Classiq 与 Comcast 基于 AMD GPU 通过量子算法设计高弹性路由
Feb 18, 2026

简介
现代电信网络采用密集的计算图拓扑结构,其中任意两个站点之间存在多条物理路径。这种冗余提供了至关重要的弹性保障:当一条路径上的链路发生故障时,流量可经由备用路径重新路由,以保持服务的连续性。然而,要充分利用这种内置的弹性机制,就需要能够同时针对多个相互竞争的目标进行优化的算法,例如在尽量降低延迟的同时避免出现关联链路故障(比如,不同链路由于共同的环境风险而可能同时发生故障的情况)。
在这些约束条件下寻找最优路径,计算难度极大。找出互不相交路径,同时实现延迟最小化与双链路故障风险最小化,这属于 NP-hard 问题;这意味着随着网络规模不断增大,传统算法将难以求出最优解。而量子计算正好可针对这一问题提供有效的替代解决方案。在本博客中,我们将低延迟、高弹性路由问题表述为一项优化任务,并展示量子算法如何应对这一高难度计算难题。我们将展示在基于 GPU 的量子仿真器上执行量子算法后所获得的结果,从而展现量子方法如何助力电信运营商在日益复杂的网络中做出更明智的路由决策。
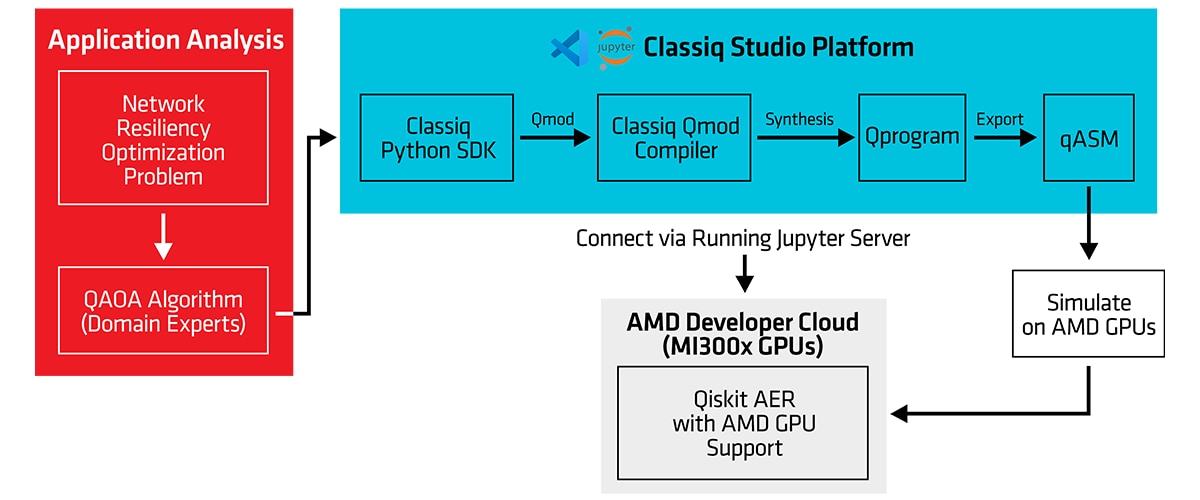
图 1 展示了本博客中所述流程的端到端完整示意图。左侧展示了应用分析:我们从某个应用中提取一种算法(例如,针对网络弹性优化问题的二元决策变量),并借助量子近似优化算法 (QAOA) 设计模式,将其适配到量子计算中。然后,我们使用 Classiq Studio 平台,通过 Classiq Python SDK 编写高级别程序。正如我们将看到的,应用开发者无需自行编写量子线路。该 SDK 程序会被编译成 Qmod 语言,这种语言可被合成到最终生成的量子线路中,从而能够对最终线路实施优化。完成合成后,该线路便可导出为更底层的线路表示形式,以用于量子计算机中真实存在的物理量子比特或仿真量子比特。在本例中,我们通过 AMD Developer Cloud 在 AMD Instinct GPU 上运行 Qiskit Aer 仿真器,以此评估生成的量子线路。
问题描述与数学建模
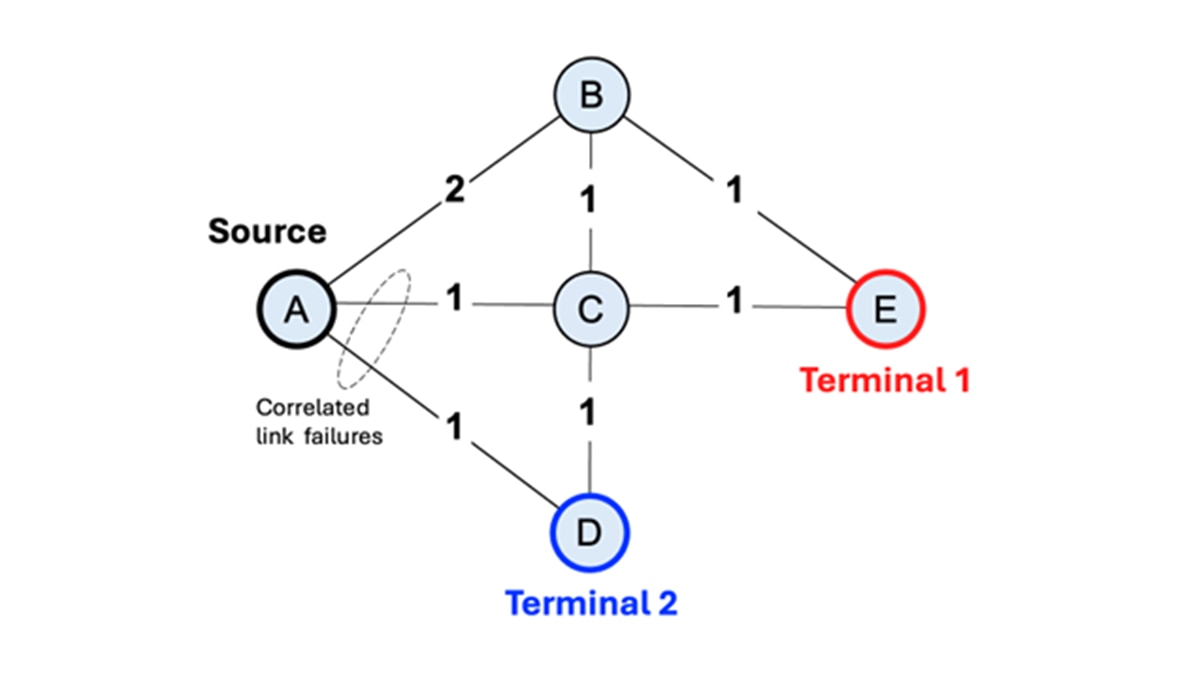
参考上方图 2 中所展示的示意图。每个顶点代表一个为数千名互联网用户服务的站点,而边则代表连接这些站点的物理链路(通常是光纤)。每条边上标注的标签表示以任意单位计量的链路延迟。顶点 D 和 E 是连接到互联网主干的特殊站点,称之为“终端站点”。
我们的目标是从每个源站点(例如站点 A)到终端站点 D 和 E,找到两条互不相交的路径:一条主路径和一条备用路径。不相交的路径之间没有共同的边或顶点,从而确保单个链路或站点故障不会同时中断两条路径。此外,我们希望在规避高度相关链路的同时,将总路径延迟(各边权重之和)降至最低(这一点稍后会详细介绍)。这是一个具有挑战性的组合优化问题:对于每个源站点,我们必须从极其庞大的解空间中选择两条路径,同时满足严格的约束条件(顶点不相交)并优化多个目标(降低延迟以及双链路故障的影响)。
此类图优化问题可使用二元决策变量进行数学建模。问题的核心在于寻找两条最短的不相交路径:一条从站点 A 到终端 D 的路径 P1,另一条从站点 A 到终端 E 的路径 P2。每条路径所需的二元决策变量数量等于图中顶点数与边数之和。
例如,如果边 (i,j) 处于激活状态(即位于从 A 到 D 的路径上)时,二元决策变量 xijP1 等于 1,否则等于 0。同样,如果顶点 i 处于激活状态(即位于从 A 到 D 的路径上),则变量 xiP1 等于 1,否则等于 0。因此,针对源站点 A,对该问题建模所需的变量总数为 2(|V|+|E|) = 24。
我们可使用以下目标函数来建立延迟最小化表达式:
