Largest Single-GPU Quantum Simulation on AMD by BlueQubit
Mar 19, 2026

Why GPU-based quantum simulators matter
As quantum computing moves from a purely academic pursuit into something that more engineers, researchers, and developers can actually touch, simulators have become a critical part of the ecosystem. While real quantum hardware continues to improve, today’s devices remain capacity-limited and are often difficult to access at scale. For most practitioners, simulators remain the fastest and most reliable way to build intuition, prototype algorithms, and debug quantum programs.
Simulators provide an idealized, noise-free environment where developers can iterate quickly. They allow you to validate correctness, experiment with circuit design choices, and explore algorithmic behavior without worrying about calibration drift, queue times, or hardware errors. In many workflows, simulation is the first - and often the longest - stage before anything ever touches real quantum hardware.
Among simulators, GPU-accelerated ones play an especially important role. At its core, universal quantum circuit simulation is dominated by linear algebra, and that is exactly the kind of workload GPUs are designed for. Compared to CPUs, GPUs can offer massive parallelism and significantly higher memory bandwidth, translating directly into faster per-gate simulation times and the ability to tackle larger circuits.
In this post, we describe how we pushed GPU-based simulation to its limits, running what we believe to be the largest single-GPU universal quantum simulations to date on AMD hardware: full-state simulations of up to 34 qubits on an AMD Instinct™ MI300X GPU.
Pushing AMD GPUs to the limit
The AMD MI300X GPUs stand out for one key reason that is especially relevant for quantum simulation: memory capacity. Compared to GPUs like NVIDIA’s H100, MI300X GPU offers more than 2× the memory, which directly translates into the ability to simulate larger quantum states. Since a full-state simulator requires storing 2n complex amplitudes for an n-qubit system, memory is often the first—and hardest—constraint to overcome. In practice, that extra memory can mean the difference between hitting a wall and adding an entire additional qubit.
Our goal was simple: fully utilize the MI300X GPU and see how far we could push single-GPU quantum simulation. Rather than relying on multi-node or distributed setups (which introduce communication overhead and latency), we wanted to understand the true limits of a single accelerator.
To do this, we built on top of Qiskit Aer, extending it with a small set of targeted patches to enable 34-qubit simulations on AMD GPUs. These changes focused on memory management and execution paths optimized for the MI300X architecture.
Benchmarking performance
To ground these results, we first ran a set of standard benchmarks. In particular, we compared quantum volume–style circuit executions on the AMD MI300X GPUs against runs on an NVIDIA A100 GPU.
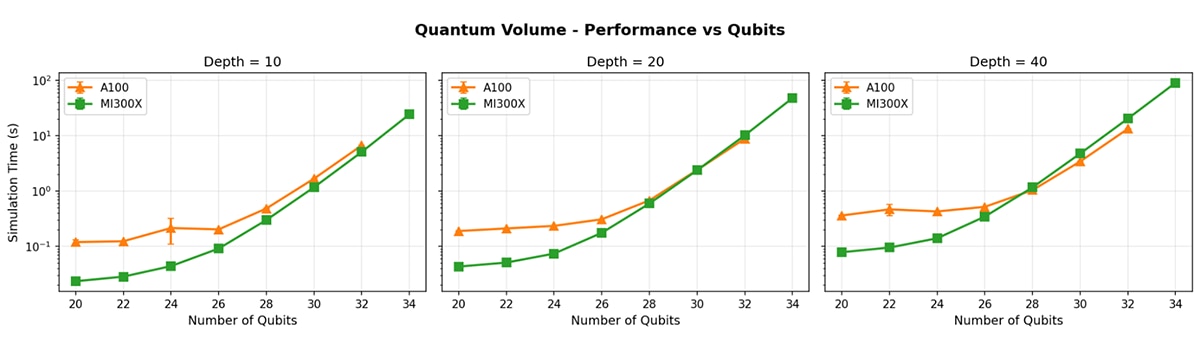
The results in Figure 1 show that, on a per-gate basis, the MI300X is broadly on par with the NVIDIA A100 in terms of simulation time. Gate execution scales similarly with circuit depth and width, indicating that the AMD GPUs stack can deliver competitive raw performance for universal quantum simulation workloads.
Where the MI300X really differentiates itself is in capacity. Thanks to its significantly larger memory, it can reliably simulate circuits that are simply out of reach for GPUs with smaller memory. In practice, this means an extra qubit for full-state simulation on a single GPU - an exponential jump in problem size.
Beyond benchmarks: real circuit workloads
Benchmarks are useful, but the real test is whether this scale unlocks meaningful simulations. To that end, we ran a series of more demanding circuit workloads that reflect how simulators are used in practice.
