Aprendizado profundo com otimização de INT8 em dispositivos AMD
A arquitetura DSP integrada da AMD pode alcançar um desempenho de nível de solução 1,75 vez maior em operações de aprendizagem profunda INT8 do que outras arquiteturas de DSP de FPGA.

Com sua flexibilidade inerente, os SoCs adaptativos e as FPGAs (Field-Programmable Gate Arrays, Matrizes de portas programáveis em campo) da AMD são ideais para aplicativos de DSP (Digital Signal Processing, Processamento de sinal digital) de alto desempenho ou multicanal, que podem aproveitar o paralelismo de hardware. Os SoCs adaptativos e as FPGAs da AMD combinam essa largura de banda de processamento com soluções abrangentes, incluindo ferramentas de projeto fáceis de usar para projetistas de hardware, desenvolvedores de software e arquitetos de sistema.
Paralelismo de hardware
Uma arquitetura DSP Von Neumann padrão requer 256 ciclos para concluir um filtro FIR de 256 toques, enquanto os SoCs adaptativos e as FPGAs podem alcançar o mesmo resultado em um único ciclo do clock.
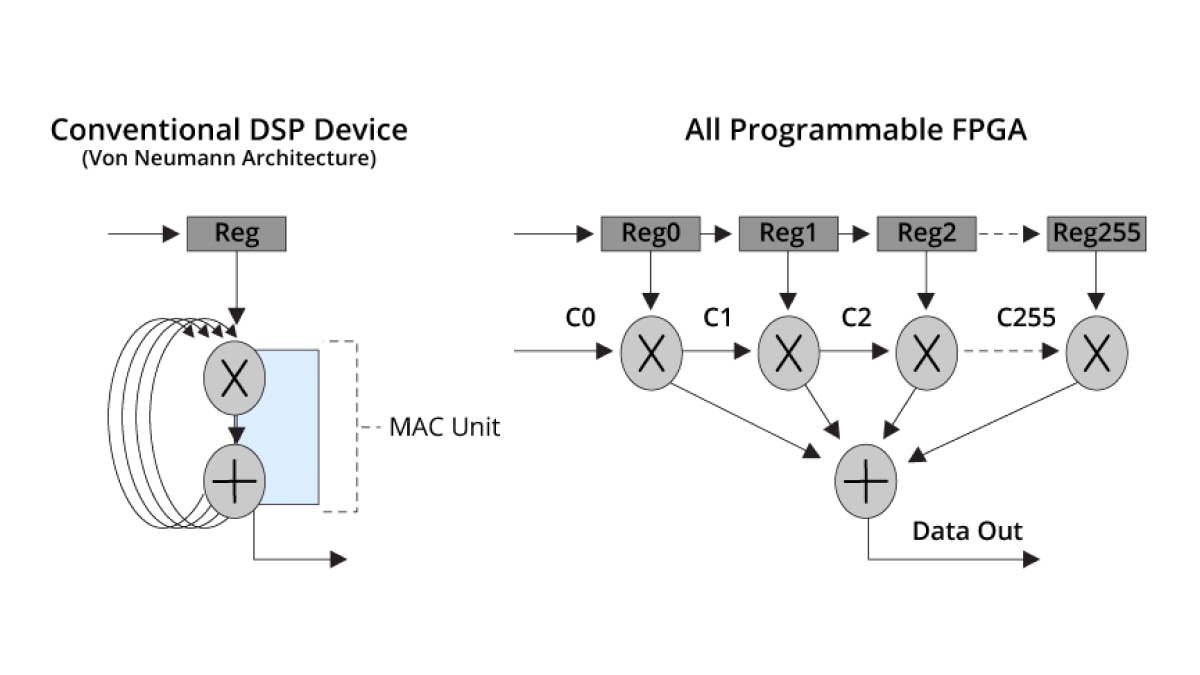
Esse grande paralelismo se traduz em níveis excepcionais de desempenho de DSP:
Soluções de DSP abrangentes
As soluções de DSP da AMD incluem chip, IP, projetos de referência, placas de desenvolvimento, ferramentas, documentação e treinamento para permitir uma ampla variedade de aplicações em diversos mercados, incluindo, entre outros, comunicações sem fio, data centers e aeroespacial e defesa.
