Versal™ AI Core 系列
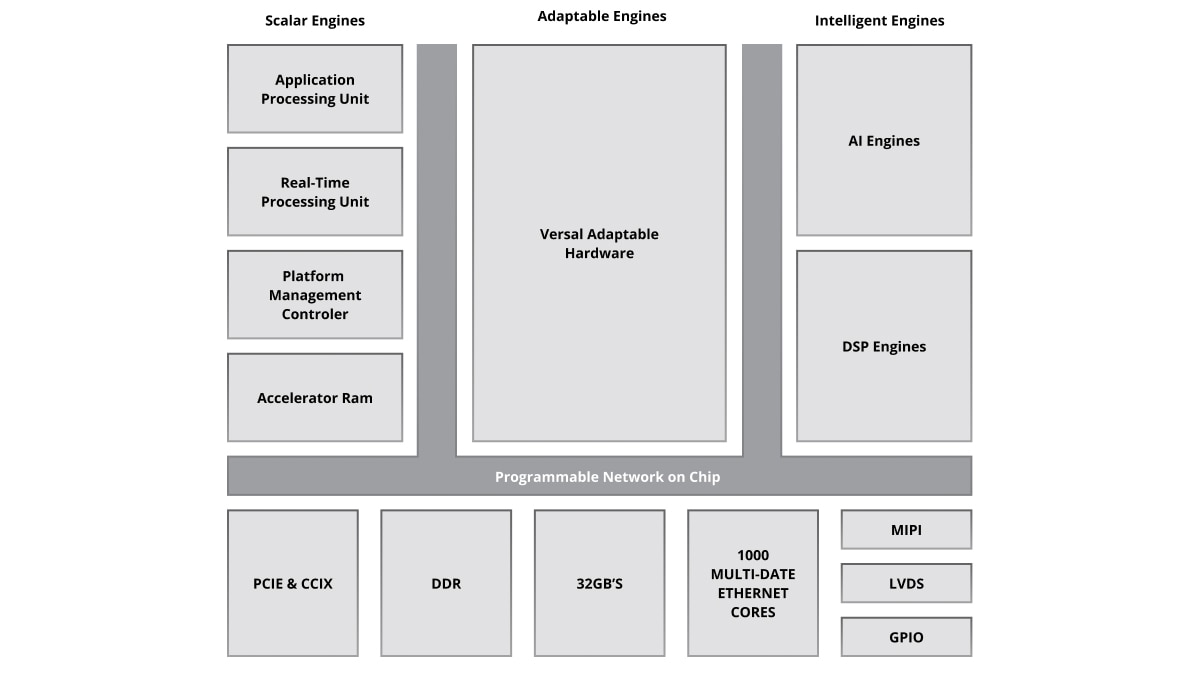
AMD Versal AI Core 系列通过 AI 引擎提供突破性的 AI 推理和无线加速,从而提供卓越的计算性能。作为 Versal 产品组合中计算性能超强的器件,Versal AI Core 自适应 SoC 主要面向以下四大核心应用场景:数据中心计算、无线通信波束成形、视频图像处理以及无线测试设备。

在 5G 通信、数据中心、汽车电子及工业应用等快速演变的市场中,各类应用在追求持续提升计算加速性能的同时,还必须保持优异的能效表现。随着摩尔定律和登纳德缩放比例定律不再遵循其传统发展规律,只向新一代芯片节点发展,就不能像前几代产品那样,以更好的性能提供更低功耗及更低成本的优势。
为应对无线波束成形和机器学习推理等新一代应用的非线性需求增长,AMD 创新开发了 AI 引擎处理技术,将其作为 AMD Versal™ 架构的核心组件。
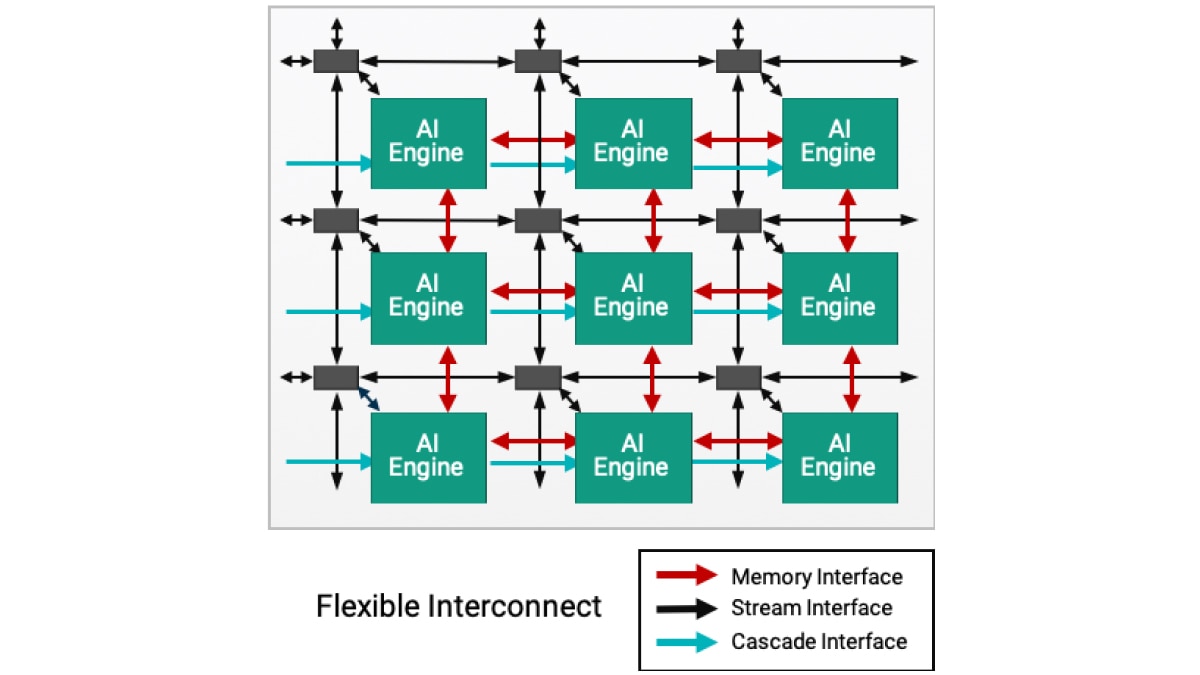
AI 引擎采用模块化二维阵列架构,由多个 AI 引擎计算单元组成,可在 Versal 产品组合中实现高度可扩展的解决方案,单个器件可集成数十至上百个 AI 引擎,全面满足各类应用场景的计算需求。产品优势包括:
