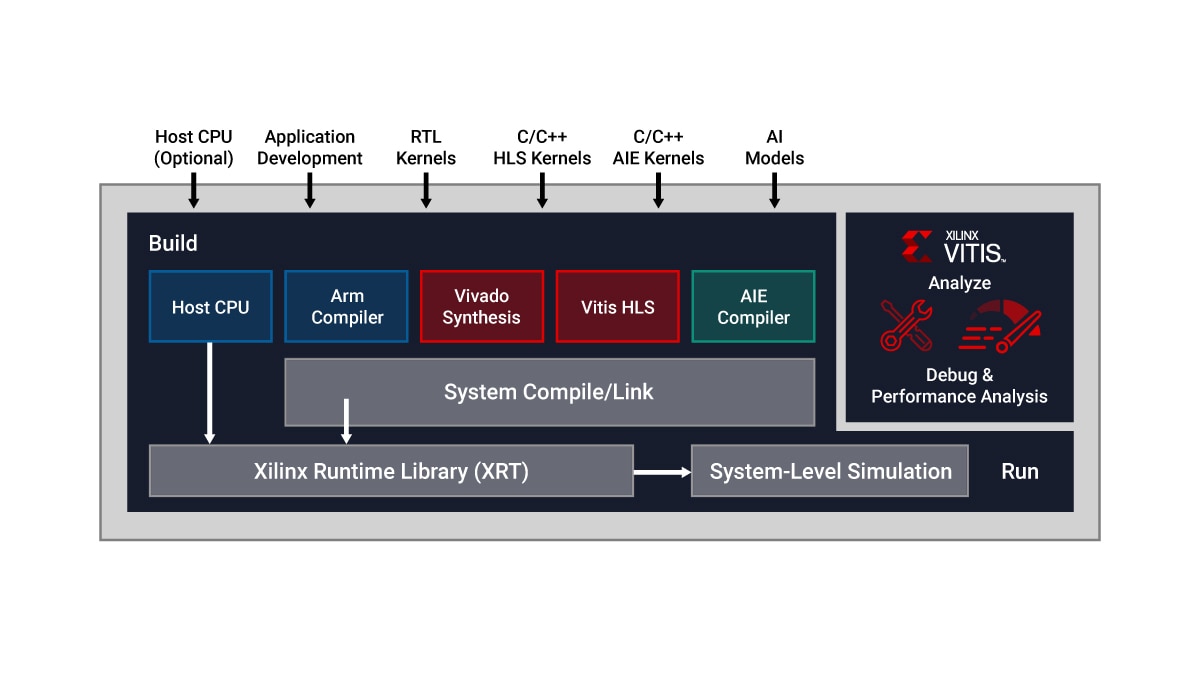
Programmation du flux de données pour développeur software/hardware
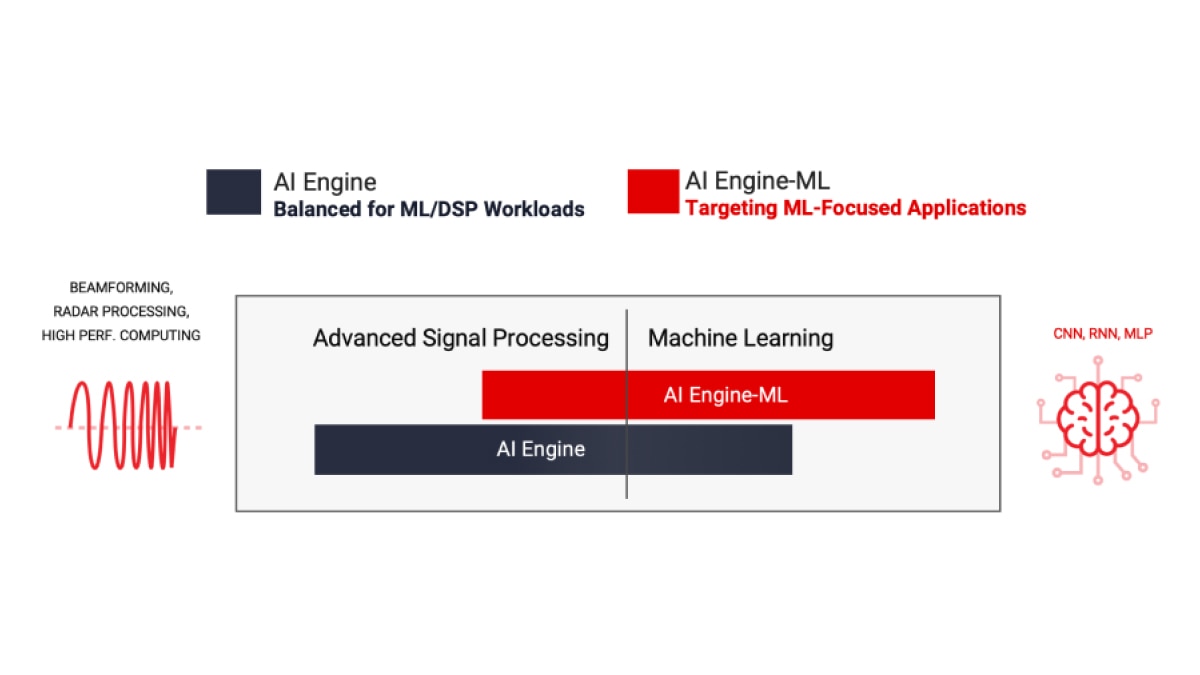
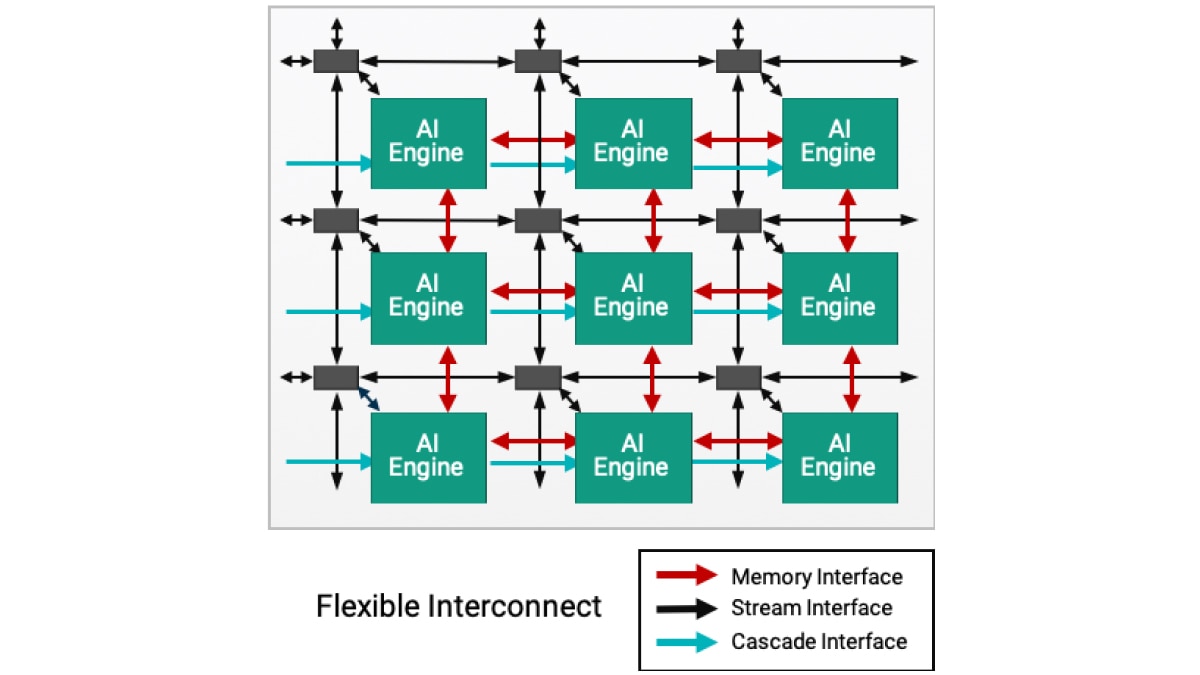
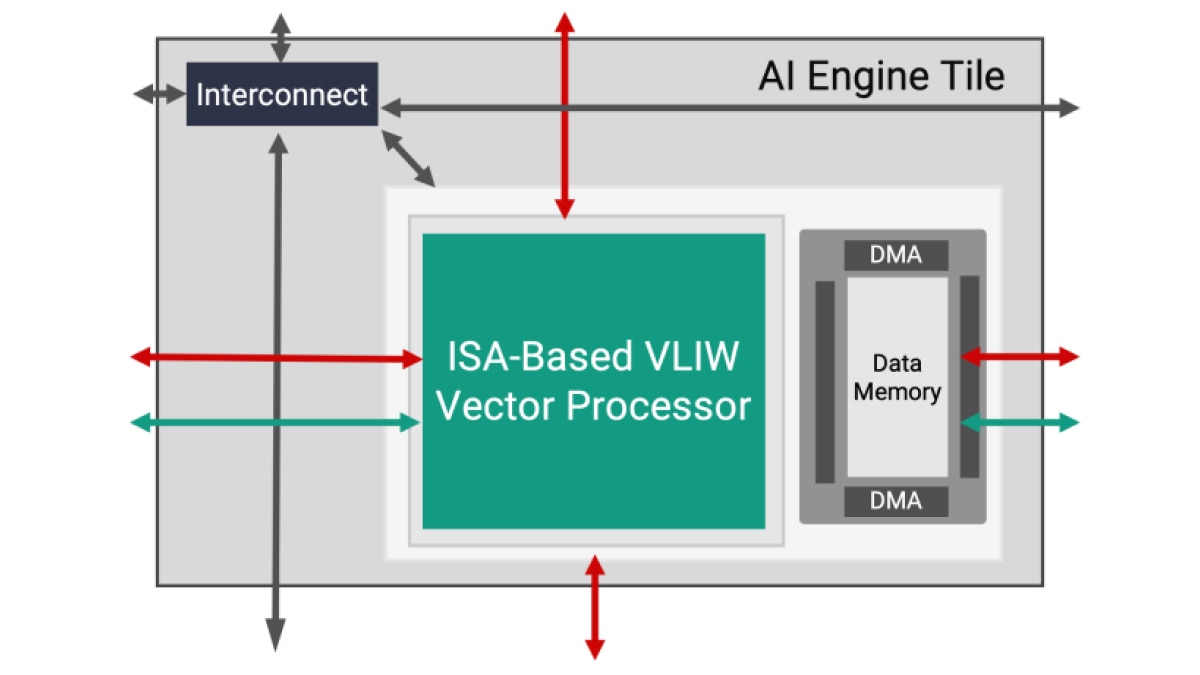
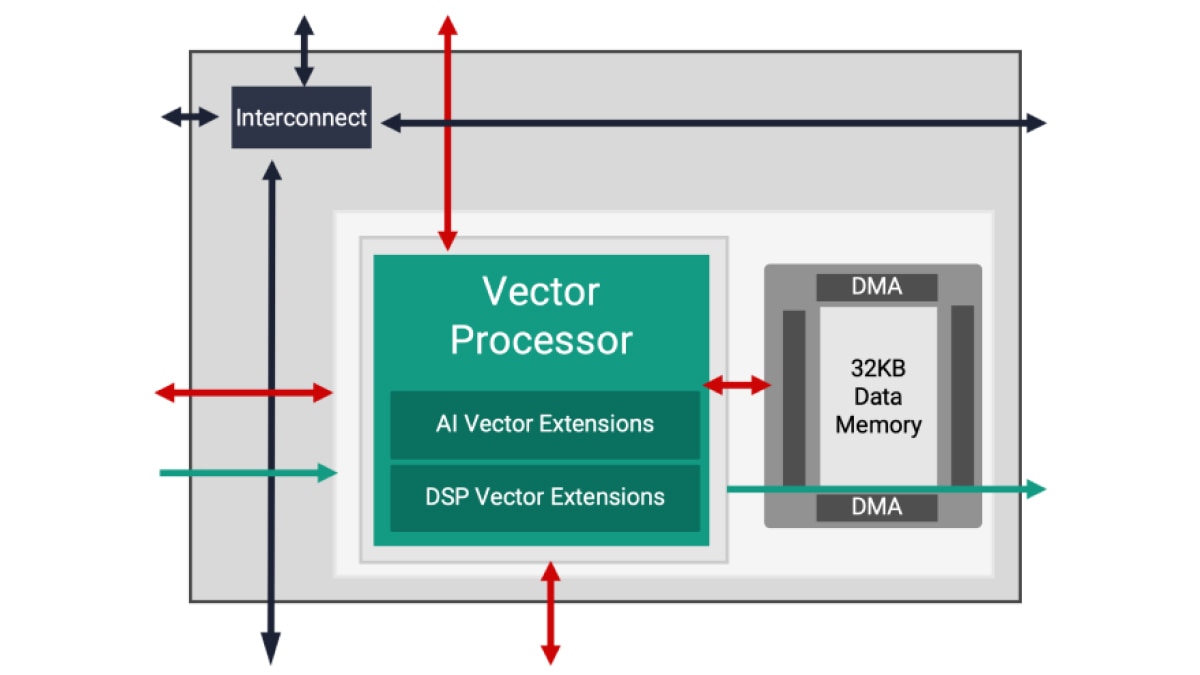
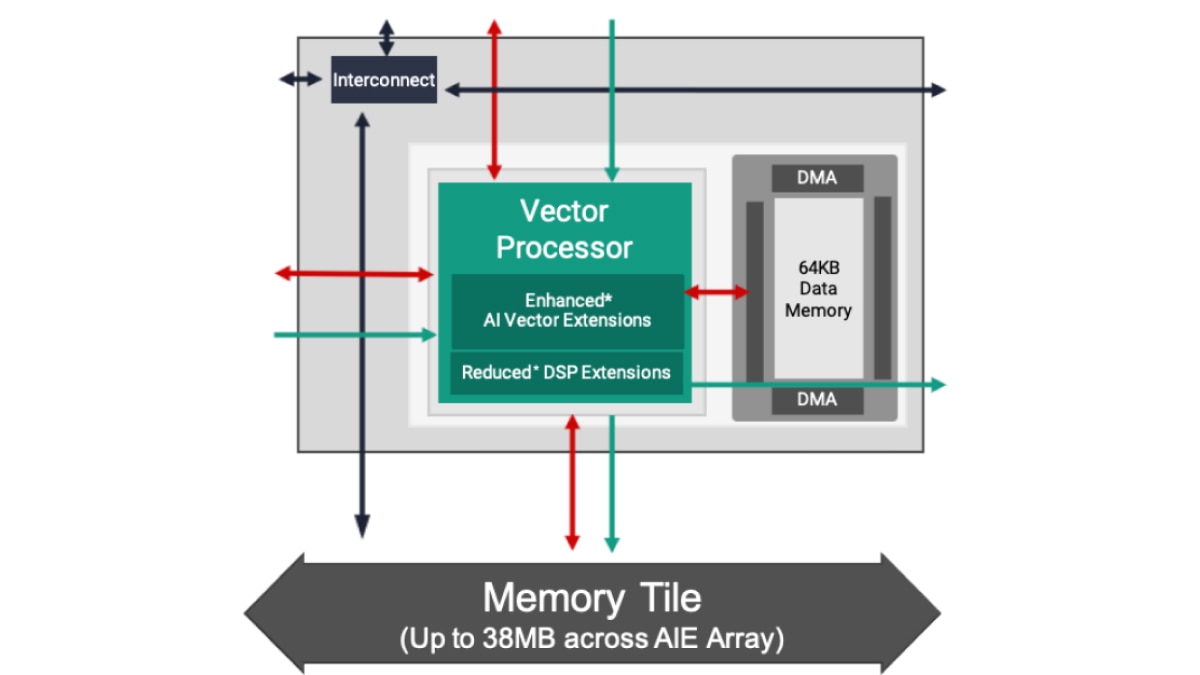