Peaked circuits and HQAP instances
We focused on peaked circuits at the 34-qubit scale, including hard instances of HQAP (Heuristic Quantum Advantage Peaked) circuits. These circuits are notoriously challenging and are often used in discussions around quantum advantage. While HQAP instances are believed to be classically solvable up to roughly the 50-qubit regime, simulating them at scale is still extremely demanding.
Image Zoom
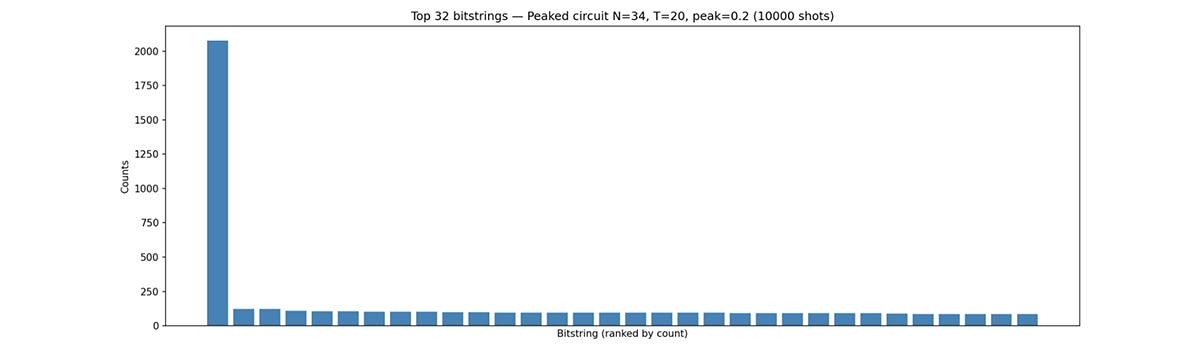
Using the MI300X, we were able to successfully simulate HQAP circuits with up to 34 qubits on a single GPU—something that would typically require multi-node setups or aggressive approximations. Figure 2 shows the histogram over a bitstring resulting after simulating 10000 shots. This provides a valuable tool for studying these circuits in a fully controlled environment and for validating claims about their structure and hardness.
Image loading and classical data encoding
We also explored data-encoding workloads inspired by BlueQubit’s Quantum Image Loading paper. In this use case, classical image data is encoded into quantum circuits, which are then simulated and decoded to reconstruct the original images.
Using BlueQubit’s data loader, we constructed circuits of varying sizes that encode classical image information. We then simulated these circuits using our AMD based simulator and reconstructed the images from the resulting quantum states.

34 = 2 x 17qubits

8 blocks x 18qubits

32 blocks x 16qubits

128 blocks x 14qubits
Figure 3: Image encoding of a road scene demonstrating classical data encoding to Qubits using BlueQubit’s data loader
The image in Figure 3 is taken from the open HSD (Honda Scenes Dataset) dataset used for autonomous driving tasks. Increasing the number of blocks and total qubits allows for increasingly improved resolution.
We successfully ran these workflows at the 34-qubit scale, reproducing results similar to those reported in the original paper. As noted there, efficient classical data encoding remains one of the hardest challenges in quantum machine learning. Workflows like these are an important step toward practical quantum classifiers and other downstream applications that operate on real-world data.
