在AMD锐龙AI Max+处理器和Radeon GPU上本地运行OpenClaw
AMD AI 事业部,Usman Pirzada 对本文有贡献
2026年3月13日

多年来,强大的AI模型主要部署在云端,通过远程API和服务进行访问。但随着本地硬件性能的提升以及推理软件栈的优化正开始改变这种模式,使得直接在个人系统上运行高性能的大语言模型成为可能。这一转变也催生了一个被称为"智能体计算机(Agent Computer)"的新计算类别。与传统个人计算机不同,这类设备的主要用户不再是人类,而是AI智能体。
随着AMD锐龙AI Max+ 这类平台的出现,像Qwen 3.5 122B这样的模型也可以在本地实现高性能运行,同时支持单智能体和多智能体工作负载,这标志着AI正从过去依赖云端的模式,转向如今更强大的本地AI系统。

虽然运行和安装OpenClaw有多种方式,但对于Windows用户来说,这些方法可能存在一些取舍或功能缺失。通过WSL2部署OpenClaw的AMD最佳已知配置(BKC)提供了一种更简化的方法,使用户无需离开熟悉的Windows环境,就能直接在AMD硬件上运行本地AI智能体和大语言模型工作负载。该配置通过使用基于llama.cpp的LM Studio,实现了完全本地化的LLM部署,并通过本地embedding提供Memory.md的功能支持。

浏览器控制运行在WSL2环境中,可实现自动化工作流程和智能体交互。整个环境可在一小时内完成配置,专为尝试个人AI智能体和本地开发工作流程的早期用户而设计。
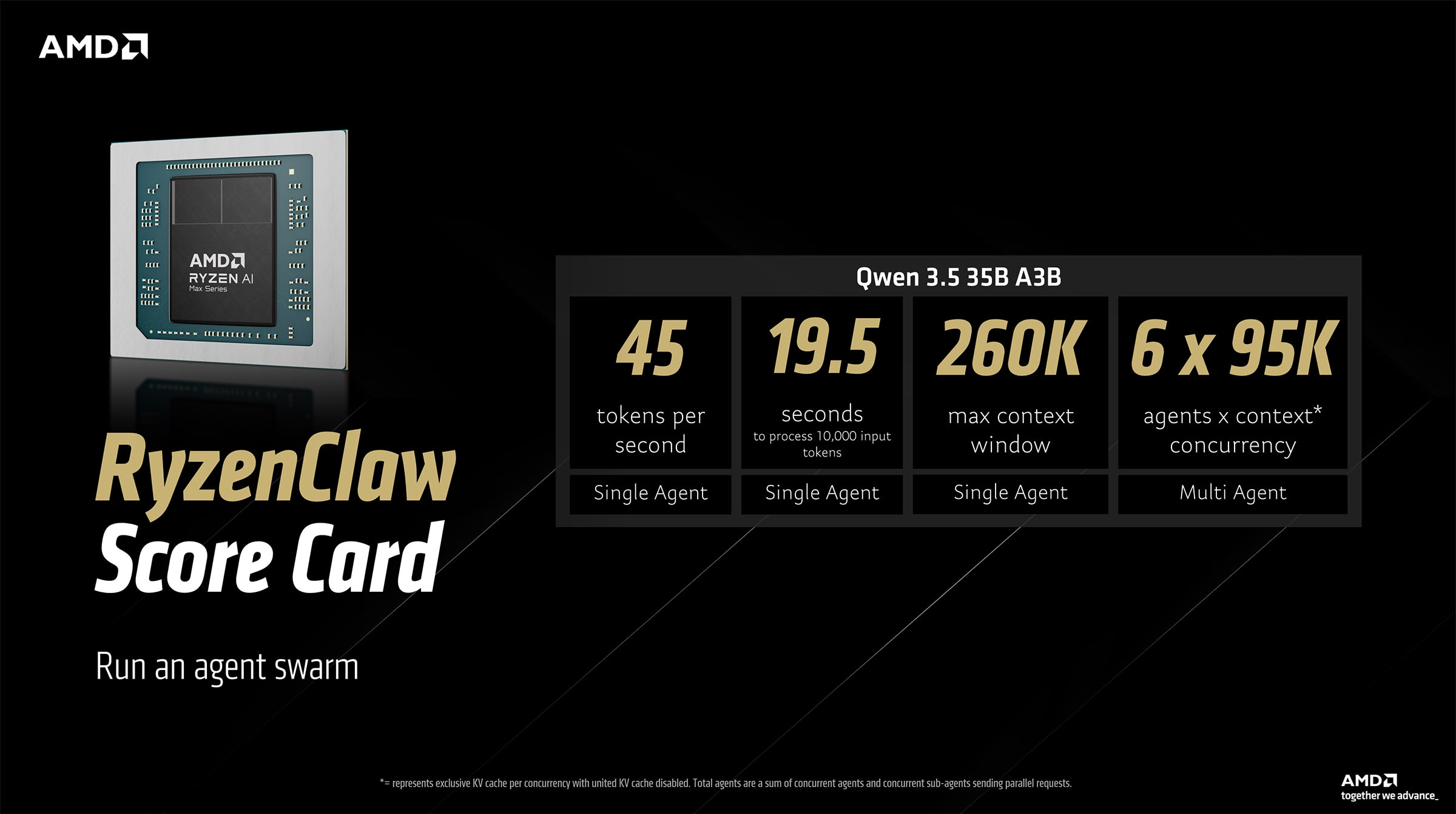
RyzenClaw 配置(又称配备 128GB 统一内存的 AMD 锐龙 AI Max+ 系统)可从各个 AMD 合作伙伴处购得。可在此处查看相关产品:智能体计算机
RyzenClaw评分卡展示了搭载128GB统一内存的AMD锐龙 AI Max+平台,能够通过OpenClaw高效运行接近云端质量的AI智能体工作负载。在运行Qwen 3.5 35B A3B模型时,系统可实现约45 tokens/s 的生成速度,处理10,000个输入token仅需约19.5秒。该平台支持最高26万 token 的最大上下文窗口,并且最多可同时运行6个智能体。这使得在消费级硬件上进行可扩展的本地AI实验(例如Agent swarm/多智能体协作)成为可能,同时仍能保持良好的响应速度。

RadeonClaw 配置(即 AMD Radeon AI PRO R9700 显卡)可从各个 AMD 合作伙伴处购得。