对于高性能 DSP 应用,可使用以下方法对 AI 引擎进行编码(有关详细信息,请访问:AMD Vitis™ AI 引擎 DSP 设计)
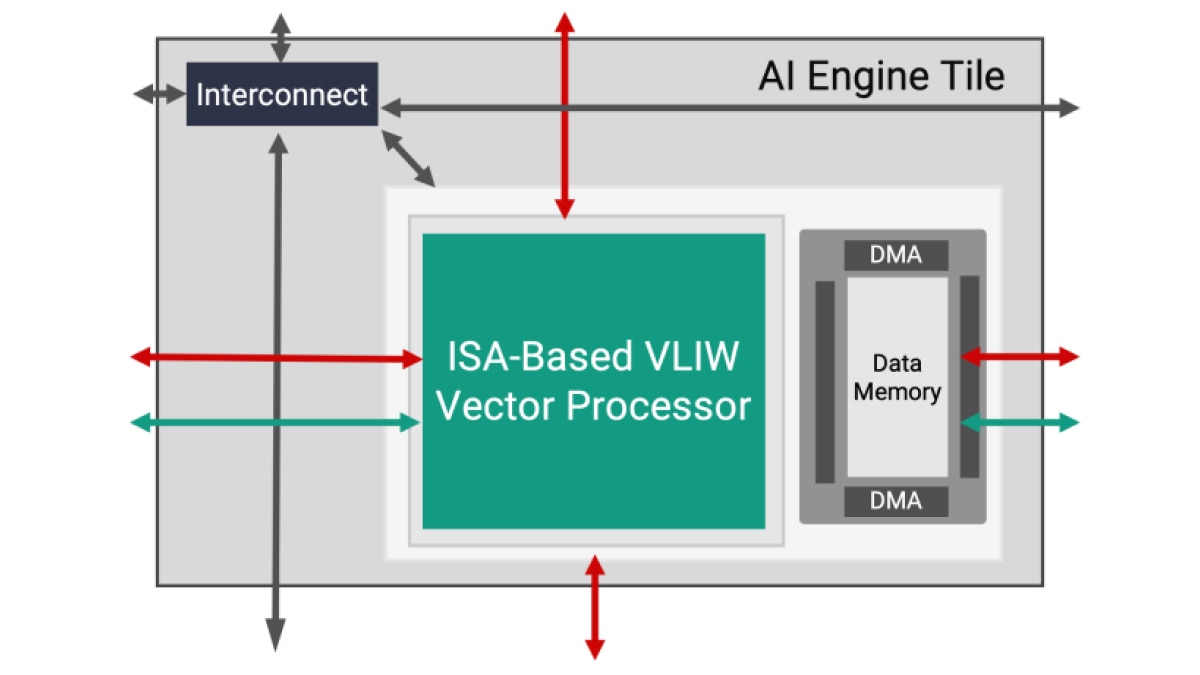
每个 AI 引擎计算单元由一个 VLIW(超长指令字)、SIMD(单指令多数据)矢量处理器组成,该矢量处理器针对机器学习和高级信号处理应用进行了优化。AI 引擎处理器运行频率高达 1.3GHz,能够实现极高效、高吞吐量和低延迟的各项功能。
每个计算单元不仅包含 VLIW 向量处理器,还包括用于存储必要指令的程序存储器;用于存储数据、权重、激活值和系数的本地数据存储器;一个 RISC 标量处理器以及用于处理不同类型数据通信的多种互连模式。
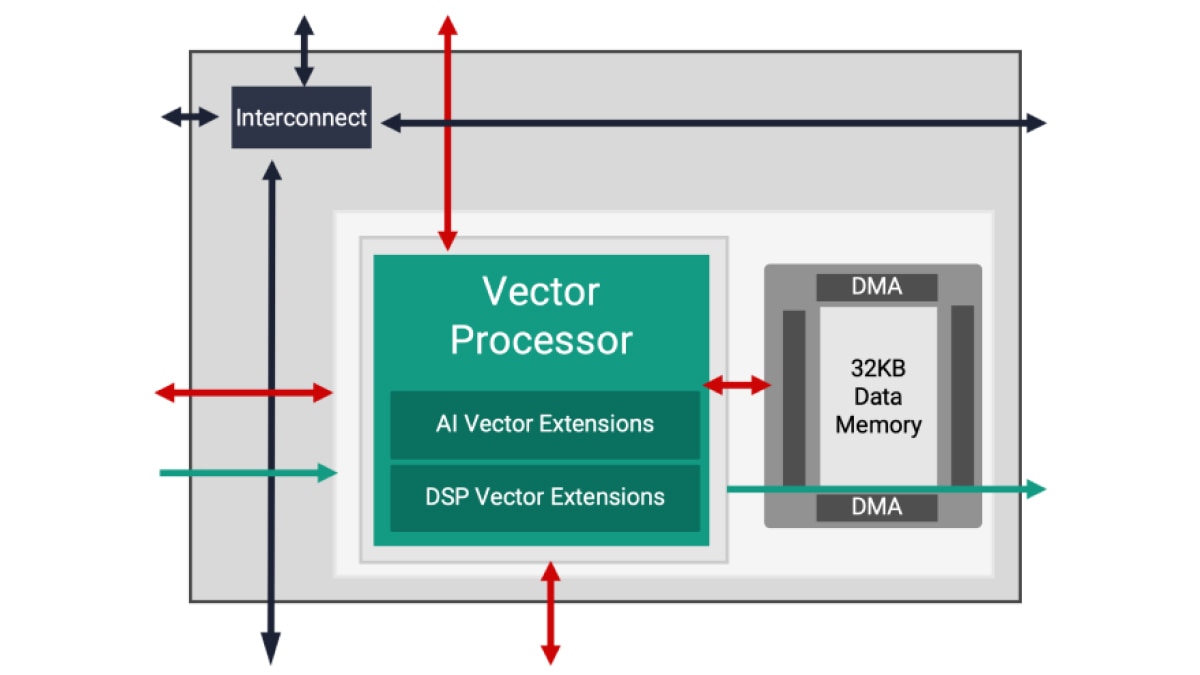
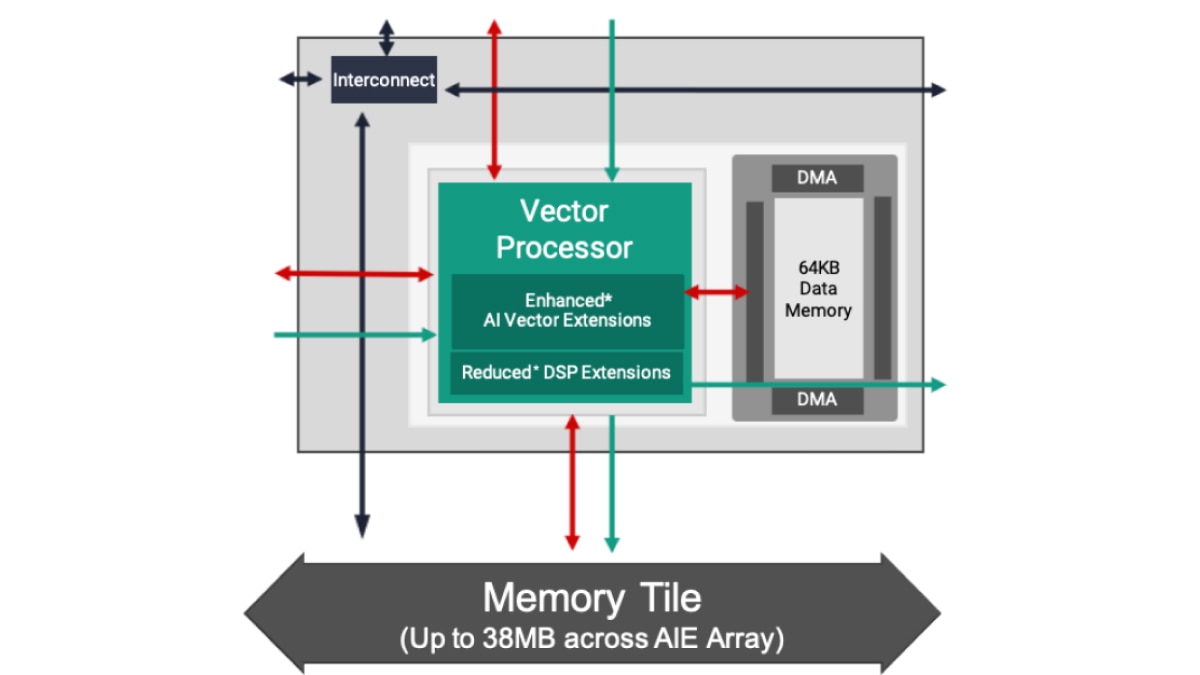
AMD 提供两种类型的 AI 引擎:AIE 和 AIE-ML(用于机器学习的 AI 引擎)均较前一代 FPGA 实现了显著的性能提升。AIE 可加速包括机器学习推理应用和高性能 DSP 信号处理工作负载(如波束成形、雷达以及其他需要大规模滤波和变换的工作负载)在内的多种工作负载。通过增强的 AI 向量扩展以及在 AI 引擎阵列中引入共享内存计算单元,AIE-ML 在专注于 ML 推理的应用中表现出比 AIE 更优越的性能,而 AIE 在某些类型的高级信号处理方面,则可能比 AIE-ML 表现更佳。
