Deep Learning mit INT8-Optimierung auf AMD Geräten
Die integrierte AMD DSP-Architektur kann bei INT8-Deep-Learning-Operationen im Vergleich zu anderen FPGA-DSP-Architekturen eine 1,75-fache Performance auf Lösungsebene erzielen.

Mit ihrer inhärenten Flexibilität sind adaptive AMD SoCs und FPGAs ideal für High-Performance- oder Mehrkanal-DSP-Anwendungen (digitale Signalverarbeitung), die die Vorteile von Hardwareparallelität nutzen können. Adaptive AMD SoCs und FPGAs kombinieren diese Verarbeitungsbandbreite mit umfassenden Lösungen, darunter benutzerfreundliche Design-Tools für Hardwaredesigner, Softwareentwickler und Systemarchitekten.
Hardwareparallelität
Eine Von-Neumann-DSP-Standardarchitektur benötigt bis zur Fertigstellung eines FIR-Filters mit 256 Stufen 256 Zyklen, während adaptive SoCs und FPGAs das gleiche Ergebnis in einem einzigen Taktzyklus erzielen können.
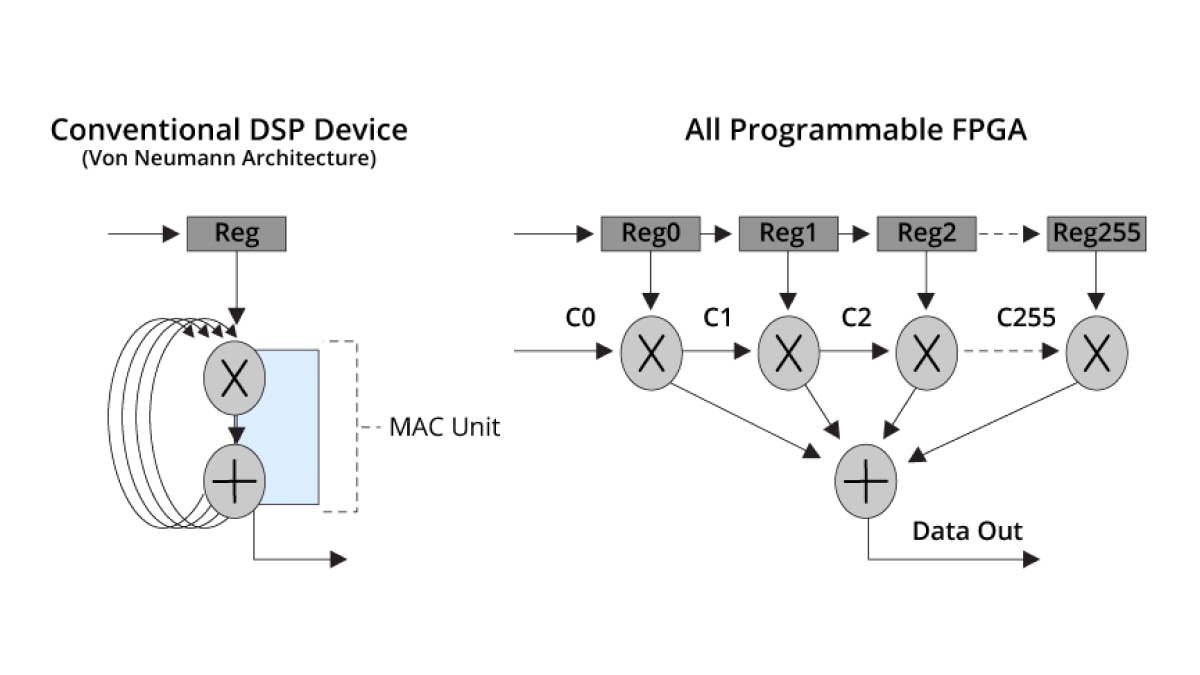
Diese massive Parallelität ermöglicht eine außergewöhnliche DSP-Performance:
Umfassende DSP-Lösungen
AMD DSP-Lösungen umfassen Halbleiter, IP, Referenzdesigns, Entwicklungsplatinen, Tools, Dokumentation und Schulungen, um eine Vielzahl von Anwendungen in einem breiten Spektrum an Märkten zu ermöglichen, darunter drahtlose Kommunikation, Rechenzentren, Luft-/Raumfahrt und Verteidigung.
