Versal™ AI コア シリーズ
AMD Versal AI コア シリーズは、優れた演算性能を発揮する AI エンジンにより、革新的な AI 推論処理とワイヤレス アクセラレーションを実現します。Versal 製品ポートフォリオの中で最も高い演算能力を備えており、Versal AI コア アダプティブ SoC は、データセンター コンピューティング、ワイヤレス ビームフォーミング、ビデオ/画像処理、ワイヤレス テスト装置などのアプリケーションに最適です。

5G セルラー、データセンター、オートモーティブ、インダストリアルなど、急速に進化している多くの市場では、電力効率を維持しながら、演算処理を高速化させる技術が求められています。ムーアの法則やデナード スケーリングが限界を迎えた現在では、次世代シリコン ノードへ進化するだけでは、かつての世代のように高性能、低コスト、低消費電力のメリットを得ることができません。
ワイヤレス ビームフォーミングや機械学習推論など、次世代アプリケーションによるこのような非線形な需要の増加に対応するため、AMD Versal™ アーキテクチャの一部となる革新的プロセッシング技術の AI エンジンを開発しました。
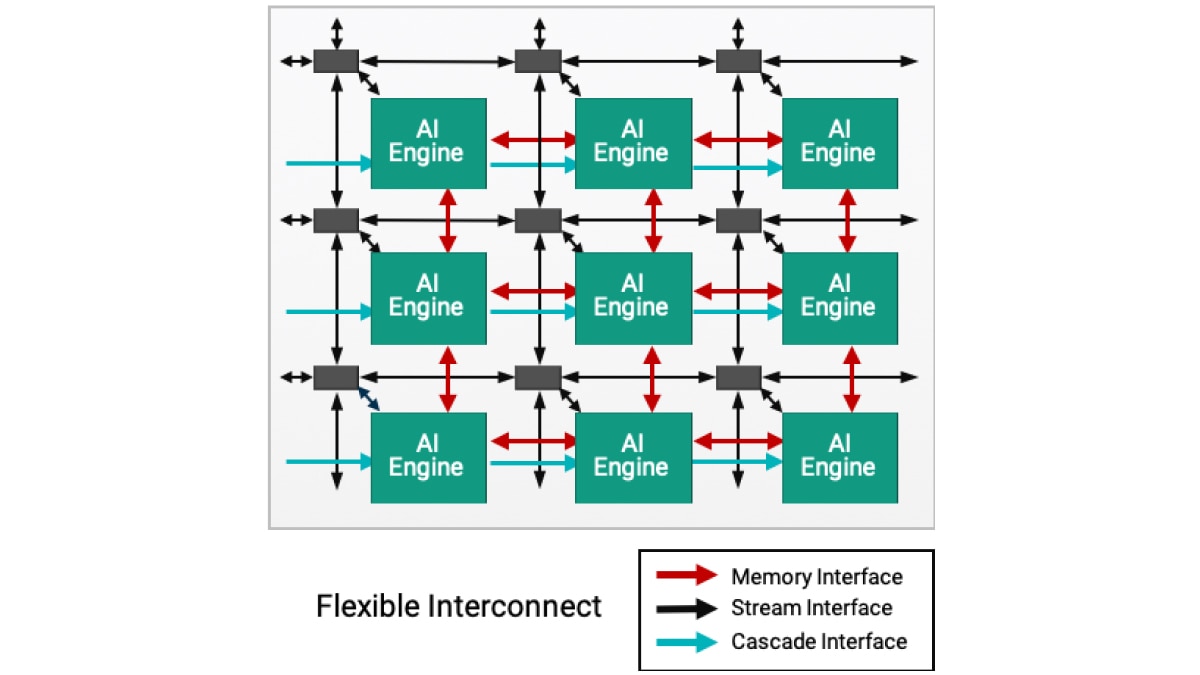
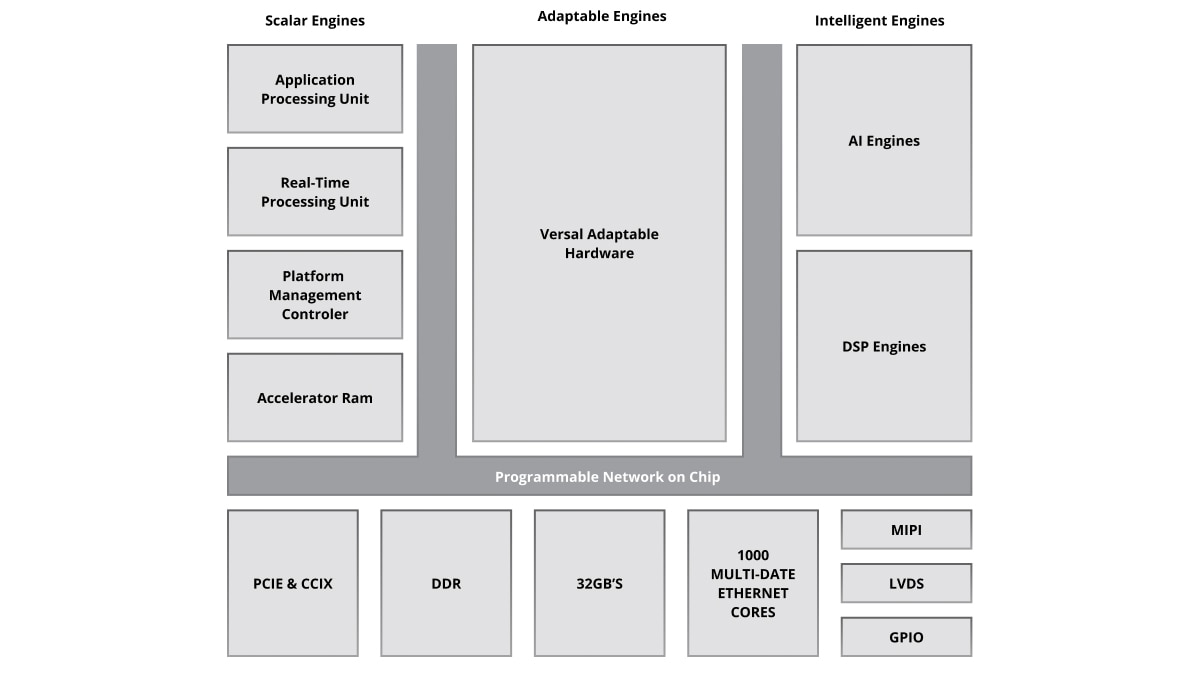
AI エンジンは、複数の AI エンジン タイルを二次元に配列したものです。単一デバイスに数十から数百個の AI エンジンを搭載した Versal ポートフォリオを利用することで、多様なアプリケーションの演算要件に応えることができ、拡張性も備えることができます。メリットは以下のとおりです。
高性能 DSP アプリケーション向けに、AI エンジンをコーディングする手法として次のオプションがあります (詳細は「AMD Vitis™ AI エンジンを活用する DSP デザイン」を参照)。
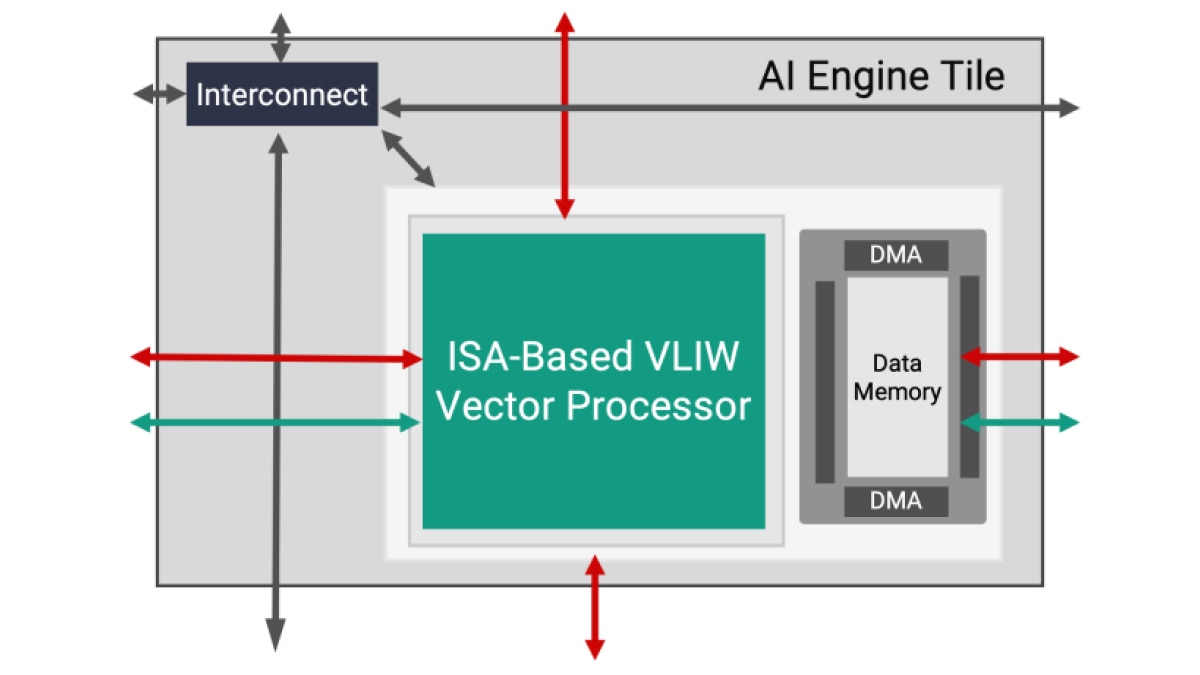
