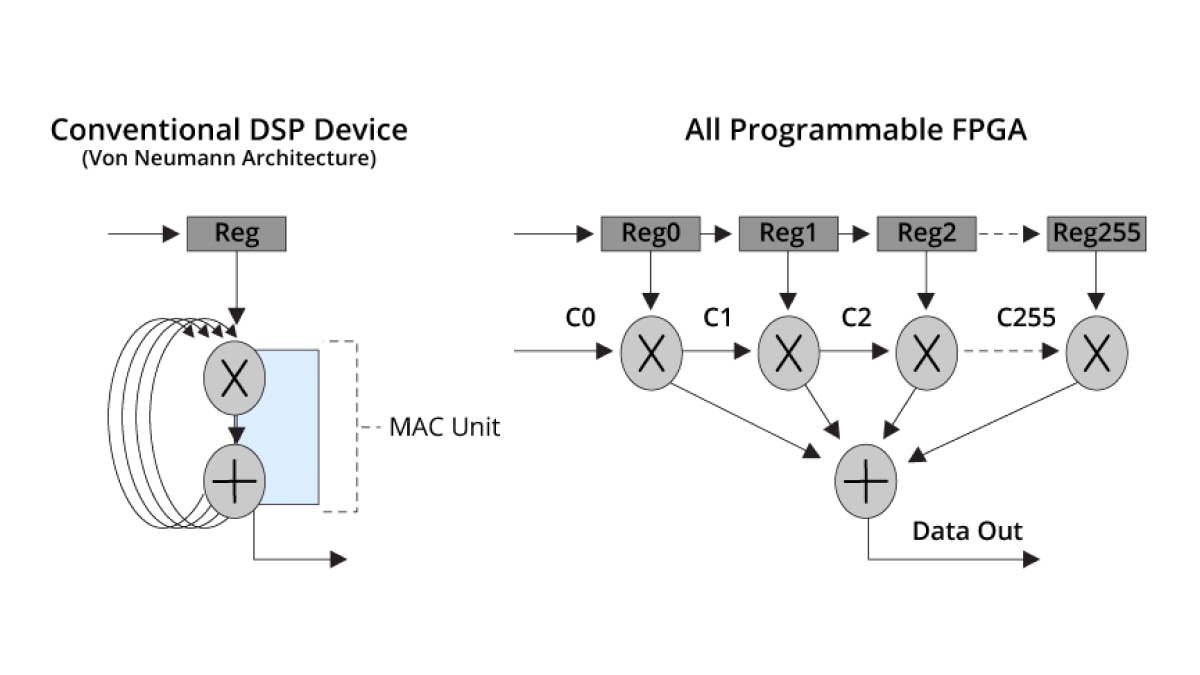
En ciblant les SoC adaptatifs et les FPGA d'AMD, de nombreuses applications DSP et intégrées verront leur efficacité s'améliorer et leur consommation diminuer.
Caractéristiques et performances DSP des appareils SoC AMD
Les tableaux suivants présentent certaines des principales fonctionnalités et mesures de performance DSP des gammes de MPSoC Zynq UltraScale+ et des appareils Versal™ d'AMD. Pour connaître les performances des appareils autres que les SoC, consultez la section Concepteur de hardware.
| Système de traitement |
SoC Zynq 7000 |
MPSoC Zynq UltraScale+ |
|---|
Application
Unité centrale (APU) |
- MPCore™ ARM Cortex-A9 simple/double cœur jusqu'à 1 GHz
- Architecture ARMv7-A
- Moteur de traitement multimédia NEON™
- Unité à virgule flottante vectorielle (VFPU) en précision simple et double
|
- MPCore ARM Cortex-A53 double cœur/quadricœur jusqu'à 1,5 GHz
- Architecture ARMv8-A
- Moteur de traitement multimédia NEON Advanced SIMD
- Unité à virgule flottante (FPU) en précision simple/double
|
En temps réel
Unité centrale (RPU) |
- |
- MPCore ARM Cortex-R5 double cœur jusqu'à 600 MHz
- Architecture ARMv7-R
- Unité à virgule flottante (FPU) en précision simple/double
|
| Traitement multimédia |
- |
- GPU ARM Mali™-400 MP2 jusqu'à 667 MHz
- Prise en charge d'OpenGL ES 1.1 et 2.0
- Prise en charge d'OpenVG 1.1
- Codec vidéo prenant en charge H.264-H.265 (appareils EV uniquement)
|
| Interface de mémoire dynamique |
DDR3, DDR3L, DDR2, LPDDR2 |
DDR4, LPDDR4, DDR3, DDR3L, LPDDR3 |
| Périphériques haut débit |
USB 2.0, Gigabit Ethernet, SD/SDIO |
PCIe® Gen2, USB3.0, SATA 3.1, DisplayPort, Gigabit Ethernet, SD/SDIO |
| Sécurité |
RSA, AES et SHA, ARM TrustZone® |
RSA, AES et SHA, ARM TrustZone |
| Nombre maximal de broches d'E/S |
128 |
214 |
| Logique programmable |
SoC Zynq 7000 |
MPSoC Zynq UltraScale+ |
|---|
| Éléments logiques du système (K) |
23–444 |
103–1 045 |
| Mémoire max. (Mo) |
1,8–26,5 |
5,3–70,6 |
| Nombre maximal de broches d'E/S |
100–362 |
252–668 |
| Unités DSP |
60–2 020 |
240–3 528 |
| Multiplicateurs 18x18 |
60–2 020 |
240–3 528 |
| Performances en virgule fixe (GMACS) (1) |
42–1 313 |
213–3 143 |
| Performances en virgule fixe pour les filtres symétriques (GMACS) (1) ( 2) |
84–2 626 |
426–6 286 |
| GOPS INT8 (1) (3) |
84–2 626 |
745–11 000 |
| GOPS INT16 (1) |
84–2 626 |
426–6 286 |
| Virgule flottante en simple précision (GFLOPS) (1) ( 4) |
23–716 |
142–1 673 |
| Virgule flottante en simple précision (GFLOPS) (1) ( 5) |
17–537 |
106–1 571 |
| Virgule flottante en demi-précision (GFLOPS) (1) (6) |
34–1 074 |
212–3 142 |
Remarques :
- Tous les calculs de performance sont basés sur des composants de niveau de vitesse -2 pour le SoC adaptatif Zynq 7000 et -3 pour le MPSoC Zynq UltraScale+
- L'utilisation du pré-additionneur DSP permet de doubler les performances sur les filtres symétriques
- Reportez-vous au document WP486 : Apprentissage profond avec optimisation INT8 sur les appareils AMD (non applicable aux appareils Zynq)
- Performance de calcul en virgule flottante en simple précision utilisant le Floating-Point Operator avec 3 tranches DSP
