BlueQubit 基于 AMD 平台实现超大规模单 GPU 量子仿真
Mar 20, 2026

为什么基于 GPU 的量子仿真器至关重要
随着量子计算从纯粹的学术研究转向广大工程师、研究人员和开发者能够实际接触的技术,量子仿真器已成为生态系统中不可或缺的一部分。尽管量子硬件仍在不断改进,但如今的设备仍存在容量限制,且往往难以大规模访问。对于大多数从业者而言,仿真器一直是加快建立直观认知、搭建算法原型和调试量子程序的可靠方式。
仿真器提供了一种理想化、无噪声的环境,使开发者能够快速迭代。借助仿真器,开发者能够验证正确性、试验线路设计方案,并探索算法行为,而无需担心校准漂移、排队时间或硬件错误。在许多工作流程中,仿真都是接入真实量子硬件之前的第一个环节,且往往是耗时最长的环节。
在各类仿真器中,基于 GPU 加速的仿真器发挥着尤为重要的作用。从本质上讲,通用量子线路仿真以线性代数为主,而这正是 GPU 所擅长的工作负载类型。与 CPU 相比,GPU 能够提供大规模并行处理能力,并拥有显著更高的内存带宽,可直接缩短单量子门仿真耗时,并能够处理规模更大的量子线路。
本博文介绍了我们如何将基于 GPU 的量子仿真推向极限,在 AMD 硬件上运行我们认为迄今为止规模最大的单 GPU 通用量子仿真:基于 AMD Instinct MI300X GPU 实现最高可达 34 量子比特的全状态仿真。
挖掘 AMD GPU 性能极限
AMD MI300X GPU 之所以在量子仿真领域格外突出,核心关键在于显存容量。MI300X GPU 的显存容量超大,可支持更大规模量子态的仿真任务。由于全态仿真器需要为一个 n 量子比特系统存储 2n 个复振幅,显存往往是最难突破的首要性能瓶颈。在实际应用中,更大的显存空间往往决定了是遇到性能上限,还是能再多扩容一整个量子比特。
我们的目标很明确:充分释放 MI300X GPU 硬件潜力,探索单 GPU 量子仿真所能达到的极限。我们希望了解单个加速器的真正极限,因此并未采用多节点或分布式架构(这会带来通信开销和延迟)。