各 AI エンジン タイルは、機械学習や高度な信号処理アプリケーション向けに最適化された、VLIW (超長命令語) および SIMD (単一命令複数データ) 型のベクトル プロセッサで構成されています。AI エンジンのプロセッサは、最大 1.3 GHz で動作するため、非常に効率的で高スループットかつ低レイテンシの機能を実現できます。
各タイルには VLIW ベクター型プロセッサのほかに、必要な命令を格納するプログラム メモリ、データ、重み、アクティベーションや、係数を格納するローカル データ メモリ、RISC スカラー プロセッサ、さらには多様なデータ通信に対応するためのさまざまなモードのインターコネクトが含まれます。
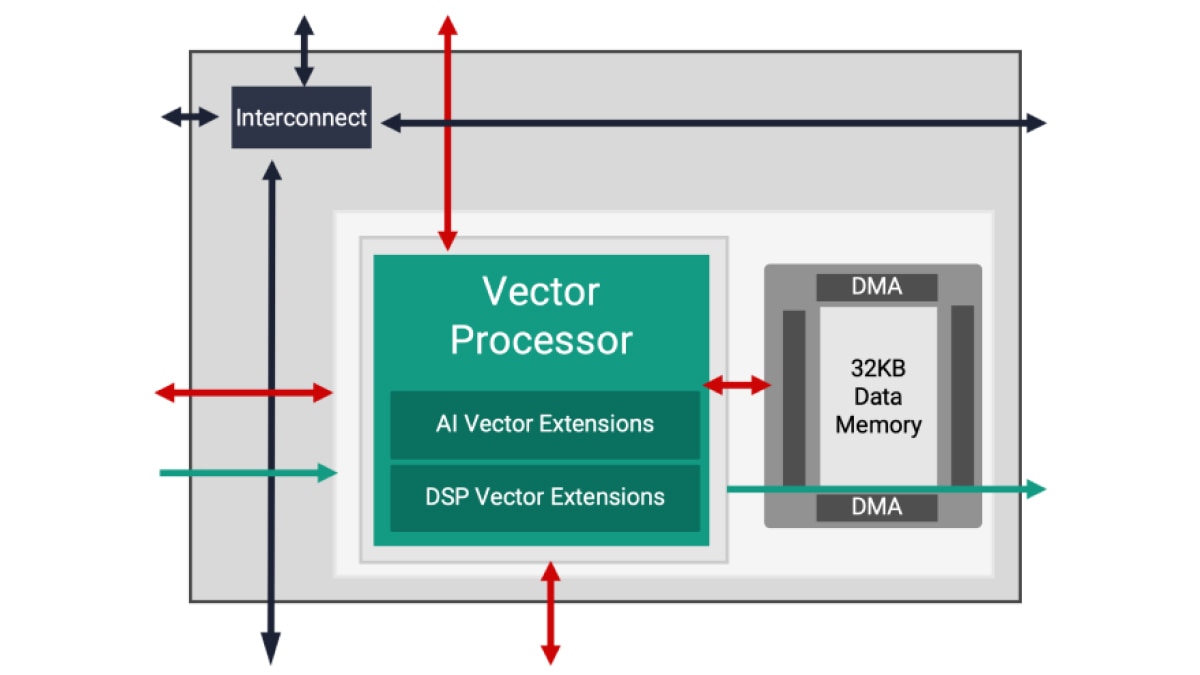
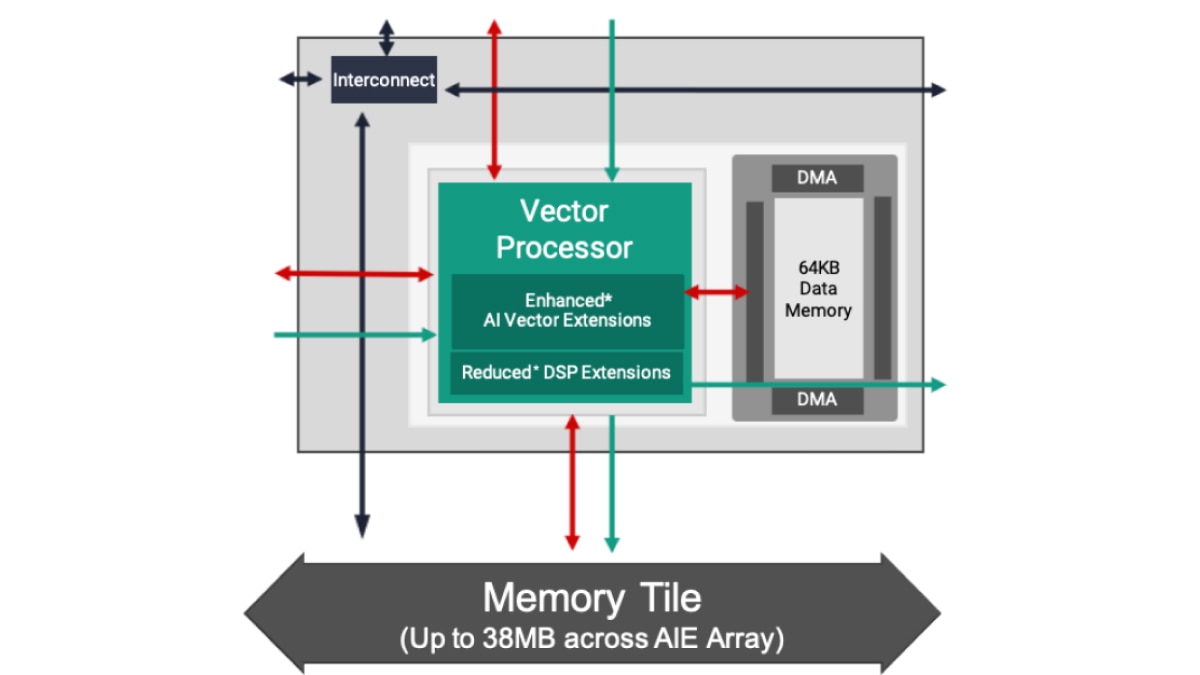
AMD は、AIE と AIE-ML (機械学習用 AI エンジン) の 2 種類の AI エンジンを提供しており、いずれも前世代 FPGA より優れた性能を提供します。AIE は、ML 推論アプリケーションのワークロードから、ビームフォーミングやレーダーなど大量のデータ フィルタリングや変換を必要とする高性能 DSP 信号処理ワークロードまで、より広範なワークロードを高速化できます。強化された AI のベクター拡張機能と AI エンジン アレイ内における共有メモリ タイルの採用によって、AIE-ML は ML 推論に特化したアプリケーションにおいては AIE より優れた性能を発揮します。一方で AIE は特定種類の高度な信号処理においては AIE-ML より優れた性能を発揮します。
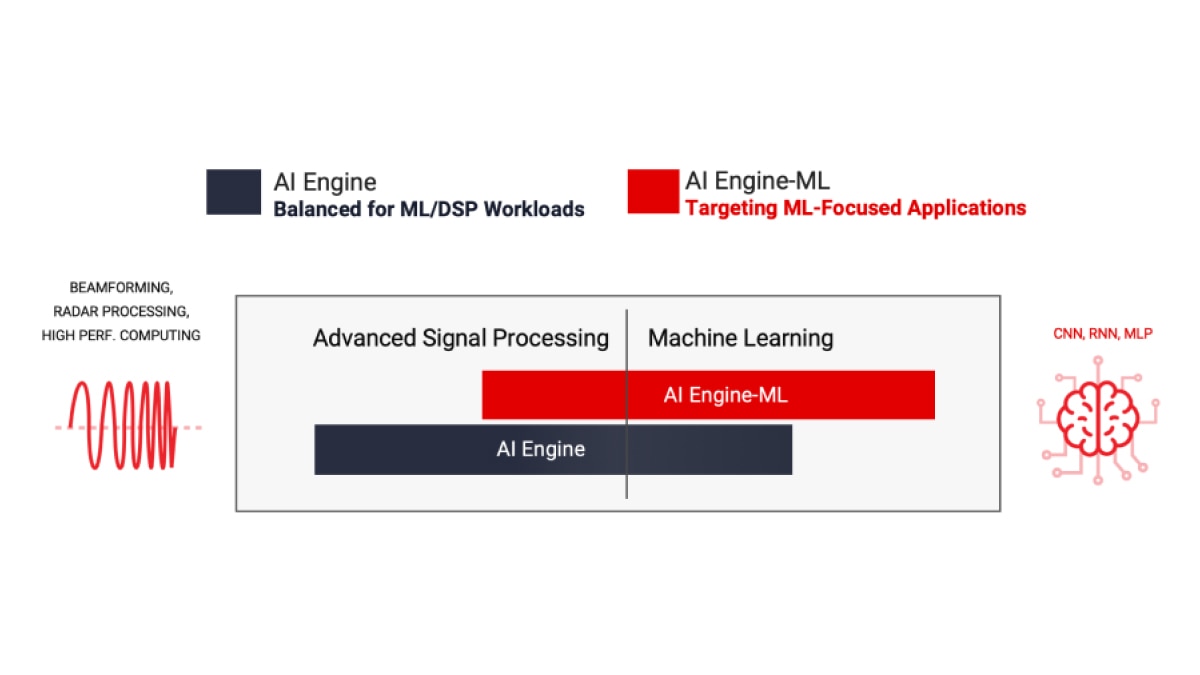
AIE は、AL 推論アプリケーションのワークロードや、ビームフォーミング、レーダー、FFT、フィルタリングなどの高度な信号処理ワークロードまで広範なワークロードを高速化できます。
