智能体 AI 不是一种工作负载,而是一个端到端的工作流程。
Jun 29, 2026

人们在谈论 AI 基础设施的时候,常常先谈起运行在 GPU 之上的 AI 模型。但在实践中,市场对 AI 基础设施的需求日益取决于围绕模型的工作流程。
智能体 AI 系统不仅仅是根据提示词进行回答,它们更会解释意图、检索上下文、规划后续步骤、调用工具、应用策略、运行沙盒代码、执行事务、观察结果并返回结果。
每个步骤都是不同的工作负载,所有步骤加起来构成一个独特的工作流程。有些需要高核心密度,有些受益于高频和可预测的延迟,还有其他的步骤则要求内存容量、I/O、数据局部性、能效或承载大量并发服务的能力。
随着智能体 AI 变得越来越普遍,基础设施团队需要的不仅仅是单一的计算配置。CIO 和企业决策者需要与整个智能体工作流程相匹配的 CPU 产品组合。
AMD EPYC(霄龙)服务器 CPU 产品组合非常适合这些任务,它不是提供单一 CPU 来提供“一刀切”的答案,而是将每个 CPU 作为独特的一部分来处理智能体 AI 的多种工作负载。(如需详细了解 CPU 在智能体 AI 中的重要性,请参阅我之前的博客, 智能体 AI 改变了 CPU/GPU 的配比。
智能体 AI 工作流程的内部
当智能体接到一项任务时,它会将目标分解为多个步骤并逐步完成,通常会在完成之前多次循环。在典型的序列中,请求会到达强制执行策略的网关。规划层(通常运行较小的 AI 模型)决定了任务的路由方式。然后,智能体查询数据库,调用 GPU 集群进行更深入的推理,基于该推理使用工具,验证输出结果并决定是再次循环还是退出。
这就解释了为何智能体 AI 应被视为端到端的工作流程,而非单一工作负载。正确的基础设施策略首先要映射每个工作流程,然后为其分配合适的 CPU 资源。
AMD 专注于工作流程中的每一个环节:包括用于高频、高密度计算的 EPYC(霄龙)CPU,用于 AI 推理和训练的 AMD Instinct 加速器,还有以可预测的方式传输数据的 Pensando™ 网络。
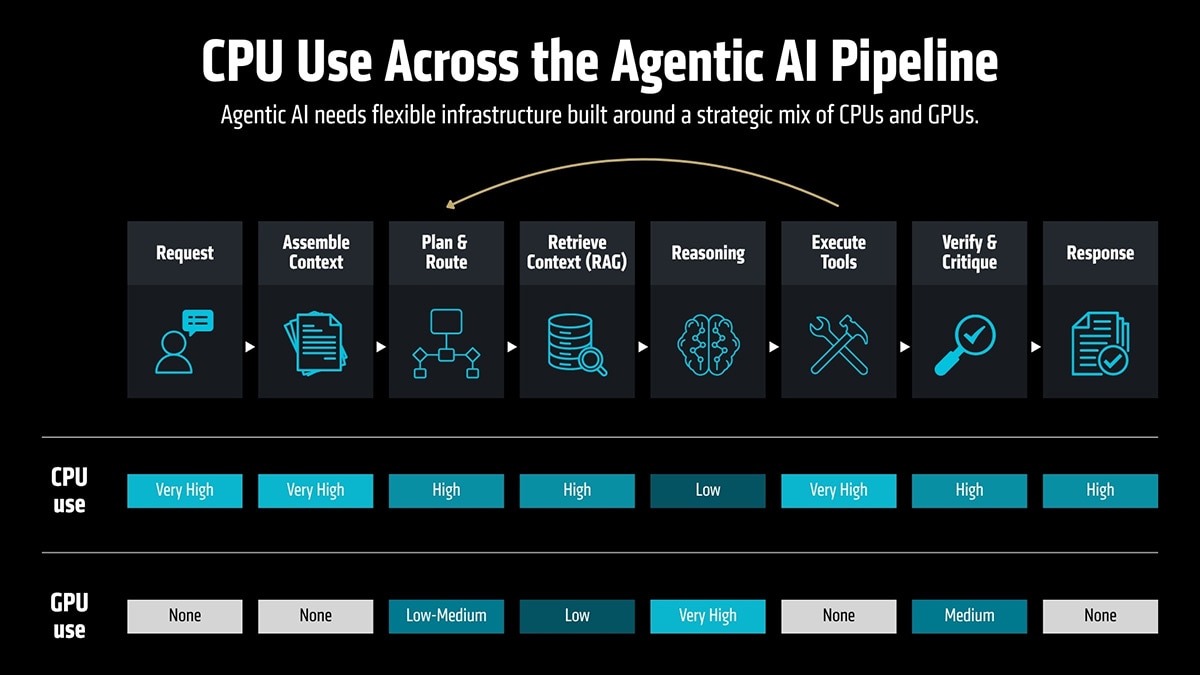
在延迟至关重要的地方,在吞吐量占主导地位的地方,以及两者都不可或缺的地方
工作流程的每个阶段都有不同的需求,因此我们围绕多种配置场景构建了 AMD EPYC(霄龙)产品组合。
- 智能体编排、沙盒执行、工具调用:当需要多个智能体同时运行沙盒代码(例如 Python)、调用 API 或查询数据库时,核心密度可能比时钟速度更重要。我们的第五代 AMD EPYC(霄龙)服务器 CPU 提供最多可达 192 核心和 384 线程,支持同步多线程处理。今年晚些时候,我们的下一代 EPYC 处理器(代号为“Venice”)将把这一数字提升到 256 核心和 512 线程。
- 在企业应用程序上运行工具:智能体之所以有用是因为它可以调用工具或企业应用程序。CPU 拥有超多的核心和高性能,能够处理大量且种类繁多的传入请求。AMD EPYC(霄龙)9005 系列处理器就能兼顾这些请求。它拥有 8 至 192 个核心和高达 640GB/s 的内存带宽,而“Venice”处理器则将核心/线程数量增加到 1.3 倍,内存带宽增加到 2.5 倍。
- 分析与推理:智能体要完成工作,就依赖于推理。大语言模型主要在 GPU 上运行,主机 CPU 可充分利用 GPU。为了让加速器保持忙碌,就需要发挥主机节点 CPU 的优势:强大的单核性能、高频率以及适当的核心平衡能力(有时需要的比您想象的要少)、内存带宽、I/O 和网络。主机节点 CPU 的恰当组合可以使 GPU 集群获得合适的指令,以便每个集群提供尽可能多的 Token。AMD EPYC(霄龙)9575F 处理器具有 64 个核心,能够以高达 5Ghz 的频率运行,从而实现了这种高单核性能。“Venice”将进一步扩展 EPYC(霄龙)CPU 的高频产品。