RadeonClaw评分卡展示了在AMD Radeon AI PRO R9700显卡上运行相同工作负载时所带来的性能提升。在运行Qwen 3.5 35B A3B 模型时,系统可实现约120 tokens/s 的生成速度,处理10,000个输入token仅需约4.4秒。该配置支持19万token的上下文窗口,并且最多可同时运行2个智能体。这一结果显著提升了本地智能体推理的响应速度。
如何在AMD锐龙 AI Max+处理器或Radeon显卡上设置并运行OpenClaw
接下来,我们将一步步演示如何搭建该环境。
预计跟随步骤完成安装所需时间:约1小时。

安装最新驱动并设置 AMD 可变显存
- 下载并安装最新的AMD Software: Adrenalin™ Edition驱动程序。
- 拥有AMD Radeon显卡的用户请跳过此步骤。对于基于AMD锐龙AI Max+128GB平台的用户:在桌面任意位置右键 → AMD Software: Adrenalin Edition → Performance(性能) → Tuning(调整) → Variable Graphics Memory(可变显存) → 设置为96GB并重启。
LM Studio安装与正确配置
初始设置
- 下载LM Studio
- 启动LM Studio,在模型下载提示处点击“Skip for now(暂时跳过)"。
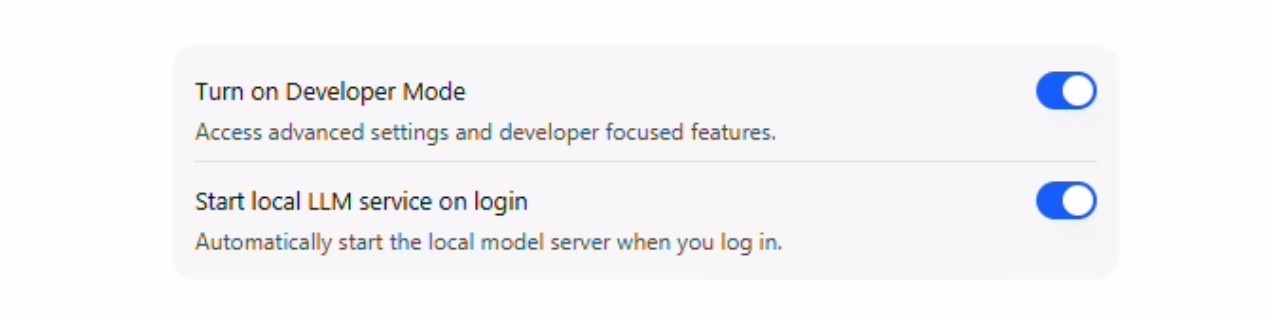
- 勾选"Developer Mode(开发者模式)"和"Start LLM service login(登录时启动LLM服务)"。
- 点击"Model Search(模型搜索)"图标(机器人搭配放大镜的符号)。
- 在左侧选择 “Qwen 3.5 35B A3B”,然后在右侧点击下载,等待下载完成。
- 按下Ctrl+L调出模型选择界面。勾选"Manually choose load model parameters(手动选择加载模型参数)",然后点击对应的大语言模型以调出加载选项。
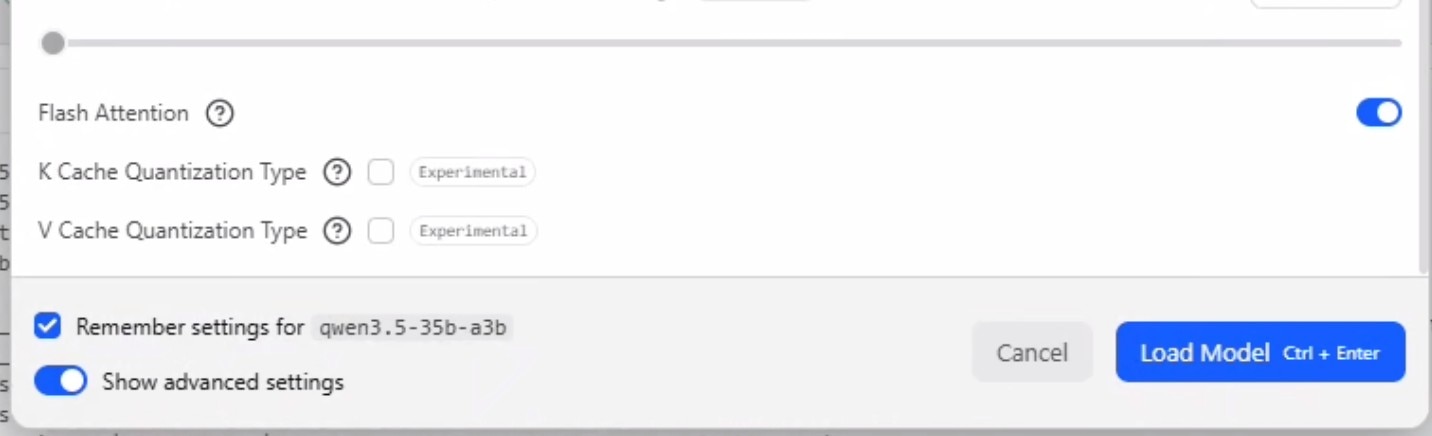
- 勾选"remember settings(记住设置)"并勾选"show advanced setting(显示高级设置)"。
- 将上下文窗口设置为190000,并确保GPU卸载已设为最大。
- 取消勾选"尝试使用nmap"。
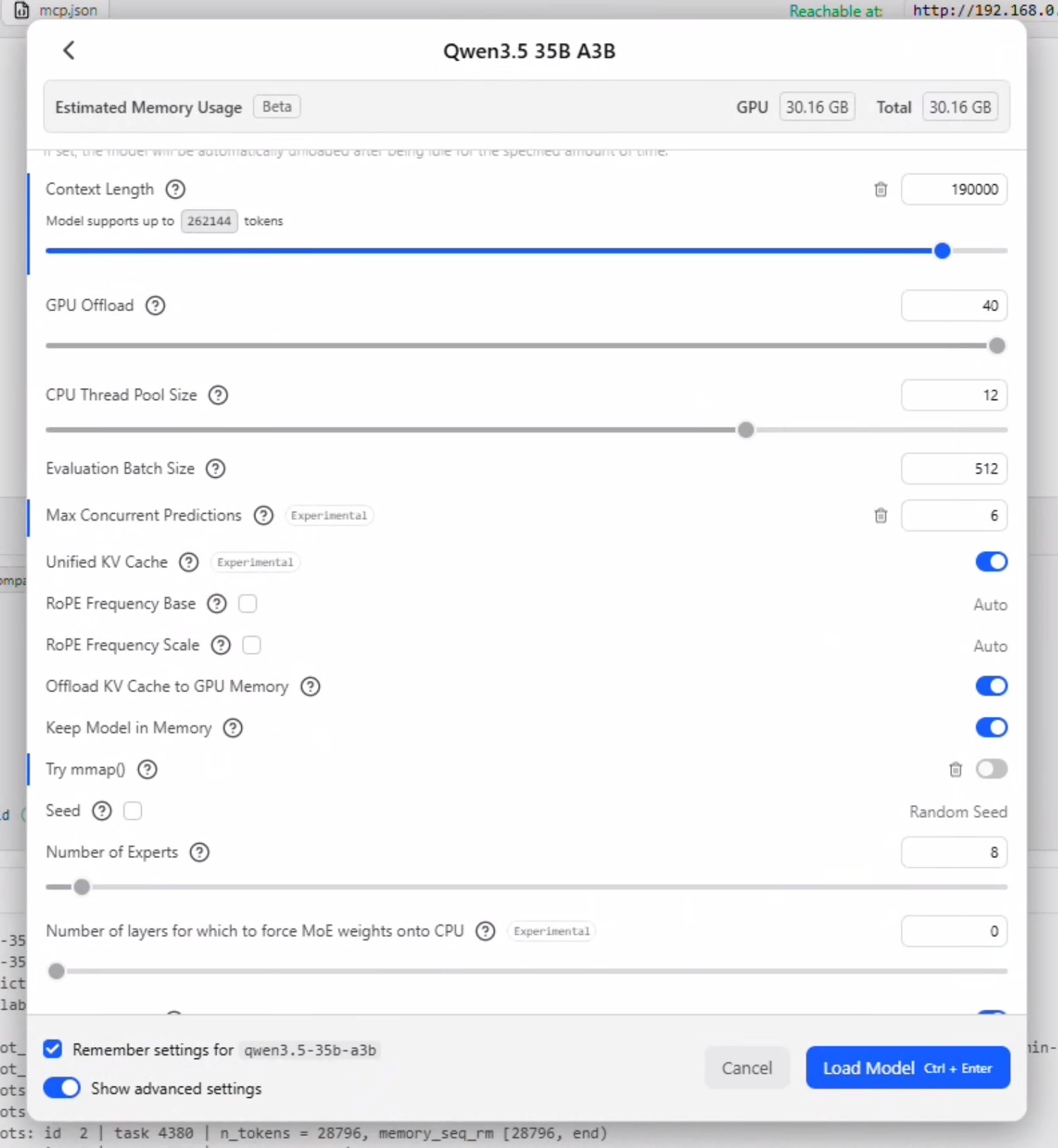
