Win on TCO: How AMD Instinct™ MI355X GPUs Achieve Cost-Competitive Distributed Inference Through SGLang with MoRI
May 27, 2026

As large-scale LLM inference increasingly relies on multi-node disaggregated serving with wide Expert Parallelism (EP), the critical question for infrastructure teams is no longer "which GPU is fastest" but "which platform delivers the lowest cost per token at production interactivity levels."
Using SGLang with AMD's MoRI communication library on AMD Instinct™ MI355X GPUs, we demonstrate that AMD achieves competitive - and at key operating points, superior - Total Cost of Ownership (TCO) compared to NVIDIA B200 running Dynamo + TRT-LLM on DeepSeek-R1 disaggregated inference. These results are validated by InferenceX™, SemiAnalysis's open-source continuous benchmark platform that tests across hundreds of GPUs with a live dashboard.
This post describes what we have achieved, how we achieve it, and our future plans.
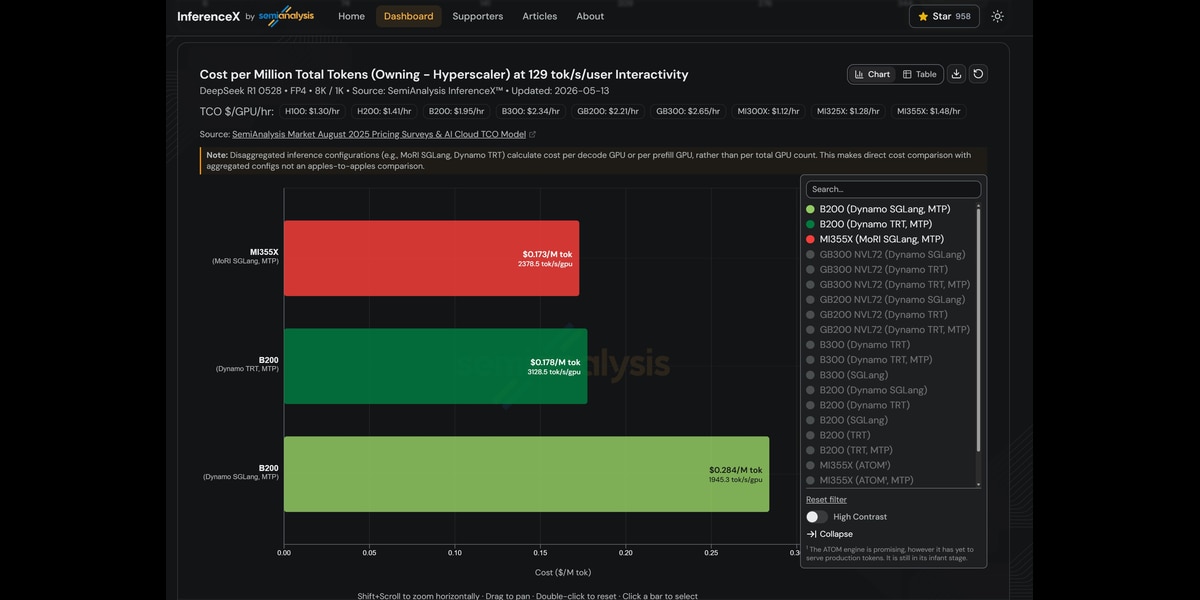
Results at a Glance
At the typical operating point representative of production coding assistants and interactive chatbots - e.g. 129 tok/s/user interactivity - we observe the following:
- AMD Instinct™ MI355X GPUs (MoRI SGLang MTP): $0.173 per million tokens, 2,378 tok/s/GPU (achieved on 24 GPUs)
- NVIDIA B200 (Dynamo TRT-LLM MTP): $0.178 per million tokens, 3,128 tok/s/GPU (achieved on 28 GPUs)
- NVIDIA B200 (Dynamo SGLang MTP): $0.284 per million tokens, 1,945 tok/s/GPU (achieved on 48 GPUs)
The MI355X GPUs delivers 2.9% lower cost than B200 TRT-LLM, 39% lower cost than B200 SGLang, and 1.22× higher throughput per GPU than B200 SGLang - winning on both cost and performance simultaneously.