詳細は、AMD Versal AI Engine アーキテクチャ マニュアルを参照してください。
*BFLOAT16 は FP32 ベクター プロセッサを使用して実装されています。
AI エンジン-ML のアーキテクチャは、演算コアとメモリ アーキテクチャの両方を重視し、機械学習に最適化されています。ML と高度な信号処理の両方に対応できますが、レーダー処理で一般的な INT32 と CINT32 のサポートを排除して最適化されているため、ML に特化したアプリケーションで高性能を発揮します。
AIE-ML は 2 種類のバージョンで提供しています。AIE の 2 倍の演算性能を持つ AIE-ML、そして AIE-ML の 2 倍の演算性能に加えて、ストリーム インターコネクト間の帯域幅を強化した AIE-MLv2 を利用可能です。
** AIE-ML FP32 をサポートする SW エミュレーション。
AI エンジンは、プログラマブル ロジックやプロセッシング システムと連携し、Versal アダプティブ SoC 内で高い統合性を持つヘテロジニアス アーキテクチャを構成しています。このアーキテクチャは、ハードウェアとソフトウェアの両レベルで変更可能であり、さまざまなアプリケーションやワークロードのニーズに動的に対応できます。
Versal アーキテクチャは、ネイティブにソフトウェア プログラマビリティを備えるようゼロから構築されています。柔軟なマルチテラビット/秒のプログラマブル ネットワーク オン チップ (NoC) ですべてのコンポーネントと主要インターフェイスをシームレスに統合することで、ソフトウェア開発者、データ サイエンティスト、ハードウェア開発者は起動してすぐに利用でき、簡単にプログラムできるようになっています。
クラウド、ネットワーク、エッジで無線処理から機械学習までのヘテロジニアス ワークロードに対応する AI エンジン
データセンターの演算