最大并发预测(Max Concurrent Prediction) 指的是模型能够接受的并行请求数量。该值应设置为 OpenClaw 中以下设置的总和:[最大并发智能体个数] + [最大并发智能体个数 * 最大并发子智能体个数]。因此,如果您的 openclaw.json 文件配置为 2 个并发智能体和 2 个并发子智能体,则此字段应设置为 6。
禁用统一 KV 缓存(Unified KV Cache): 禁用此选项允许每个智能体拥有独立的 KV 缓存(Key-Value Cache) 和 上下文窗口(Context Window),但这会随着并行请求数量的增加而显著加大显存占用(Memory Utilization)。保持启用统一 KV 缓存则让所有智能体共享同一个窗口,因此不会对显存利用率产生额外影响。
- 确保已启用"Flash Attention"。
- 关于"最大并发预测"和"统一KV缓存"的详细说明,请参阅上文中的并发智能体逻辑。目前,我们将"最大并发预测"设置为6,并保持勾选"统一KV缓存"。
- 点击加载
- 如果模型未在列表中显示,您可能需要再次从下拉菜单中选择该模型。
- 启动聊天窗口,并发送消息"test",以确认大语言模型是否正常工作。
服务器设置与崩溃防护加固
- 请按Ctrl+2切换到开发者标签页。
- 点击"status: Stopped"前的开关以启动服务器。
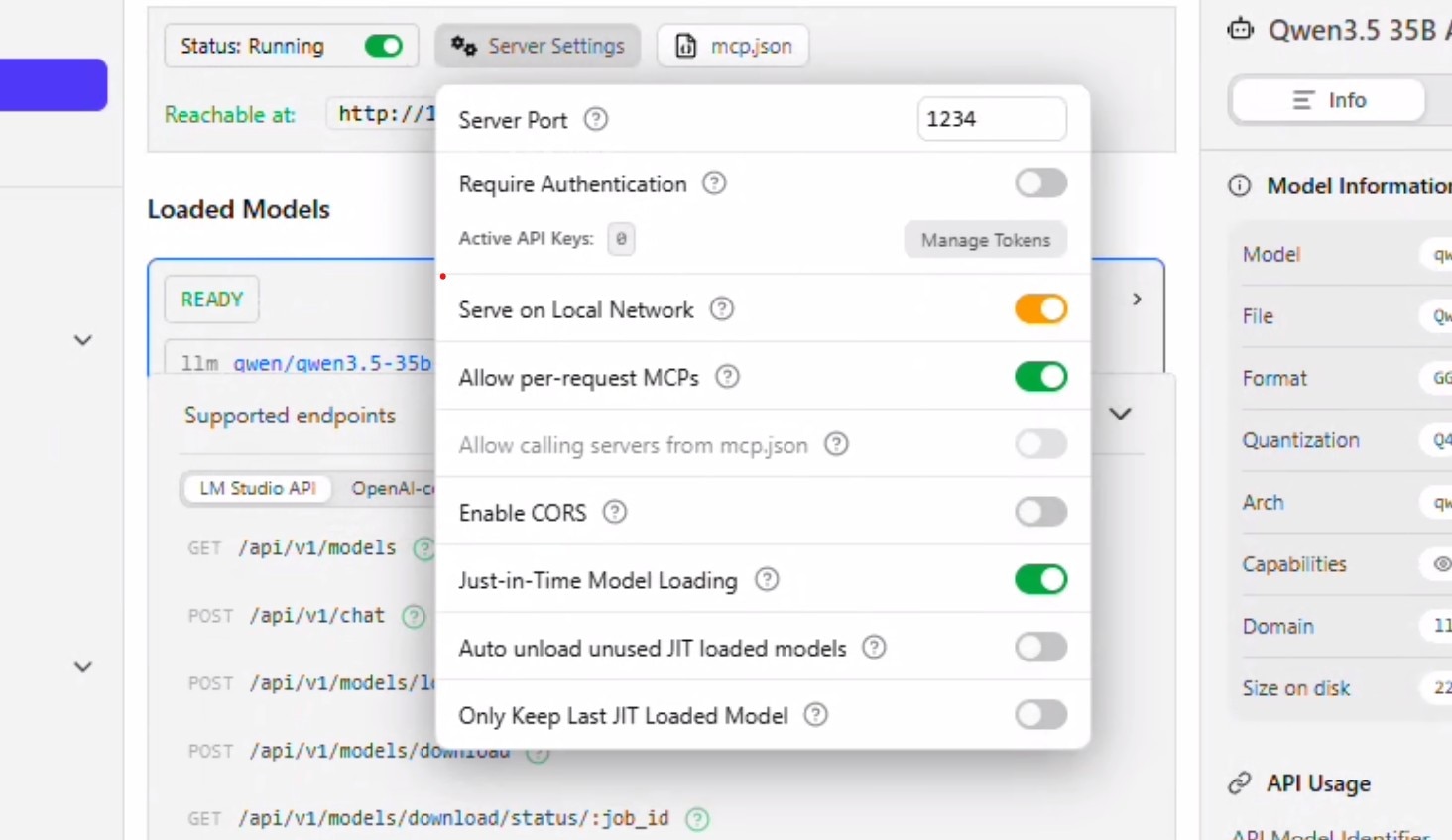
- 点击 “Server Settings(服务器设置)”。
- 允许 “Serve on Local Network(在本地网络上提供服务)”。此时系统会提示您进行权限确认。
- 取消勾选 “Auto unload unused JIT loaded models(自动卸载未使用的 JIT 加载模型)” 和 “Only keep last JIT loaded model(仅保留最后加载的 JIT 模型)”,然后点击任意位置关闭设置窗口。
- 点击Load Model(加载模型),选择Qwen 35B A3B。此前配置的设置应会自动填充,然后点击 “Load(加载)”。
- 模型加载完成后,状态将显示为“READY”。
- 保持此窗口打开,然后继续下一步操作。
安装WSL2及OpenClaw核心组件
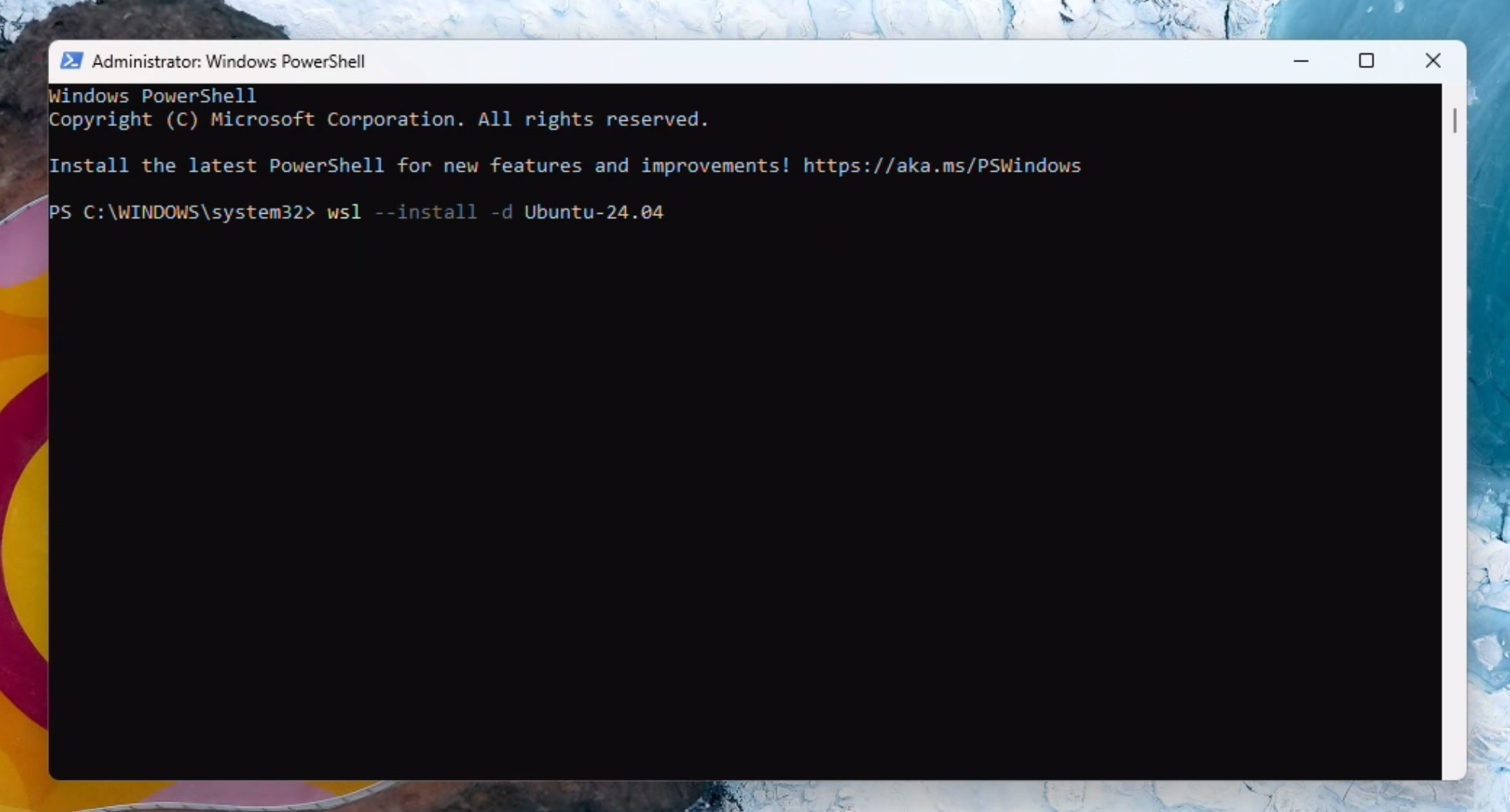
以管理员身份打开PowerShell窗口。
安装Ubuntu(如果这是您第一次运行此命令,系统将会先安装WSL):
wsl --install -d Ubuntu-24.04