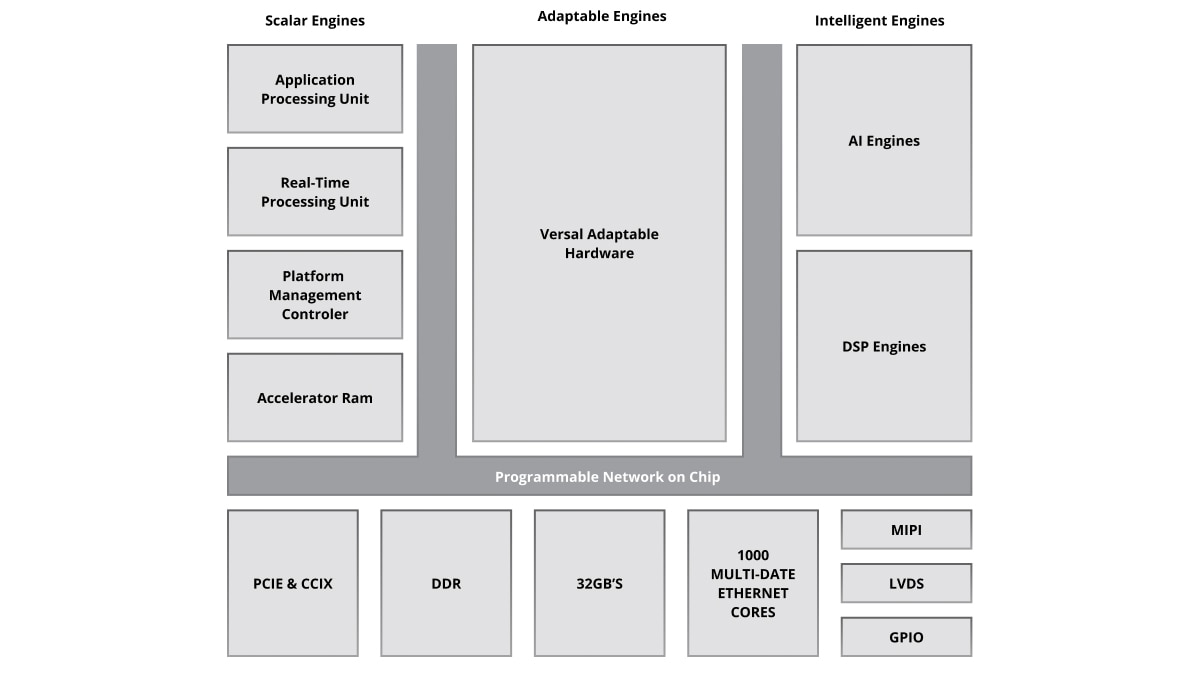
L'architecture AI Engine est basée sur une technologie de flux de données. Les éléments de traitement se présentent sous forme de matrices de 10 à 100 tuiles, créant un programme unique à l'échelle des unités de calcul. Pour un concepteur, il serait fastidieux et presque impossible