Umfassende Entwicklungs-Flows
Für verschiedene Anwendungsmodelle und verschiedene Ebenen der Designabstraktion stehen mehrere Toolflows zur Verfügung:
Hardwaredesigner haben folgende Möglichkeiten:
Softwareentwickler, die gewohnt sind, in C/C++ zu entwickeln, haben folgende Möglichkeiten:
Systemarchitekten können neue Algorithmen schnell evaluieren mit:
Mit adaptiven AMD SoCs und FPGAs können Entwickler je nach Designansatz und Abstraktionsgrad mehrere Flows zur Bereitstellung ihrer DSP-Anwendungen verwenden.
In vielen dynamischen und aufstrebenden Märkten, z. B. Luft- und Raumfahrt, Verteidigung, Automobil/Industrie sowie Prüf- und Messtechnik, treiben Anwendungen die Forderung nach immer höherer Rechenbeschleunigung bei gleichzeitig hoher Energieeffizienz voran.
Das Mooresche Gesetz und die Dennard-Skalierung folgen nicht mehr ihrem traditionellen Verlauf. Deshalb kann der Wechsel zum Halbleiterknoten der nächsten Generation für sich allein nicht die Vorteile durch Reduzierung von Stromverbrauch und Kosten bei gleichzeitig besserer Performance bieten, wie dies in früheren Generationen der Fall war.
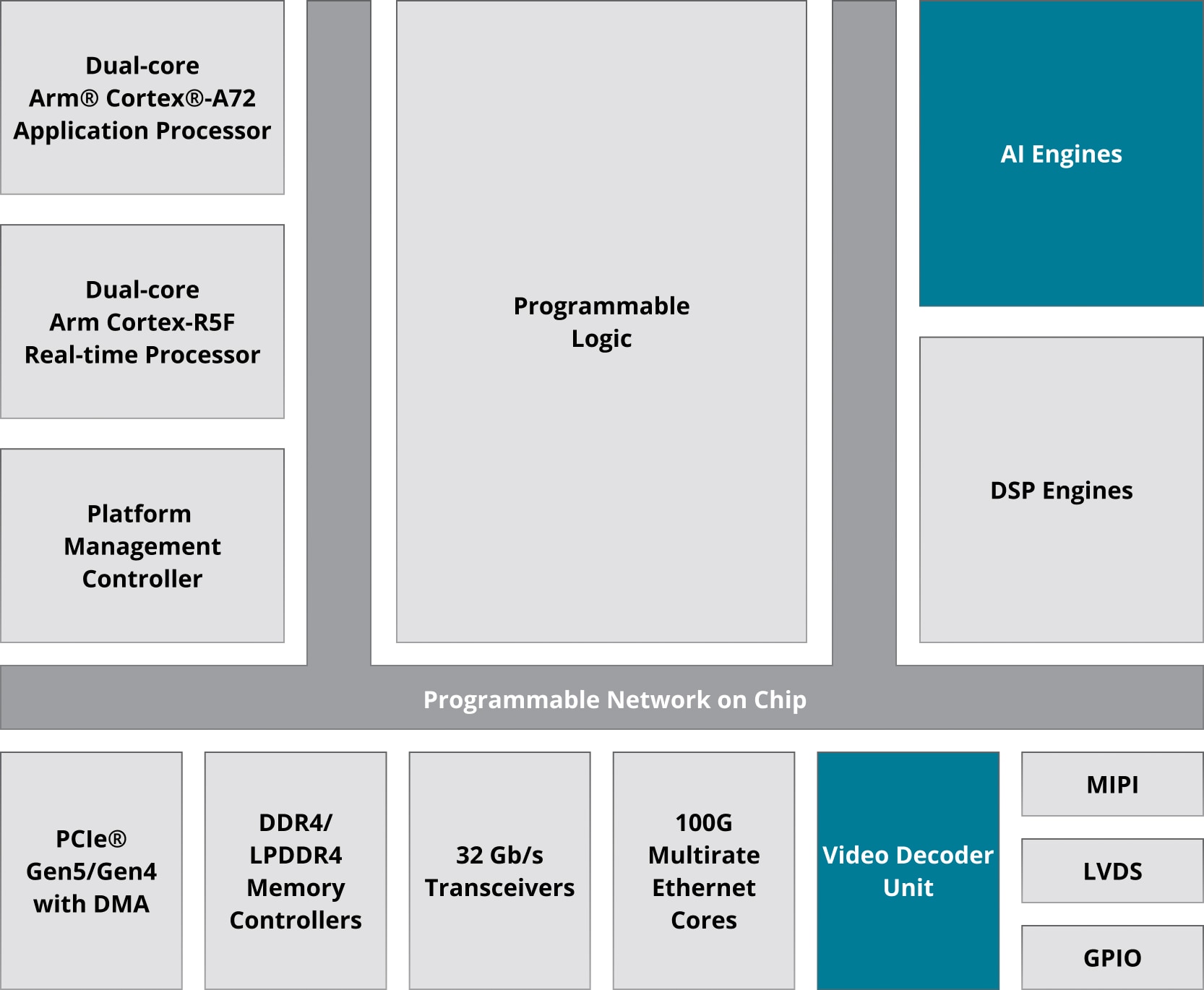
Als Reaktion auf diesen nichtlinearen Anstieg der Nachfrage durch DSP-Anwendungen der nächsten Generation, z. B. Polyphase Channelizer und Beamforming, hat AMD eine innovative Verarbeitungstechnologie entwickelt: die AI Engine, die zur AMD Versal™ Architektur gehört.