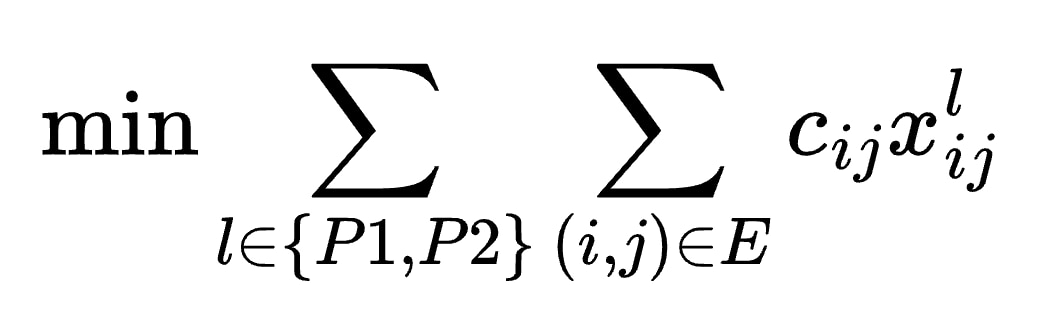
其中 cij 表示边 (i,j) 的延迟。然而,您立刻就能看出问题所在:仅最小化这一目标函数,会得出一种无意义的解,即所有路径中均不包含任何链路,这意味着虽然延迟为零,但连通性也彻底归零!为确保仅返回有效路径,我们必须添加路径连通性约束条件,以强制解代表从源站点到终端站点的实际路线。路径连通性采用以下表达式进行编码:

上述表达式的含义为:若某个顶点属于路径 P,该顶点要么拥有 1 条有效边(若为源或终端站点),要么拥有 2 条有效边(若为中间站点)。或者,若顶点不属于路径 P,则有效边的数量为 0。
接下来,我们要设置约束条件以强制路径不相交。也就是说,P1 和 P2 除了源顶点 A 之外,不得有任何共同的顶点。由此推论,两条没有共同顶点的路径也必然没有共同的边。路径不相交性表示为:
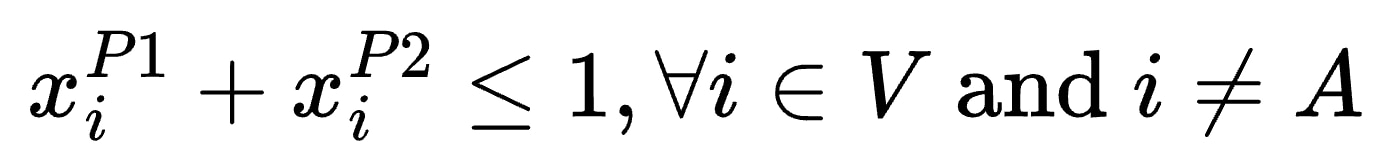
最后,我们需要对存在两条相关边的情况进行惩罚,这两条边分别属于路径 P1 和 P2。请注意,忽略链路关联性会造成一种虚假的弹性错觉:尽管图中 P1 和 P2 看似冗余,但实际上它们可能包含易受相同类型风险影响的链路。我们将考虑一种简单情形:AC 边和 AD 边的关联度为 100%,而图中所有其他成对的边之间均无共同风险。我们将以下表达式添加到目标函数中:
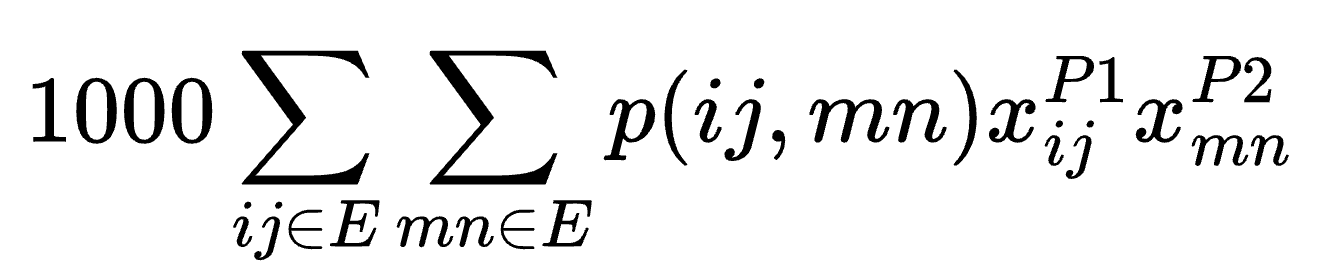
仅当边 (i,j) 和 (m,n) 分别对应 AC 和 AD 时,双链路故障概率 p(ij,mn) 才为 0.1。否则,p(ij,mn) 的值为 0.01。缩放因子 1000 特意设置为远大于边权重,以此确保规避关联链路故障的优先级高于延迟最小化。
现在,我们已通过待最小化的目标函数和一些约束条件,对问题进行了编码!请注意,要利用量子算法求解该问题,我们需要将目标函数和约束条件合并为单个表达式。这一简单步骤虽未在本博客中提及,但可在随附的出版物 [1] 中查阅。
量子近似优化算法 (QAOA)
到目前为止,我们已通过一个单一的目标函数对该问题进行数学建模,而目标函数中同时包含优化目标和必要的约束条件(以惩罚项形式纳入)。这种统一的表达式被称为哈密顿量,这是一个来自物理学的基础概念,用于描述系统内部的能量分布与相互作用。在物理学中,哈密顿量决定了系统随时间的演化方式。我们在此也利用这一原理:通过将组合优化问题编码为哈密顿量,便可利用量子硬件驱动量子粒子物理系统不断演化,最终收敛至问题的最优解。
为求解这种经量子编码的问题,我们采用量子近似优化算法 (QAOA)。该算法是一种混合方法,融合了传统计算与量子计算各自的优势。可以将 QAOA 理解为一种高级搜索方法:由传统计算机承担繁重的计算任务,包括目标函数计算与约束条件校验;而量子处理器则负责探索传统计算机无法驾驭的庞大候选解空间。该算法交替执行两类操作:问题哈密顿量(对待求解的问题进行编码)与混合哈密顿量(探索不同候选解)。这两类操作以层级形式依次迭代执行,每一层迭代都会让结果愈发逼近高质量最优解。整个过程的核心难点在于调优控制上述操作的参数,这一调优任务通过传统优化算法完成,目的是充分提高解的可信度。
从数学角度来讲,整个求解过程以均匀叠加态作为初始态启动:
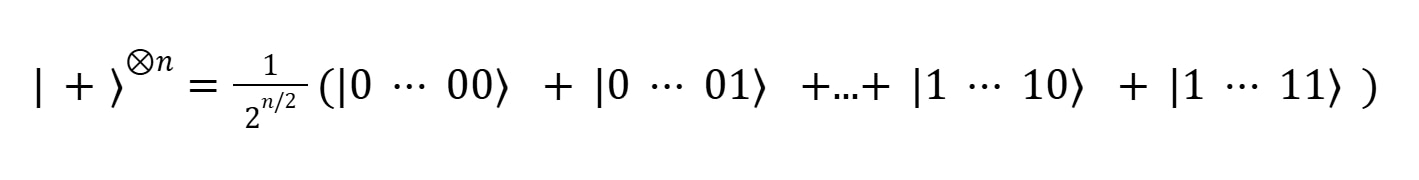
其中每一种“情形”(即系统 2n 种可能状态空间中的任意一种状态)以均等概率形式存在。随后,将可实现下述运算的参数化量子线路应用于均匀叠加态:
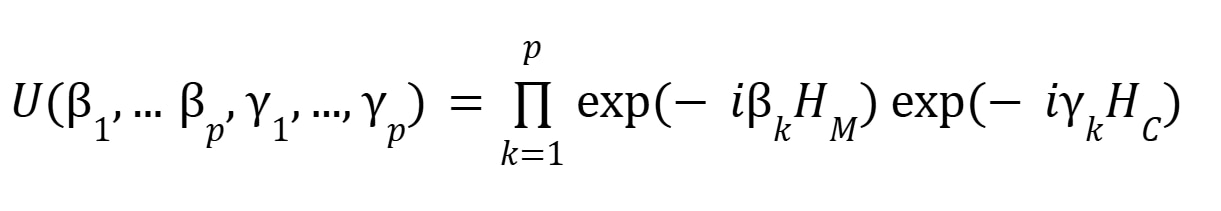
在公式中,p 为 QAOA 层数;βk, k 为量子线路参数,在每一轮运行与测量迭代中,线路都会经由传统算法进行优化;HC,HM 分别为代价哈密顿量与混合哈密顿量。该线路结构的运行机制充分展现了量子计算的独特优势:量子比特波函数经过精心设计的相消干涉过程,从系统所有初始可能状态集合中剔除不符合预期的状态。