思维惯性带来的挑战
在与企业客户的对话中,有几个模式很突出。
首先,许多企业根据传统规格(例如 16 核和 32 核 CPU)对 CPU 基础设施的采购进行标准化。智能体工作流程的某些阶段需要更高的核心数,而对于其他阶段则需要更高的频率,并且客户需要灵活地针对这两个阶段进行配置。我们的思维方式应该从单一的 CPU 标准转变为与智能体工作流程相匹配的产品组合。
其次,随着智能体成为使用现有 IT 基础设施的主要用户,企业应用和推理服务器也会产生乘数效应。一旦您让员工能够构建和部署自己的智能体,智能体的使用率就会迅速增长。IT 规划团队应该询问他们的基础设施之上会发生什么——例如数据库、用于 ERP 和 CRM、BI 和身份管理的平台以及推理服务器(当智能体大幅提高使用量时)。
首席信息官的问题
智能体 AI 正在改变企业确定基础设施规模的方式。如果 IT 领导者将其视为一个单一的问题(单一的 GPU 策略或用 CPU 解决一切问题),则很可能会遇到挑战。但随着智能体数量激增,那些规划多样化的端到端工作流程且每个阶段都有不同计算需求的人员可以更高效地扩展业务。
值得问的问题不在于您的企业需要多少个 CPU 或 GPU 来支持智能体 AI。关键在于您是否将基础设施与智能体 AI 在工作负载中的多个阶段的工作方式相匹配。如果您尽早规划这些阶段并为每个阶段选择正确的算力配置,那么随着这些阶段的不断扩展,您的业务将在速度和效率方面处于有利地位。



Related Blogs
-
AMD Advancing AI 2026 前瞻:精彩内容抢先看
抢先了解“AMD Advancing AI 2026”大会,探索塑造 AI 未来的核心议题、会议环节及创新技术。了解行业领军者如何携手合作,共同探讨实际应用场景以及在企业范围内规模化部署 AI 的策略。
July 14, 2026
-
Gartner 将 AMD 评为 Gartner® AI 供应商竞争中的当前领先企业
Gartner 在一份报告中将 AMD 称为企业级 AI 服务器 CPU 领域的当前领跑者。
June 24, 2026
-
-
-
AMD 推出全新锐龙 AI Halo 开发者平台和锐龙 AI Max PRO 400 系列处理器,助力新一代智能体计算机发展
AMD 推出面向本地智能体 AI PC 和工作站的锐龙 AI Halo 和锐龙 AI Max PRO 400 系列。
May 20, 2026
-
AMD携手联想百应打造x86全栈算力+端云混合+智能体服务
联想百应AI Max+395系列旨在给开发者、中小企业的AI本地化智能体提供 “隐私可控的创作自由和使用自由”。
April 28, 2026
-
跳出概念炒作:将 AI PC 的潜在价值转化为切实商业收益
AI PC 正在重塑企业战略。了解 AMD 计算连续体如何帮助首席信息官跳出概念炒作,通过部署 AI 创造切实商业价值。
April 23, 2026
-
为现代工作室的生产引擎添能助力:AMD 亮相 NAB 2026
2026 年美国广播电视展 (NAB Show) 将于 4 月 18 日至 22 日在拉斯维加斯举行。整个行业正发生着令人振奋的新变化,我们期待在展会上与您相见!
April 17, 2026