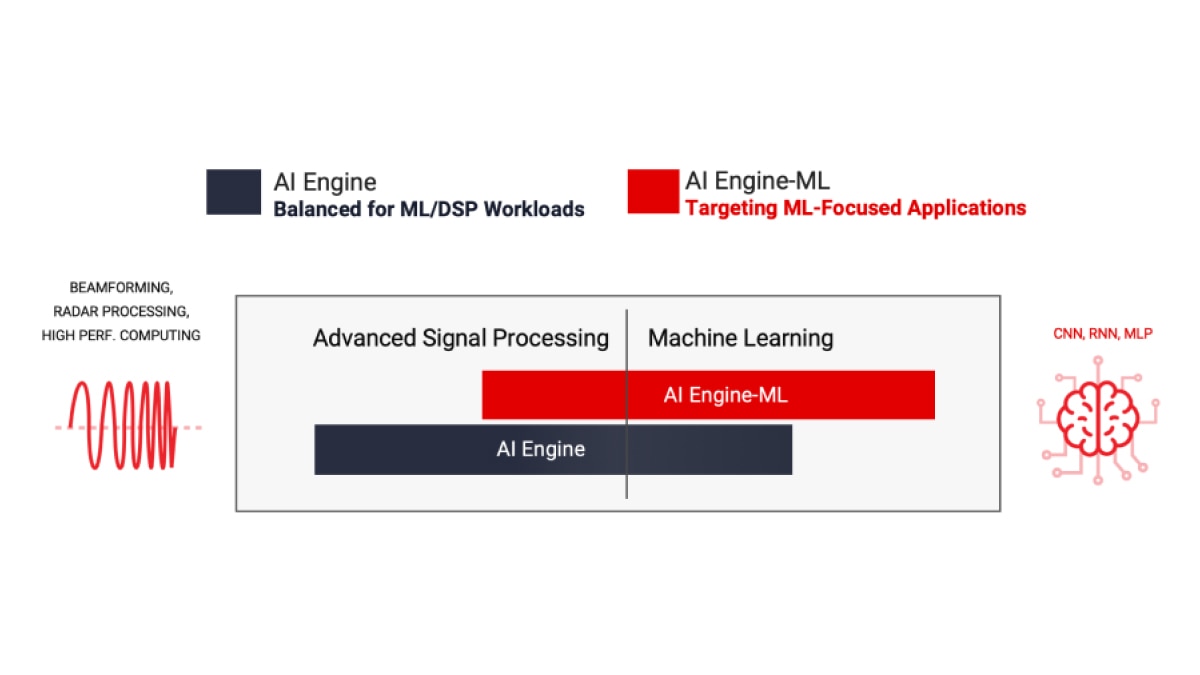
AIE 可加速一组均衡的工作负载,包括机器学习推理应用,以及波束成形、雷达、FFT 和滤波器等高级信号处理工作负载。
请参阅 AMD Versal AI Engine 架构手册以了解更多信息。
*BFLOAT16 使用 FP32 矢量处理器实现。
AI Engine-ML 架构针对机器学习进行了优化,全面增强计算核心和存储器架构。这些经过优化的计算单元兼具机器学习和高级信号处理能力,它们降低了对 INT32 和 CINT32 的支持(在雷达处理中普遍存在),目的是强化专注于机器学习的应用。
AIE-ML 将提供两个版本:AIE-ML(与 AIE 相比,计算能力翻了一番)和 AIE-MLv2(与 AIE-ML 相比,计算能力翻了一番),并且增加了流互连之间的额外带宽。
**AIE-ML 的 FP32 软件仿真支持。
AI 引擎与可编程逻辑单元及处理系统共同构成 Versal 自适应 SoC 中紧密集成的异构架构,该架构支持硬件与软件层面的动态重构,可灵活适应多样化应用场景与工作负载需求。
Versal 架构采用原生软件可编程设计,集成灵活的每秒多太比特级片上可编程网络 (NoC),实现所有组件与关键接口的无缝互联,使该平台在启动时即可就绪,并且软件工程师、数据科学家及硬件开发者可轻松对其进行编程。