具体原理如下:将目标函数编码至代价哈密顿量中,在整个线路执行过程中,劣势状态(即代价更高的状态)会在幺正演化 exp(- i HC) 过程中累积更大相位,从而受到惩罚。然后,通过混合层的作用促成不同状态之间的干涉效应,使振幅(实验结果的出现概率)在各状态间发生“流转”,从而放大低代价状态的出现概率,同时压制高代价状态。每完成一轮线路运行与测量后,便将测量结果输入传统优化器,并相应调整 βk, k 参数,确保进一步向低代价状态收敛优化。

我们基于下文介绍的 Classiq 平台实现算法。Classiq 平台支持研究人员使用熟悉的 Python 语法编写量子程序,无需费力处理底层量子门。算法会多次运行量子线路、测量结果,并从中筛选出最优解。虽然 QAOA 无法保证一定求出最优解,但在部分优化问题上性能可与传统算法比肩,而且随着量子硬件持续迭代升级,其优势还将进一步扩大。
Classiq QMOD
量子线路设计的底层复杂性长期制约着量子计算开发。Classiq 推出名为 Qmod 的高阶领域特定语言 (DSL),并配套强大的量子编译器,有效解决了这一难题。
开发者可借助该高阶语言简洁描述量子算法逻辑,然后,再由编译器自动生成并优化最高效的量子线路。
这种方法可确保:
- 可扩展性:应对大规模问题带来的指数级复杂度增长。
- 易用性:降低非专业人员使用量子硬件的门槛。
- 效率:生成更精简、深度更浅的量子线路,对噪声具备更强的抗干扰性。
Classiq 高阶语言与编译器是求解复杂 NP-hard 问题的重要工具,可让从数学问题到可执行量子线路的转化流程变得更简单、可扩展。
请注意,开发者若习惯使用 Python,也无需编写 Qmod 代码。Classiq 提供 Python SDK,可通过修饰器及各类 API 直接创建 Qmod 程序。下文将给出具体演示。
在 DevCloud 中搭建仿真基础设施
本文旨在验证 AMD GPU 基础设施可与 Classiq 平台无缝协同使用。为此,我们借助 AMD Developer Cloud 搭建搭载 MI300X GPU 的环境,作为 Classiq Studio 平台的执行后端。本节将介绍如何配置 AMD Developer Cloud,并构建支持 AMD GPU 的 Qiskit-AER 库。
创建 Droplet
假设您已拥有一个帐户(任何人都可在 https://amd.digitalocean.com/login 上创建帐户),您需要创建一个新的 Droplet。在 DigitalOcean 中,Droplet 是指虚拟机。为此,我们可以使用网站右上角的“Create”菜单(如图 4 所示)。我们选择“GPU Droplets”。
GPU Droplet 有两种规格,它们在分配的 GPU 数量上有所不同:MI300X(1 个 GPU)和 MI300X x8(8 个 GPU)。请注意,成本与 GPU 数量成正比;因此,MI300X x8 的价格将是前者的 8 倍。
在本博文进行的演示中,我们采用单个 GPU(如图 5 所示)。我们鼓励用户测试 Qiskit AER 提供的多 GPU 支持。
除了选择 GPU 数量,我们还必须选择用于启动虚拟机的操作系统镜像。在可用选项中,我们将使用纯净的 AMD ROCm 软件镜像(如图 6 所示)。
最后,我们需要添加一个 SSH 密钥(如图 7 所示)。该密钥用于建立 SSH 连接;不过,在本示例中,我们将使用预加载的 Jupyter Notebook 环境。因此,无需建立 SSH 连接。
准备就绪后,我们可以单击“Create GPU Droplet”按钮。此过程可能需要几分钟,具体取决于虚拟机的配置时长。创建完成后,您将看到一个如图 8 中所示的 droplet 控制面板。