画像/ビデオの解析が、データセンターの処理量を爆発的に増加させています。たたみ込みニューラル ネットワーク (CNN) を使用するワークロードでは、膨大な計算量を要し、数テラ OPS に達する場合も少なくありません。AI エンジンは、この演算密度を優れたコスト効率と消費電力効率で実現できるように最適化されています。
5G の無線処理
5G は、極めて低いレイテンシで最高クラスのスループットを提供できるため、信号処理にかかる負荷が大幅に増加します。AI エンジンは、Massive MIMO パネルで使用される高度なビームフォーミング技術のような信号処理を、低消費電力の無線ユニット (RU) や分散ユニット (DU) 内でリアルタイムに実行できます。これは、ネットワーク容量の拡大に貢献します。
ADAS および自動運転
画像解析には、たたみ込みニューラル ネットワーク (CNN) と呼ばれるフィード フォワード型のディープ ニューラル ネットワークが最もよく使用されます。自動運転車やビデオ監視などあらゆる用途にコンピューターが利用されるようになった現在、CNN は欠かせない技術となっています。AI エンジンは、温度に対する厳しい要件を満たす必要がある小型システムで必要とされる演算密度と効率を提供します。
航空宇宙/防衛
処理能力の優れたベクター型 DSP エンジンと AI エンジンを小型フォーム ファクターに搭載することで、フェーズド アレイ レーダー、早期警戒 (EW)、MILCOM、無人機などの A&D 分野の幅広いシステムを実現します。マルチミッション ペイロードの信号処理、信号調整、AI 推論などの多様なワークロードをサポートする AI エンジンは、これらのミッション クリティカル システムの厳しい SWaP (サイズ、重量、電力)要件を満たす演算効率を実現します。
産業用機器
ロボットやマシン ビジョンなどの産業用アプリケーションでは、センサー フュージョンに AI/ML 技術を組み合わせて、エッジ デバイスなどの情報発生源に近い場所でデータ処理を実行します。AI エンジンは、不確実性の高い現場環境にもかかわらず、このようなリアルタイム システムで高い性能と信頼性を提供します。