AI 引擎适用于各种异构工作负载,从无线处理到位于云端、网络和边缘的机器学习,无所不包
数据中心计算
图像和视频分析是数据中心数据爆炸式增长的核心。这些工作负载的卷积神经网络 (CNN) 特性需要数量庞大的计算,通常达数万亿次。AI 引擎经过专门优化,能够以高成本效益与高能效比实现卓越的计算密度。
5G 无线处理
5G 能够以极低的时延提供前所未有的吞吐量,因此需要显著增加信号处理。AI 引擎可在无线电单元 (RU) 和分布式单元 (DU) 中以更低功耗执行实时信号处理,例如通过大规模 MIMO 天线阵列中的先进波束成形技术来提升网络容量。
ADAS 和自动驾驶
CNN 是一种深度前馈人工神经网络,常用于分析视觉图像。随着计算机广泛用于从自动驾驶汽车到视频监控的各个领域,CNN 现已变得至关重要。AI 引擎能够为具有紧凑散热封装的小尺寸规格,提供所需的高计算密度和效率。
工业
工业应用(包括机器人和机器视觉)通过结合传感器融合与 AI/ML 技术,在边缘侧靠近数据源头完成实时数据处理。尽管环境存在不确定性,但 AI 引擎仍能提高这些实时系统的性能和可靠性。
无线测试设备
实时 DSP 被广泛用于无线通信测试设备中。AI 引擎架构能够很好地处理各种协议的实现,包括从数字前端到波束成形和基带的 5G 应用。