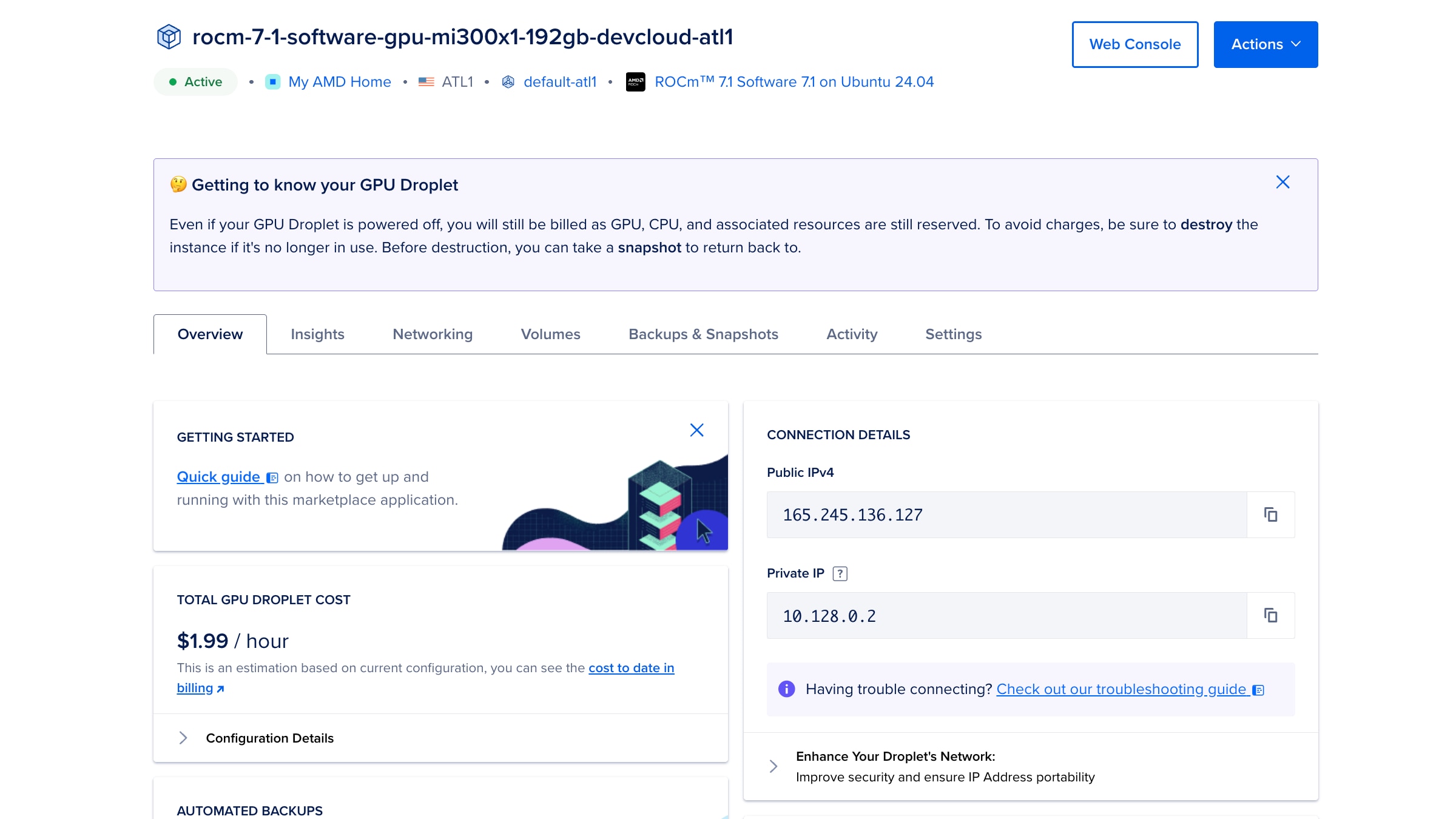
此过程的最后一步是学习如何访问 Jupyter Notebook 环境,以设置 Qiskit-AER,并从 Classiq Studio 平台进行连接。为此,我们可以使用图 8 右上角所示的 Web 控制台白色按钮,打开一个基于 Web 的终端。图 9 显示了您在打开终端后将看到的输出示例。“Access the Jupyter Server”后面的两行非常重要。我们可以在任意浏览器中打开相应 HTTP 地址,并在收到提示时使用该令牌登录。
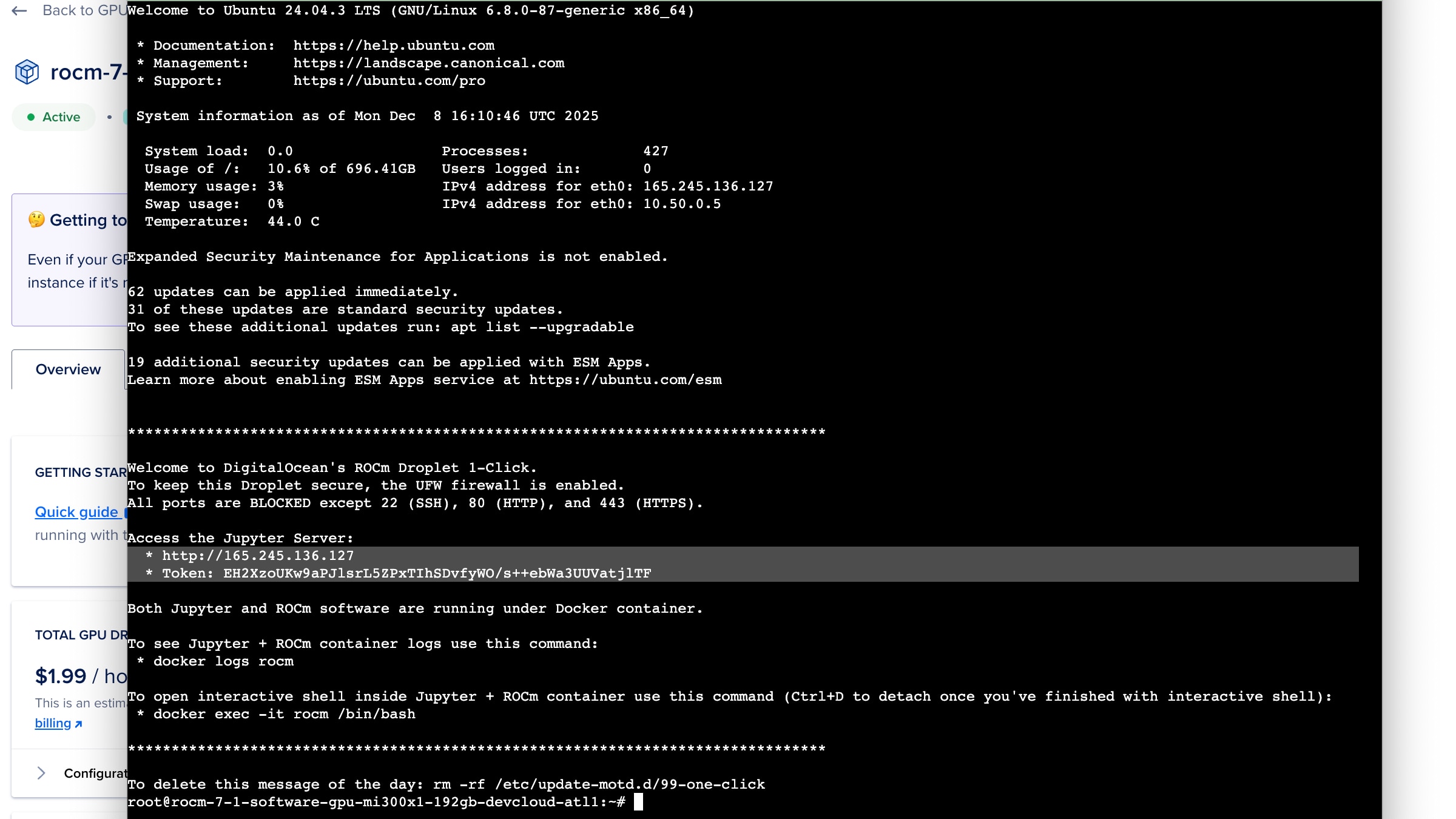
为 AMD GPU 构建 Qiskit-AER
执行环境已经准备就绪,现在可以构建 Qiskit-Aer 了。我们将使用 Qiskit-AER 的一个分支,该分支目前正在接受审核,后续将并入主项目。在本博文中,我们将使用 0.17.2-amd-rocm-dev 标签。
以下说明已添加到预加载的 Classiq Jupyter Notebook 中(详细说明见下文)。为保证完整性,下面列出了在 DevCloud 上构建 Qiskit-AER 所需使用的指令。
#set environment variables
%env ROCM_PATH=/opt/rocm
%env AER_THRUST_BACKEND=ROCM
%env QISKIT_AER_PACKAGE_NAME=qiskit-aer-gpu-rocm
%env ROCR_VISIBLE_DEVICES=0
%env HIP_VISIBLE_DEVICES=0
ulimit -s unlimited
## Get Git. Needed for Dev Cloud
apt-get update && apt-get install -y git
# pull rocm-qiskit-aer branch
mkdir quantum-sim && cd quantum-sim/
git clone https://github.com/coketaste/qiskit-aer.git
cd qiskit-aer/
git fetch origin tag 0.17.2-amd-rocm-dev
git checkout 0.17.2-amd-rocm-dev
# build rocm-qiskit-aer branch
rm -rf _skbuild dist build
pip install cmake pybind11 “conan<2” scikit-build
pip install -r requirements-dev.txt
python3 setup.py bdist_wheel -- \
-DCMAKE_CXX_COMPILER=/opt/rocm/llvm/bin/clang++ \
-DCMAKE_HIP_COMPILER=/opt/rocm/llvm/bin/clang++ \
-DAER_THRUST_BACKEND=ROCM
pip install --force-reinstall dist/qiskit_aer_gpu_rocm*.whl
pip install qiskit
# run sample benchmark
examples/single_gpu/benchmark.py
现在,我们已准备好在 Classiq Studio 平台中使用 AMD GPU 和 Qiskit-AER。
Classiq Studio 平台