ワイヤレス テスト装置
ワイヤレス テスト装置には、リアルタイム DSP が広く使用されています。AI エンジンのアーキテクチャは、デジタル フロントエンドからビームフォーミングやベースバンドに至るまで、5G を含むあらゆるタイプのプロトコル実装に適しています。
ヘルスケア
AI エンジンを活用するヘルスケア アプリケーションには、超音波診断装置用の高性能並列ビームフォーマー、CT スキャナーの逆投影、MRI 装置の画像再構成技術のオフロード、さまざまな臨床/診断アプリケーションでの診断支援などがあります。
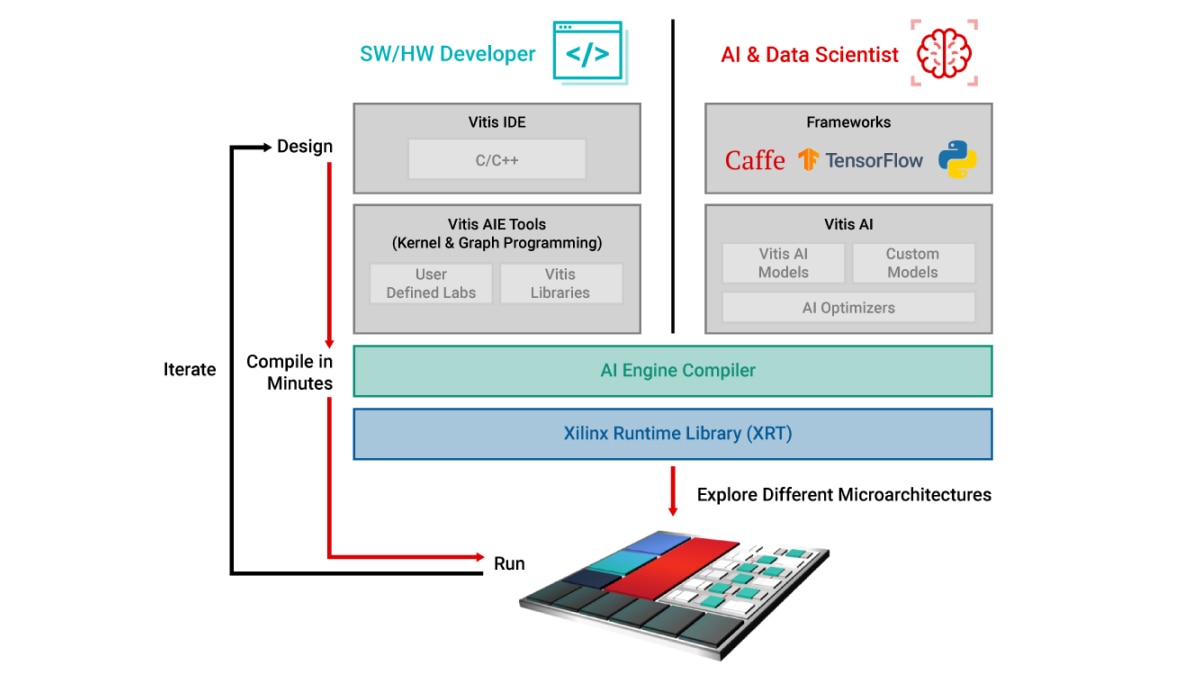
AI エンジンは、ソフトウェア プログラマブルとハードウェア アダプタブルを兼ね備えた革新的なエンジンです。開発者には、わずか数分でコンパイルを完了し、異なるマイクロアーキテクチャをすばやく探索しながら、これらの演算エンジンの性能を最大限に引き出すことができる 2 種類のフローがあります。2 つの設計フローは次のとおりです。
AI エンジン アレイは、リソースと電力を最適化しながら、高性能な DSP 機能のインプリメンテーションを可能にします。AI エンジンを FPGA ファブリック リソースと組み合わせて使用することで、高性能 DSP アプリケーションを非常に効率的に実装できます。AMD の Vitis ツール フローを使用して、DSP アプリケーション向け AI エンジンのハードウェア アクセラレーション機能を活用する方法を習得してください。AMD Vitis AI エンジンを活用する DSP デザイン
AMD の Vitis アクセラレーション ライブラリには、次のことを可能にする事前構築済みカーネルが含まれています。
ソフトウェア/ハードウェア開発者は、ベクター プロセッサベースの AI エンジンを直接プログラミングし、必要に応じて C/C++ コードのビルド済みライブラリを呼び出すことができます。