Fluxos de desenvolvimento abrangentes
Vários fluxos de ferramentas estão disponíveis para diferentes modelos de uso e diferentes níveis de abstração de projeto:
Os projetistas de hardware podem trabalhar em:
Os desenvolvedores de software acostumados a desenvolver em C/C++ podem projetar usando:
Os arquitetos de sistema podem avaliar rapidamente novos algoritmos com:
Com os SoCs adaptativos e as FPGAs da AMD, os projetistas podem usar vários fluxos para implantar seus aplicativos de DSP, dependendo da abordagem do projeto e do nível de abstração.
Em muitos mercados de DSP dinâmicos e em evolução, como aeroespacial, defesa, automotivo/industrial e teste/medição, as aplicações estão aumentando cada vez mais a aceleração de computação de DSP, mantendo a eficiência de energia.
Como a Lei de Moore e o Escalonamento de Dennard não seguem mais a sua trajetória tradicional, a migração para a próxima geração de nós de silício, por si só, não pode mais garantir os benefícios de menor consumo de energia e custo com melhor desempenho, como acontecia nas gerações anteriores.
Em resposta a esse aumento não linear na demanda por aplicativos de DSP de última geração, como canalização polifásica e beamforming, a AMD desenvolveu uma nova e inovadora tecnologia de processamento, o mecanismo de IA, como parte da arquitetura AMD Versal™.
Os mecanismos de IA são arquitetados como matrizes 2D que consistem em vários blocos de mecanismos de IA e permitem uma solução muito dimensionável em todo o portfólio Versal, variando de dezenas a centenas de mecanismos de IA em um único dispositivo, atendendo às necessidades de computação de uma ampla gama de aplicações.
Os benefícios incluem:
Com base em uma arquitetura de classe ASIC, os SoCs adaptativos e as FPGAs da AMD combinam largura de banda de E/S de centenas de gigabits por segundo com mais de 49 TeraMACs de desempenho de DSP de ponto fixo no Versal™ Série Premium. A fatia de DSP da AMD e seu paralelismo são fundamentais para o desempenho de DSP alcançável na última geração de FPGAs da AMD.
A fatia DSP58 nos dispositivos Versal é a 6ª geração de fatias de DSP nas arquiteturas AMD.
Este bloco dedicado de processamento de DSP é implementado em chip totalmente personalizado, proporcionando liderança em consumo de energia/desempenho e permitindo implantações eficientes de funções de DSP populares, como multiplicador-acumulador (MACC), multiplicador-somador (MADD) ou multiplicação complexa.
A fatia também fornece recursos para executar diferentes tipos de operações lógicas, como E, OU e operações XOR.
A arquitetura DSP58 do dispositivo Versal baseia-se no sucesso da FPGA UltraScale™ DSP48E2 com mais aprimoramentos:
Esses aprimoramentos ajudam os aplicativos críticos de DSP a executar mais computação dentro da fatia DSP48E2 antes de entrar na malha da FPGA, resultando em economia de recursos e energia.
| Função | UltraScale | Versal |
|---|---|---|
| Tipo de bloco/fatia de DSP | DSP48E2 | DSP58 |
| Múltiplas operações de adição/subtração/conta |  |
|
| Multiplier e MACC | 27x18 | 27x24 |
| Elevação ao quadrado: [(A ou B) +/- D]2 | |
|
| WMUX Feedback Ultra Efficient Complex Multiply CMACC | 3 DSP48E2 | 2 DSP58 |
| Suporte a SIMD | |
|
| Circuito integrado de detecção de padrão | |
|
| Unidade lógica integrada | |
|
| Funções Wide Mux | 48 bits | 58 bits |
| Wide XOR | 96 bits | 116 bits |
| Multiplier de ponto de flutuação de precisão única | |
|
| Saída opcional de 96 bits | |
|
| Roteamento em sequência | |
|
| Registros de pipeline | |
|
| Pre-somador D | |
|
| Multiplicação complexa sequencial, acesso AB Dyn | |
|
| Melhoria do balanceamento do pipeline de registros AB | |
|
Vídeos em destaque:
Dependendo das suas preferências de projeto, a AMD oferece ferramentas que suportam entrada de projeto baseada em RTL, C/C++ e modelos. Essa flexibilidade no fluxo do projeto, juntamente com um extenso catálogo de IP de DSP, facilita a adoção de ferramentas e dispositivos AMD.