Classiq 提供了多种高级编程方式。使用 Qmod 进行量子编程时,最常用的平台之一便是 Classiq Studio。这是一种基于 Visual Studio Code 的托管环境,专为 Classiq 编程而设计。在该平台中,用户还能利用 Classiq 特有的 AI 编码助手,该助手专为使用 Classiq SDK 进行编程而设计。
使用 Jupyter Notebook 对各种算法进行编程是十分普遍的做法。Classiq Studio 中具有用于线路执行和可视化的特定组件。这意味着,用户无需离开 Studio,即可检查自己创建的线路。这让每位量子开发者都能获得理想的一站式开发体验。
在 Classiq Studio 中,可以非常轻松地利用 AMD GPU 的强大功能。在 DevCloud 中设置 GPU 实例后,系统会默认运行一个 Jupyter Notebook 服务器。在 Classiq IDE 中,连接到外部 Jupyter Notebook 服务器非常简单,因此可轻松访问在 DevCloud 中运行的 AMD GPU 实例。
我们假设您拥有一个有效的 Classiq 帐户并已开通 Studio 访问权限。在 classiq.io 网站上,我们通过选择左侧第一个菜单项来打开 Studio(如图 10 所示)。

这将打开一个新的浏览器窗口。几分钟后,您将被重定向到一个托管 Visual Studio IDE 的网站。如图 11 所示,文件资源管理器分为两部分。Classiq Library 是一个只读部分,其中包含大量预加载资源,包括 Classiq 提供的示例和教程。本博文中使用的 Notebook 位于 Classiq Library > applications > telecom > resiliency_planning > resiliency_planning_AMD.ipynb。User Workspace 支持用户数据持久化,即跨会话保留数据。我们建议您将 Jupyter Notebook 复制到 User Workspace,以便在搭建执行环境之前进行进一步探索。顺带一提,该 Notebook 也可在 Classiq 资源存储库中找到。

在 Workspace 部分,将启动一个 Jupyter Notebook 环境。我们需要切换执行内核,以使用位于 AMD Developer Cloud 中的远程 Jupyter 服务器。如图 12 所示,可通过单击 Jupyter Notebook 界面右上角的 Select Kernel 来实现这一操作。

从弹出菜单中,选择“Existing Jupyter Server”(请参见图 13)。按照指示操作,使用之前由 AMD Developer Cloud 提供的 HTTP URL 以及相应的访问令牌。请注意,此访问令牌就是您最初通过浏览器访问 Jupyter Notebook 时所用的访问令牌。

设置完成后,我们现在可以直接在 AMD Developer Cloud 的 GPU 上运行 Classiq Jupyter Notebook。此配置至关重要,能让您在配备 Instinct GPU 的专用 AMD 服务器上充分发挥 Classiq SDK 和平台工具的全部功能。
代码结构与执行
编写用于生成量子线路的 Qmod 代码非常简单。Classiq 的 Python SDK 允许用户使用纯 Python 编写目标函数,而无需使用任何量子特定的构造函数。
以下是用纯 Python 编写的目标函数;此函数中调用的所有函数均可在完整 Notebook 中找到:
def cost_hamiltonian(assigned_Z):
return (
objective_func(assigned_Z)
+ node_resiliency(assigned_Z)
+ objective_minimal_resiliency(assigned_Z)