AI データ サイエンティストは、PyTorch や TensorFlow などの使い慣れたフレームワーク環境を使用して、AI エンジンを直接プログラミングしなくても、Vitis AI を介してビルド済みの ML オーバーレイを呼び出すことができます。
これらのライブラリはオープンソースで提供されており、GitHub (https://github.com/Xilinx/Vitis_Libraries) から入手できます。
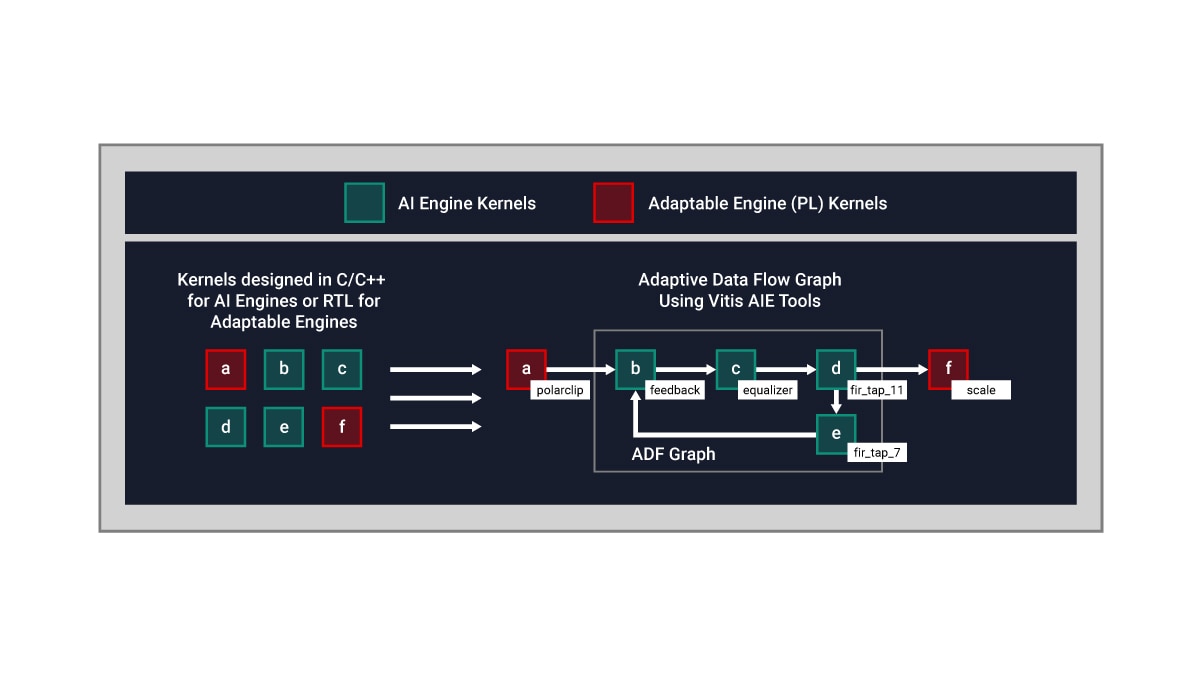
AI エンジンのアーキテクチャは、データフロー技術に基づいて構築されています。プロセッシング エレメント (PE) は、10 ~ 100 個のタイルが配列されたもので、演算ユニット全体にわたる 1 つのプログラムを作成します。こうしたタイル全体に対して並列処理を指定する指示子を埋め込む作業は設計者の手間がかかり、ほぼ不可能です。この問題を解決するために、AI エンジンの設計を 2 段階で行います。まず、1 つのカーネルを開発します。その後、ADF (適応型データフロー) グラフを作成して、複数カーネルをアプリケーション全体に接続します。
Vitis 統合 IDE では、C/C++ プログラミング コードを使用して AI エンジンのカーネルを開発したり、ADF グラフを設計したりできます。具体的には、次のことが可能になります。
デフォルトでは、1 つの AI エンジン タイル上で 1 つのカーネルが動作します。ただし、アプリケーションで許容される限り、同じ AI エンジン タイル上で複数カーネルを動作させて処理時間を短縮できます。
次に概念的な例を示します。
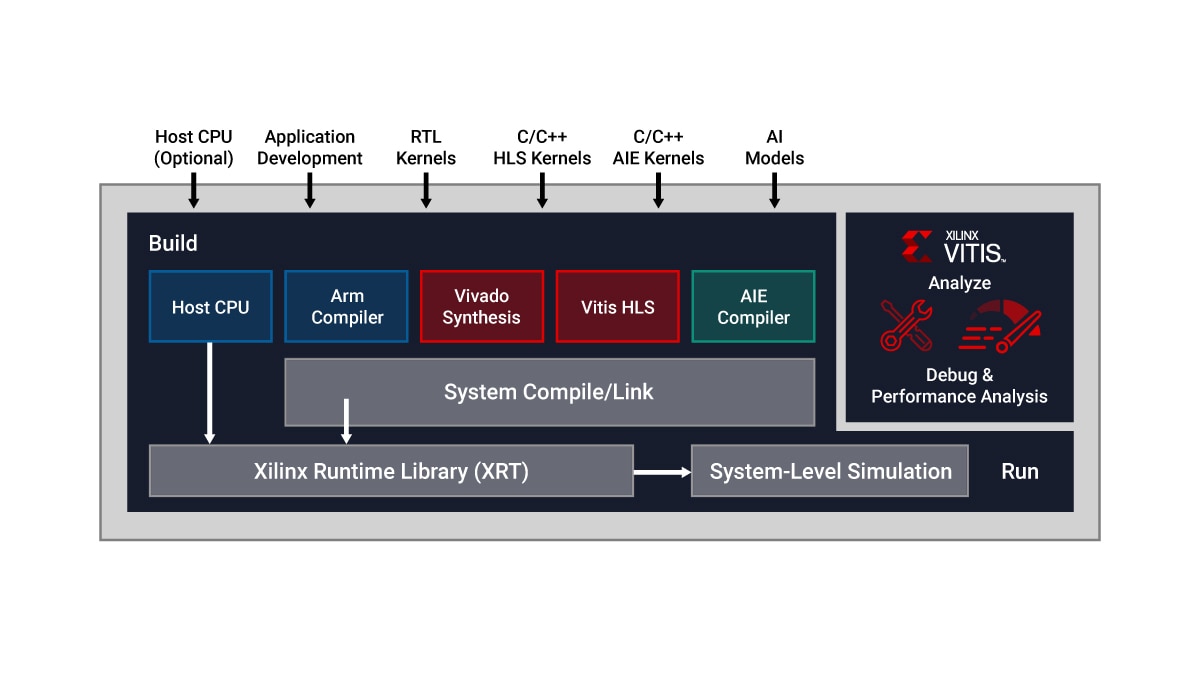
Vitis 統合 IDE を利用することで、大規模なシステムに AI エンジン デザインを統合できます。1 つの統合フローでシミュレーション、ハードウェア エミュレーション、デバッグ、運用までを実行できます。