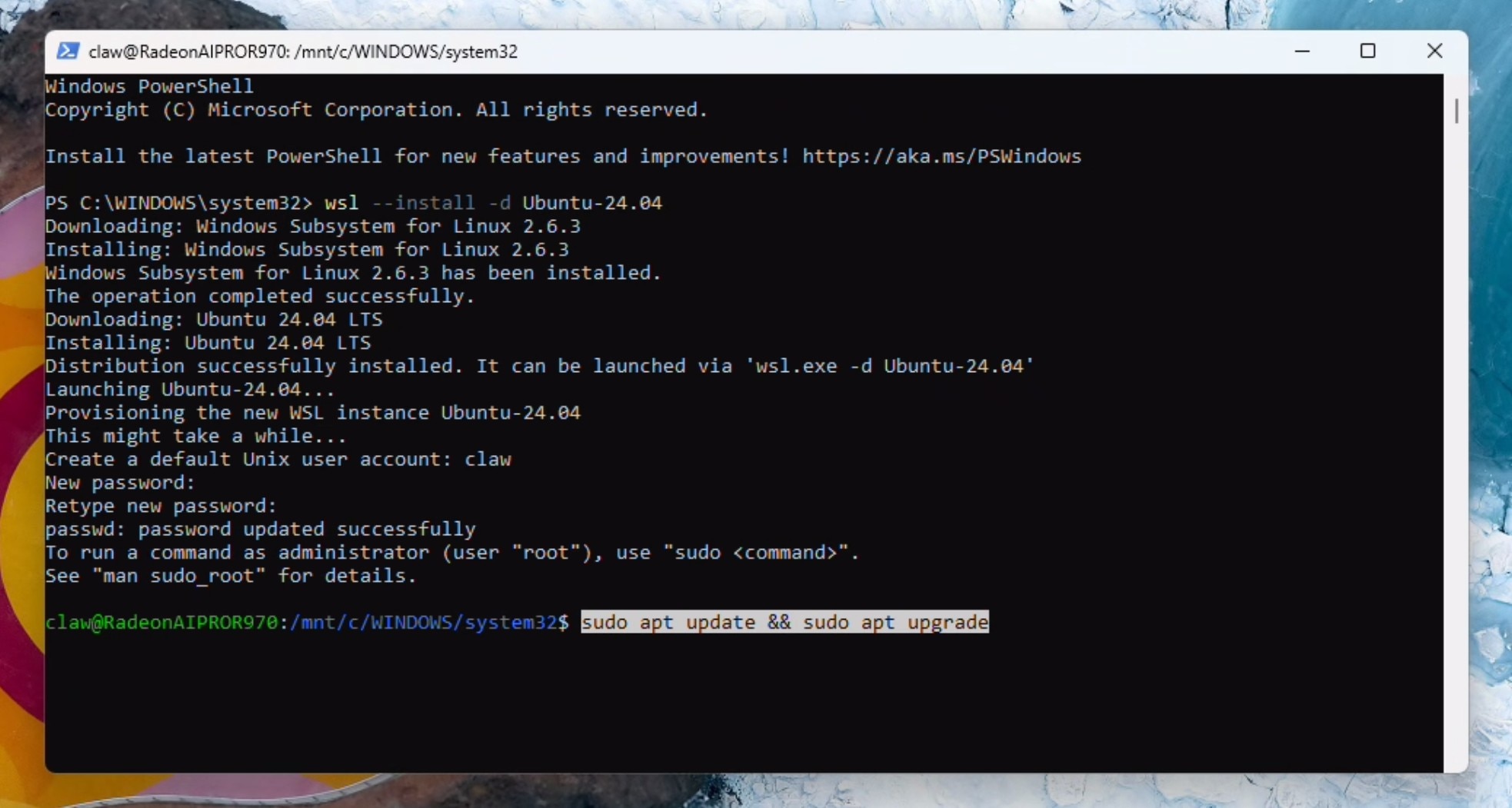
创建用户名和密码,然后运行更新。系统可能会提示您输入密码,并按 Y 继续。
sudo apt update && sudo apt upgrade
启用Systemd
sudo tee /etc/wsl.conf >/dev/null <<'EOF'
[boot]
systemd=true
EOF
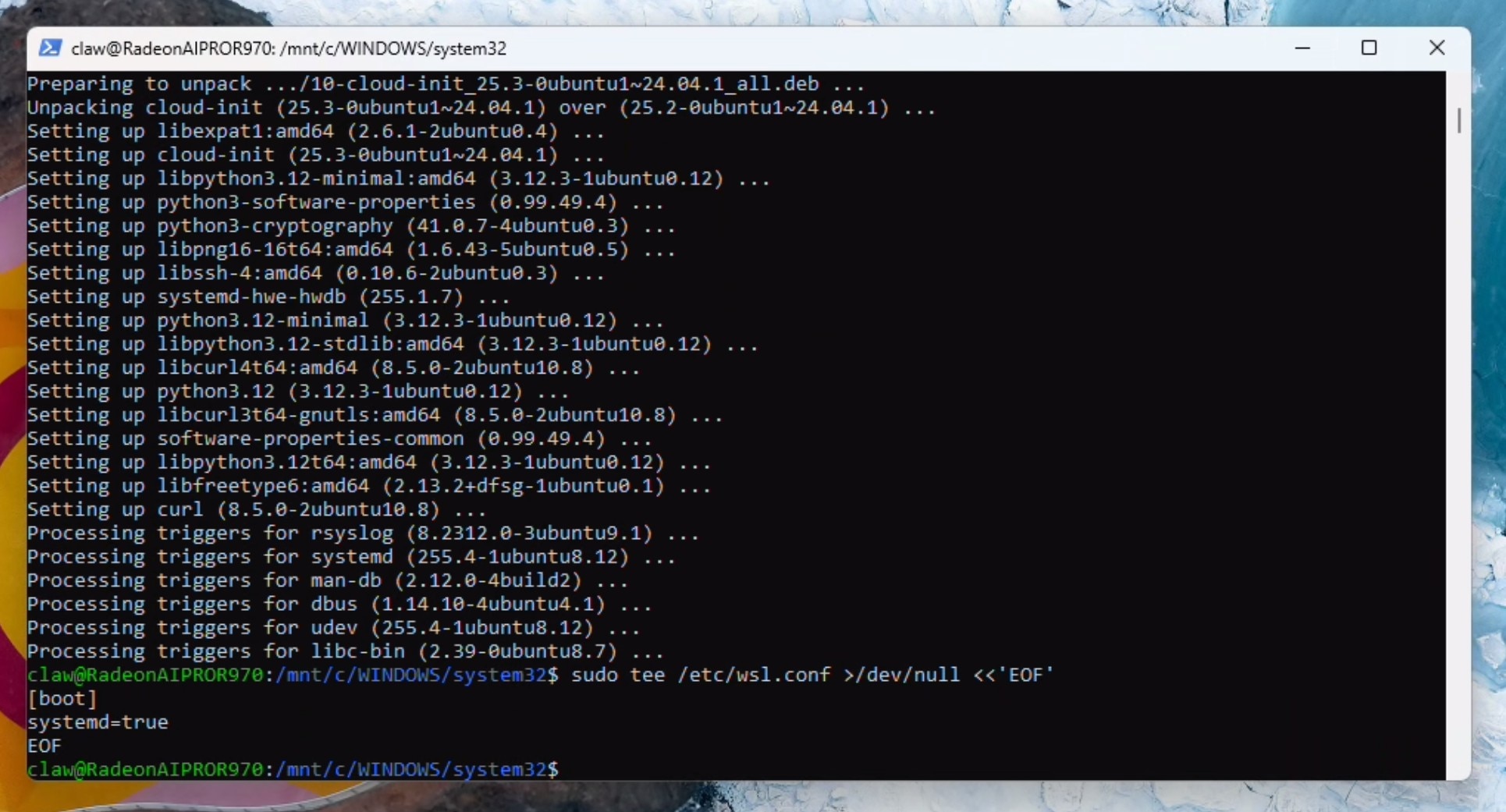
打开第二个PowerShell 窗口(以管理员身份),然后运行以下命令:
wsl --shutdown
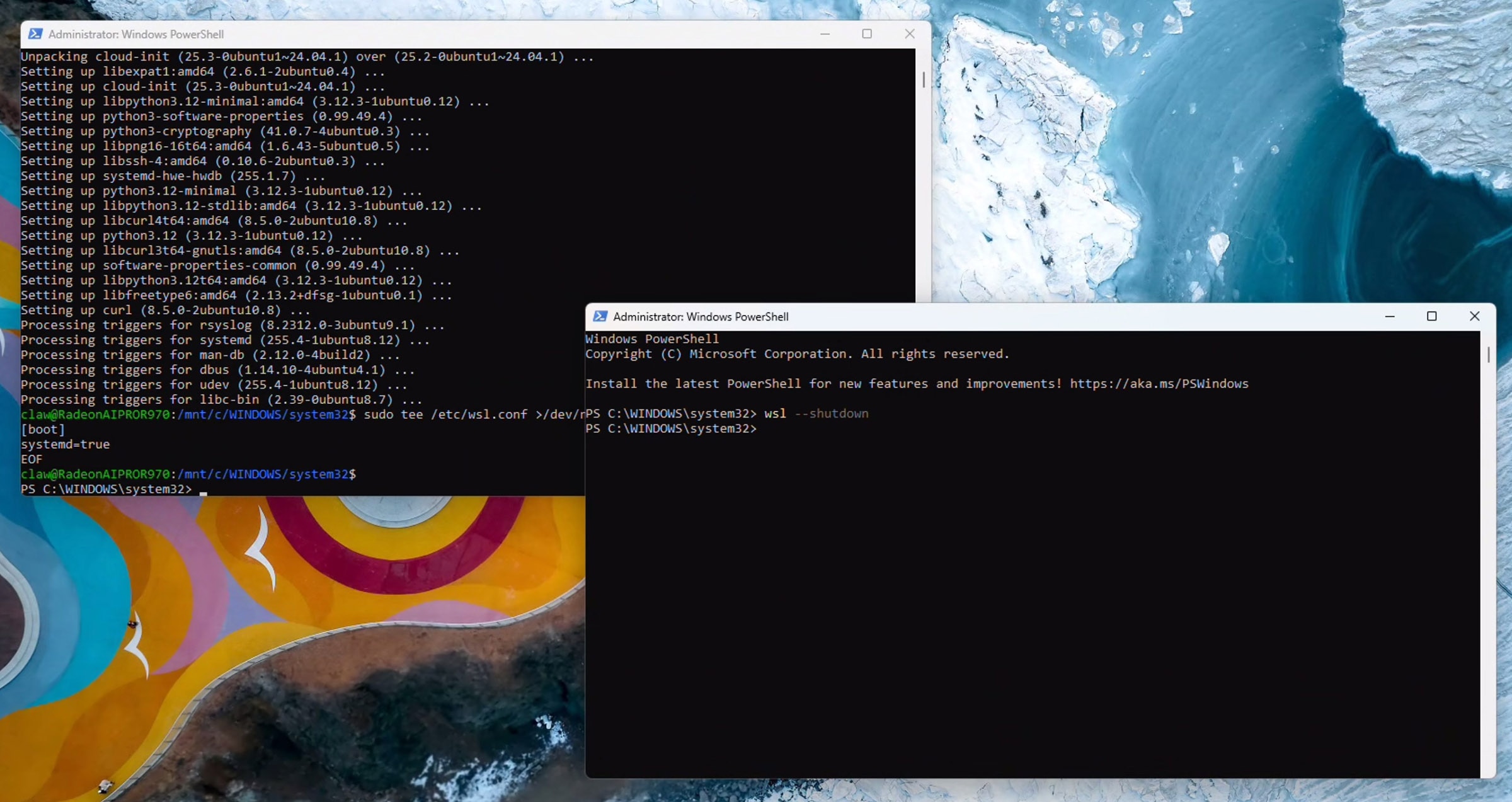
返回到原先的PowerShell 窗口(从现在起保持在此窗口),然后运行:
wsl.exe
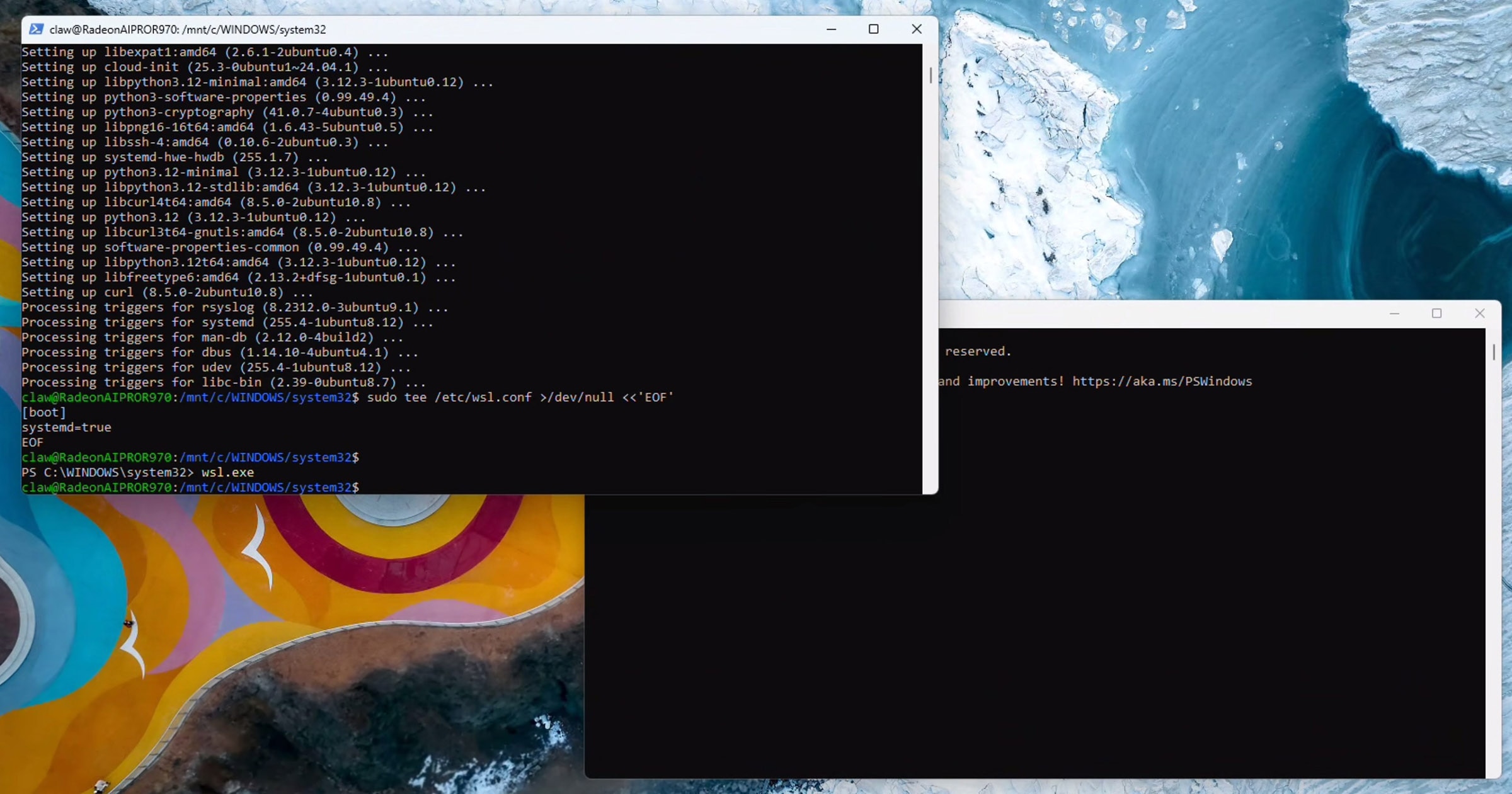
通过执行以下命令验证systemd是否正在运行:
ps -p 1 -o comm=
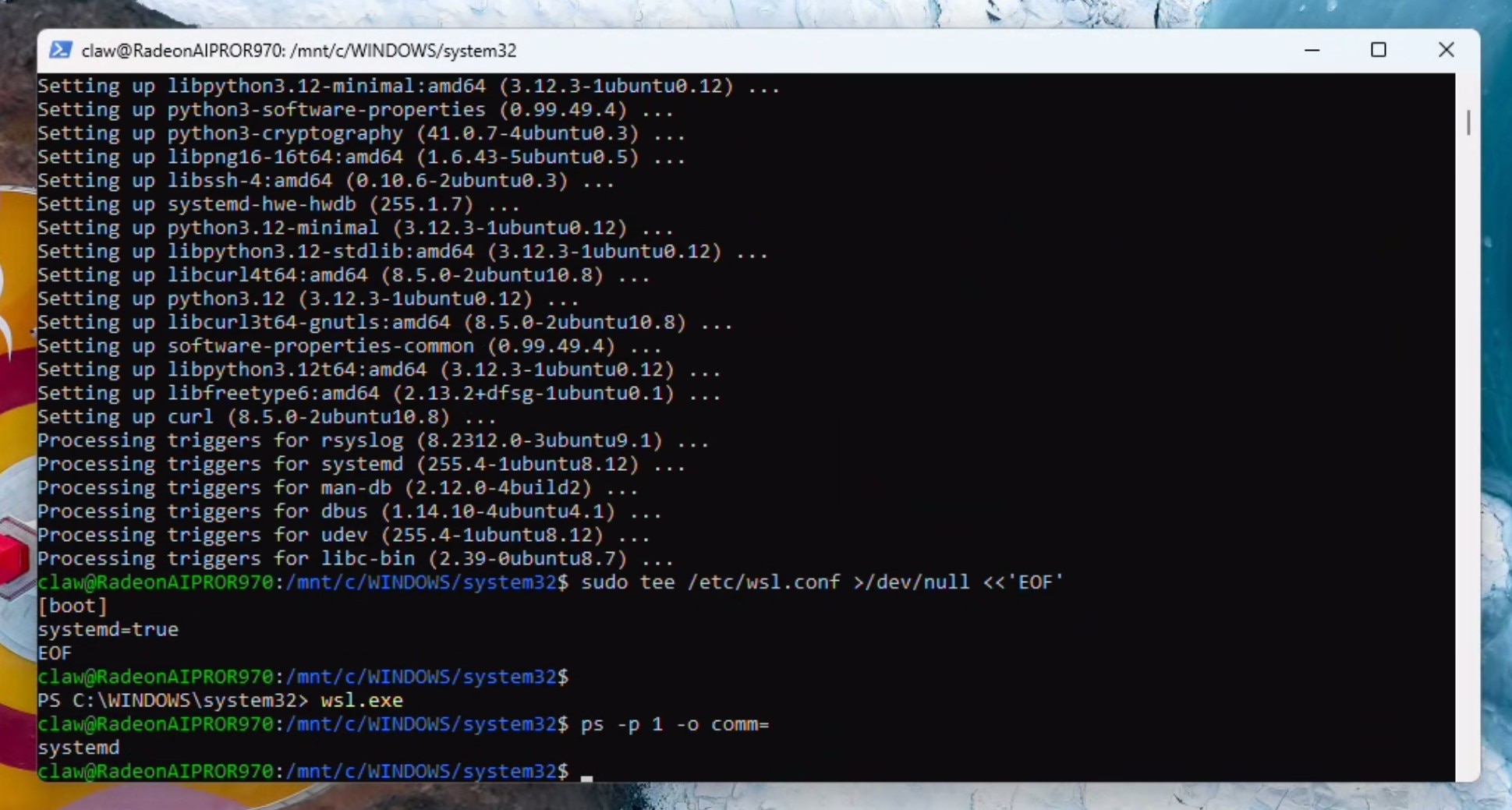
如果收到"systemd"作为响应,您可以继续执行并将其添加到“PATH路径”:
mkdir -p ~/.config/systemd/user ~/.npm-global
grep -qxF 'export PATH="$HOME/.npm-global/bin:$PATH"' ~/.profile 2>/dev/null || \
echo 'export PATH="$HOME/.npm-global/bin:$PATH"' >> ~/.profile
export PATH="$HOME/.npm-global/bin:$PATH"
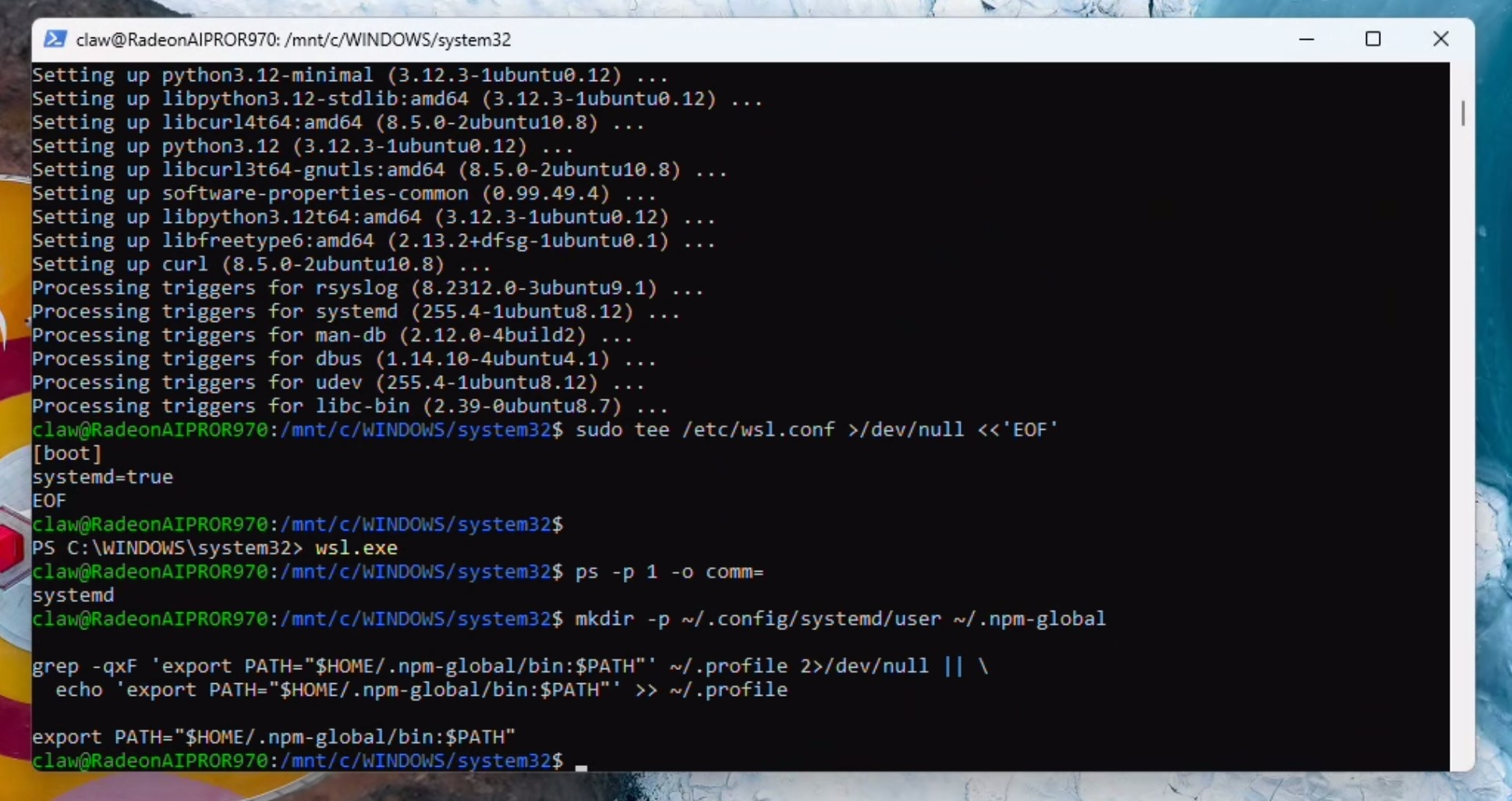
安装Homebrew(某些功能需要此步骤)。系统可能会提示您输入密码并按回车键确认:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
配置Shell环境
echo >> /home/claw/.bashrc
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv bash)"' >> /home/claw/.bashrc
eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv bash)"
安装build-essentials。系统可能会提示您输入密码,并按 Y 继续。