为此,我们在 Qiskit Aer 的基础上进行了扩展,通过一些有针对性的优化补丁,在 AMD GPU 上实现了 34 量子比特的仿真。这些改进重点围绕针对 MI300X 架构优化的显存管理和执行路径。
基准性能测试
为了验证这些结果,我们首先运行了一组标准基准测试。具体而言,我们在 AMD MI300X GPU 上执行量子体积式线路,并对性能进行分析。
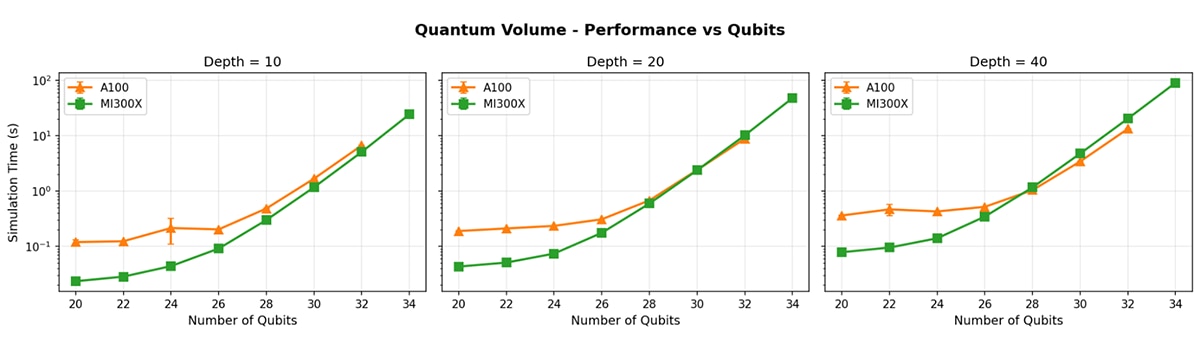
图 1 中的结果表明,在单量子门仿真耗时方面,MI300X 整体表现出色。量子门执行耗时随线路深度与线路宽度的变化趋势说明 AMD GPU 堆栈在通用量子仿真工作负载中出色的原生性能。
MI300X 真正的差异化优势在于容量。凭借超大显存容量,它能够稳定运行小显存 GPU 根本无法承载的量子线路仿真任务。在实际应用中,这意味着单 GPU 全态仿真可额外支持一个量子比特,使得问题处理规模实现指数级提升。
超越基准测试:真实量子线路工作负载
基准测试具备一定参考价值,但真正的考验在于这种规模能否支撑有实际意义的仿真任务。为此,我们运行了一系列复杂度更高的量子线路工作负载,贴合仿真器的实际应用场景。
峰值线路与 HQAP 实例
本次测试聚焦 34 量子比特规模的峰值线路,包含多组高难度 HQAP(Heuristic Quantum Advantage Peaked,启发式量子优势峰值)线路实例。这类线路仿真难度极高,常被用于与量子优势相关的研究论证。尽管业界普遍认为 HQAP 实例在传统计算条件下大约可在 50 量子比特以内的范围内求解,但对其进行大规模仿真仍极具挑战。
图像缩放
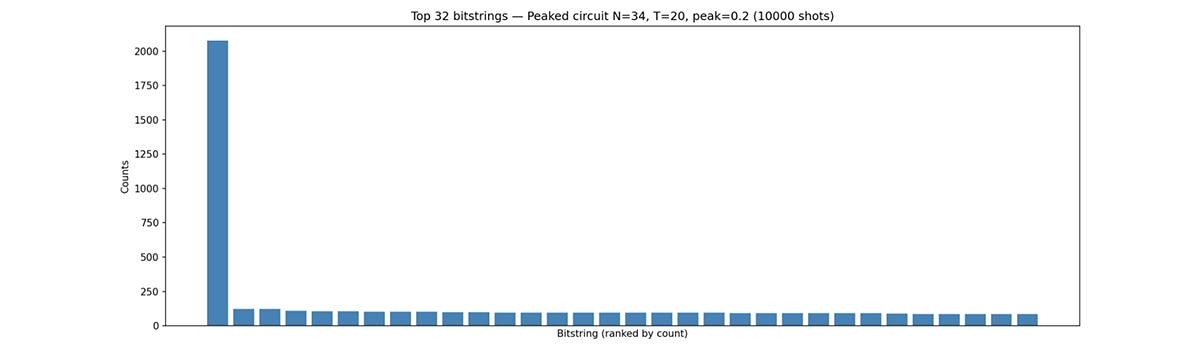
借助 MI300X,我们在单块 GPU 上得以成功仿真最高 34 量子比特的 HQAP 线路;这类任务以往通常需要多节点集群部署,或是采用激进的近似方法才能完成。图 2 为经过 10000 次采样仿真后,生成的比特串分布直方图。这提供了一种极具价值的工具,不仅可在完全可控的环境中研究此类线路,还可验证其结构与复杂度相关论断。
图像加载与传统数据编码