医疗
利用 AI 引擎的医疗应用包括:用于医疗超声的高性能并行波束成形器、用于 CT 扫描仪的反向投影、MRI 设备中图像重建的分载,以及各种临床和诊断应用中的辅助诊断。
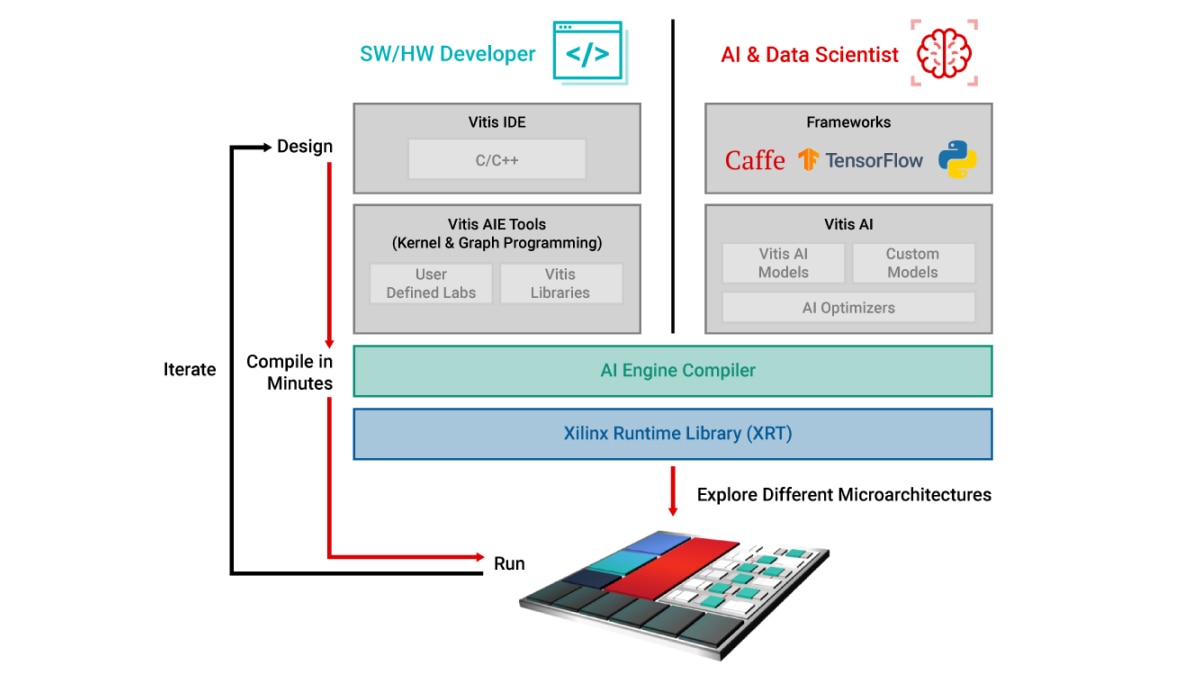
AI 引擎采用原生设计理念,兼具软件可编程性与硬件可适配性。为充分发挥这些计算引擎的性能优势,开发者可采用两种独特的设计流程,既能实现分钟级编译,又可快速探索不同微架构方案。这两种设计流程包括:
AI 引擎阵列还能够以一种优化资源和功耗的方式,实现高性能 DSP 功能的部署。通过将 AI 引擎与 FPGA 结构资源结合使用,能够非常高效地实现高性能 DSP 应用。了解如何使用 AMD Vitis 工具流程释放 AI 引擎在 DSP 应用中的硬件加速潜能:AMD Vitis AI Engine DSP 设计
利用 Vitis 加速库,AMD 提供预构建的内核,旨在实现:
软件和硬件开发者可以直接编程基于矢量处理器的 AI 引擎,并在需要时,使用 C/C++ 代码调用预构建的库。
AI 数据科学家可以继续在他们熟悉的框架环境(如 PyTorch 或 TensorFlow)中工作,并通过 Vitis AI 调用预构建的 ML 覆盖层,从而避免直接编程 AI 引擎。