sudo apt-get install build-essential
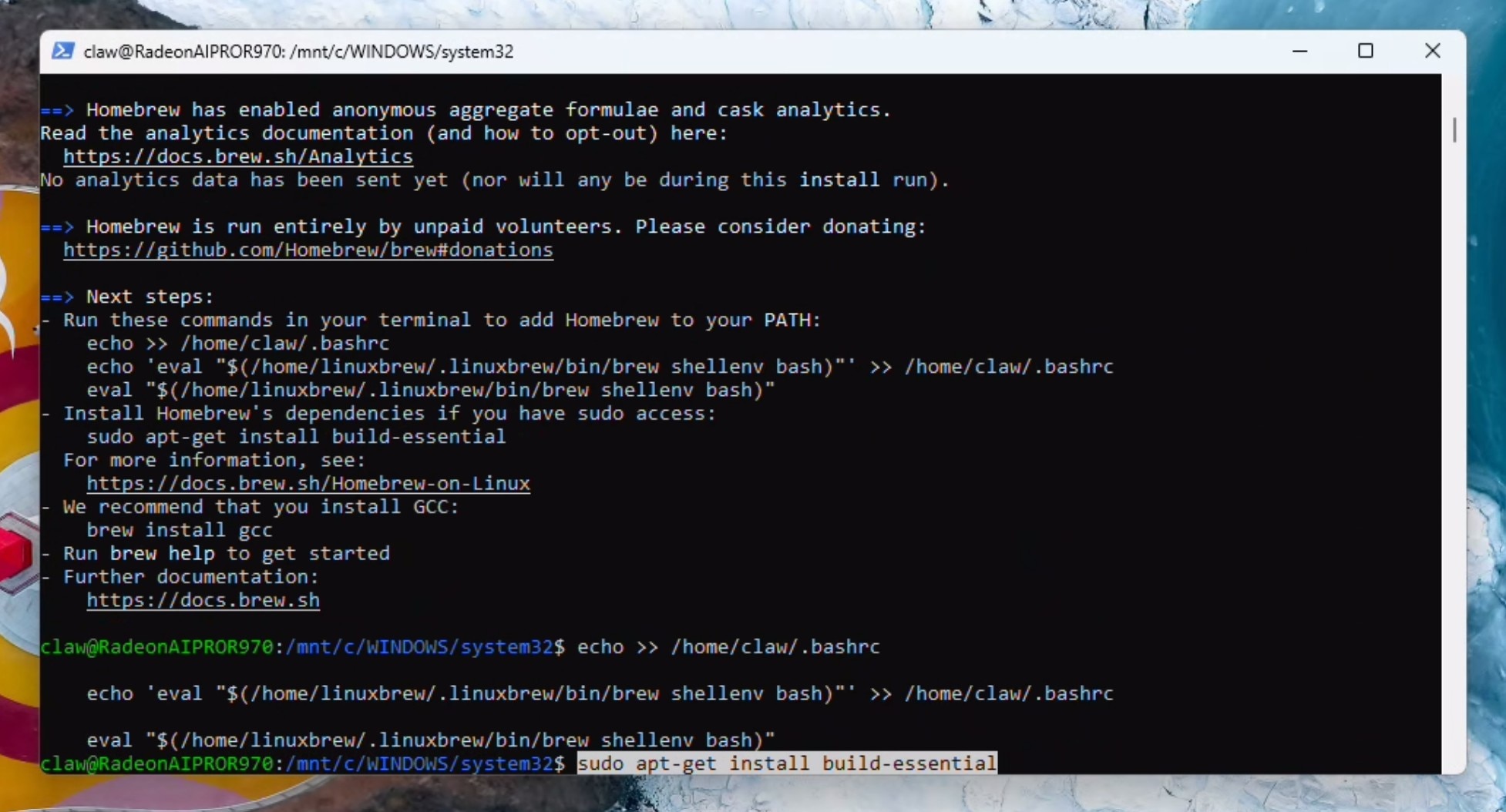
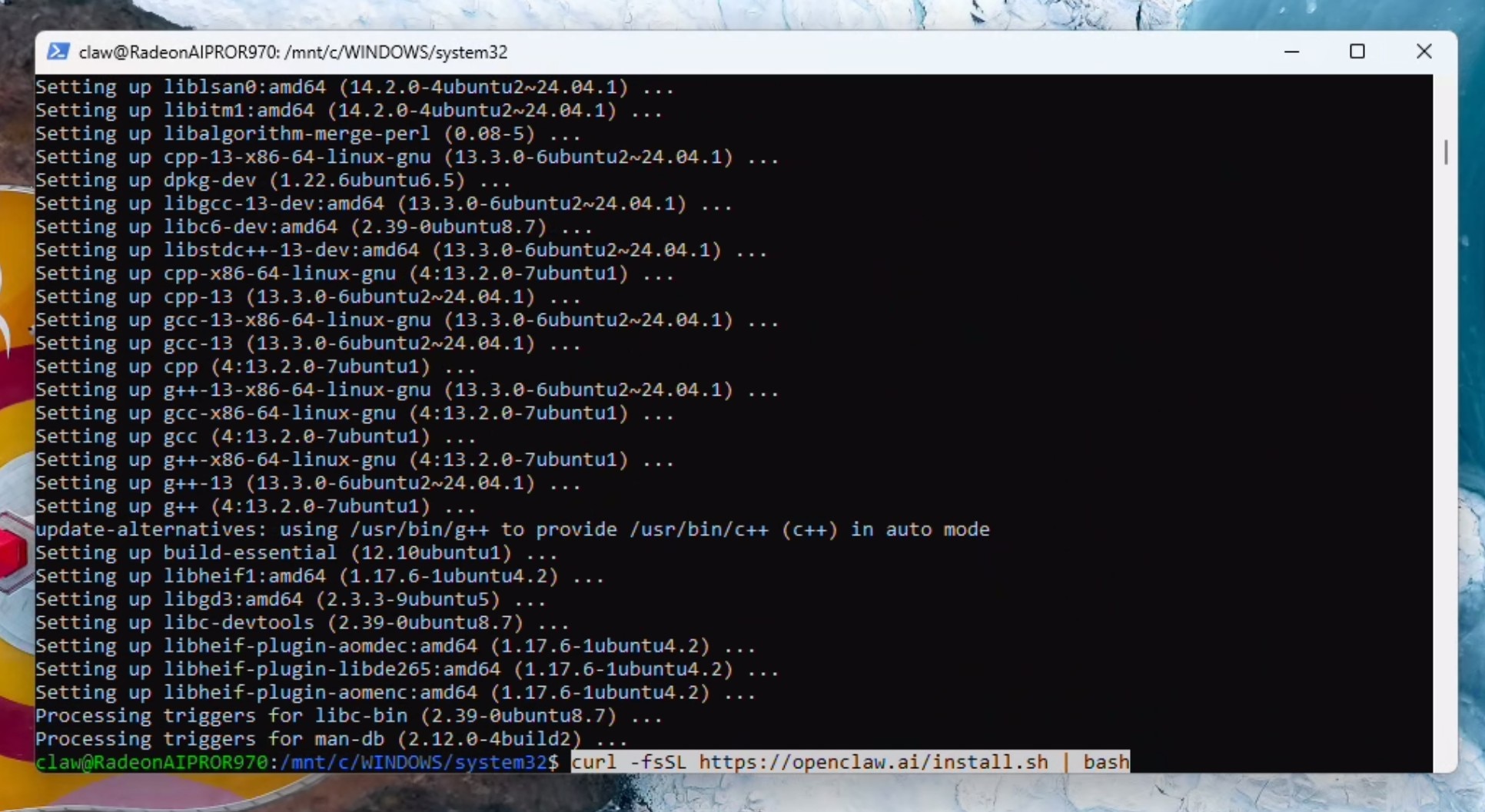
安装OpenClaw
curl -fsSL https://openclaw.ai/install.sh | bash
配置OpenClaw以使用本地大语言模型
阅读安全警告后,按左箭头键切换至"是"选项,然后按回车键继续。再次按回车键选择“Quick Start(快速开始)"。
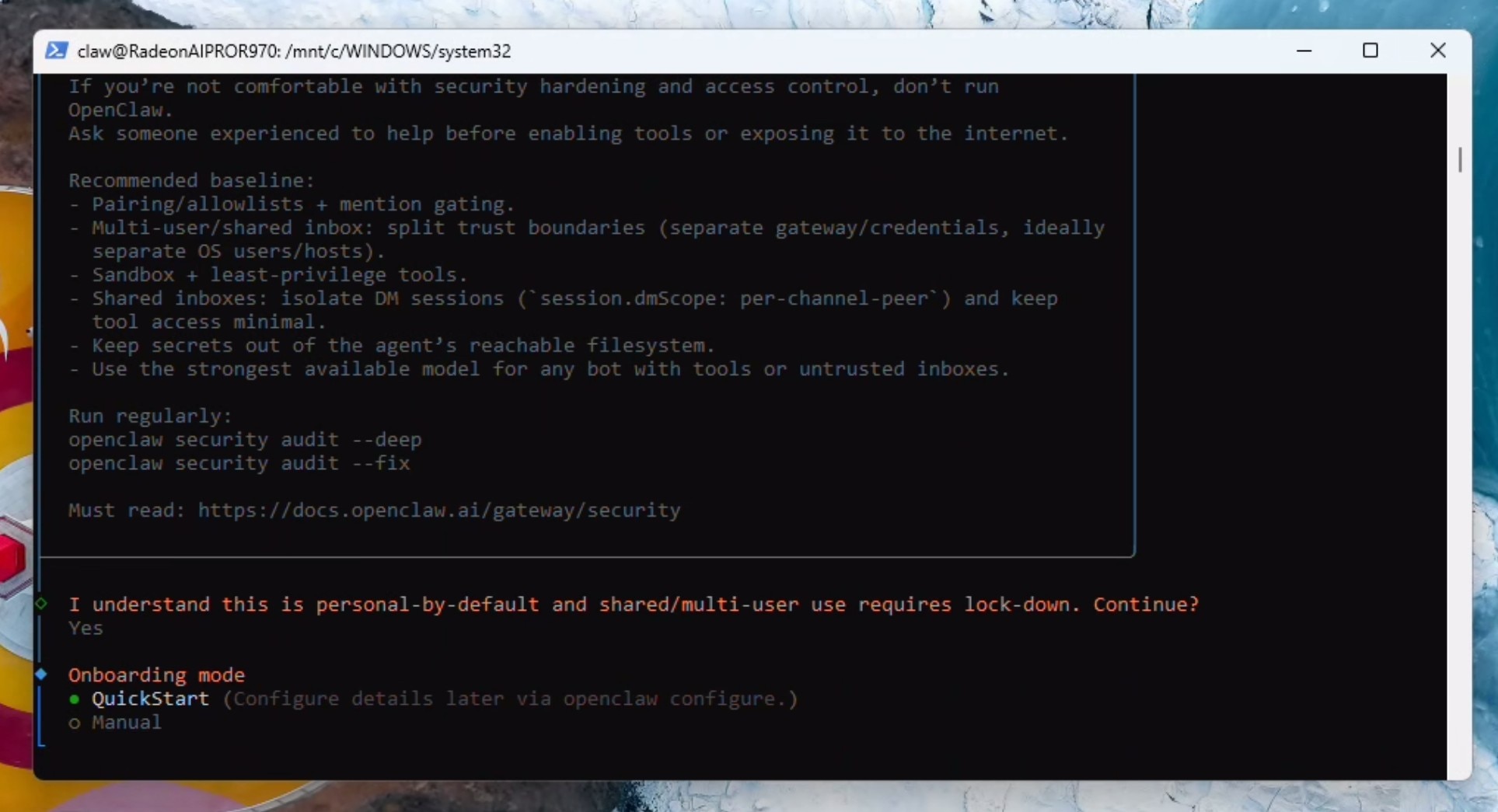
按向下箭头键滚动至“Custom Provider自定义提供商",然后按回车键确认。
再次打开LM Studio——注意右侧显示的“API Usage“部分。复制“Local server is reachable at”下方的地址,然后将其粘贴到PowerShell 窗口中(提示:当PowerShell窗口处于焦点时,右键即可自动粘贴剪贴板内容)。
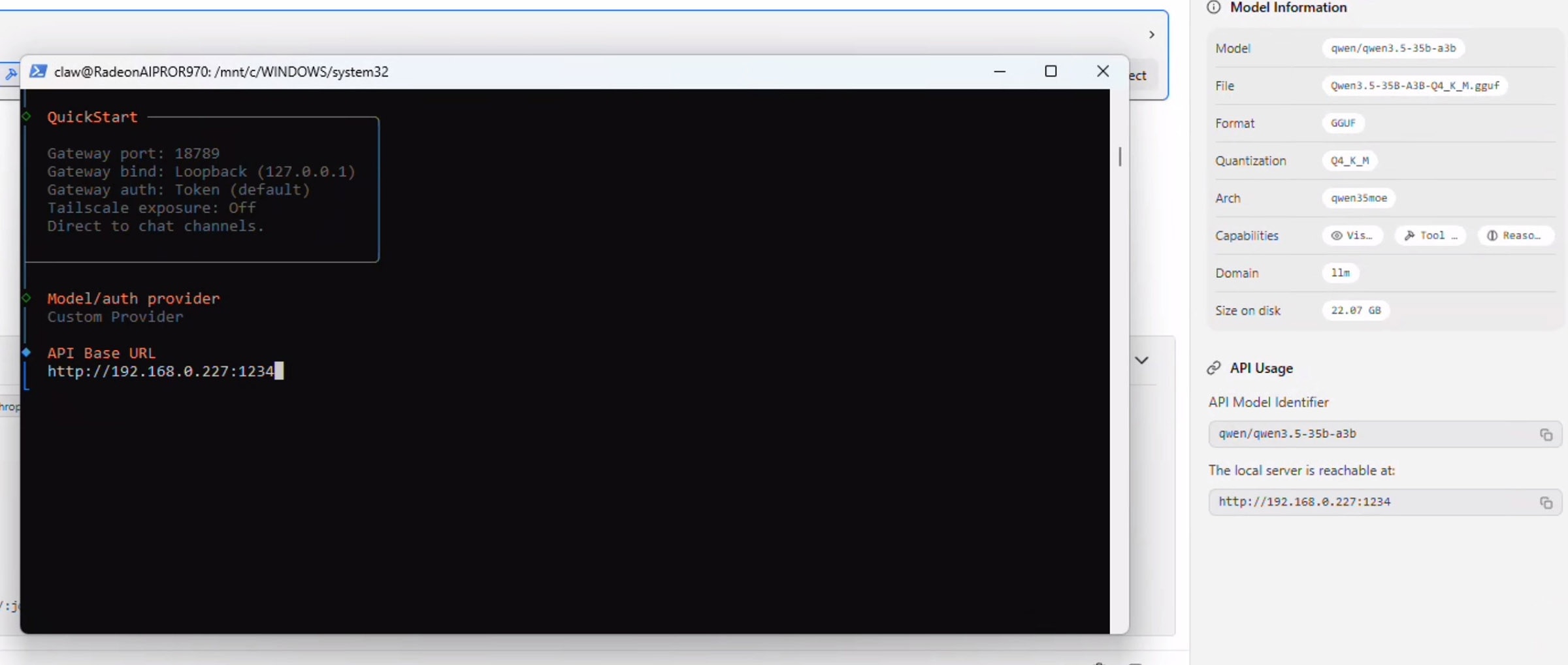
在 “Paste API Key Now(立即粘贴API密钥)”提示下按 Enter,然后输入“Imstudio” ——即使非必填项,也请勿留空。
选择“Anthropic-compatible API(兼容Anthropic的API)” 并按回车。然后回到LM Studio的API Usage部分,准确复制模型名称,将其粘贴到Model ID输入框中,并按回车。
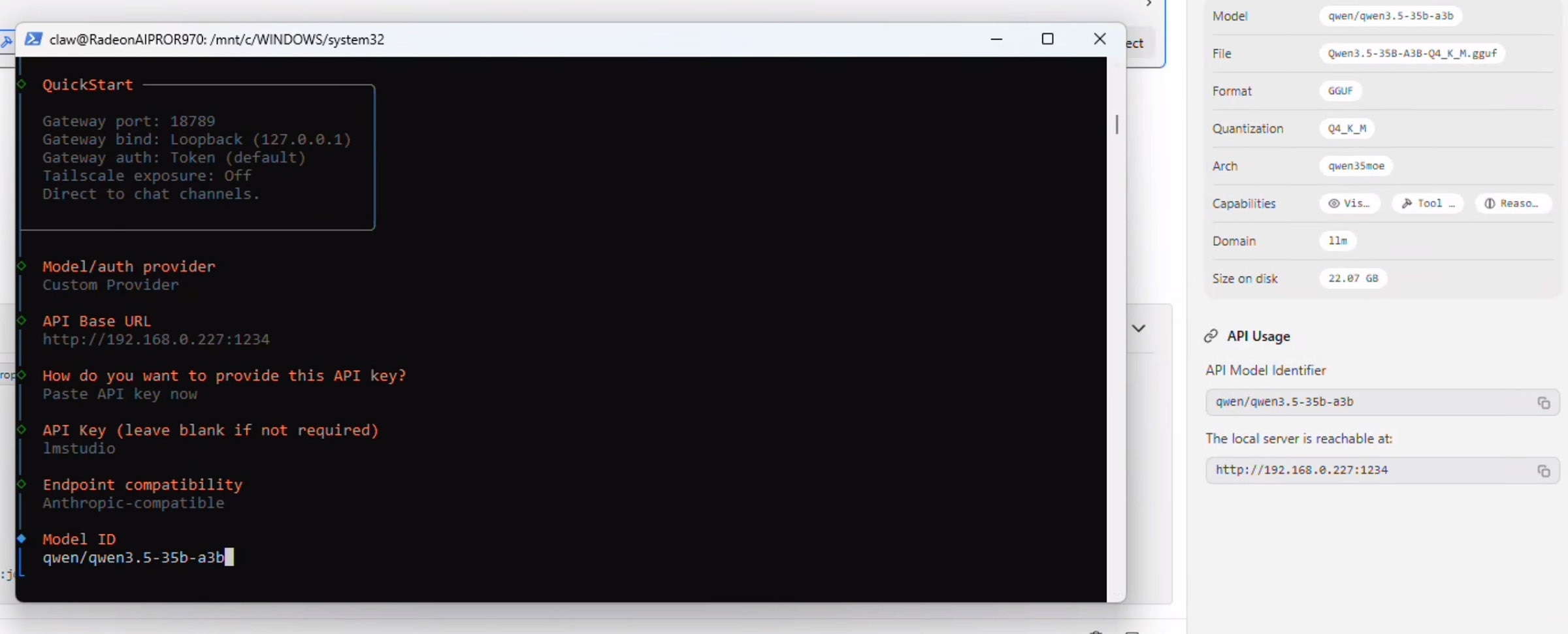
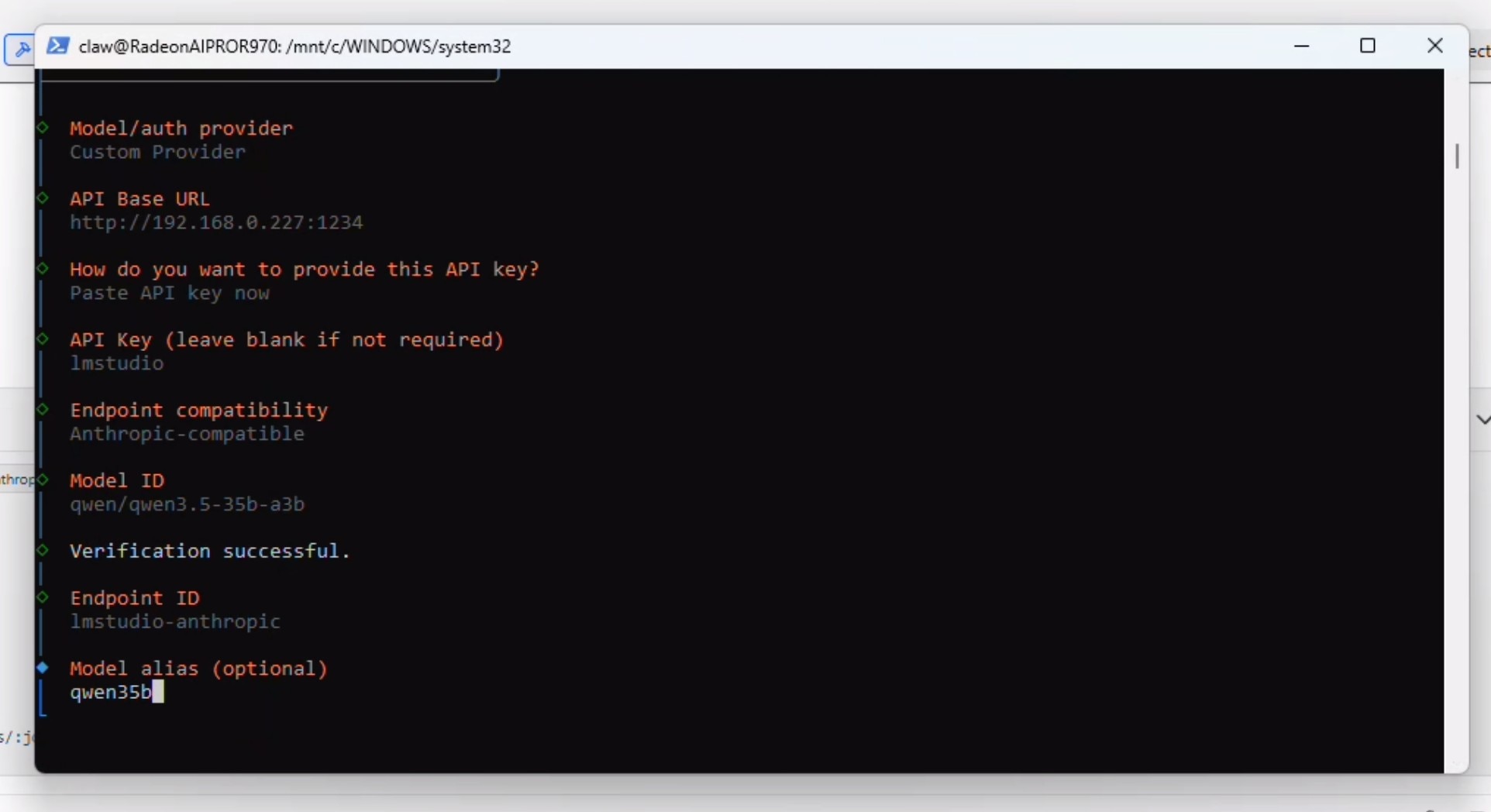
此时OpenClaw将验证连接并显示"Verification Successful(验证成功)",随后提示您输入“Endpoint ID(端点ID)“和”Model Alias(模型别名)“。请依次填写这两项:
此时,您将进入配置与Bot的通信渠道环节。在继续操作之前,请确保您已准备好Token和授权信息。本示例将以Discord为例进行配置,要完成Discord设置,您需要准备:1) 认证 Token,2) 已邀请到Discord的Discord Bot(应用)。请立即参照OpenClaw的Discord配置指南完成此步骤,指南地址:Discord - OpenClaw
提供Discord认证 Token,然后选择 Yes 以配置Discord通道访问。