我们还参考 BlueQubit 的 Quantum Image Loading(量子图像加载)论文,开展了数据编码类工作负载的相关研究。在该应用场景中,要将传统图像数据编码为量子线路,再通过仿真运算并解码,以还原原始图像。
我们基于 BlueQubit 数据加载器,构建了不同规模、可编码传统图像数据的量子线路。我们随后利用基于 AMD 的仿真器对这些线路进行仿真,并依据输出的量子态完成图像重构。

34 = 2 x 17 量子比特

8 个区块 × 18 量子比特

32 个区块 × 16 量子比特

128 个区块 × 14 量子比特
图 3:道路场景的图像编码示例:展示借助 BlueQubit 数据加载器将传统数据编码为量子比特的过程
图 3 中的图像取自自动驾驶任务所使用的开源 HSD 数据集(Honda 场景数据集)。增加区块数量与总量子比特数能够持续提升图像编码分辨率。
我们已成功在 34 量子比特规模下运行上述工作流,重现了与原始论文相近的实验结果。正如该论文所述,高效的传统数据编码仍是量子机器学习领域最难攻克的挑战之一。此类工作流是打造实用量子分类器及其他基于真实世界数据的下游应用的重要一步。
ROCm 集成:在 AMD GPU 上启用 Qiskit Aer
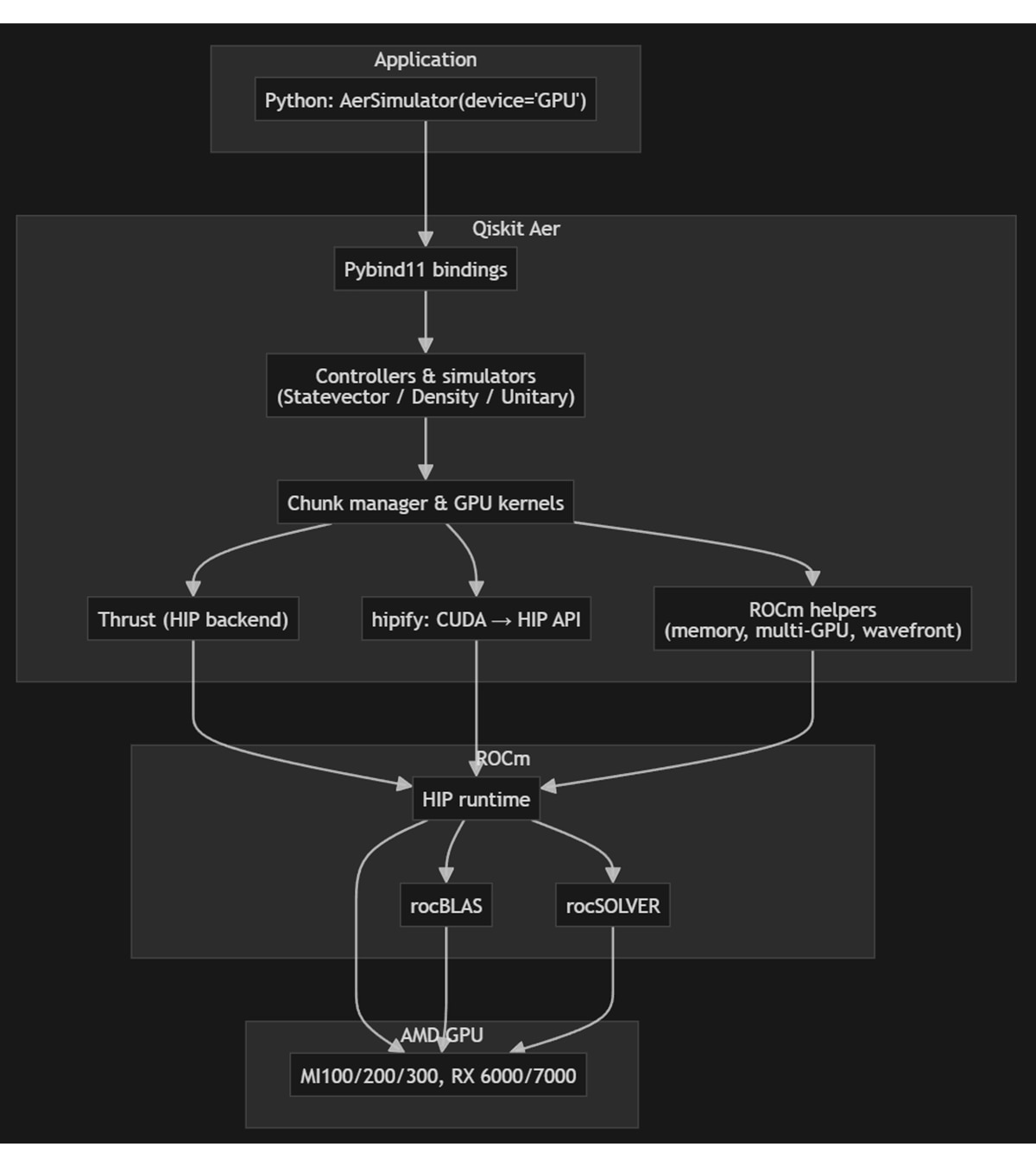
Qiskit-Aer 现已支持 AMD GPU。通过增强现有 GPU 实现方案,而非另行创建和维护独立分支,Qiskit-Aer 依托 ROCm 扩展了对 AMD GPU 的支持。
该仿真器原本就依赖 Thrust 库实现 GPU 并行计算,因此本次优化将 ROCm 新增为 CUDA 之外的第二个 Thrust 后端。编译系统会在编译阶段自动选择后端:选择 ROCm 时,采用 HIP 工具链与 Clang 编译器,面向 AMD GPU 架构编译,并链接 AMD 数学库(rocBLAS、rocSOLVER,必要时调用系统 LAPACK),替代对应的 CUDA 组件。通过一个精简的可移植层,将 CUDA API 名称映射至 HIP,并处理 AMD 架构特有特性,例如 CDNA 波前大小、shuffle 内置函数等;借助条件编译,同一套 GPU 内核与态向量逻辑可分别面向 NVIDIA 和 AMD 进行编译。专属 ROCm 支持模块负责显存管理、多 GPU 分配以及针对特定架构的调优。