这些库是开源的,可在 GitHub 上获取:https://github.com/Xilinx/Vitis_Libraries。
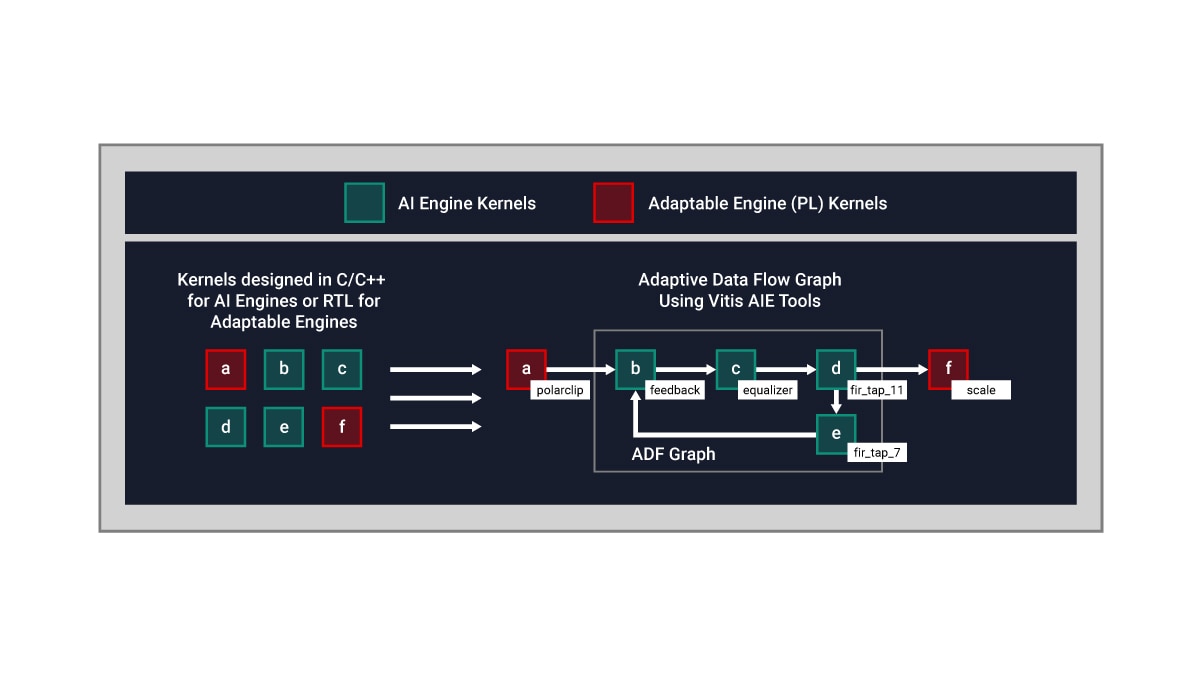
AI 引擎架构基于数据流技术。处理元件以 10 至 100 个阵列片 (tile) 的规模组成,可通过统一编程模型实现跨计算单元的协同运算。若要求设计人员手动为每个阵列片 (tile) 编写并行化指令,不仅繁琐且几乎不可行。为突破这一技术瓶颈,AI 引擎设计分两阶段执行:先进行单个内核开发,然后通过自适应数据流 (ADF) 图创建,将这些内核连接在整个应用中。
Vitis Unified IDE 提供单一 IDE 控制平台,支持通过 C/C++ 代码开发 AI 引擎内核,并集成 ADF 图设计功能。具体而言,设计人员可以:
默认情况下,单个内核运行在单个 AI 引擎计算单元上。然而,多个内核可在同一 AI 引擎阵列片 (tile) 上分时运行(只要应用允许)。
下面是一个概念示例:
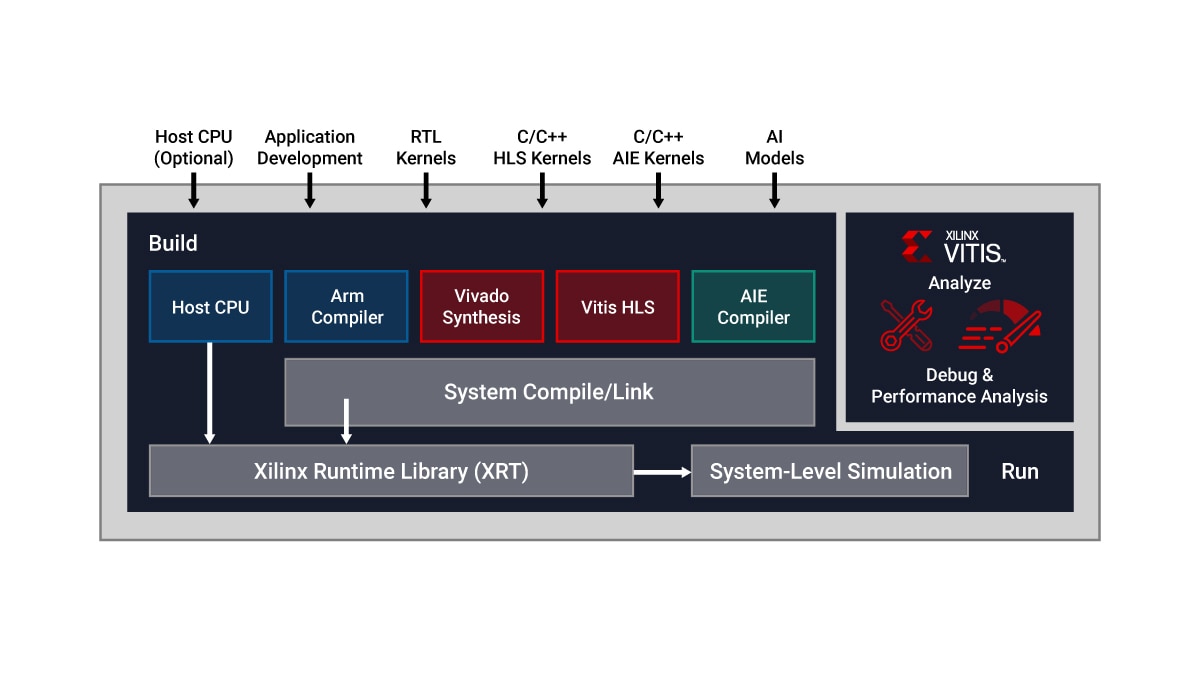
借助 Vitis Unified IDE,AI 引擎设计可以集成到一个更大的完整系统中,该系统将设计的各个组成部分整合到一个统一的流程中,从而实现仿真、硬件仿真、调试和部署。