Die Architektur der KI-Engines ist als 2D-Arrays konzipiert, die aus mehreren KI-Engine-Kacheln bestehen und eine hochgradig skalierbare Lösung im gesamten Versal Portfolio ermöglichen. Diese reichen von Dutzenden bis zu Hunderten von KI-Engines in einem einzigen Chip und erfüllen die Rechenanforderungen einer breiten Palette von Anwendungen.
Die Vorteile sind:
Adaptive AMD SoCs und FPGAs basieren auf einer Architektur der ASIC-Klasse. In der Versal™ Premium-Serie kombinieren sie eine E/A-Bandbreite von mehreren hundert Gigabit pro Sekunde mit einer Festkomma-DSP-Performance von über 49 TeraMACs. Der AMD DSP Slice und seine Parallelität sind entscheidend für die erreichbare DSP-Performance in den AMD FPGAs der neuesten Generation.
Der DSP58-Slice in Versal Chips gehört zur 6. Generation von DSP-Slices in AMD-Architekturen.
Dieser dedizierte DSP-Verarbeitungsblock ist in einem vollständig kundenspezifischen Halbleiter implementiert, der ein führendes Verhältnis von Stromverbrauch/Performance bietet und eine effiziente Implementierung gängiger DSP-Funktionen ermöglicht, beispielsweise Multiply-Accumulator (MACC), Multiply-Adder (MADD) oder Complex Multiplier.
Der Slice verfügt außerdem über Fähigkeiten zur Ausführung verschiedener Arten von logischen Operationen, z. B. AND, OR und XOR.