Versal AI エッジ VE2802 アダプティブ SoC が搭載されている VEK280 評価キットには、AI エンジン ML や DSP ハードウェア アクセラレーション エンジンが含まれており、複数の高速接続オプションを利用できます。このキットは、オートモーティブ、ビジョン、航空宇宙/防衛、産業、科学、医療などの市場における ML 推論アプリケーション向けに最適化されています。

VCK190 評価キットは、現在のサーバー クラスの CPU と比べて 100 倍以上の演算性能を実現可能な AI エンジンおよび DSP エンジンを活用したソリューションの開発を支援します。豊富な接続オプションと標準化された開発フローでサポートされた Versal AI コア シリーズの VC1902 デバイスは、クラウド、ネットワーク、エッジ アプリケーション向けに、Versal 製品ポートフォリオの中で最高レベルの AI 推論および信号処理スループットを提供します。
AMD の Vitis 統合ソフトウェア プラットフォームは、ハードウェア アクセラレーション テクノロジを使用する、包括的なコア開発キットとライブラリを提供します。
Vitis GitHub および AI エンジン開発リポジトリでは、AI エンジンに関するさまざまなチュートリアルが公開されており、テクノロジの詳細や設計手法について理解を深めることができます。
コンパイラとシミュレータを含む AI エンジン ツールは、Vitis IDE に統合されており、追加のライセンスが必要です。AI エンジン ツールおよびライセンスへのアクセス方法の詳細は、AMD 営業担当者へお問い合わせいただくか、お問い合わせフォームをご利用ください。
