Advancing Windows ML Acceleration with AMD at Microsoft Build 2026
Jun 02, 2026

Since Microsoft Ignite 2025, AMD has continued advancing NPU- and GPU-accelerated AI on Windows, with a focus on developer productivity, performance, and platform scale. Ahead of Microsoft Build 2026, we delivered meaningful updates across the NPU and GPU Execution Providers (EPs) as well as the broader Windows ML ecosystem for AMD APUs, NPUs, and discrete GPUs.
These improvements span the Windows AI stack and Microsoft’s emerging DirectX Compute Graph Compiler. DxCGC uses MLIR-based representations to bring full model graphs into the DirectX pipeline, enabling compiler-driven graph optimization, memory planning, operator fusion, and GPU execution on AMD hardware. On the NPU side, the latest work improves inference performance, developer tooling, benchmarking, and web platform integration.
This post highlights the platform enhancements delivered during this period and how they improve the end-to-end developer experience for AI inference workloads, including diffusion models and large language models (LLMs).
NPU Execution Provider Improvements
The NPU EP now supports more LLMs and runs supported models more quickly.
These gains come from improvements across the execution path, including operator fusion, more efficient kernels, and reduced overhead in end-to-end model execution. Model coverage has also doubled, with added support for GPT-OSS-20B, Qwen 2.5, and other models. The AI toolkit (AITK) now provides per-operator execution timelines and NPU utilization breakdowns, helping developers identify and resolve inference bottlenecks with greater precision.
Strong scores in Procyon® AI Computer Vision Benchmark 2.0
Windows ML achieved excellent scores on the Procyon AI Computer Vision 2.0 benchmark, validating end-to-end performance across a range of workloads on similar NPUs.
WebNN Support (Experimental)
An initial Web Neural Network API (WebNN) integration now routes browser-based inference through the Windows ML AMD NPU execution path, extending hardware acceleration to web applications.
GPU Execution Provider (EP) Advancements
We introduced a new plugin interface for the ONNX Runtime GPU Execution Provider with the latest GPU EP release. This new release aligns with the current ONNX Runtime plugin API and separates GPU backend implementation from the ONNX Runtime core, allowing GPU backends to evolve without requiring core runtime updates.
Separating backend implementation from the core runtime provides several benefits. First, it gives backend teams a stable ONNX Runtime plugin ABI (Application Binary Interface) to target, improving long-term compatibility and reducing integration work. Second, it allows the GPU backend to move faster, with shorter release cycles and less dependency on core runtime changes.
Finally, it simplifies deployment. A single, unified MSIX package now supports both legacy GPU EP backends and new plugin-based, ABI-compatible GPU EP implementations. Developers can continue using existing backends while adopting the new plugin model as they see fit and at their own pace.
AMD ROCm™ Software 7.1 Library and Runtime Upgrade
The GPU EP has been upgraded to ROCm 7.1-based runtime and libraries. This delivers measurable gains in kernel-level performance and runtime stability while reducing a model’s overall memory footprint. These updates improve out-of-the-box behavior in Windows ML inference workloads running on AMD GPUs.
