
- 概观
- 开始体验
配置
AMD Vitis™ BLAS 库提供:
- 标准基本线性代数子例程 (BLAS) 的快速 FPGA 加速实现
- 用 C、C++ 和 Python 编写的高层次软件接口,无需任何额外的硬件配置,即可轻松使用
- 用 HLS 编写的低层次硬件接口,可实现更大的灵活性和控制能力
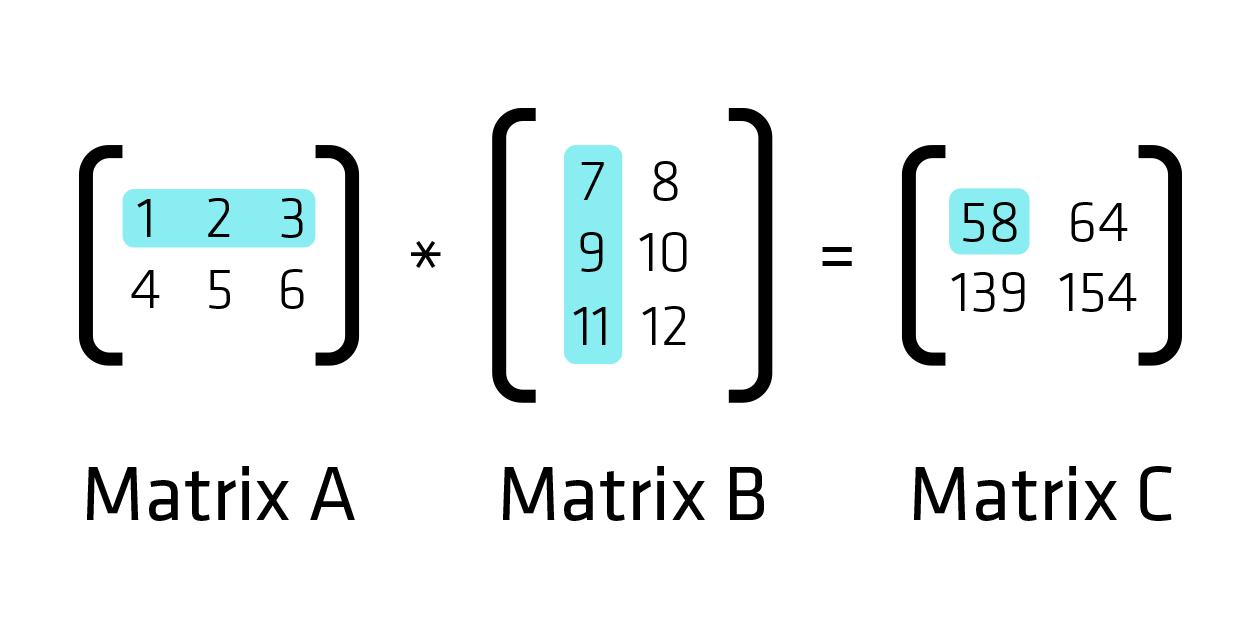
功能
Vitis BLAS 库包含以下矩阵和矢量运算函数:
矩阵运算函数:
- 一般矩阵乘法
矢量运算函数:
- 搜索矢量元素位置
- 累加矢量元素的大小
- 计算两个矢量的点积
- 计算矢量标量积
- 计算矢量的欧氏范数
- 交换、缩放、复制矢量
矩阵矢量运算的函数:
- 一般矩阵矢量乘法
- 一般带状矩阵矢量乘法
- 对称矩阵和矢量乘法
- 三角矩阵和矢量乘法
函数实现类型
Vitis BLAS 库提供三种类型的函数实现方案,即 L1 原语函数、L2 内核函数和 L3 软件 API 函数。FPGA 硬件开发者可利用 L1 原语函数。L2 内核函数通过整合 L1 原语函数和数据移动器构建而成,可通过 Vitis 运行时库由主机代码调用。L3 软件 API 函数提供 C、C++ 和 Python 函数接口,允许纯软件开发者将 BLAS 运算交由 AMD 平台完成,无需其他与硬件相关的配置。下表列出了一部分这三种类型的函数。请注意,Vitis BLAS 库目前不提供任何在 Versal AI Engine 上运行的函数。
| Vitis BLAS 库函数 | L1 原语函数 |
|---|---|
| amax、amin:搜索矢量元素位置 | |
| asum:累加矢量元素的大小 | |
| dot:计算两个矢量的点积 | |
| axpy:计算矢量标量乘积并添加到矢量 | |
| nrm2:计算矢量的欧氏范数 | |
| swap、scal、copy:交换、缩放或复制矢量 | |
| symv:对称矩阵和矢量乘法 | |
| trmv:三角矩阵和矢量乘法 | |
| L2 内核函数 | |
| Gemm 类:一般矩阵乘法 | |
| Gemv 类:一般矩阵矢量乘法 | |
| L3 软件 API 函数 | |
| xfblasCreate:初始化库并创建句柄 | |