Die DSP58-Architektur des Versal Chips baut auf dem Erfolg von UltraScale™ FPGA DSP48E2 auf und bringt weitere Verbesserungen:
Dank dieser Verbesserungen können DSP-kritische Anwendungen mehr Berechnungen innerhalb des DSP48E2-Slice durchführen, bevor sie in die FPGA-Struktur wechseln, was letztendlich zu Ressourcen- und Energieeinsparungen führt.
| Funktion | UltraScale | Versal |
|---|---|---|
| Typ von DSP-Kachel/-Slice | DSP48E2 | DSP58 |
| Mehrere Add-/Sub-/ACC-Operationen |  |
|
| Multiplier und MACC | 27x18 | 27x24 |
| Quadrieren: [(A oder B) +/- D]2 | |
|
| Extrem effiziente komplexe Multiplikation CMACC mit WMUX-Feedback | 3 x DSP48E2 | 2 x DSP58 |
| SIMD-Unterstützung | |
|
| Integrierte Musterdetektor-Schaltkreise | |
|
| Integrierte Logikeinheit | |
|
| Wide Mux-Funktionen | 48-Bit | 58-Bit |
| Wide XOR | 96-Bit | 116-Bit |
| Gleitkomma-Multiplier mit einfacher Genauigkeit | |
|
| Optionaler 96-Bit-Ausgang | |
|
| Kaskaden-Routing | |
|
| Pipeline-Register | |
|
| D Pre-Adder | |
|
| Sequentielles Komplexes Multiplizieren, AB dyn. Zugriff | |
|
| Verbessertes Balancing der AB Register Pipeline | |
|
Ausgewählte Videos:
Je nachdem, was Sie bevorzugen, bietet AMD Tools zur Unterstützung von RTL-, C/C++- und modellbasierten Designeingaben. Diese Flexibilität im Design-Flow und ein umfangreicher DSP-IP-Katalog erleichtern die Einführung von AMD-Tools und -Chips.
Weitere Informationen finden Sie unter Tools, Bibliotheken und Frameworks.
In der folgenden Tabelle sind einige der wichtigsten DSP-Performance-Metriken für die 7-Serie, UltraScale™ und UltraScale+™ Familien zusammengestellt. Informationen zur Performance von adaptiven SoC-Chips finden Sie im Abschnitt „Softwareentwickler“.
| Kintex UltraScale | Kintex UltraScale+ | Virtex UltraScale | Virtex UltraScale+ | Versal AI Core | Versal AI Edge | Versal AI Prime | Versal AI Premium | |
|---|---|---|---|---|---|---|---|---|
| Systemlogikelemente (K) | 318–1.451 | 356–1.143 | 783–5.541 | 862–3.780 | 540–1.968 | 44–1.139 | 329–2.233 | 833–7.352 |
| DSP-Schichten | 768–5.520 | 1.368–3.528 | 600–2.880 | 2.280–12.288 | 928–1.968 | 90–1.312 | 464–3.984 | 1.140–14.352 |
| 27x18 Multiplier | 768–5.520 | 1.368–3.528 | 600–2.880 | 2.280–12.288 | 928–1.968 | 90–1.312 | 464–3.984 | 1.140–14.352 |
| INT8 GOPs1 | 1.774–14.315 | 4.263–11.000 | 1.554–7.469 | 7.108–38.318 | 6.403–13.579 | 62–9.052 | 3.201–27.489 | 7.866–99.029 |
| INT16 GOPs | 1.014–8.180 | 2.436–6.286 | 888–4.268 | 4.062–21.896 | 2.134–4.526 | 21–3.017 | 1.067–9.163 | 2.622–33.010 |
| Komplexe INT18 GOPs | 676–5.453 | 1.624–4.191 | 592–2.845 | 2.708–14.597 | 913–1.937 | 8–1.291 | 456–3.920 | 1.122–14.122 |
| Gleitkomma mit einfacher Genauigkeit (GFLOPs)2 | 320–2.685 | 800–1.673 | 294–1.411 | 1.354–7.299 | 1.494–3.168 | 14–2.112 | 747–6.414 | 1.835–23.107 |
Wir haben Softwareentwicklungsumgebungen und eine umfassende Auswahl an vertrauten und leistungsstarken Tools, Bibliotheken und Methoden eingeführt, mit denen Softwareentwickler problemlos Projekte für adaptive AMD SoCs und FPGAs in Angriff nehmen können. Eine Umgebung mit hohem Abstraktionsgrad ist hierfür die Vitis™ Unified Software Platform. Wir können GPU-ähnliche und vertraute Embedded-Anwendungsentwicklung und Laufzeiterfahrungen für die C-, C++- und/oder OpenCL-Entwicklung anbieten.