Visite Ferramentas, bibliotecas e estruturas para obter mais informações.
A tabela a seguir mostra algumas das principais métricas de desempenho do DSP para as famílias da Série 7, UltraScale™ e UltraScale+™. Para saber mais sobre o desempenho do dispositivo SoC adaptativo, consulte a seção Desenvolvedor de software.
| Kintex UltraScale | Kintex UltraScale+ | Virtex UltraScale | Virtex UltraScale+ | Versal AI Core | Versal AI Edge | Versal AI Prime | Versal AI Premium | |
|---|---|---|---|---|---|---|---|---|
| Elementos lógicos do sistema (mil) | 318–1.451 | 356–1.143 | 783–5.541 | 862–3.780 | 540–1.968 | 44–1.139 | 329–2.233 | 833–7.352 |
| Fatias de DSP | 768–5.520 | 1.368–3.528 | 600–2.880 | 2.280–12.288 | 928–1.968 | 90–1.312 | 464–3.984 | 1.140–14.352 |
| Multipliers 27x18 | 768–5.520 | 1.368–3.528 | 600–2.880 | 2.280–12.288 | 928–1.968 | 90–1.312 | 464–3.984 | 1.140–14.352 |
| INT8 GOPs1 | 1.774–14.315 | 4.263–11.000 | 1.554–7.469 | 7.108–38.318 | 6.403–13.579 | 62–9.052 | 3.201–27.489 | 7.866–99.029 |
| INT16 GOPs | 1.014–8.180 | 2.436–6.286 | 888–4.268 | 4.062–21.896 | 2.134–4.526 | 21–3.017 | 1.067–9.163 | 2.622–33.010 |
| INT18 GOPs complexos | 676–5.453 | 1.624–4.191 | 592–2.845 | 2.708–14.597 | 913–1.937 | 8–1.291 | 456–3.920 | 1.122–14.122 |
| Ponto de flutuação de precisão única (GFLOPs)2 | 320–2.685 | 800–1.673 | 294–1.411 | 1.354–7.299 | 1.494–3.168 | 14–2.112 | 747–6.414 | 1.835–23.107 |