d'intégrer des directives pour spécifier le parallélisme entre ces tuiles. Pour surmonter cette difficulté, la conception AI Engine s'effectue en deux étapes : le développement d'un seul noyau suivi de la création d'un graphe ADF (Adaptive Data Flow), qui connecte plusieurs noyaux dans une application globale.
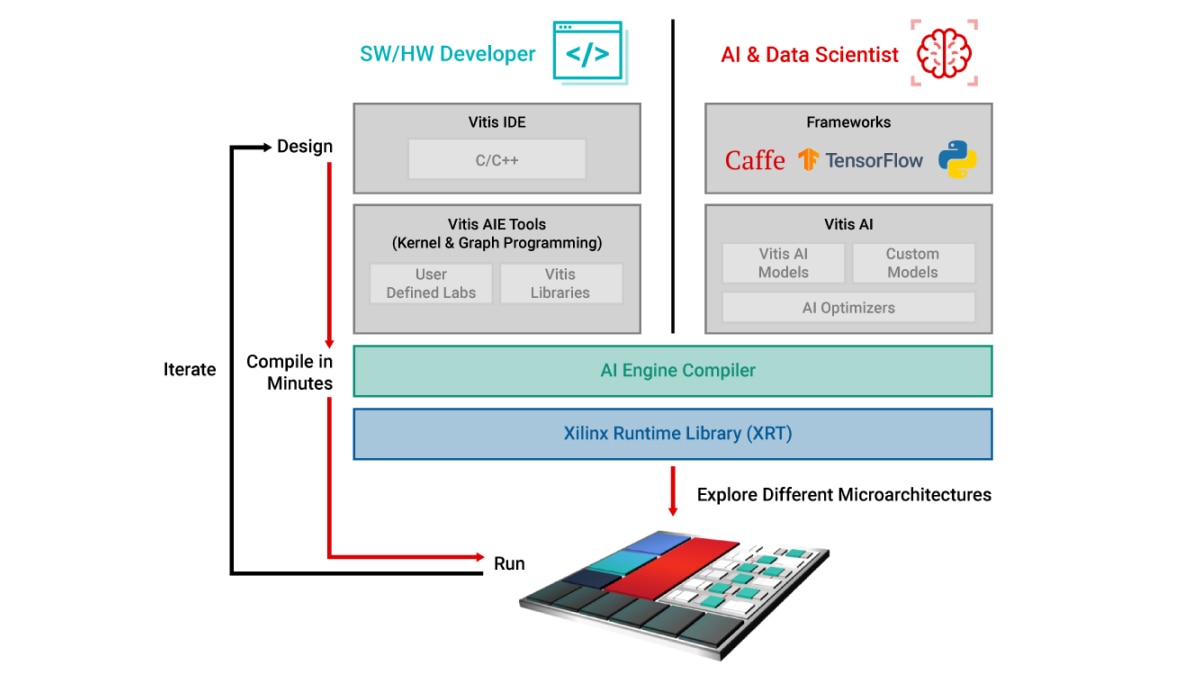
Vitis Unified IDE constitue un cockpit IDE unique qui permet le développement de noyaux AI Engine à l'aide de code de programmation C/C++ et de conception de graphes ADF. Plus précisément, les concepteurs peuvent :
- Développer des noyaux en C/C++ et décrire des fonctions de calcul spécifiques à l'aide des bibliothèques Vitis