Die Kombination aus Zynq™ UltraScale+™ MPSoC und Versal Architektur ergibt ein leistungsstarkes Verarbeitungssystem (Processing System, PS) mit Arm® Cortex® Prozessoren und benutzerprogrammierbarer Logik (PL) in einem einzigen Chip.
Die Vitis Unified Software Platform bietet die Möglichkeit, ein Profil für eine bestimmte Anwendung festzulegen und Hardwarebeschleuniger zu erstellen, die in der programmierbaren Logik (PL) effizienter ausgeführt werden können. Dank der Flexibilität und Parallelität des FPGA können damit große Performancesteigerungen erzielt werden. Bei Bedarf können so auch andere Funktionen der Anwendung im Verarbeitungssystem (PS) parallel ausgeführt werden.
Durch die Ausrichtung auf adaptive AMD SoCs und FPGAs werden viele DSP- und Embedded-Anwendungen effizienter und mit geringerem Stromverbrauch arbeiten.
In den folgenden Tabellen sind einige der wichtigsten Funktionen und DSP-Performance-Metriken für die AMD Zynq UltraScale+ und die MPSoC-Familie sowie für Versal™ Chips zusammengestellt. Informationen zur Performance von Nicht-SoC-Chips finden Sie im Abschnitt „Hardwaredesigner“.
| Verarbeitungssystem | Zynq 7000 SoC | Zynq UltraScale+ MPSoC |
|---|---|---|
| Application Processing Unit (APU) |
|
|
| Echtzeitverarbeitungseinheit (RPU) | – |
|
| Multimedia-Verarbeitung | – |
|
| Dynamic Memory Interface | DDR3, DDR3L, DDR2, LPDDR2 | DDR4, LPDDR4, DDR3, DDR3L, LPDDR3 |
| Hochgeschwindigkeits-Peripheriegeräte | USB 2.0, Gigabit Ethernet, SD/SDIO | PCIe® der 2. Generation, USB3.0, SATA 3.1, DisplayPort, Gigabit Ethernet, SD/SDIO |
| Sicherheit | RSA, AES und SHA, ARM TrustZone® | RSA, AES und SHA, ARM TrustZone |
| Max. E/A-Pins | 128 | 214 |
| Programmierbare Logik | Zynq 7000 SoC | Zynq UltraScale+ MPSoC |
|---|---|---|
| Systemlogikelemente (K) | 23–444 | 103–1.045 |
| Max. Speicher (Mb) | 1,8–26,5 | 5,3–70,6 |
| Max. E/A-Pins | 100–362 | 252–668 |
| DSP-Schichten | 60–2.020 | 240–3.528 |
| 18x18 Multiplier | 60–2.020 | 240–3.528 |
| Festkommaleistung (GMACs) (1) | 42–1.313 | 213–3.143 |
| Festkommaleistung für symmetrische Filter (GMACs) (1) (2) | 84–2.626 | 426–6.286 |
| INT8 GOPs (1) (3) | 84–2.626 | 745–11.000 |
| INT16 GOPs (1) | 84–2.626 | 426–6.286 |
| Gleitkomma mit einfacher Genauigkeit (GFLOPs) (1) (4) | 23–716 | 142–1.673 |
| Gleitkomma mit einfacher Genauigkeit (GFLOPs) (1) (5) | 17–537 | 106–1.571 |
| Gleitkomma mit halber Genauigkeit (GFLOPs) (1) (6) | 34–1.074 | 212–3.142 |
Hinweise:
Weitere Informationen zu adaptiven AMD SoCs und MPSoCs finden Sie unter:
Das Verarbeitungssystem (PS) stellt DSP-Verarbeitungsfunktionen über die verschiedenen ARM Prozessorkerne bereit.