Optimizations for Diffusion Models
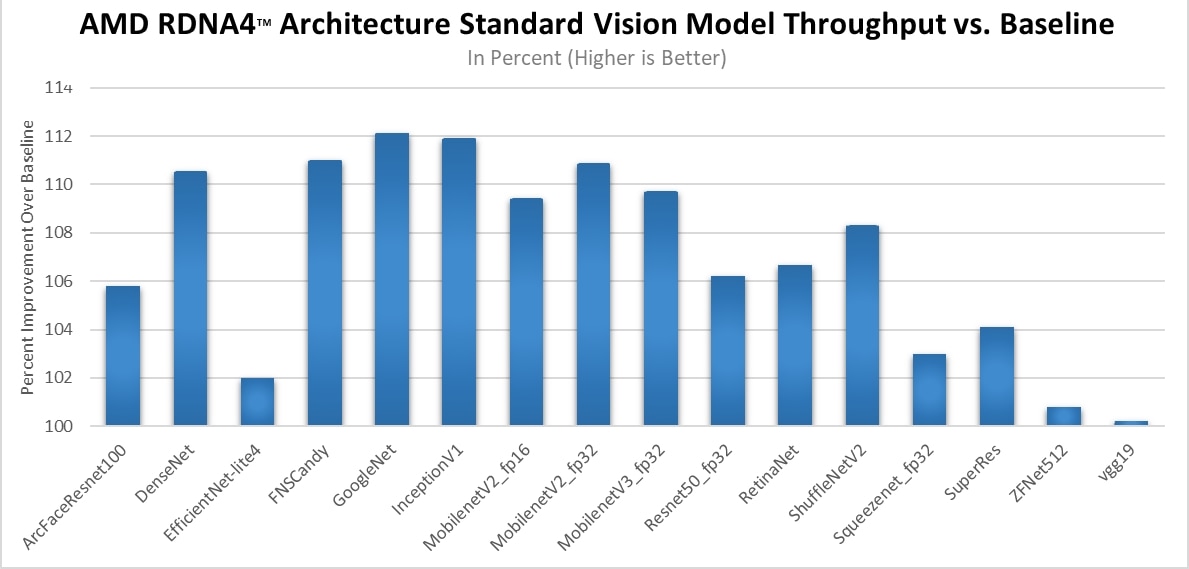
AMD delivered targeted performance and memory optimizations for diffusion workloads, reducing memory use and improving throughput for widely used models such as Stable Diffusion 3.5 (SD3.5), SDXL, and FLUX.1. These improvements make image generation pipelines more efficient, particularly in memory-constrained scenarios, and improve both responsiveness and scalability when these workloads are run on AMD GPUs. Additional performance data for AMD RDNA4™-based GPUs in diffusion1 and standard vision models2 is shared below:
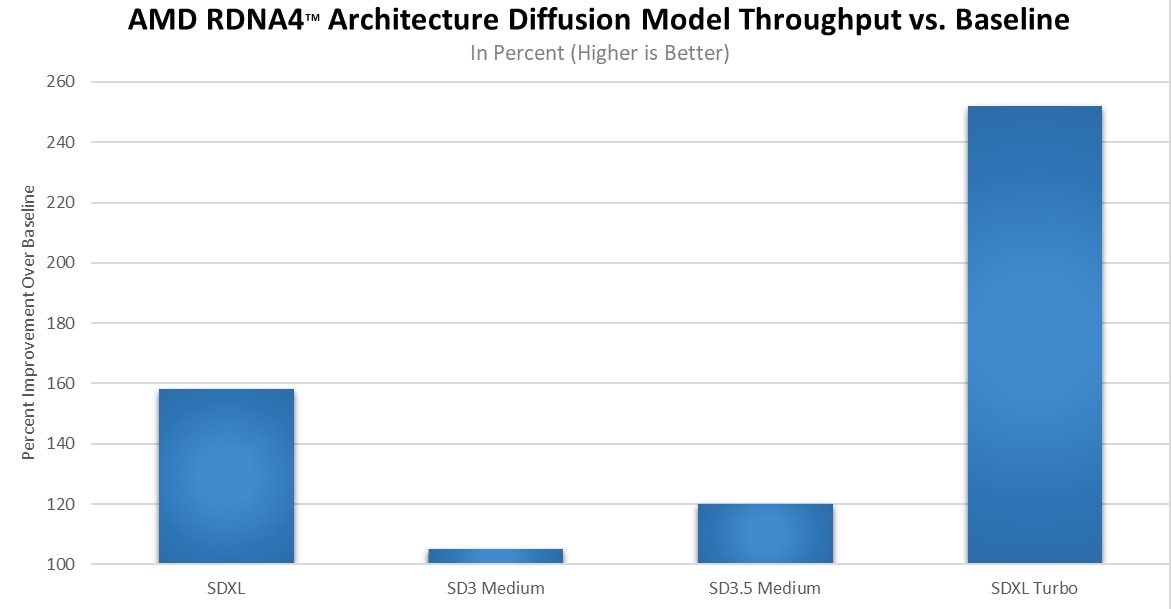
Standard Vision Models:
Expanded Hardware Support
GPU EP support now extends to AMD Ryzen™ AI 400 Series processors, enabling GPU-accelerated AI inference on the latest Ryzen AI platforms. This expansion broadens the hardware targets available to developers using the ONNX Runtime GPU EP for client-side AI workloads on Windows.