Introduzimos ambientes de desenvolvimento de software e um conjunto abrangente de ferramentas, bibliotecas e metodologias poderosas e familiares que permitem que os desenvolvedores de software direcionem os SoCs adaptativos e as FPGAs da AMD com facilidade. Com ambiente de abstração de alto nível, a plataforma de software unificada Vitis™. Podemos oferecer experiências de desenvolvimento e tempo de execução de aplicações incorporadas familiares e semelhantes à GPU para desenvolvimento em C, C++ e/ou OpenCL.
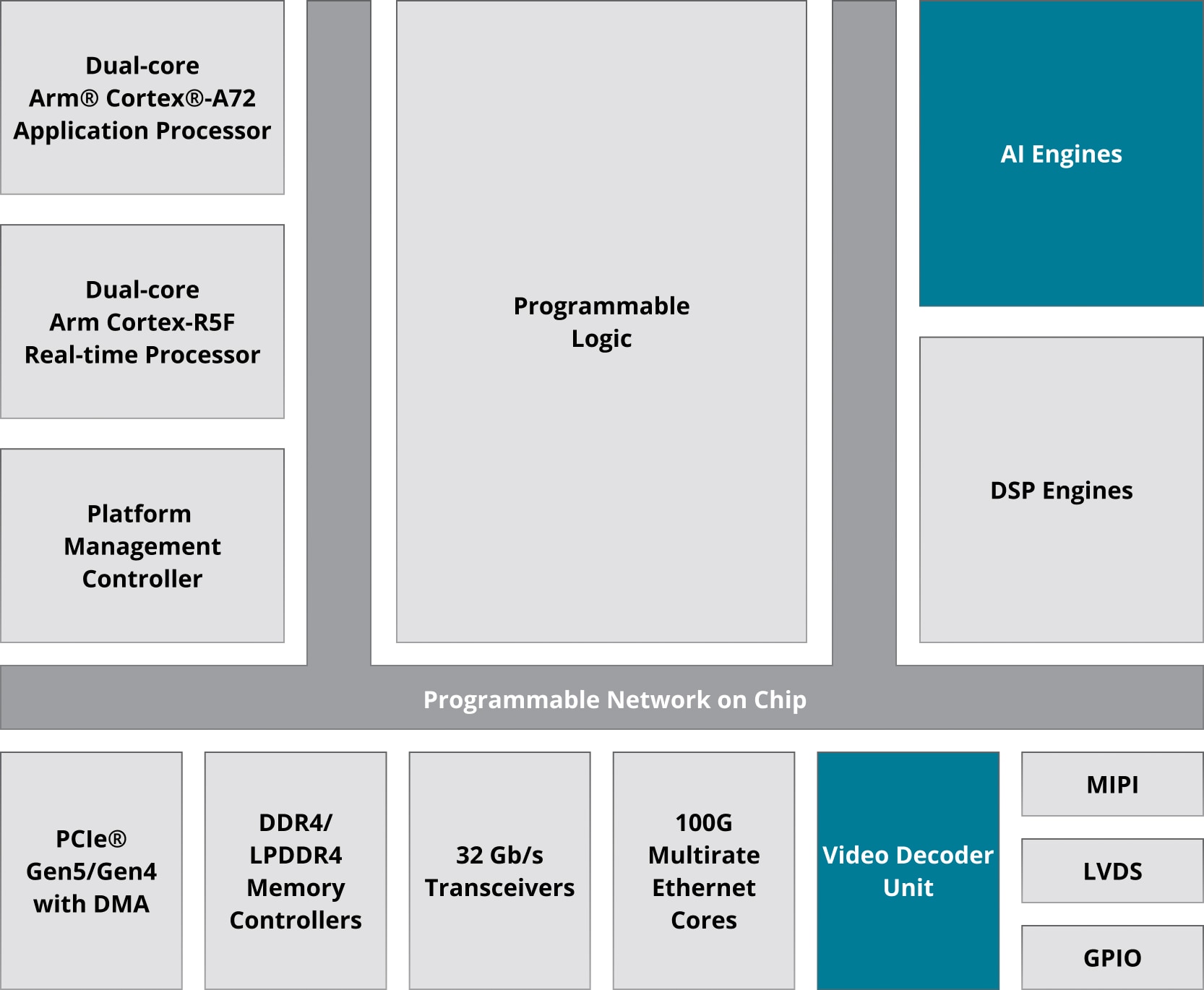
O MPSoC Zynq™ UltraScale+™ e a arquitetura Versal combinam um poderoso PS (Processing System, Sistema de processamento), incorporando processadores Arm® Cortex® e lógica programável pelo usuário em um único dispositivo.
A plataforma de software unificada Vitis oferece a capacidade de criar um perfil de um determinado aplicativo e permite a criação de aceleradores de hardware para serem executados com mais eficiência na PL (Programmable Logic, Lógica programável), onde a flexibilidade e o paralelismo da FPGA são aproveitados para proporcionar grandes melhorias de desempenho. Isso também permite que outras funções do aplicativo sejam executadas no PS em paralelo, se desejado.
Ao direcionar os SoCs adaptativos e FPGAs da AMD, muitas aplicações de DSP e aplicações incorporadas verão ganhos em eficiência e redução do consumo de energia.
As tabelas a seguir mostram alguns dos principais recursos e métricas de desempenho de DSP para as famílias MPSoC AMD Zynq UltraScale+ e dispositivos Versal™. Para saber mais sobre o desempenho de dispositivos que não são SoC, visite a seção Projetista de hardware.