Weitere Informationen zu den DSP-Funktionen der ARM Prozessoren finden Sie unter:
Einige nützliche Beispiele finden Sie über die folgenden Links:
Für das Zynq UltraScale+ MPSoC finden Sie eine Demonstration einer FFT mit dem ARM NEON-Befehlssatz unter UG1211.
Für das Zynq 7000 SoC stehen die folgenden Tech Tips in der Xilinx Wiki zur Verfügung, wenn Sie mit Cortex-A9 und ARM SIMD arbeiten:
AMD bietet in seinen Chips eine sehr flexible Unterstützung für Datentypen. Festkomma, Gleitkomma und Ganzzahl mit unterschiedlicher Genauigkeit werden nativ in AMD Tools unterstützt. Gleitkommafunktionen werden dabei mithilfe des Floating-Point Operator IP-Kerns implementiert.
Gleitkommadesigns, die auf FPGAs implementiert werden, führen immer zu einem höheren Ressourcen- und Stromverbrauch als Festkomma- oder Ganzzahl-Implementierungen. Sofern die Konvertierung in eine Lösung mit Festkomma möglich ist, bringt dies große Vorteile:
Weitere Informationen zu den Vorteilen einer Konvertierung von Gleitkomma- in Festkommadatentypen finden Sie in WP491.
Die folgenden Tabellen enthalten eine kleine Auswahl an Algorithmen und mögliche Performanceverbesserungen durch Verwendung eines AMD Chip und insbesondere der Struktur in der programmierbaren Logik (PL) zur Beschleunigung des Designs.
| Algorithmus | CPU/GPU | Zynq UltraScale+ MPSoC | Advantage |
|---|---|---|---|
| Stereo LocalBM bei 2K | ARM: 0,5 FPS/Watt nVidia: 3,5 FPS/Watt |
146 FPS/Watt | 292x 42x |
| Optischer Fluss (Lucas-Kanade) |
ARM: 0,1 FPS/Watt nVidia: 0,8 FPS/Watt |
7,1 FPS/Watt | 9,3x |
| GoogleNet (Batch=1) |
ARM: 0,1 Bilder/s/w nVidia: 8,8 Bilder/s/w |
53 Bilder/s/w | 530x 6x |
Hinweise:
| Algorithmus | CPU/DSP | Zynq 7000 | Advantage |
|---|---|---|---|
| Vorwärtsprojektion | ARM: 3 Sek./Ansicht | 0,016 Sek./Ansicht | 188x |
| Bewegungserkennung | ARM: 0,7 FPS | 67 FPS | 90x |
| Rauschunterdrückung – Sobel | ARM: 1 FPS | 67 FPS | 60x |
| Canny-Algorithmus (Kantendetektion) | ARM: 0,66 FPS | 40 FPS | 45x |
| 3D-Bildrekonstruktion | ARM: 75k | 8k | 9x |
| DPD | ARM: 506 ms | 31,3 ms | 16x |
| FIR | TI DSP: 64020 ns | 1200 ns | 53x |
| FFT | TI DSP: 1036 ns | 128 ns | 8x |
Hinweise:
AMD High-Level-Design-Tools wie der Vitis Model Composer für DSP und High-Level-Synthese bieten einen Abstraktionsgrad, mit dem Systemarchitekten und Fachexperten schnell neue Algorithmen evaluieren und sich auf die Entwicklung der differenzierenden Teile ihres Designs konzentrieren können. Die gesamte AMD DSP-Lösung ist eine Kombination aus diesen Designtools, IP, Referenzdesigns, Methoden und Platinen, die in ihrem Zusammenspiel ermöglichen, in kürzester Zeit zu einem funktionierenden Produktionsdesign zu kommen.