+ TotalConstraintNormalisation * (constraint_flow_conservation(assigned_Z))
)
在 QAOA 线路中,最重要的部分之一就是拟设,该拟设会将 cost_hamiltonian() 编码到量子线路中。借助 Classiq,创建这个量子线路非常简单。以下代码可根据 Python 目标函数创建量子线路。
@qfunc
def cost_layer(gamma: CReal, qba: QArray[QBit]):
phase(phase_expr=cost_hamiltonian(qba), theta=gamma)
要创建 QAOA 线路,我们可以使用 synthesize() 函数将高级代码综合成线路,如下所示:
qprog = synthesize(main)
qprog 变量现在包含我们程序的底层量子线路表示,其中包括一个 QASM 线路。此 QASM 线路可用于在 AMD GPU 上执行。执行流程如下(部分细节已省略,可在完整 Notebook 中查看):
# Convert the QASM string into a Quantum Circuit
qc = qasm3.loads(qasm_string)
# Add measurements
qc.measure_all()
# Tell the simulator to use the AMD GPU
sim = AerSimulator(device="GPU")
# Transpile the circuit to the GPU
qc_t = transpile(qc, sim)
最后,转译后的线路可以按如下方式执行:
bind_dict = make_aer_bind_dict(qc_t, samples)
job = sim.run(qc_t, shots=shots, memory=True, parameter_binds=[bind_dict])
res = job.result()
samples = res.get_memory(0)
在生成并执行线路后,算法就进入了最后的混合执行阶段。QAOA 线路包含多个参数;混合执行流程的目标是确定能够给出问题正确解的参数值。为此,我们将从一组简单的参数开始,并如前所述,逐步对这些参数进行调优。为运行此优化循环,我们使用 SciPy 来最小化哈密顿量的代价函数。要让这个流程顺利进行,我们首先需要通过一种方法来确定每次迭代的代价值。为此,我们使用以下函数:
def estimate_cost_func(params):
samples = qaoa_samples(params)
samples = [[int(c) for c in row] for row in samples]
shot_costs = np.array([cost_hamiltonian(s) for s in samples], dtype=float)
objective_val = shot_costs.mean()
print(f"Cost Hamiltonian = {np.round(objective_val, decimals=3)}")
return objective_val
在运行最小化优化之前,我们需要一组初始参数,其计算方法如下:
def initial_qaoa_params(NUM_LAYERS) -> np.ndarray:
initial_gammas = math.pi * np.linspace(
1 / (2 * NUM_LAYERS), 1 - 1 / (2 * NUM_LAYERS), NUM_LAYERS
)
initial_betas = math.pi * np.linspace(
1 - 1 / (2 * NUM_LAYERS), 1 / (2 * NUM_LAYERS), NUM_LAYERS