LLM Stability and Performance Enhancements
Large language model (LLM) workloads remain a key focus area. Since Ignite 2025, we’ve delivered additional stability and performance improvements through enhanced integration with the onnxruntime-genai (OGA) and continued stability improvements via DirectML (DML). Together, these improvements have increased execution reliability, throughput, and overall efficiency when running transformer-based models on AMD GPUs.
Dx Compute Graph (CG) API with Windows AI API on AMD Radeon™ GPUs
Following the public launch of the DxCG API at GDC 2026, we are excited to announce a preview driver of DxCG integration with Windows ML on AMD GPUs via the Windows ML API. This preview provides early access to the Windows AI API, enabling a more direct and efficient mapping of machine learning graphs to modern GPU backends, while strengthening alignment across Windows ML, DirectX, and AMD GPU execution providers.
Integrating DxCG into Windows ML is a key step toward tighter cohesion across the Windows AI stack. It opens new opportunities for innovation at both the ML compiler level and within hardware acceleration, enabling developers to deliver higher-performance AI workloads on Windows.
On the AMD side, the DxCGC driver-based backend will introduce advanced graph optimizations and highly tuned GPU kernels specifically optimized for AMD Radeon™ GPUs. These optimizations will enable efficient execution paths through the Windows ML → DxCGC pipeline, delivering improved performance and scalability on AMD devices.
This preview driver also enables Microsoft PhiSilica workloads to run optimally on AMD platforms using these driver-based optimizations. Please note this driver is intended for preview purposes only and may not be suitable for production environments.
Looking Ahead
The updates delivered since Microsoft Ignite 2025 and highlighted at Build 2026 reflect our continued investment to make AI on Windows more performant, scalable, and easier to use when developing for different AMD platforms.
Whether you’re deploying diffusion models, running local LLMs, or building on the next generation of Windows ML APIs, these improvements are designed to help you move faster and ship with greater confidence on AMD hardware.
We look forward to continuing to work with the developer community throughout 2026.
1 - Testing as of May 2026 by AMD Engineering Labs on a test system configured with AMD Ryzen™ 9 7950X3D CPU, ROG Crosshair X670E Extreme motherboard, 32 GB DDR5 Memory, Windows 11 25H2 and AMD Radeon™ RX 9070 XT (Driver 26.3.1) vs a similarly configured system with graphics driver version 25.10.1 comparing Text-To-Image Diffusion Model Throughput between drivers. The following benchmark(s) were used: SDXL (1024x1024), SD3 Medium (1024x1024), SD3.5 Medium (1024x1024), and SDXL Turbo (512x512). System manufacturers may vary configurations, yielding different results. RX-1262.
2 - Testing as of May 2026 by AMD Engineering Labs on a test system configured with AMD Ryzen™ 9 7950X3D CPU, ROG Crosshair X670E Extreme motherboard, 32 GB DDR5 Memory, Windows 11 25H2 and AMD Radeon™ RX 9070 XT (Driver 26.3.1) vs a similarly configured system with graphics driver version 25.10.1 comparing Vision Model Throughput between drivers. The following benchmark(s) were used: ArcFaceResnet100, DenseNet, EfficienctNet-lite4, FNSCandy, GoogleNet, InceptionV1, MobilenetV2_fp16, MobilenetV2_fp32, MobilenetV3_fp32, Resnet50_fp16, Resnet50_fp32, RetinaNet, ShuffleNetV2, Squeezenet_fp32, SuperRes, ZFNet512, and vgg19. System manufacturers may vary configurations, yielding different results. RX-1263.

Contributors

Related Blogs
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Closing the GPU Cluster Validation Gap: A Kubernetes-Native Approach with CVF — ROCm Blogs
Learn how to validate AMD GPU clusters end-to-end with CVF: hardware acceptance, mesh bandwidth, RDMA, and RCCL testing in one pipeline.
July 28, 2026
-
AMD GPU Operator v1.5.0: DRA Support, Automated GPU Node Recovery, and Expanded Kubernetes Infrastructure Control — ROCm Blogs
Discover how AMD GPU Operator v1.5.0 improves GPU scheduling, automates node recovery, and expands Kubernetes control.
July 27, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026