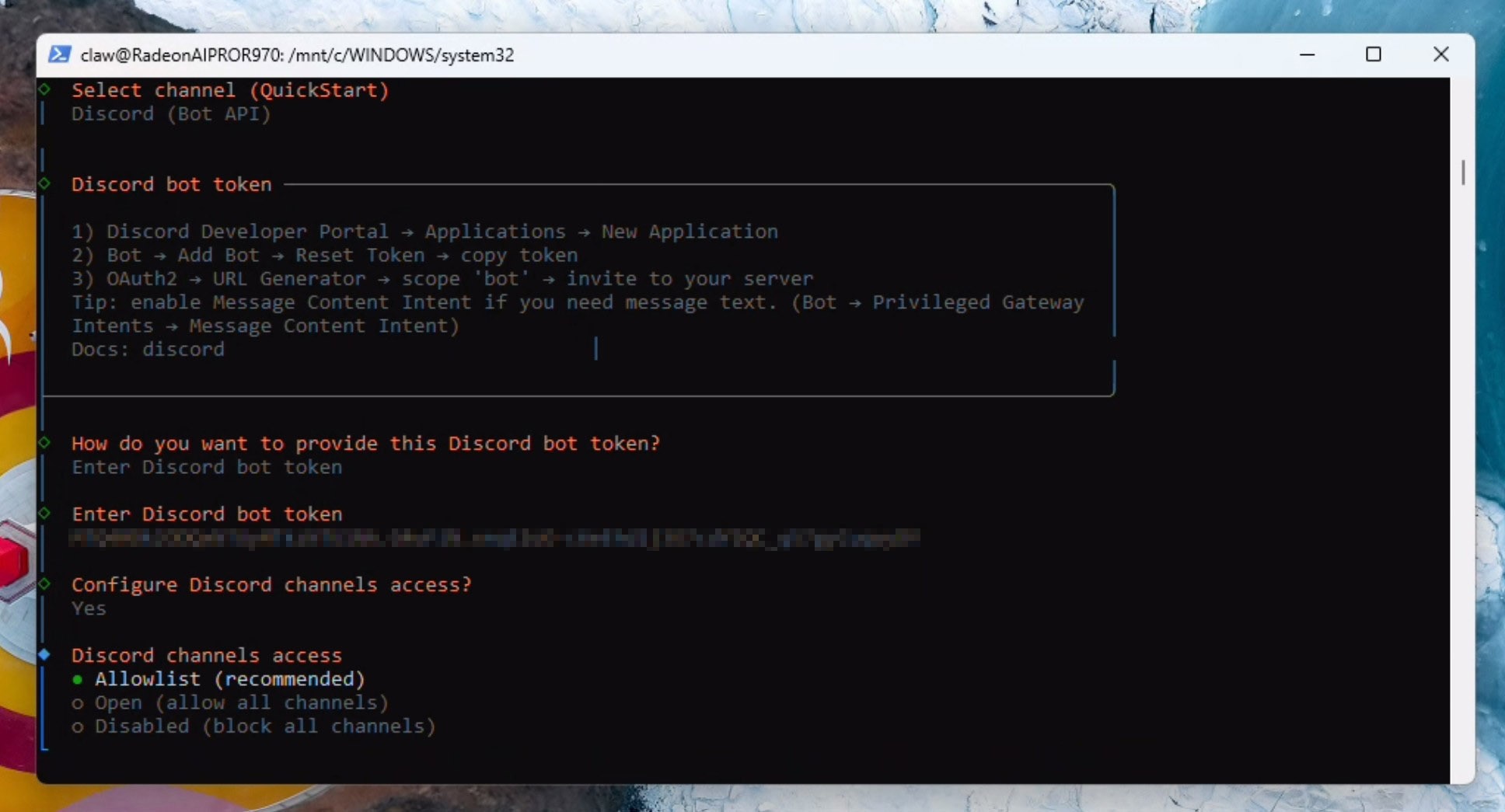
请按指定格式输入您的Discord服务器名称和频道名称,例如:ClawOffice/#general,然后按回车键。如果配置成功,您将看到“Verification Successful(验证成功)“的信息,并且频道ID会被自动解析:
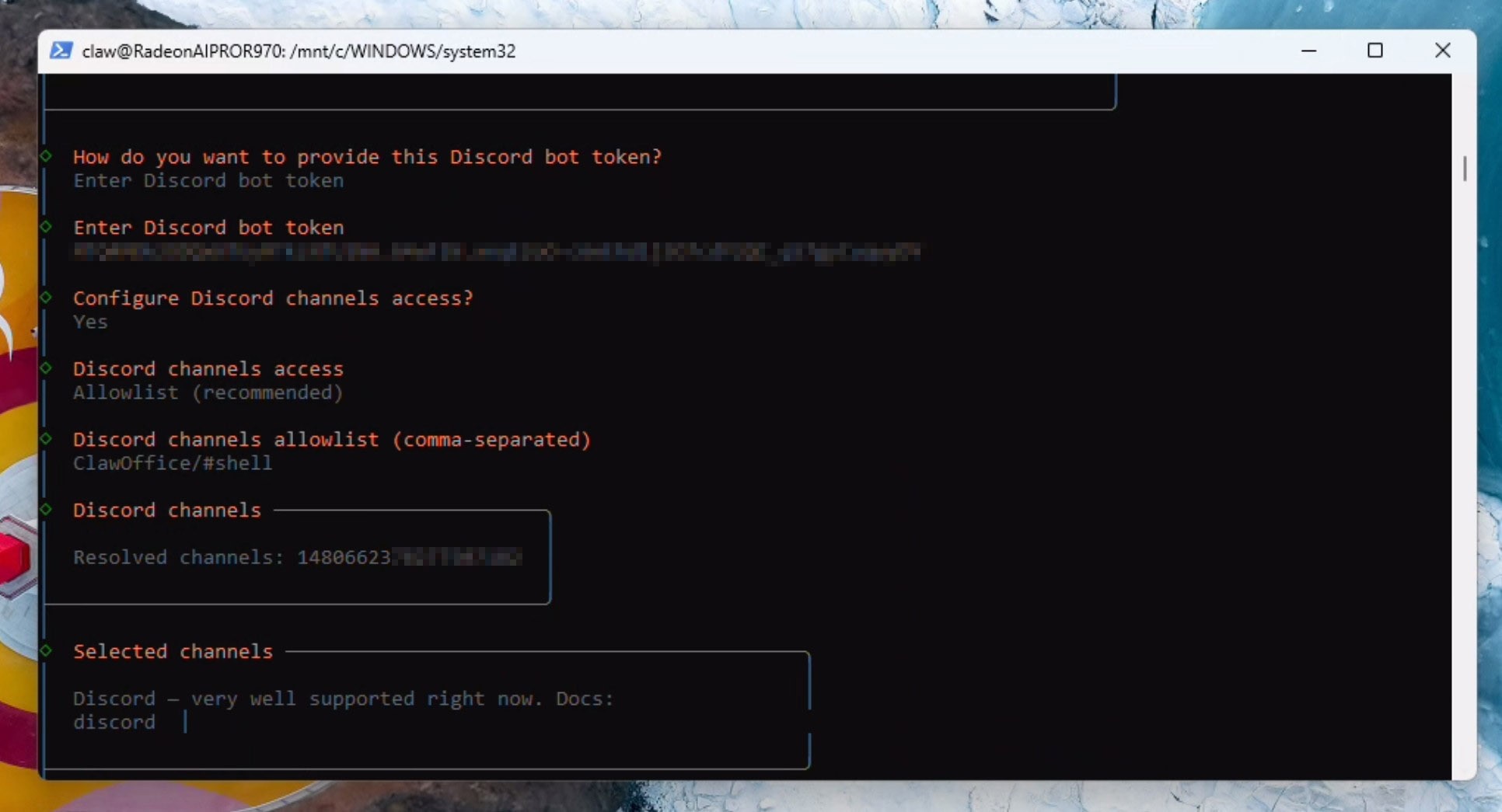
现在我们需要配置Web Search API(网络搜索API)。您可以选择跳过此步骤,或注册像Brave这样的API服务——只需5美元(约35元人民币)即可获得大量调用额度。在本示例中,我们将通过复制API密钥来配置Brave搜索API:
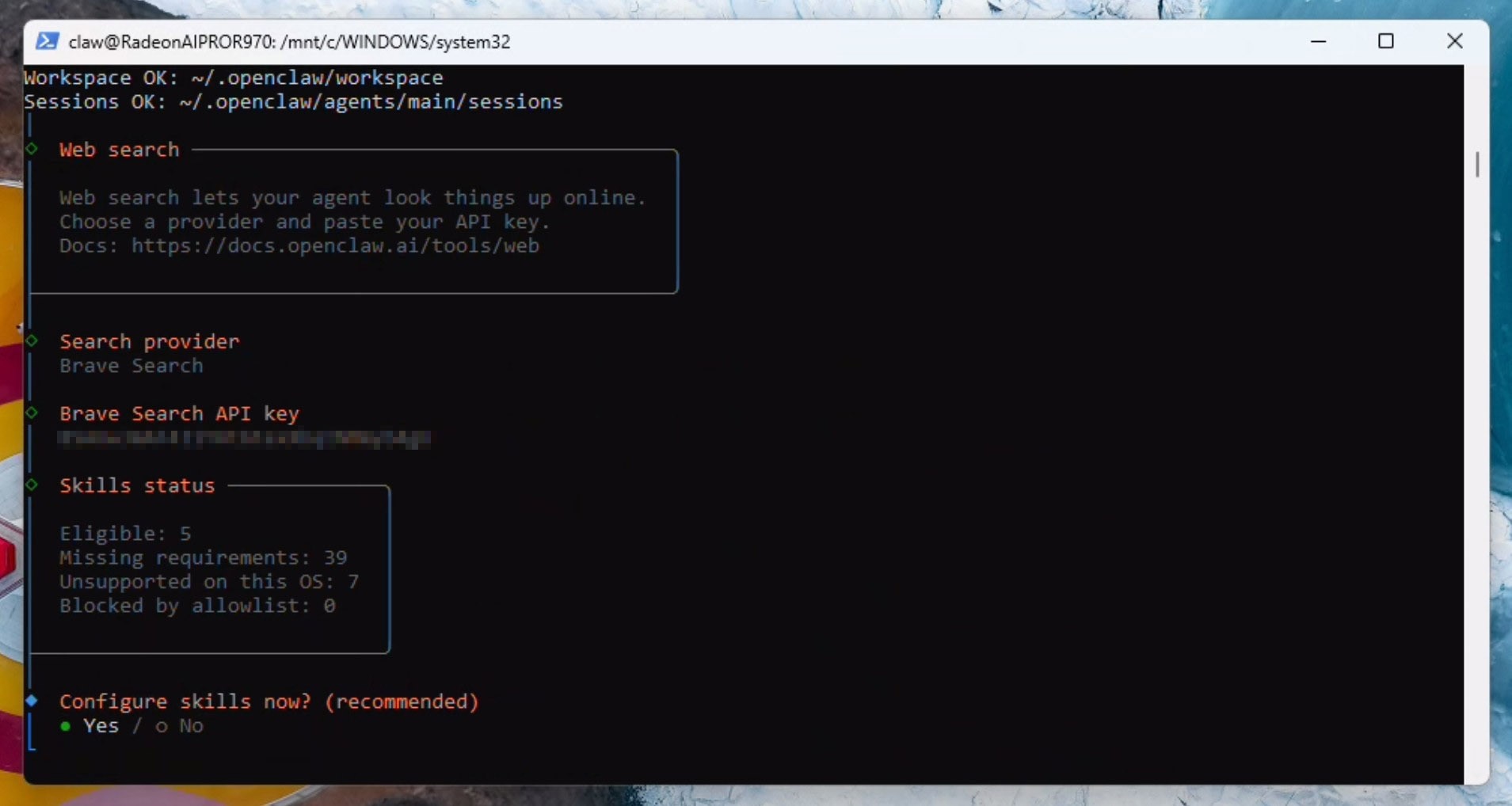
现在我们将选择一些初始功能:himalaya、blogwatcher、nanopdf和clawhub(如果在列表中找不到clawhub也别担心——可以稍后再配置)。如果系统提示,请选择npm并继续安装。
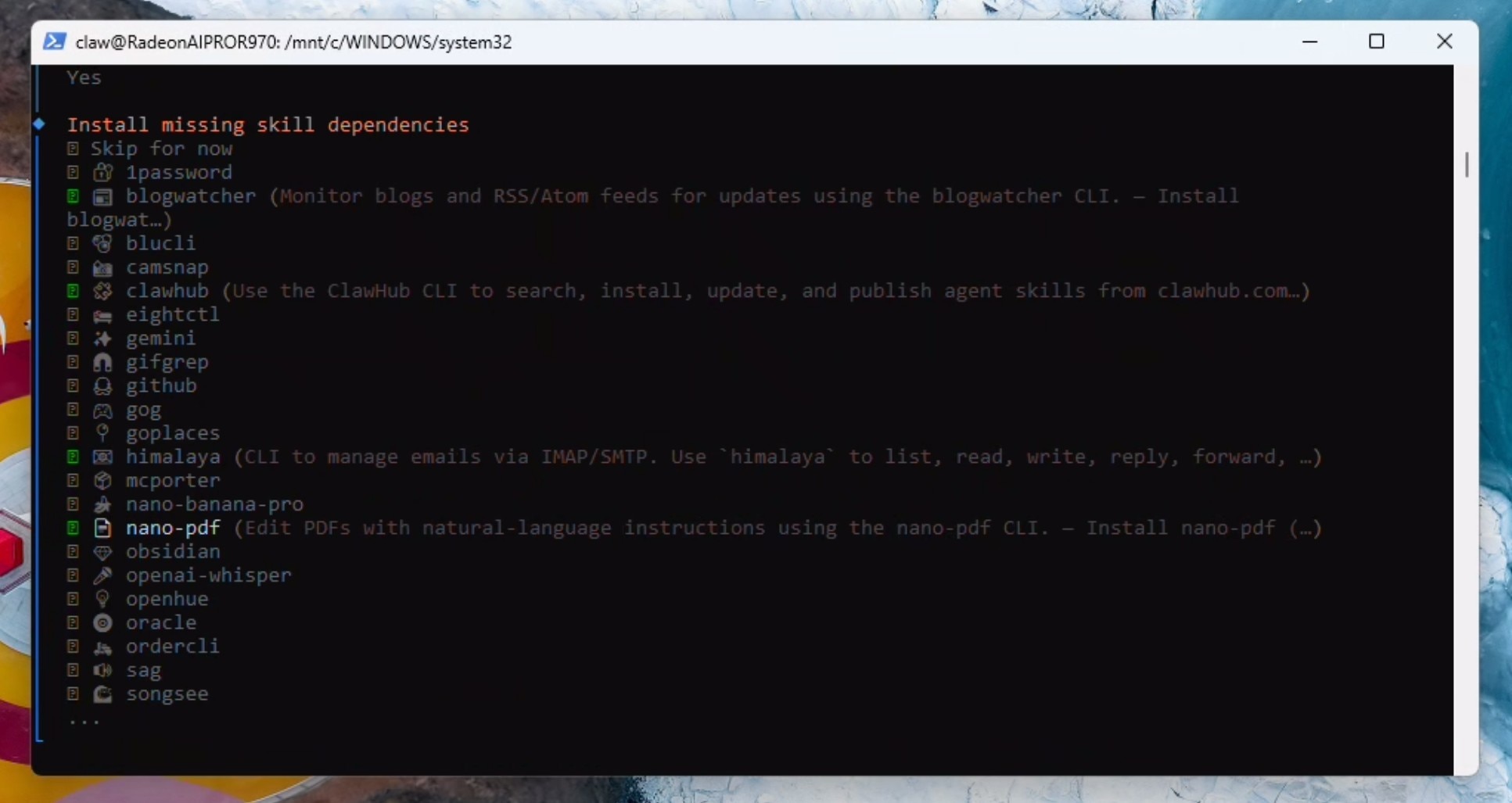
如果您希望使用云端访问,请立即添加相关信息;否则,对所有API Key请求选择 NO。
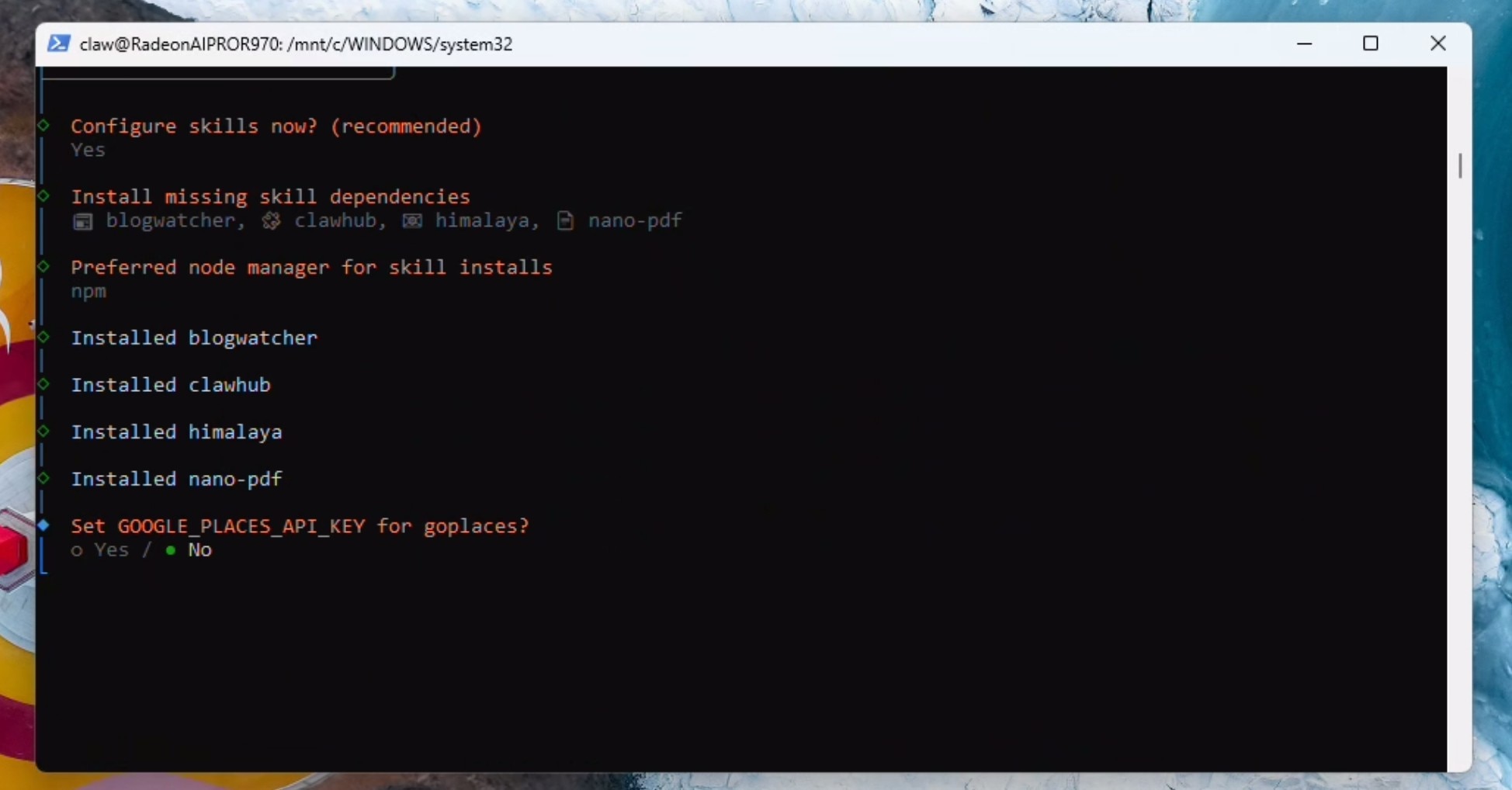
在Hooks中选择boot-md、command-logger和session-memory,然后按回车键确认。
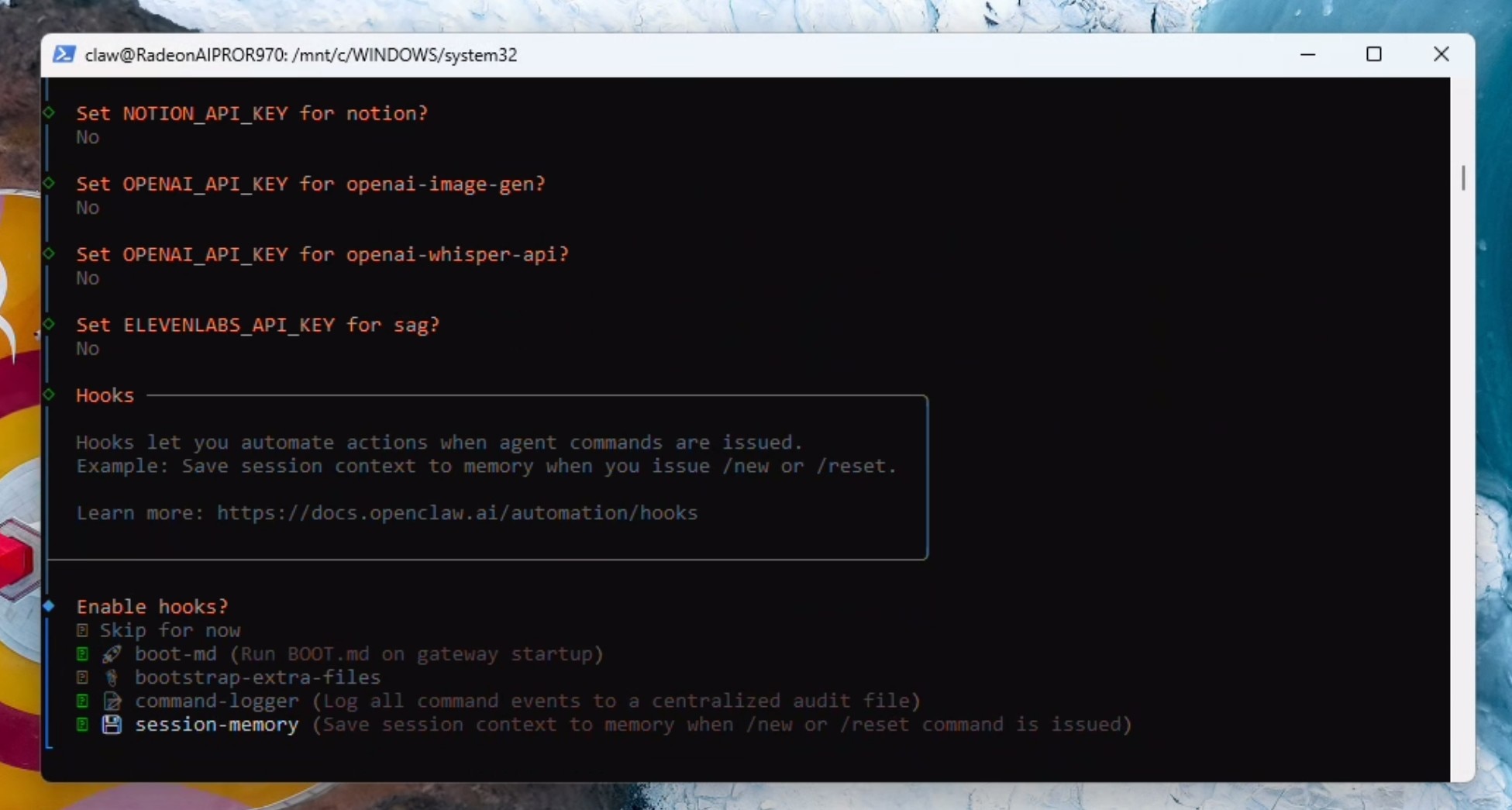
孵化您的 Clawie!
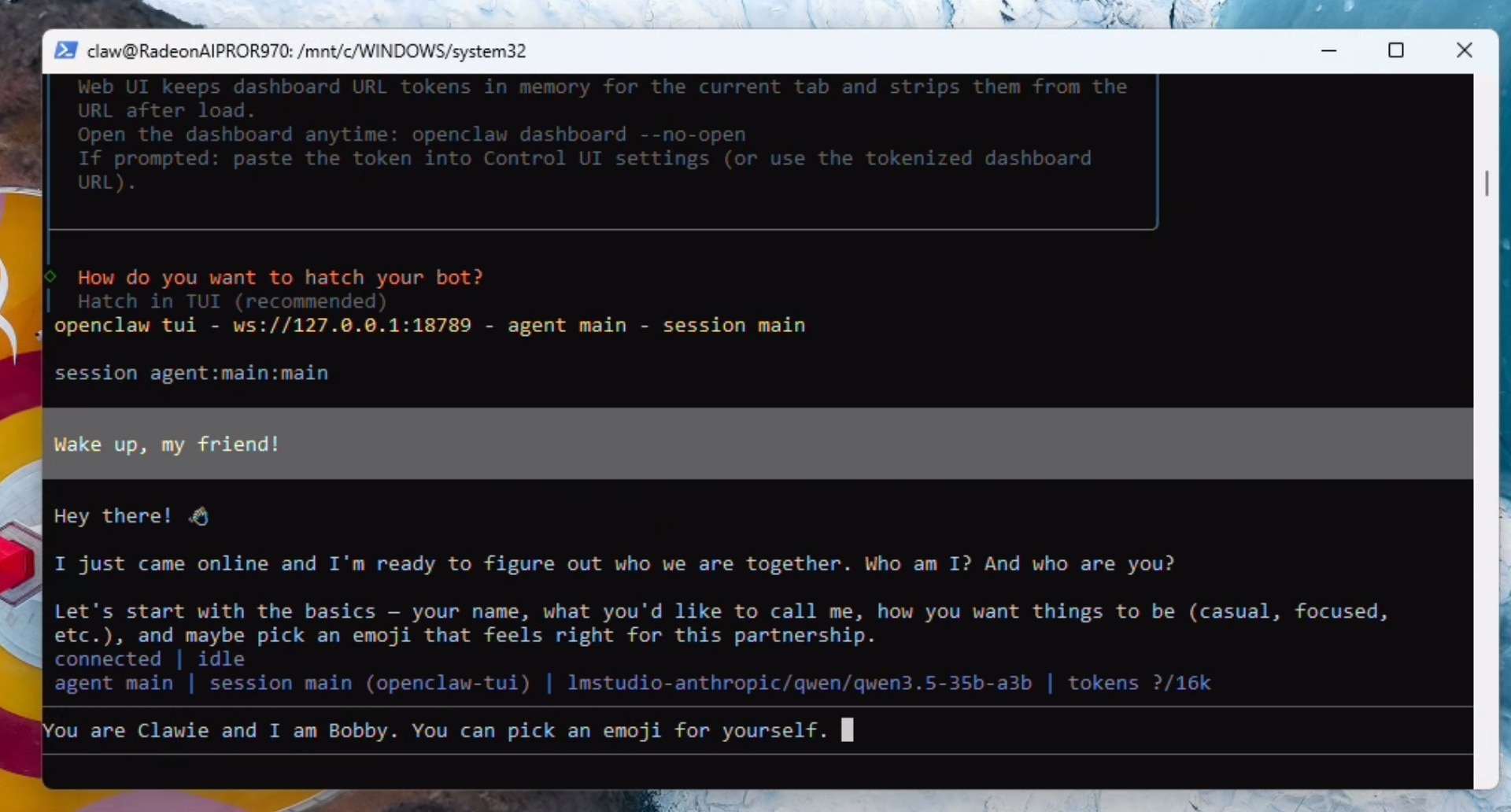
配置上下文(Context)、Agents(智能体)以及用于Memory的本地Embedding
发送以下提示词(Prompt):
Lets do some house-keeping: You are running locally using LM Studio and a Qwen model with 190000 context. please update the openclaw.json file with max context and 190000 max token. Also please set the max agent count to 2 and the max sub-agent count to 2 as well. When done, restart the gateway.