Der Vitis Model Composer ist ein modellbasiertes Designtool, das die MATLAB- und Simulink-Umgebung nutzt, um DSP-Algorithmen in Produktionsqualität in programmierbarer Logik zu definieren, zu testen und zu implementieren – und das in einem Bruchteil der herkömmlichen RTL-Entwicklungszeiten.
Das Tool bietet:
Weitere Informationen über den Vivado System Generator finden Sie unter:
Die High-Level-Synthese, zu der auch die Vitis Unified Software Platform gehört, ermöglicht es, Spezifikationen für portable C-, C++- und System C-Algorithmen direkt auf AMD FPGAs und adaptive SoCs auszurichten, ohne dass ein RTL erstellt werden muss. Genau wie es Compiler von C/C++ zu verschiedenen Prozessorarchitekturen gibt, bietet der HLS-Compiler die gleiche Funktionalität von C/C++ zu AMD FPGA und adaptiven SoCs.
Weitere Informationen über die Vivado High-Level-Synthese finden Sie unter:
AMD bietet erstklassige Tools, mit denen digitale Signalverarbeitung (DSP) effizient und mit geringem Energieverbrauch auf adaptiven AMD SoCs und FPGAs implementiert werden kann. Ganz gleich, ob Sie Ihr Design mit RTL, C/C++/SystemC oder Matlab/Simulink erstellen, die folgenden AMD Tools können Ihr DSP-Design erheblich vereinfachen und die Markteinführungszeit verkürzen.
Bibliotheken und Frameworks
AMD bietet eine Reihe von Bibliotheken, die im Hinblick auf Performance, Ressourcennutzung und Benutzerfreundlichkeit optimiert sind.
| Bibliotheken und Frameworks | Beschreibung |
Anwendung |
|---|---|---|
| GitHub Repositorys | AMD hat GitHub Repositorys erstellt, die nützliche Beispiele für viele Anwendungen enthalten, darunter auch Funktionen für DSP enthalten. | |
| Vitis Accelerated Libraries | AMD hat eine umfangreiche Sammlung an leistungsoptimierten Open-Source-Bibliotheken erstellt, die eine sofortige Beschleunigung mit minimalen oder gar keinen Code-Änderungen an Ihren vorhandenen Anwendungen ermöglichen. | Vitis Bibliotheken |
Partner, Platinen und Kits
AMD erstellt und produziert gemeinsam mit seinen Partnern Tools und Platinen, die die Einführung von AMD FPGAs und SoCs für DSP-Anwendungen in vielen Marktsegmenten erleichtern.
| Partner | Beschreibung | Lösung |
|---|---|---|
| Avnet: DSP-zentrierte Entwicklungskits und -module | MathWorks und Avnet als führender Anbieter im Hochgeschwindigkeits-Analogbereich bieten DSP-zentrierte Entwicklungskits und produktionsbereite System-On-Modules (SOMs) für Embedded Vision, softwaredefinierte Funktechnik und High-Performance-Motorsteuerung an. |
Avnet |
| Mathworks: Computing-Software | MATLAB® und Simulink® von Mathworks können die Entwicklungszeit für adaptive SoCs und FPGA-Systeme erheblich reduzieren, indem sie Benutzern folgende Möglichkeiten bieten:
|
Mathworks |
| Analog Devices: Add-On-Platinen | Die AD-FMCDAQ2-EBZ FMC Platine ist eine eigenständige Plattform zur Entwicklung von Prototypen für Datenerfassung und Signalsynthese, die eine benutzerfreundliche Bedienung unterstützt und eine schnellere Entwicklung der Signalverarbeitung des Endsystems ermöglicht.
|
Analoge Geräte |
Melden Sie sich für die E-Mail-Liste an, um die neuesten Nachrichten und Meldungen zu adaptiven SoCs and FPGAs zu erhalten.