| Sistema de processamento | SoC Zynq 7000 | MPSoC Zynq UltraScale+ |
|---|---|---|
| APU (Unidade de processamento de aplicações) |
|
|
| RPU (Unidade de processamento em tempo real) |
- |
|
| Processamento multimídia | - |
|
| Interface de memória dinâmica | DDR3, DDR3L, DDR2, LPDDR2 | DDR4, LPDDR4, DDR3, DDR3L, LPDDR3 |
| Periféricos de alta velocidade | USB 2.0, Gigabit Ethernet, SD/SDIO | PCIe® Gen2, USB 3.0, SATA 3.1, DisplayPort, Gigabit Ethernet, SD/SDIO |
| Segurança | RSA, AES e SHA, ARM TrustZone® | RSA, AES e SHA, ARM TrustZone |
| Máximo de pinos de E/S | 128 | 214 |
| Lógica programável | SoC Zynq 7000 | MPSoC Zynq UltraScale+ |
|---|---|---|
| Elementos lógicos do sistema (mil) | 23–444 | 103–1.045 |
| Memória máxima (Mb) | 1,8–26,5 | 5,3–70,6 |
| Máximo de pinos de E/S | 100–362 | 252–668 |
| Fatias de DSP | 60–2.020 | 240–3.528 |
| Multipliers 18x18 | 60–2.020 | 240–3.528 |
| Desempenho de ponto fixo (GMACs) (1) | 42–1.313 | 213–3.143 |
| Desempenho de ponto fixo para filtros simétricos (GMACs) (1) (2) | 84–2.626 | 426–6.286 |
| INT8 GOPs (1) (3) | 84–2.626 | 745–11.000 |
| INT16 GOPs (1) | 84–2.626 | 426–6.286 |
| Ponto de flutuação de precisão única (GFLOPs) (1) (4) | 23–716 | 142–1.673 |
| Ponto de flutuação de precisão única (GFLOPs) (1) (5) | 17–537 | 106–1.571 |
| Ponto de flutuação de meia precisão (GFLOPs) (1) (6) | 34–1.074 | 212–3.142 |
Notas:
Para saber mais sobre os SoCs adaptativos e MPSoCs da AMD, acesse:
O PS fornece recursos de processamento de DSP por meio dos diferentes núcleos de processamento ARM.
Para obter mais informações sobre os recursos de DSP nos processadores ARM, visite:
Alguns exemplos úteis podem ser encontrados nos seguintes locais:
Para o MPSoC Zynq UltraScale+, consulte UG1211 para obter uma demonstração de um FFT usando o conjunto de instruções do ARM NEON.
Para o SoC Zynq 7000, as seguintes dicas técnicas estão disponíveis no wiki da Xilinx ao direcionar o Cortex-A9 e o ARM SIMD:
A AMD tem um suporte de tipo de dados muito flexível em seus dispositivos. As diferentes precisões de ponto fixo, ponto de flutuação e inteiro são suportadas nativamente nas ferramentas AMD, sendo o ponto de flutuação implementado com a ajuda do Núcleo de IP do Floating-Point Operator.
Os projetos de ponto de flutuação implementados nas FPGAs sempre levarão a um maior uso de recursos e energia em comparação com as implementações de ponto fixo ou inteiro. A conversão para uma solução de ponto fixo sempre que possível trará grandes benefícios:
Para obter mais detalhes sobre os benefícios da conversão de tipos de dados de ponto de flutuação para ponto fixo, leia o WP491.
As tabelas abaixo mostram uma pequena seleção de algoritmos e possíveis melhorias de desempenho ao utilizar um dispositivo AMD, e em particular a malha na lógica programável para acelerar o projeto.
| Algoritmo | CPU/GPU | MPSoC Zynq UltraScale+ | Vantagens |
|---|---|---|---|
| LocalBM estéreo em 2K | ARM: 0,5 FPS/Watt nVidia: 3,5 FPS/Watt |
146 FPS/Watt | 292x 42x |
| Fluxo óptico (Lucas-Kanade) |
ARM: 0,1 FPS/Watt nVidia: 0,8 FPS/Watt |
7,1 FPS/Watt | 9,3x |
| GoogleNet (Lote=1) |
ARM: 0,1 Imgs/s/w nVidia: 8,8 Imgs/s/w |
53 Imgs/s/w | 530x 6x |
Notas:
| Algoritmo | CPU/DSP | Zynq 7000 | Vantagens |
|---|---|---|---|
| Projeção frontal | ARM: 3 s/vista | 0,016 s/vista | 188x |
| Detecção de movimento | ARM: 0,7 FPS | 67 FPS | 90x |
| Redução de ruído – Sobel | ARM: 1 FPS | 67 FPS | 60x |
| Detecção de borda de Canny | ARM: 0,66 FPS | 40 FPS | 45x |
| Reconstrução de imagem em 3D | ARM: 75.000 | 8.000 | 9x |
| DPD | ARM: 506 ms | 31,3 ms | 16x |
| FIR | DSP da TI: 64.020 ns | 1.200 ns | 53x |
| FFT | DSP da TI: 1.036 ns | 128 ns | 8x |
Notas:
As ferramentas de projeto de alto nível da AMD, como o Vitis Model Composer para DSP e a Síntese de alto nível, fornecem um nível de abstração que capacita arquitetos de sistema e especialistas em domínio a avaliar rapidamente novos algoritmos e a se concentrar no desenvolvimento de partes diferenciadas de seu projeto. A solução completa de DSP da AMD é uma combinação dessas ferramentas de projeto, IP, projetos de referência, metodologias e placas que trabalham em conjunto para chegar a um projeto de produção funcional no menor tempo possível.