该版本还利用 ROCm 7.2 全新功能特性,包括:HIP 编译器优化升级、多 GPU 扩展能力提升、显存管理增强,从而在 AMD 硬件上实现更快、更高能效的量子线路仿真。用户可沿用完全一致的 Python API – AerSimulator(method='statevector', device='GPU'),并直接通过 qiskit-aer-gpu-rocm 软件包安装 ROCm 版本;目前支持态向量、密度矩阵、幺正矩阵等仿真方法,同时在 Linux 平台上支持多 GPU 并行与分块缓存(并提供各 GPU 系列推荐配置),适配 AMD Instinct (MI100/MI200/MI300) GPU 以及 AMD Radeon (RX 6000/7000/9000) GPU。
展望未来:持续扩大规模
这项工作仅仅是个开始。我们正在努力将 AMD GPU 引入 BlueQubit (BQ) 平台,让这种高性能量子仿真惠及更多用户。
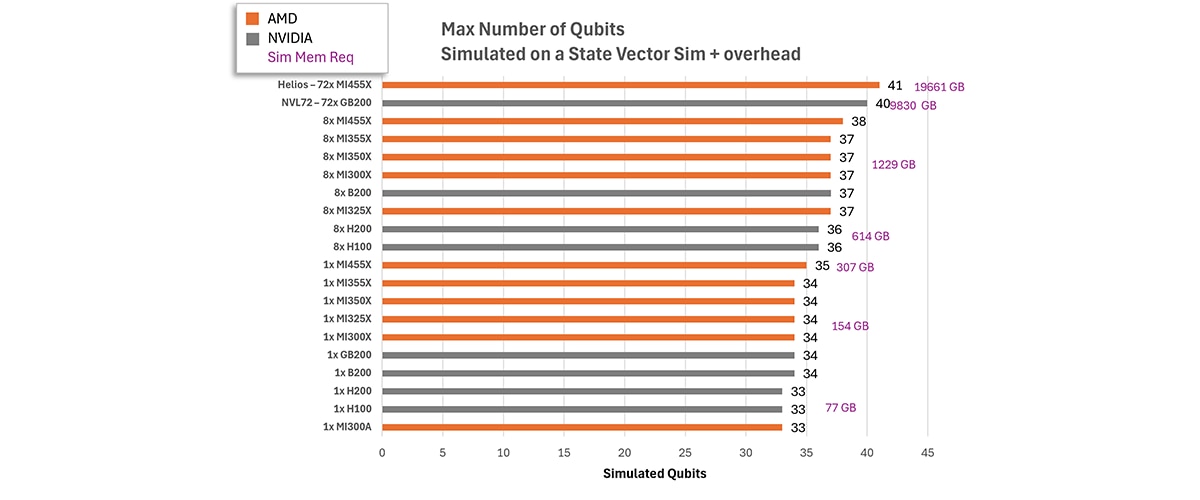
展望未来,我们相信单节点仿真仍有进一步突破的空间。随着显存管理、内核效率和仿真器架构持续改进,在单个 Helios 机架上实现 41 量子比特的仿真已指日可待。达到这一规模后,单机架运行将极具优势:原本需要多 GPU 部署才能完成的仿真任务,可在单机架内运行,无需再承受往往占据大量运行耗时的通信开销与网络延迟。图 5 展示了,假设单精度复数占用 8 字节,在不同硬件配置下,态向量仿真可支持的最大量子比特数预测值。显存需求预计为 2^n * 8 bytes * 120%,其中 n 为量子比特数量。依托高量子比特数与低延迟这两大优势,将为当下打造速度更快、响应更灵敏的仿真解决方案打开全新局面。
图像缩放
这仅仅是 AMD GPU 赋能量子仿真的开端。我们正与 Qsim、Qibo 等开源社区以及商业解决方案厂商密切合作。