AMD Vitis Model Composer は、Simulink® および MATLAB® 環境でデザインを短時間で試行できるモデル ベースのデザイン ツールです。これにより、RTL および HLS ブロックを AI エンジン カーネルやグラフと一体化させて同じシミュレーションに組み込むことができるため、AI エンジン ADF グラフ開発やシステム レベルでのテストが効率化されます。DSP エンジニアは、Simulink や MATLAB ツールの信号生成や可視化機能を活用できるため、使い慣れた環境で設計やデバッグが可能になります。Vitis Model Composer で Versal AI Engine を活用する方法については、AI エンジンのリソース ページをご覧ください。
Versal AI コア シリーズをベースとした VCK190 キットは、AI エンジンおよび DSP エンジンを活用したソリューションの開発を可能にします。この評価キットには、設計を始めるために必要なものがすべて含まれています。
PCIe® ベースの VCK5000 開発カードもご利用いただけます。これには、データセンターの高スループット AI 推論用に構築された AI エンジンを備える Versal AI コア デバイスが搭載されています。
AIE-ML 開発向けの VEK280 評価キットは、Versal AI エッジ シリーズをベースとしており、DSP や ML アプリケーションの開発が可能になります。
AMD のトレーニングおよび学習リソースは、開発者が次回の Versal アダプティブ SoC 開発プロジェクトで十分な生産性を発揮するために必要な実践的スキルと基礎知識を提供します。対象コースは次のとおりです。
ソリューション計画から、システム統合、検証まで、AMD は設計の生産性を最大限に高めるために、Versal アダプティブ SoC 関連の膨大な資料の中から必要なリソースをカスタマイズして提供します。Versal アダプティブ SoC デザイン プロセス ハブにアクセスして、設計のニーズに合った最新のコンテンツを入手し、AI エンジンの機能および設計手法の詳細をご覧ください。
アダプティブ SoC/FPGA の通知リストに登録された方には、最新情報をいち早くお届けします。