ROCm Integration: Enabling Qiskit Aer on AMD GPUs
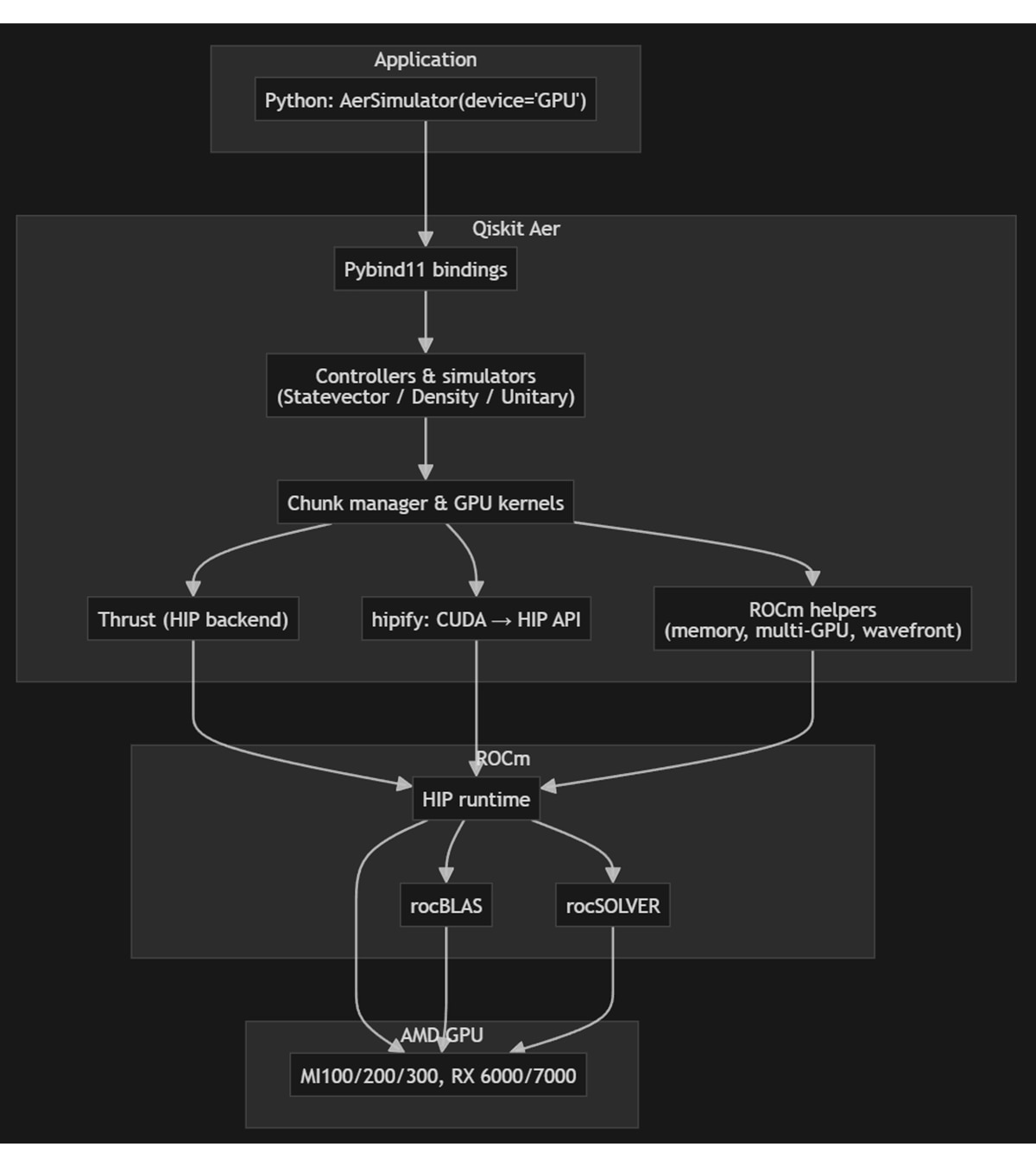
Qiskit-Aer already supports AMD GPUs. As part of this work, Qiskit‑Aer was updated to expand its AMD GPU support through the ROCm™ software by enhancing the existing GPU implementation rather than creating or maintaining a separate fork.
The simulator already relied on the Thrust library for GPU parallelism, so ROCm was added as a second Thrust backend alongside CUDA. The build system selects the backend at compile time: for ROCm, it uses the HIP toolchain and Clang, targets AMD GPU architectures, and links AMD math libraries (rocBLAS and rocSOLVER, with system LAPACK where needed) instead of CUDA equivalents. A thin portability layer maps CUDA API names to HIP and handles AMD specific behavior, such as CDNA wavefront size and shuffle intrinsics, so the same GPU kernel and state vector logic compile for both NVIDIA and AMD via conditional compilation. Dedicated ROCm support handles memory management, multi-GPU distribution, and architecture-specific tuning.
This version also takes advantage of the latest ROCm 7.2 features—including improved HIP compiler optimizations, better multi-GPU scaling, and enhanced memory management—to deliver faster and more efficient quantum circuit simulation on AMD hardware. Users see the same Python API – AerSimulator(method='statevector', device='GPU') – and can install a ROCm build as the qiskit-aer-gpu-rocm package, with statevector, density matrix, and unitary methods, plus multi-GPU and cache blocking (with recommended settings per GPU family) on AMD Instinct (MI100/MI200/MI300) GPUs and AMD Radeon™ (RX 6000/7000/9000) GPUs on Linux.
What’s next: scaling further
This work is just the beginning. We are working on bringing AMD GPUs into the BlueQubit (BQ) platform, making this level of performance accessible to a broader set of users.