- Performance de calcul en virgule flottante en simple précision utilisant le Floating-Point Operator avec 4 tranches DSP
- Performance de calcul en virgule flottante en demi-précision utilisant le Floating-Point Operator avec 2 tranches DSP
Pour en savoir plus sur les SoC et les MPSoc adaptatifs AMD, rendez-vous sur :
DSP dans le sous-système de traitement
Le système de traitement (PS) fournit des capacités de traitement DSP via les différents cœurs de traitement ARM.
Pour plus d'informations sur les capacités DSP des processeurs ARM, rendez-vous sur :
Vous trouverez des exemples utiles aux emplacements suivants :
Pour le MPSoC Zynq UltraScale+, consultez le UG1211 pour une démonstration d'un FFT à l'aide du jeu d'instructions ARM NEON.
Pour le SoC Zynq 7000, les conseils techniques suivants sont disponibles sur le wiki Xilinx pour le ciblage du Cortex-A9 et de l'ARM SIMD :
Prise en charge des types de données AMD
AMD offre une prise en charge très flexible des types de données dans ses appareils. Les outils AMD prennent en charge nativement les différentes précisions des nombres à virgule fixe, des nombres à virgule flottante et des nombres entiers, la virgule flottante étant implémentée à l'aide du cœur IP Floating-Point Operator.
Les conceptions en virgule flottante implémentées sur des FPGA entraîneront toujours une consommation de ressources et d'énergie plus élevée que les implémentations en virgule fixe ou en nombre entier. Le passage à une solution en virgule fixe, lorsque cela est possible, apportera de nombreux avantages :
- Moins de ressources FPGA
- Consommation d'énergie inférieure
- Coût inférieur
Pour plus de détails sur les avantages du passage des types de données à virgule flottante à ceux à virgule fixe, consultez le document WP491.
Benchmarks
Les tableaux ci-dessous présentent une petite sélection d'algorithmes et les améliorations de performances possibles en utilisant un dispositif AMD et en particulier la structure de la logique programmable (PL) pour accélérer la conception.
| Algorithme |
CPU/GPU |
MPSoC Zynq UltraScale+ |
Advantage |
|---|
| Stereo LocalBM @ 2K |
ARM : 0,5 i/s/Watt
NVIDIA : 3,5 i/s/Watt |
146 i/s/Watt |
292x
42x |
Flux optique
(Lucas-Kanade) |
ARM : 0,1 i/s/Watt
NVIDIA : 0,8 i/s/Watt |
7,1 i/s/Watt |
9.3x |
GoogleNet
(Lot =1) |
ARM : 0,1 im/s/w
NVIDIA : 8,8 im/s/w |
53 im/s/w |
530x
6x |
Remarques :
- ARM : Le quadricœur A53 fonctionne sur le Raspberry Pi à une fréquence de 1 200 MHz.
- Les benchmarks NVIDIA ont été réalisés avec Tegra X1
- Flux optique (LK) – Taille de fenêtre 11 x 1
| Algorithme |
CPU/DSP |
Zynq 7000 |
Advantage |
|---|
| Projection avant |
ARM : 3 s/vue |
0,016 s/vue |
188x |
| Détection de mouvement |
ARM : 0,7 i/s |
67 FPS |
90x |
| Réduction du bruit-Sobel |
ARM : 1 i/s |
67 FPS |
60x |
| Détection des contours de Canny |
ARM : 0,66 i/s |
40 i/s |
45x |
| Reconstruction d'images 3D |
ARM : 75k |
8k |
9x |
| DPD |
ARM : 506 ms |
31,3 ms |
16x |
| FIR |
TI DSP : 64020 ns |
1200 ns |
53x |
| FFT |
TI DSP : 1036 ns |
128 ns |
8x |
Remarques :
- Le cœur Cortex-A9 est utilisé uniquement sur les appareils Zynq lorsqu'ils ciblent ARM.
- Les benchmarks TI ont été réalisés à l'aide du cœur DSP C66