)
initial_params = []
for i in range(NUM_LAYERS):
initial_params.append(initial_gammas[i])
initial_params.append(initial_betas[i])
return np.array(initial_params)
initial_params = initial_qaoa_params(NUM_LAYERS)
此时,我们已经找到在 AMD GPU 上执行代码的方法,并拥有了一组初始参数,而且能够针对这组特定参数确定每次运行的代价。现在,我们可以开始进行参数调优。具体操作方式如下:
optimization_res = minimize(
estimate_cost_func,
x0=initial_params,
method="COBYLA",
options={"maxiter": MAX_ITERATIONS},
)
完成后,optimization_res 变量应包含最优参数值。
完整代码在 Notebook 中提供。
结果与分析
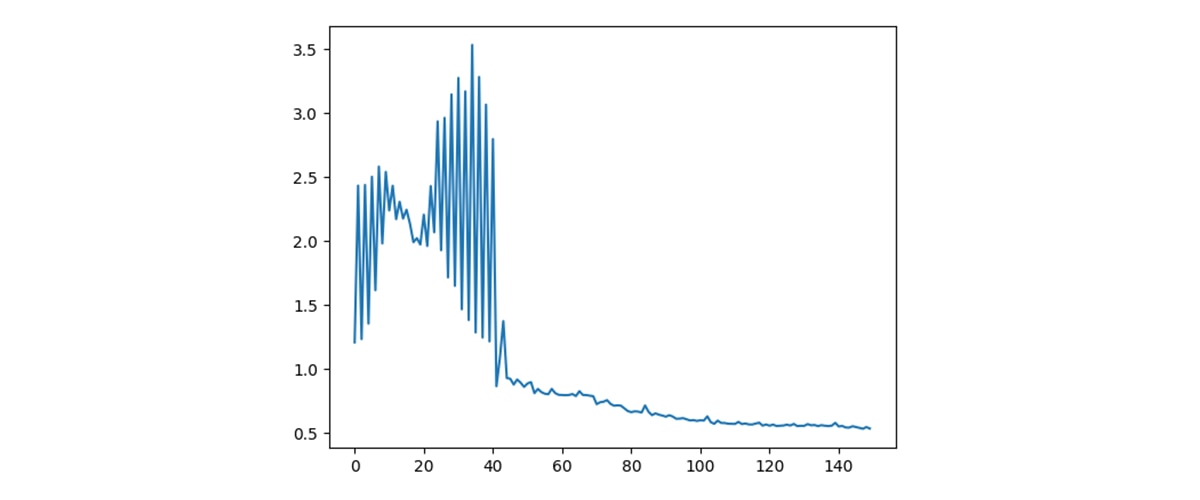
通过传统优化循环确定最优 QAOA 参数后,我们即可用这些参数执行线路,以获得候选路由解。如图 14 所示,混合优化过程会使代价哈密顿量数值随迭代轮次稳步下降。在初始探索阶段,代价数值出现明显振荡,之后逐步收敛至稳定的最小值。这种行为体现了 QAOA 中混合层与代价层的协同作用:随着参数持续迭代更新,量子态会逐步趋向最优配置,即满足流量守恒、路径无交叉约束、链路关联惩罚等条件,同时实现整体延迟最小化。
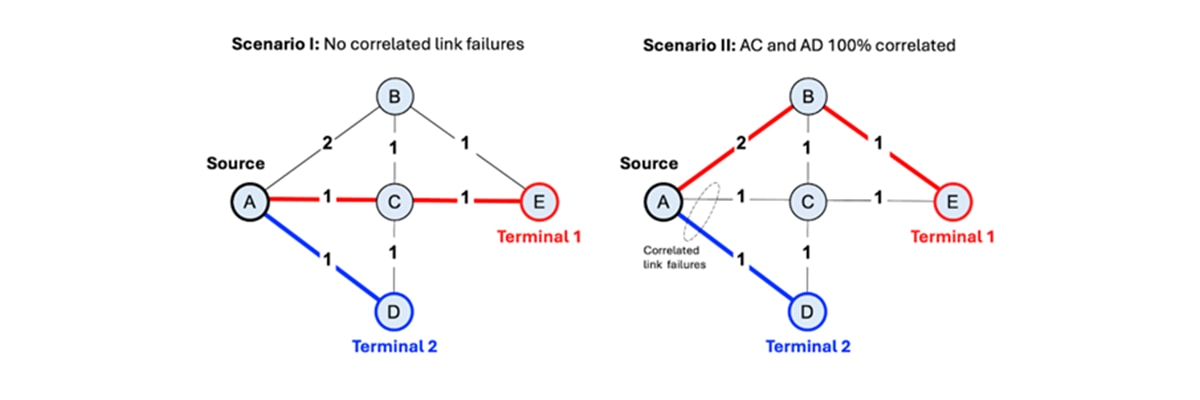
我们针对前面所述的两种场景评估了该算法。在场景 I 中,即不存在链路关联的情况下,仿真器将返回从源站点到两个终端站点的一对最短且互不相交的路径,在满足所有约束条件的同时,使总延迟最小化。在场景 II 中,边 AC 和边 AD 完全关联,即便单从延迟角度来看这两条链路具备优势,优化器仍会避免同时选用这两条链路。返回的解会自动对其中一条路径进行重路由,以规避关联故障风险,这也证明嵌入在哈密顿量中的惩罚项能够有效重塑系统能量分布态势。在两种场景下,采样频次最高的比特串均对应有效且满足全部约束的流量路由方案,这表明 QAOA 线路可同时编码路由问题的优化目标与结构要求。
图 15 展示了双链路故障场景对应的两种最优解,这两种解均是 QAOA 返回的最高频率解(概率约为 1%)。请注意,鉴于整个解空间共包含 224 种组合,因此 1% 的概率属于强有效信号。
除了上述示例之外,该仿真框架还支持扩展到更大规模的实例。高性能的 AMD 显卡凭借其大容量显存,可在单张显卡上运行超大规模量子线路。这使得快速、大规模的运行成为可能,非常适合此类混合场景。通过在仿真器中利用 AMD GPU 加速技术,我们可以将问题处理规模扩大到 7 节点配置,其中包含一个源节点和两个终端节点,这些节点最多需要 32 个量子比特。尽管本文未展示这类规模更大的实例,但这种能力表明,通过将 Classiq 中的高级建模功能与 GPU 加速的量子态向量仿真相结合,能够探索远超纯 CPU 环境可实现的超大规模解空间。
结语
本博文介绍了一种可落地应用的完整工作流程,即如何完全依托 AMD GPU,利用量子近似优化算法 (QAOA) 解决网络弹性问题。我们首先展示了 QAOA 设计模式在这一特定挑战中的实用价值。接下来,我们重点展示了基于 Classiq 平台实现算法的便捷性,Classiq Python SDK、QMod 以及 Classiq Studio 平台等工具能够以简单的高级语法实现算法。最后,我们通过在 AMD Instinct GPU 上执行量子线路,展示了该 GPU 硬件的强大功能。凭借庞大的显存容量,该 GPU 能够支持更大规模的量子比特,就当前存在的量子硬件访问限制而言,这是一项显著优势。这项探索工作也为行业提供了实践参考:依托 Classiq 高级软件基础设施与 AMD 高性能硬件的整合优势,可积极探索量子应用并为未来发展做好准备。