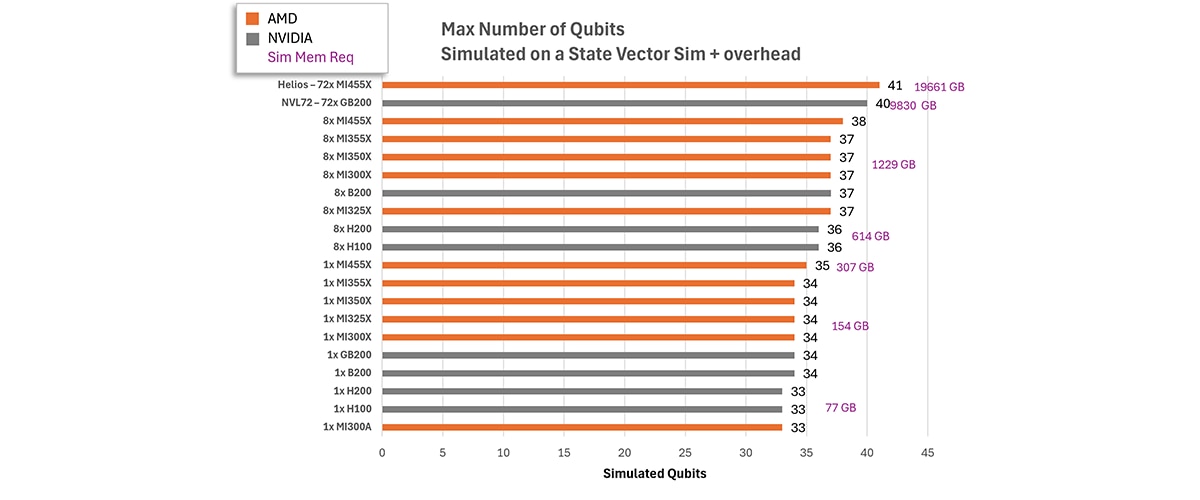
Looking ahead, we believe it should be possible to push single-node simulations even further. With continued improvements in memory management, kernel efficiency, and simulator architecture, 41-qubit simulations on a single Helios rack are within reach. At that scale, single-rack execution is especially compelling: simulations that would normally require setups with more GPUs can run without the communication overhead and latency that often dominate runtime. Figure 5 shows the projection of the maximum number of qubits that can be simulated via the state vector for different hardware configurations, assuming 8 bytes per single-precision complex number. The memory requirement is projected to be 2^n * 8 bytes * 120%, where n is the number of qubits. That combination - large qubit counts and low latency - opens the door to the fastest, most responsive simulations available today.
Image Zoom
This is just the beginning for Quantum simulation on AMD GPUs. We’re working closely with open-source communities such as Qsim and Qibo, as well as commercial solutions.
If you are currently working on Quantum Simulations and are interested in adding support for AMD GPUs, or if you want to explore firsthand the possibilities of large-scale quantum simulations and pushing the limits of classical simulation on AMD GPUs, we encourage you to reach out. Contact AMD (quantum@amd.com) or BlueQubit (hayk@bluequbit.io, rht@bluequbit.io) to begin the conversation.
Disclaimer: The AMD results presented in this blog were obtained running on an AMD Developer Cloud on 1xMI300x GPU node (196 GB). It uses a fork of Qiskit-Aer (link above) rather than the upstream version. The Nvidia results used Azure's Standard_NC24ads_A100_v4 nodes with 1xA100 GPU (80 GB). The qubit projections for memory requirements are based on the aforementioned equation, compared with the memory size specifications for each GPU.


Related Blogs
-
Open Standards, Real Solutions: AMD at SIGGRAPH 2026
AMD heads to DigiPro and SIGGRAPH 2026 to discuss open standards, production technology, and the fine art of Gaussian splatting.
July 17, 2026
-
FastFlowLM Joins AMD to Advance AI Inference
The FastFlowLM team has joined AMD, marking another key step in AMD’s strategy to advance AI performance and efficiency across the stack.
July 17, 2026
-
Running Cloud Agents? Your Most Important Upgrade Could be an AMD Zen 5 CPU
As agents begin navigating applications, coordinating tools and completing real work, the local CPU is becoming a critical part of the AI execution pipeline.
July 16, 2026
-
From Vector Search to Agentic RAG: Building an Enterprise Research Analyst with hipVS — ROCm Blogs
Learn how to build an agentic RAG research assistant using hipVS GPU-accelerated vector search on AMD Instinct GPUs, with multi-query decomposition, parallel retrieval, and cited sources synthesis.
July 14, 2026
-
When a Faster Kernel Doesn’t Speed Up Serving: Profiling FP8 KV Cache on AMD Instinct MI308X — ROCm Blogs
Learn how a 34% faster FP8 KV cache kernel delivered 0% E2E speedup, and how profiling attribution exposed the hidden dtype-cast cost on MI308X.
July 14, 2026
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026
-
Local Image and Video Generation on AMD Ryzen™ AI Max+ Processor (Windows) — ROCm Blogs
Run ComfyUI natively on Windows on AMD Ryzen AI Max+ with ROCm 7.2.1—SDXL, Flux, and video workflows on the Radeon 8060S, no WSL.
July 13, 2026
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026