VEK280 评估套件配备 Versal AI Edge VE2802 自适应 SoC,不仅提供 AIE-ML 及 DSP 硬件加速引擎,而且还提供多种高速连接选项。该套件针对汽车、视觉、工业、科学以及医疗等市场的机器学习推理应用进行了优化。

VCK190 评估套件让设计人员能够开发基于 AI 和 DSP 引擎的解决方案,这些引擎的计算性能比现有服务器级 CPU 高出 100 倍以上。Versal AI Core 系列 VC1902 器件,凭借广泛的连接选项和标准化的开发流程,能够为云、网络和边缘应用提供 Versal 产品组合中最高的 AI 推理和信号处理吞吐量。
AMD Vitis 统一软件平台提供了全面的内核开发套件与库,助力更好地利用硬件加速技术。
访问 Vitis GitHub 和 AI 引擎开发资源库以获得各种 AI 引擎教程,并了解有关技术特性和设计方法的更多信息。
AI 引擎工具(编译器和仿真器)都集成在 Vitis IDE 中,需要额外的专用许可证。有关如何访问 AI 引擎工具和许可证的更多信息,请联系您当地的 AMD 销售代表,或查看联系销售人员表单。
AMD Vitis Model Composer 是一款基于模型的设计工具,可在 Simulink® 和 MATLAB® 环境中实现快速的设计探索。它支持在系统级进行 AI 引擎 ADF 图的开发与测试,使用户能够在同一仿真环境中将 RTL 和 HLS 模块与 AI 引擎内核及/或计算图集成。