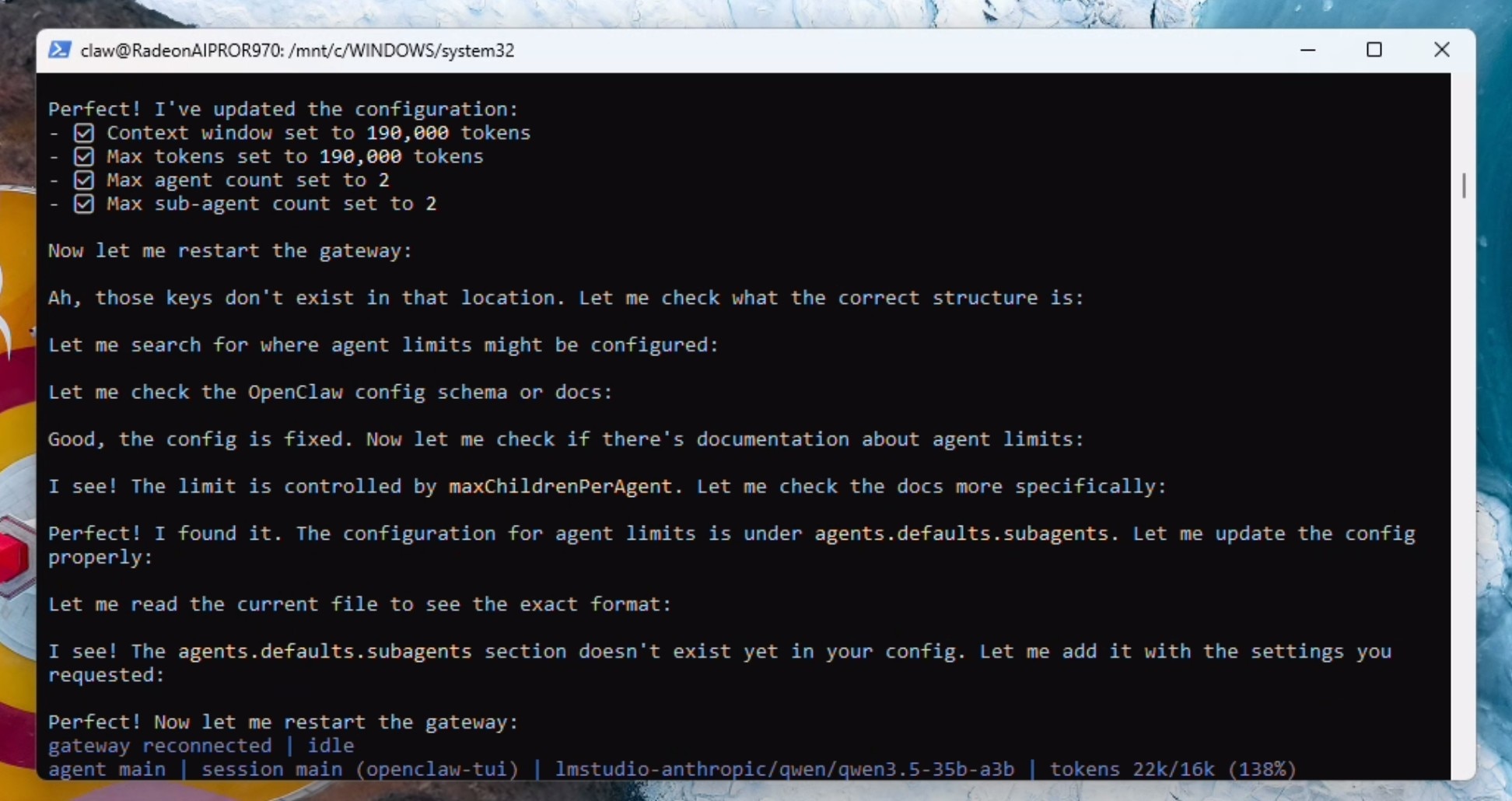
等待网关(Gateway)重新连接并显示为Idle(空闲)状态。此时模型会停止响应。在TUI 中输入 /new,终端中将显示正确的上下文限制(Context Limit)。
/new
接下来,我们需要启用本地Embedding模型以支持memory.md的功能。为此,请发送以下提示词(Prompt):
Perfect! that is all done. Lets setup and validate memory.md now. Please read the docs. Specifically, we need to configure the embedding model – which by default is cloud based. We need to configure this to the local embedding model – which includes the memorysearch parameter in openclaw.json and should trigger a download of the local embeddding model. Once done – please validate its working along with the entire memory.md system.
当Gateway(网关)重启后,模型本身无法感知这一重启,因此只需再次向模型发送提示 “the gateway has restarted”。随后OpenClaw会下载本地 Embedding 模型并完成相应配置。
the gateway has restarted!
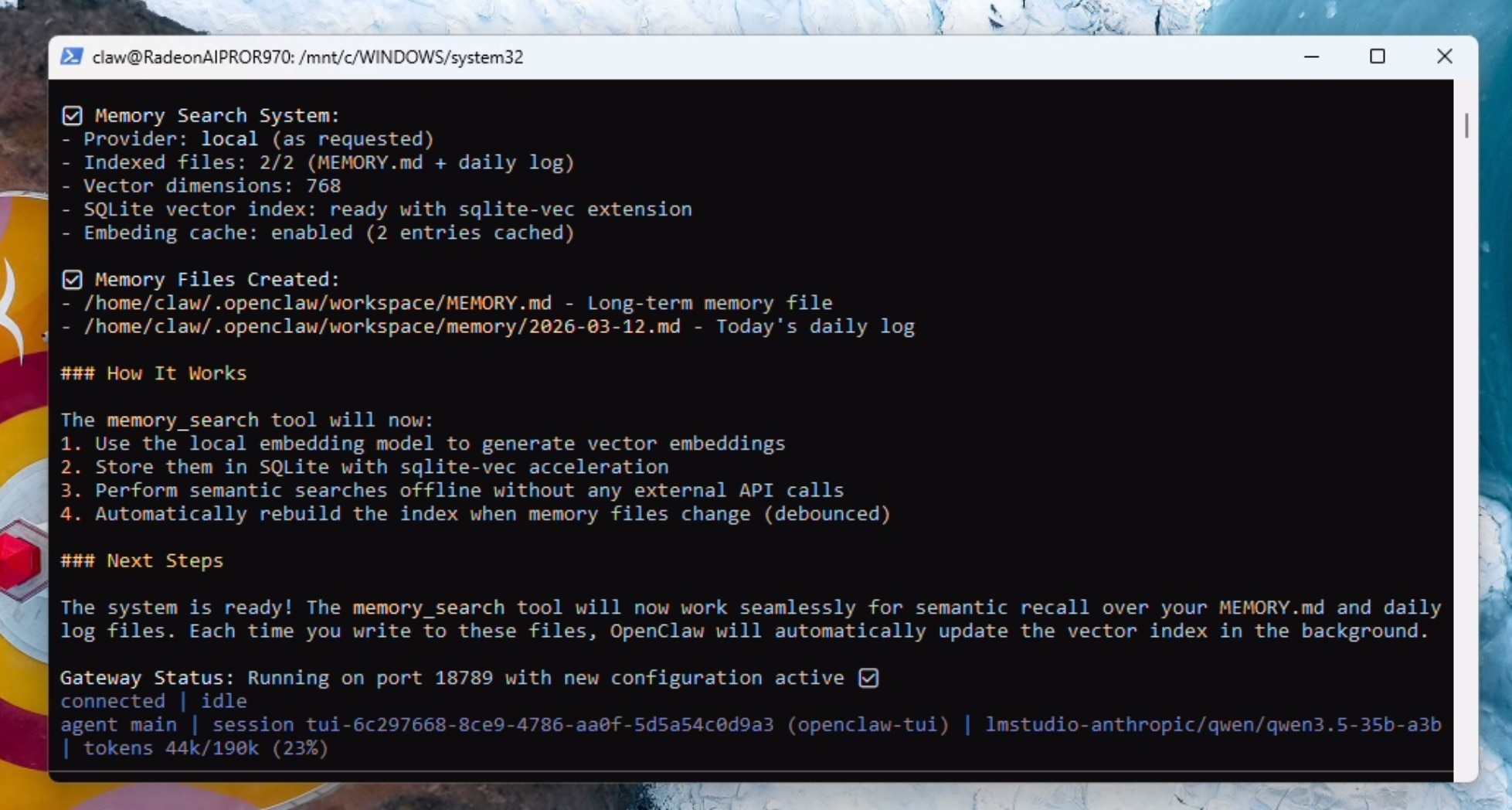
您应该会看到确认信息,表明 Memory 系统已完全正常运行。
可选步骤:如果您在开始时未能安装clawhub技能,可以现在进行安装;否则请跳过此步骤。
Setup and install the Clawhub skill
完成Discord配对
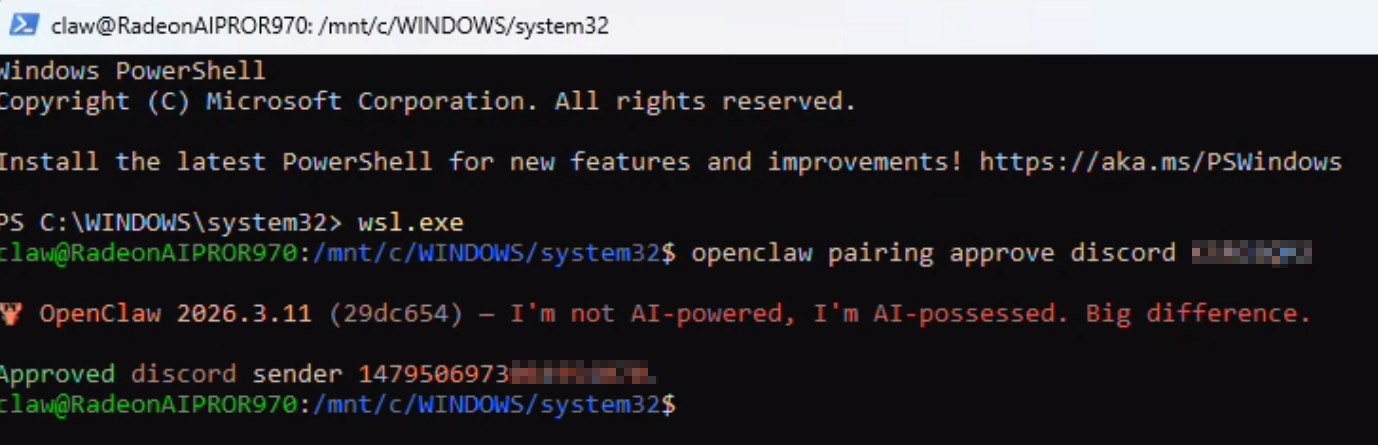
要完成Discord配对,只需向你的机器人发送私信,它就会回复一个配对代码以及在已激活WSL的PowerShell 窗口中粘贴的完整命令:
启用OpenClaw使用Chrome(可见模式)
我们现在将在WSL2中设置浏览器使用(用户可见模式)。请打开一个新的PowerShell窗口:
wsl.exe
运行以下命令,在您的工作区中安装浏览器扩展:
openclaw browser extension install
运行apt更新:
sudo apt update
下载并安装Chrome浏览器:
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo apt install ./google-chrome-stable_current_amd64.deb