- Connecter des noyaux via des graphes ADF à l'aide des outils Vitis AI Engine
Par défaut, un seul noyau s'exécute sur une seule tuile AI Engine. Cependant, plusieurs noyaux peuvent s'exécuter sur la même tuile AI Engine, partageant le temps de traitement lorsque l'application le permet.
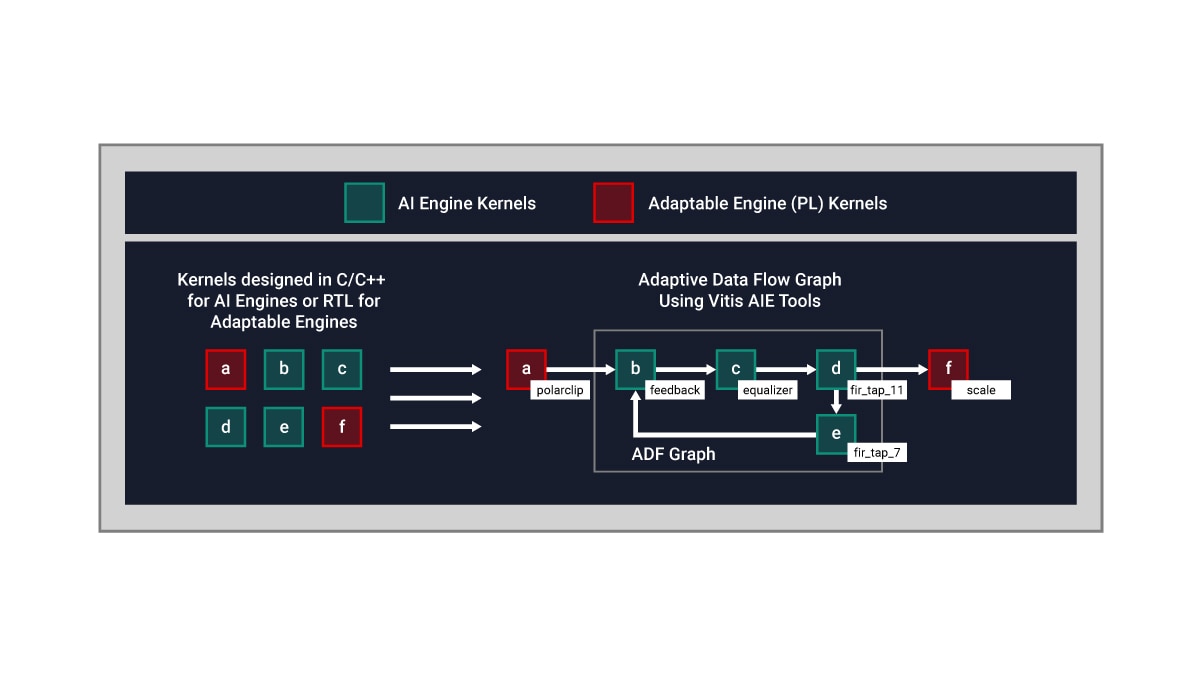
Voici un exemple conceptuel :
- Les noyaux AI Engine sont développés en C/C++
- Les noyaux en logique programmable (PL) sont écrits en RTL ou en synthèse de haut niveau (HLS) Vitis
- Le flux de données entre les noyaux en PL et les AI Engines s'effectue via un graphique ADF