| xfblasFree:释放 FPGA 器件中的内存 | |
| xfblasGetMatrix:将 FPGA 器件内存中的矩阵复制到主机 | |
| xfblasExecute:启动内核并等待其完成 | |
| 注意:完整的 L3 软件 API 函数列表和简介可在此处找到。 |
如欲详细区分 L1 原语与 L2 内核函数,请参见下表。
L1 原语函数 |
|
L2 内核函数 |
|
L3 软件 API 函数 |
|
组织
Vitis BLAS 库提供三种类型的函数实现方案,即 L1 原语函数、L2 内核函数和 L3 软件 API 函数。FPGA 硬件开发者可利用 L1 原语函数。L2 内核函数通过整合 L1 原语函数和数据移动器构建而成,可通过 Vitis 运行时库由主机代码调用。L3 软件 API 函数提供 C、C++ 和 Python 函数接口,允许纯软件开发者将 BLAS 运算交由 AMD 平台完成,无需其他与硬件相关的配置。下表列出了一部分这三种类型的函数。请注意,Vitis BLAS 库目前不提供任何在 Versal AI Engine 上运行的函数。
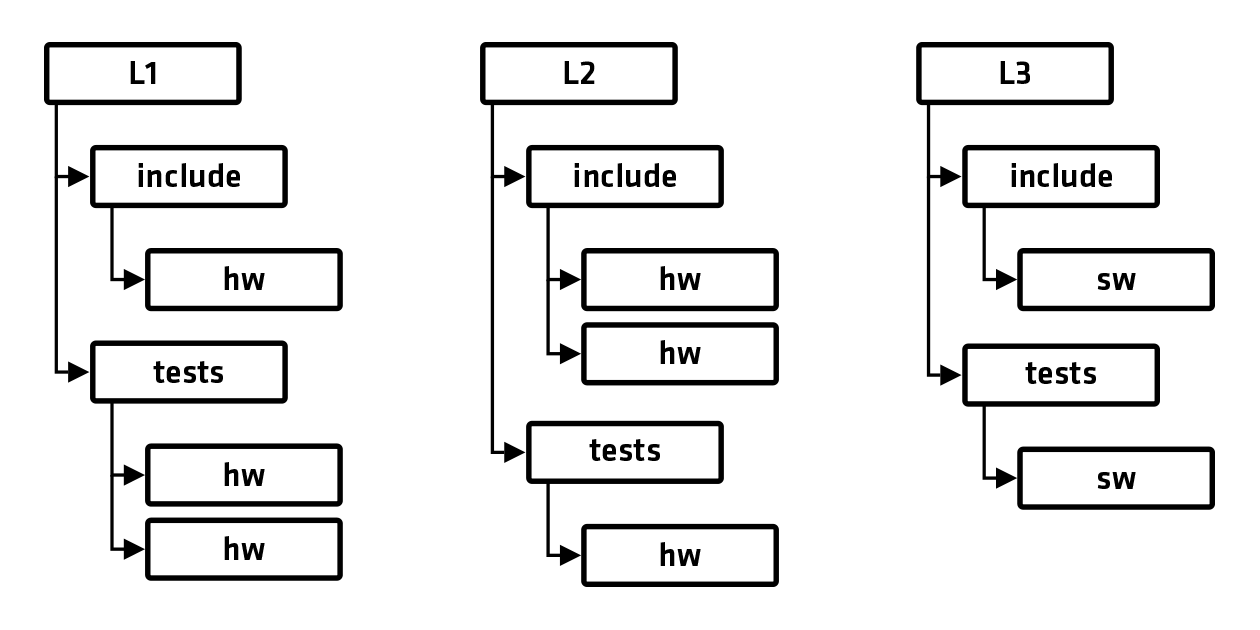
对于 L1 子目录:
- include/hw:基元函数的头文件
- tests/hw:包括数据移动器和原语函数在内的顶层模块
- tests/sw:针对调用原语函数的测试激励文件和基础设施支持
对于 L2 子目录:
- include/hw:内核函数的头文件
- include/sw:用于调用内核函数的主机模块
- tests/hw:包含用于构建已实现的每个内核函数的 Makefile
对于 L3 子目录:
- include/sw:软件 API 函数的头文件
- tests/sw:包含用于测试已实现的每个软件 API 函数的 Makefile
在 Vitis IDE 中执行
Vitis GitHub 仓库中可用的库可以使用为 L2 和 L3 函数提供的 Makefile(如上所述)或 Vitis IDE 进行编译。要在 IDE 中使用该库,必须首先将其作为库模板下载,然后必须使用该模板创建一个新的 Vitis 项目。有关使用 Vitis 图形用户界面中的库模板创建 L2 或 L3 应用的更多信息,请点击此处。