O Vitis Model Composer é uma ferramenta de projeto baseada em modelos que aproveita o ambiente MATLAB e Simulink para definir, testar e implementar algoritmos de DSP de qualidade de produção em lógica programável em uma fração do tempo de desenvolvimento de RTL tradicional.
A ferramenta oferece:
Saiba mais sobre o Vivado System Generator para DSP:
A Síntese de alto nível, que inclui a plataforma de software unificada Vitis, permite que as especificações de algoritmos portáteis C, C++ e System C sejam direcionadas diretamente para FPGAs e SoCs adaptativos da AMD sem a necessidade de criar RTL. Assim como existem compiladores de C/C++ para diferentes arquiteturas de processador, o compilador HLS oferece a mesma funcionalidade de C/C++ para FPGAs e SoCs adaptativos da AMD.
Saiba mais sobre a Síntese de alto nível do Vivado:
A AMD fornece as melhores ferramentas para permitir que os aplicativos de DSP sejam implementados de forma eficiente e com baixo consumo de energia nos SoCs adaptativos e FPGAs da AMD. Independentemente de você estar projetando com RTL, C/C++/SystemC ou Matlab/Simulink, as ferramentas da AMD abaixo podem facilitar o seu projeto de DSP e reduzir o tempo de introdução no mercado.
Bibliotecas e estruturas
A AMD oferece uma variedade de bibliotecas otimizadas para desempenho, utilização de recursos e facilidade de uso.
| Bibliotecas e estruturas | Descrição |
APU |
|---|---|---|
| Repositórios do GitHub | A AMD criou repositórios do GitHub, que contêm exemplos úteis para muitos aplicativos, incluindo funções relacionadas a DSP. | |
| Bibliotecas aceleradas do Vitis | A AMD criou um amplo conjunto de bibliotecas otimizadas para desempenho e de código-fonte aberto que oferecem aceleração imediata com alterações mínimas a nenhuma alteração de código em seus aplicativos existentes. | Bibliotecas Vitis |
Parceiros, placas e kits
A AMD e seus parceiros trabalham juntos para produzir ferramentas e placas para facilitar a adoção de FPGAs e SoCs da AMD para aplicativos de DSP em vários segmentos de mercado.
| Parceiro | Descrição | Solução |
|---|---|---|
| Módulos e kits de desenvolvimento centrados em DSP da Avnet | A MathWorks e a Avnet, fornecedora líder de produtos analógicos de alta velocidade, oferecem kits de desenvolvimento centrados em DSP e SOM (System-on-Modules, Sistemas no módulo) prontos para produção para visão incorporada, rádio definido por software e controle de motor de alto desempenho. |
Avnet |
| Software de computação MathWorks | O Mathworks MATLAB® e o Simulink® podem reduzir significativamente o tempo de desenvolvimento de SoCs adaptativos e sistemas FPGA, possibilitando aos usuários:
|
Mathworks |
| Placas complementares de dispositivos analógicos | A placa FMC AD-FMCDAQ2-EBZ é uma plataforma autônoma de aquisição de dados e prototipagem de síntese de sinais que suporta uma operação fácil de usar, permitindo um desenvolvimento mais rápido do processamento de sinais do sistema final.
|
Dispositivos analógicos |
Junte-se à lista de notificações de SoC adaptativo e FPGA para receber as últimas notícias e atualizações.