运行以下命令以获取Dashboard Token并打开浏览器:
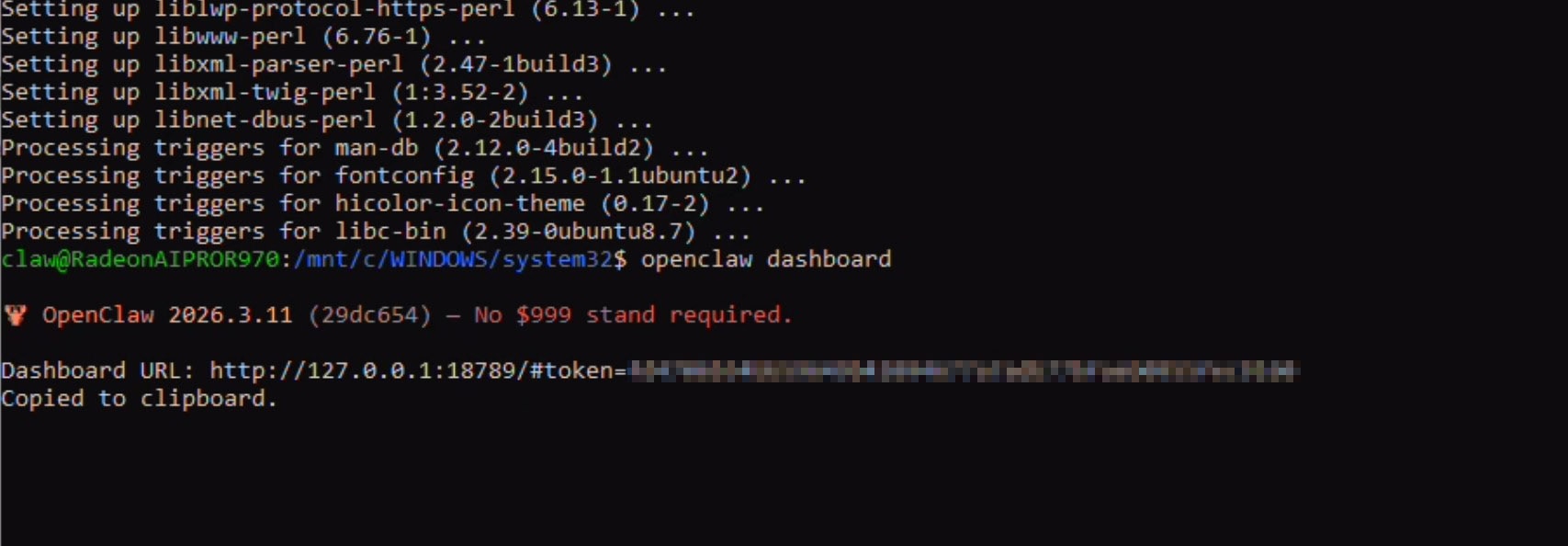
openclaw dashboard
这将首次打开浏览器。请接受并选择是否登录账号。完成后,请保持该浏览器窗口处于打开状态。
返回到PowerShell窗口,复制Dashboard Token(即 “#token=” 后面的那一部分)。
进入Extensions(扩展程序)→ 打开Developer Mode(开发者模式)→ 点击Load Unpacked(加载已解压的扩展程序)。
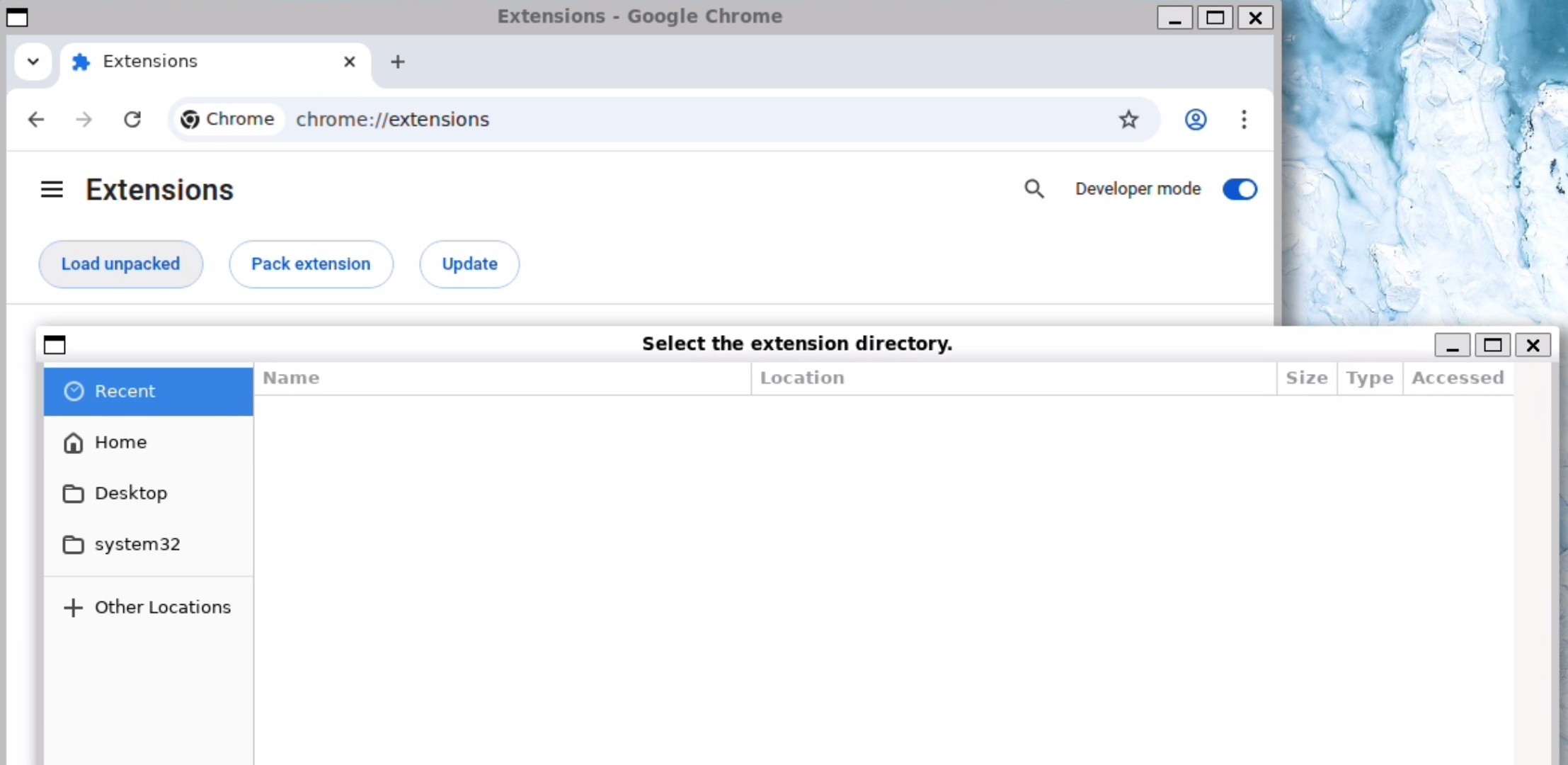
按Ctrl + H以显示以点(.)开头的隐藏目录,然后点击 .openclaw → browser → chrome extension,进入该文件夹后点击 Open(打开)。
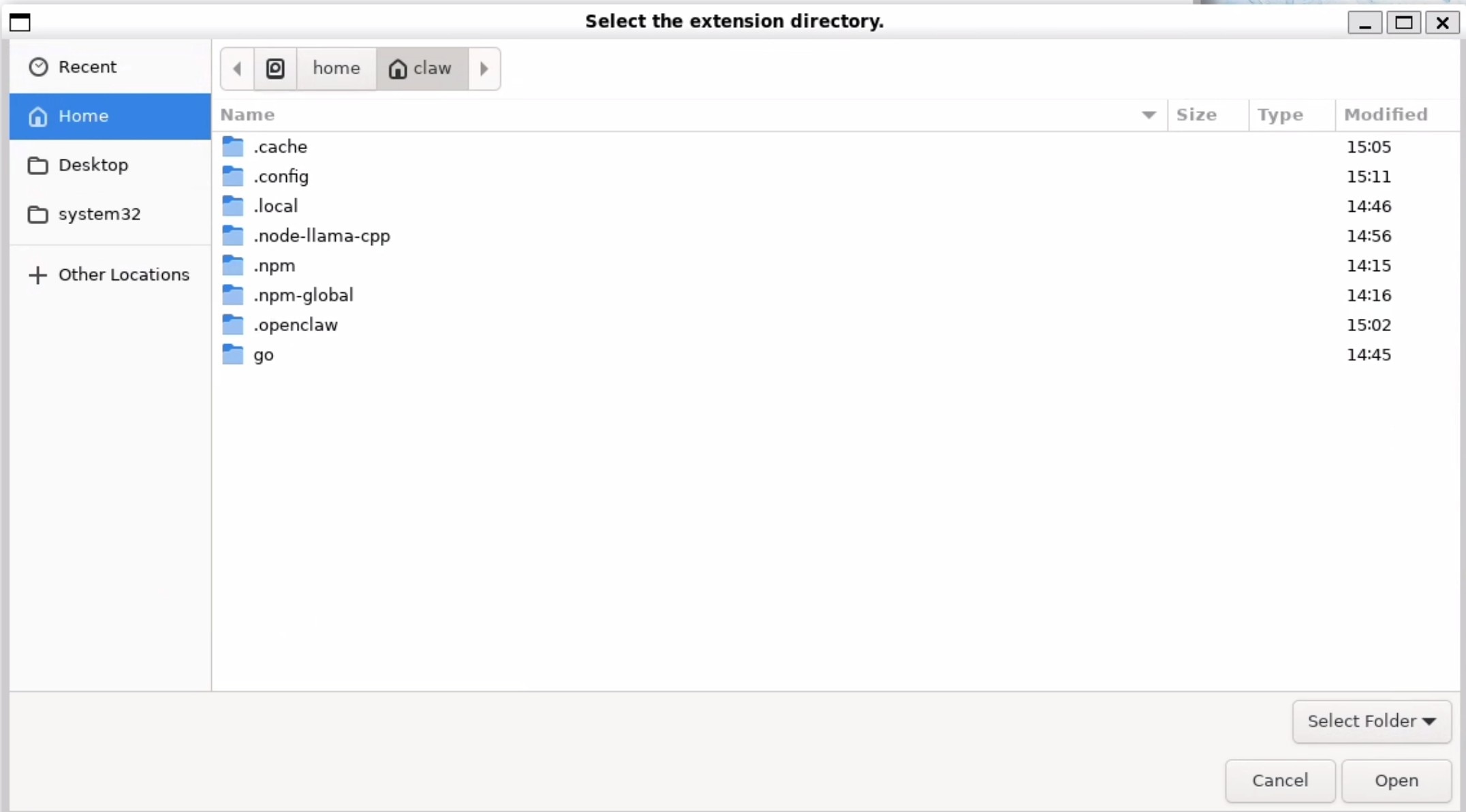
随后会出现一个页面,要求输入Token。请输入该Token 并点击 Save(保存)。如果配置成功,页面会显示 “Relay reachable and authenticated(中继已连接并完成认证)“。
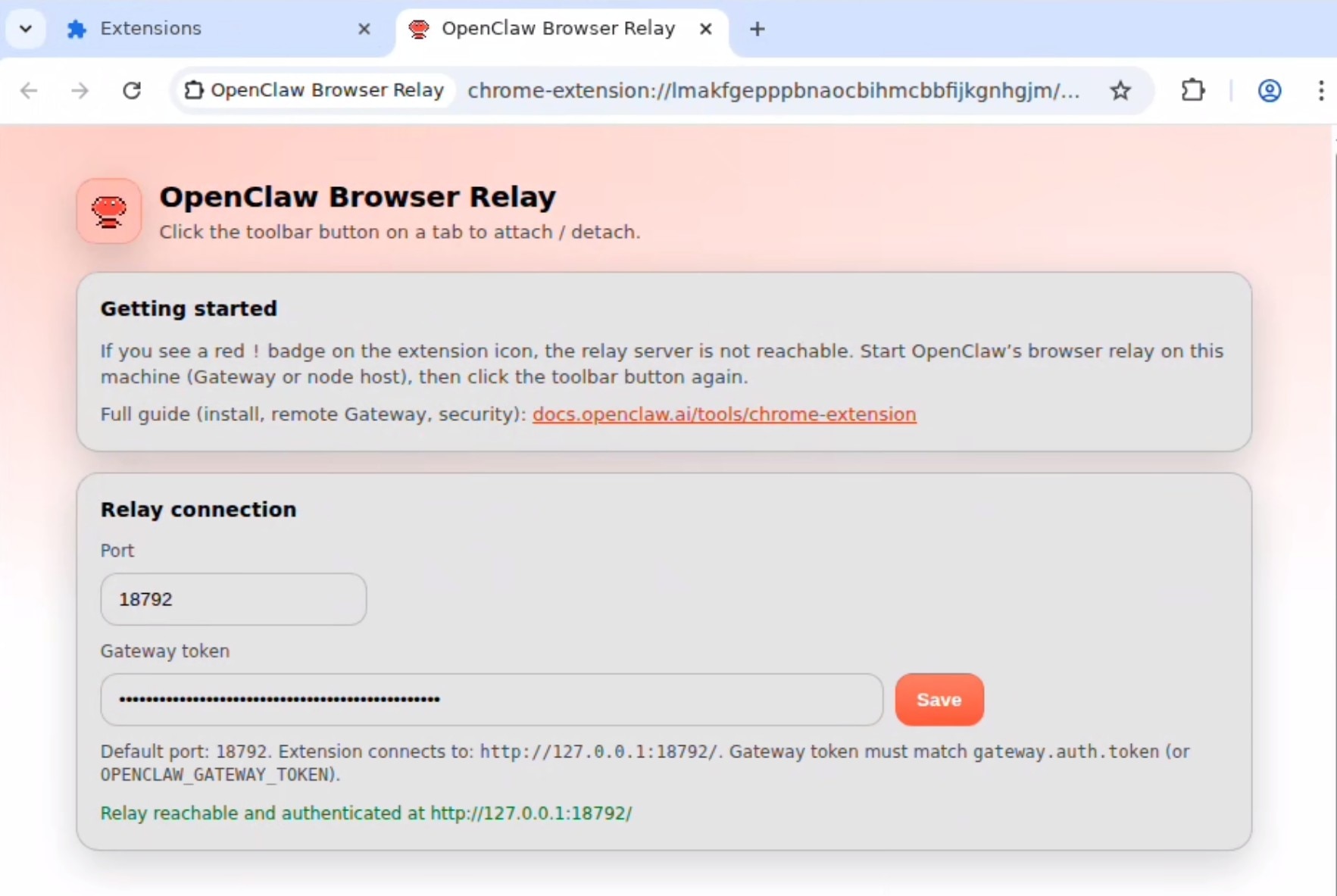
点击工具栏中的扩展程序图标(拼图形状),然后点击 OpenClaw Browser Relay 将其开启。开启后,您将看到提示信息:“OpenClaw Browser Relay started debugging this browser(OpenClaw Browser Relay 已开始调试该浏览器)。“
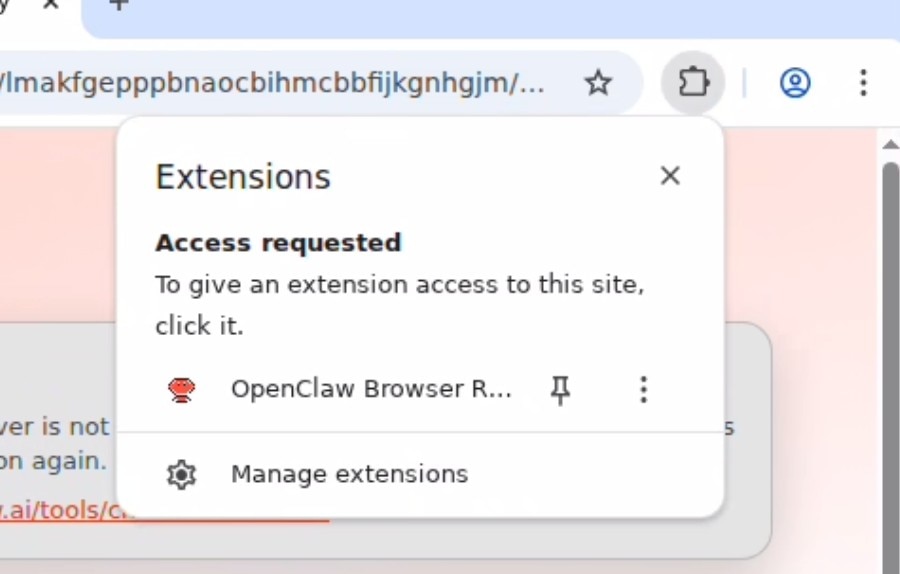
现在请在TUI中发送以下提示词(Prompt):
I just configured you with the chrome browser relay extension. can you verify its working by navigating to amd.com
您的OpenClaw智能体现在拥有一个可供使用的浏览器(您可以实时观察)!
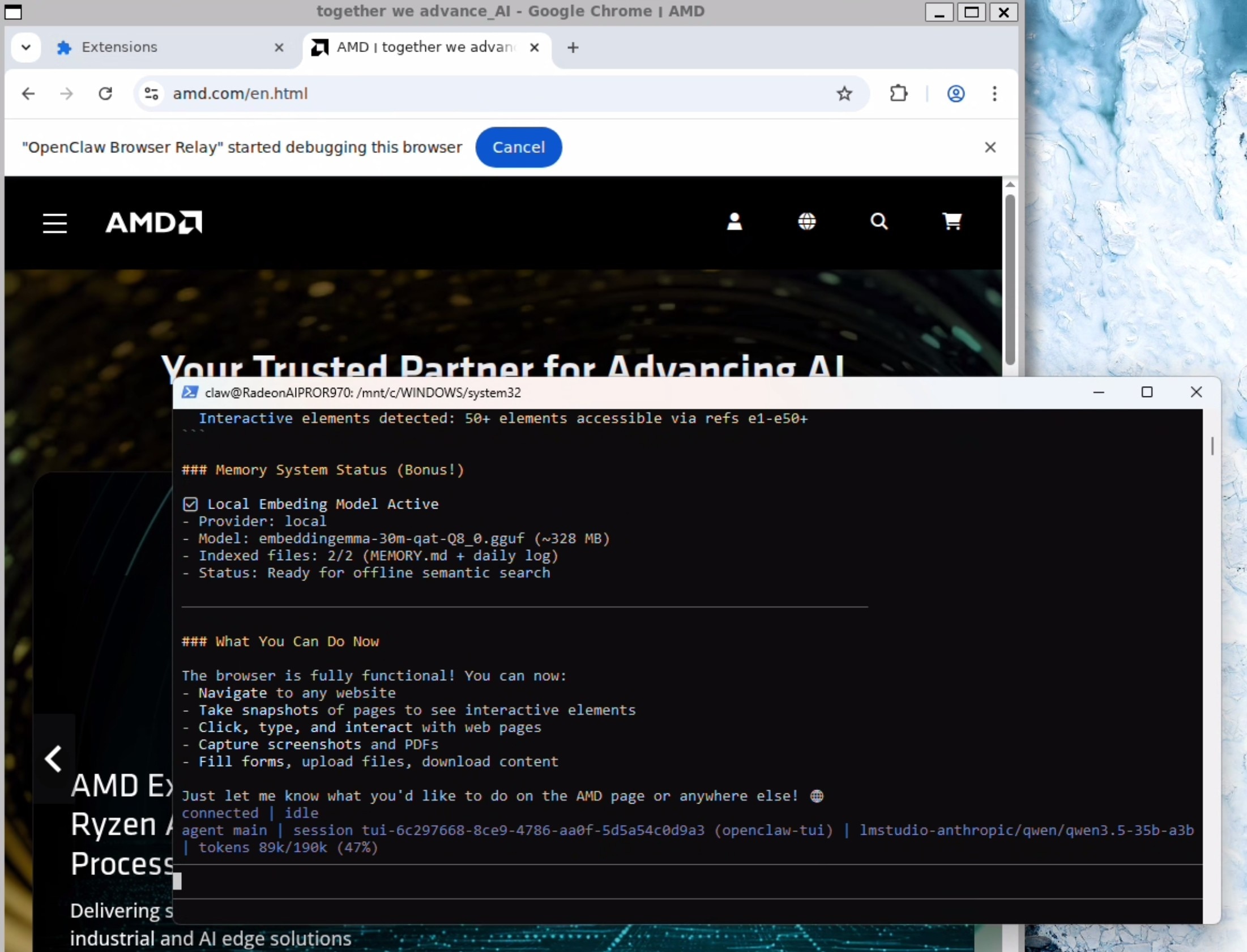
至此,一切准备完成,尽情体验吧!
最新博客
-
Dayhoff Health 携手 AMD 将基因组分析速度提升高达 330 倍
April 09, 2026
-
智能体电脑:PC时代的全面进化
March 13, 2026
-
基于 AMD 锐龙 AI 处理器和 Radeon 显卡使用 ACE Step 1.5 实现商业级 AI 音乐生成
February 04, 2026
-
AMD x ComfyUI:在 AI PC 上推进专业级生成式 AI
January 05, 2026