利用 Simulink 和 MATLAB 工具中的信号生成和可视化功能,DSP 工程师可以在熟悉的环境中进行设计和调试。要了解如何将 Versal AI Engine 与 Vitis Model Composer 配合使用,请访问 AI 引擎资源页面。
VCK190 套件基于 Versal AI Core 系列,使设计人员能够使用 AI 引擎和 DSP 引擎开发解决方案。此评估套件拥有快速启动设计所需的全部组件。
此外还提供基于 PCIe® 的 VCK5000 开发卡,该卡搭载内置 AI 引擎的 Versal AI Core 器件,专为数据中心高吞吐量 AI 推理而设计。
为了进行 AIE-ML 的开发,基于 Versal AI Edge 系列的 VEK280 评估套件将为开发者提供开发 DSP 和机器学习应用的能力。
AMD 培训和学习资源提供了实用的实践技能和基础知识,可助力开发者在下一个 Versal 自适应 SoC 开发项目中充分发挥生产力。课程包括:
从解决方案规划到系统集成与验证,AMD 为全套 Versal 自适应 SoC 文档提供定制化视图,助力用户设计效率最大化。访问 Versal 自适应 SoC 设计流程中心,获取满足您设计需求的最新内容,并探索 AI 引擎功能和设计方法。
加入自适应 SoC 和 FPGA 通知列表,及时接收最新动态与资讯。