如果您有任何疑问或想要了解更多信息,请联系我们:quantum@amd.com、maher.harb@gmail.com
附注
参考资料
1. M. Harb, N. Foroughi, M. Stehman, B. Lutz, N. Erez, and E. Garcell, “Quantum-Based Resilient Routing in Networks: Minimizing Latency Under Dual-Link Failures,” https://arxiv.org/abs/2602.04495.
附注
参考资料
1. M. Harb, N. Foroughi, M. Stehman, B. Lutz, N. Erez, and E. Garcell, “Quantum-Based Resilient Routing in Networks: Minimizing Latency Under Dual-Link Failures,” https://arxiv.org/abs/2602.04495.


Related Blogs
-
Gartner 将 AMD 评为 Gartner® AI 供应商竞争中的当前领先企业
Gartner 在一份报告中将 AMD 称为企业级 AI 服务器 CPU 领域的当前领跑者。
June 24, 2026
-
-
AMD Computex 2026:AM4 十周年,AM5 支持延长至 2029 年,RDNA 4 游戏阵容再持续扩展
AMD Computex 2026:AM4 十周年,AM5 支持延长至 2029 年,RDNA 4 游戏阵容再持续扩展,发布锐龙和 Radeon 产品。
May 31, 2026
-
跳出概念炒作:将 AI PC 的潜在价值转化为切实商业收益
AI PC 正在重塑企业战略。了解 AMD 计算连续体如何帮助首席信息官跳出概念炒作,通过部署 AI 创造切实商业价值。
April 23, 2026
-
基于 AMD 锐龙 AI Max+ 处理器和 Radeon GPU,在本地高效运行 Hermes Agent
本指南演示了如何在配备 AMD 锐龙 AI Max+ 处理器和 Radeon GPU 的 Windows 系统上,使用 WSL2 和 LM Studio 运行 Hermes Agent。
April 21, 2026
-
使用 Windows ML 在 AMD NPU 上部署 AI 模型
设备端 AI 的兴起已重塑智能应用构建方式。借助 Windows ML 和 AMD 锐龙 AI NPU,开发者现在可以直接在 Windows 设备上部署高性能 AI 模型,从而加快推理速度、增强隐私保护并降低延迟。本博客将探讨如何利用 Windows ML 在 AMD NPU 上部署 ONNX 模型,内容涵盖从环境设置到执行的全过程。
April 20, 2026
-
为现代工作室的生产引擎添能助力:AMD 亮相 NAB 2026
2026 年美国广播电视展 (NAB Show) 将于 4 月 18 日至 22 日在拉斯维加斯举行。整个行业正发生着令人振奋的新变化,我们期待在展会上与您相见!
April 17, 2026
-
算力决定规模:MediaKind 与 AMD EPYC(霄龙)平台
了解 MediaKind 如何利用 AMD EPYC(霄龙)服务器 CPU,将软件定义的视频基础设施从本地扩展到云端。
April 17, 2026