如果您目前正从事量子仿真研究,并有意增加对 AMD GPU 的支持,或者希望亲身体验大规模量子仿真的潜力、探索在 AMD GPU 上突破传统仿真限制的可能性,欢迎与我们联系。请联系 AMD (quantum@amd.com) 或 BlueQubit(hayk@bluequbit.io、rht@bluequbit.io),开启对话交流。
免责声明:本博客中提供的 AMD 结果,均是在 AMD Developer Cloud 中的单 MI300x GPU (196 GB) 节点上运行测试所得。测试使用的是 Qiskit-Aer 分支(见上文链接),而非上游版本。量子比特数对应的显存需求预测值基于前文所述公式计算得出,并基于各款 GPU 的显存规格进行了对比分析。


Related Blogs
-
-
Gartner 将 AMD 评为 Gartner® AI 供应商竞争中的当前领先企业
Gartner 在一份报告中将 AMD 称为企业级 AI 服务器 CPU 领域的当前领跑者。
June 24, 2026
-
-
-
AMD 推出全新锐龙 AI Halo 开发者平台和锐龙 AI Max PRO 400 系列处理器,助力新一代智能体计算机发展
AMD 推出面向本地智能体 AI PC 和工作站的锐龙 AI Halo 和锐龙 AI Max PRO 400 系列。
May 20, 2026
-
AMD携手联想百应打造x86全栈算力+端云混合+智能体服务
联想百应AI Max+395系列旨在给开发者、中小企业的AI本地化智能体提供 “隐私可控的创作自由和使用自由”。
April 28, 2026
-
跳出概念炒作:将 AI PC 的潜在价值转化为切实商业收益
AI PC 正在重塑企业战略。了解 AMD 计算连续体如何帮助首席信息官跳出概念炒作,通过部署 AI 创造切实商业价值。
April 23, 2026
-
为现代工作室的生产引擎添能助力:AMD 亮相 NAB 2026
2026 年美国广播电视展 (NAB Show) 将于 4 月 18 日至 22 日在拉斯维加斯举行。整个行业正发生着令人振奋的新变化,我们期待在展会上与您相见!
April 17, 2026