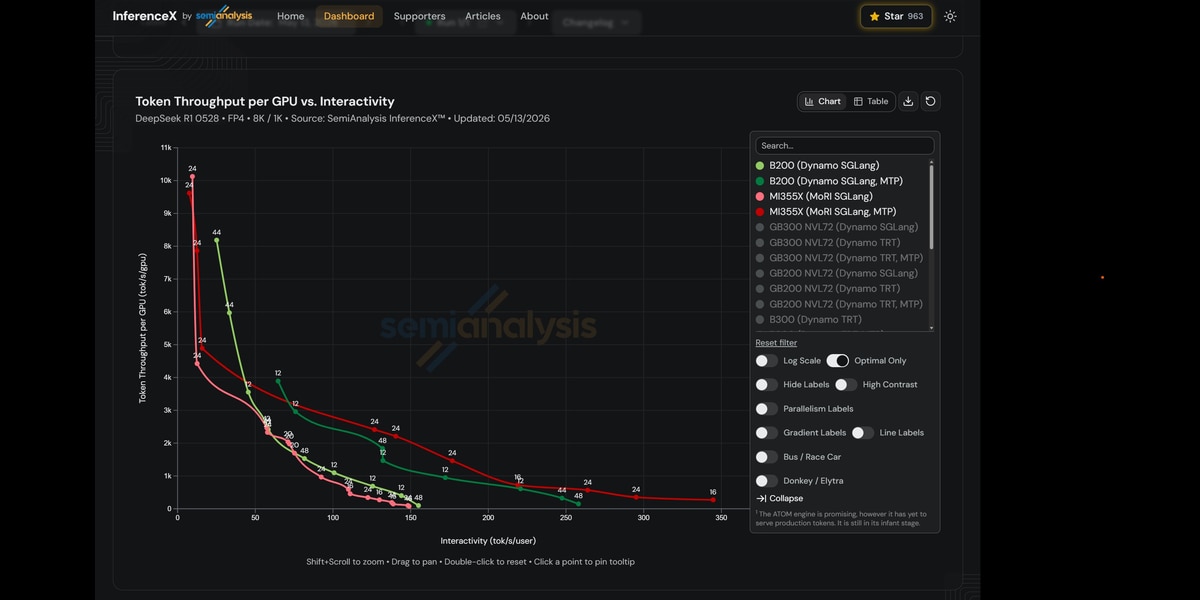
What You'll Learn Under the Hood
- How AITER FlyDSL empowers MoE in distributed scenarios
- How MoRI quantized dispatch/combine benefits expert parallelism
- How MoRI KV cache backend accelerates transfer
- How stream overlapping with SDMA hides communication latency behind compute
- How AITER FylDSL empowers MoE in distributed scenarios
- How Specv2 enablement on AMD GPU accelerates decoding
- How CPU streaming overhead is optimized for high throughput scenarios
Key Optimization Details
How MoRI quantized all2all dispatch/combine benefits expert parallelism
Hybrid FP4/FP8 quantized all-to-all
In expert-parallel MoE inference, each token must be dispatched to the top-k selected experts via dispatch and combine communication primitives. For DeepSeek-R1 with a hidden dimension of 7,168 and top-8 expert routing, BF16 communication volume is significantly higher than that of FP8 and FP4 quantized communication.
The key insight is that on-the-fly MXFP4 quantization of dispatch will bring faster transmission with accuracy lossless. Similarly, expert outputs (combine phase) tolerate FP8 quantization without meaningful accuracy loss.
MoRI supports multi-level quantized communication:
Case |
Path |
Combine Latency |
Normal (no-scale) |
fp8_blockwise specialized |
~736 µs |
Uniform−1024, 1024] (scale-active) |
fp8_blockwise specialized |
~770 µs |
Force-scale-active |
fp8_blockwise specialized |
~769 µs |
Reference |
bf16 no-quant |
~907 µs |
Reference |
fp8_direct_cast |
~526 µs |
For MXFP4 models such as amd/DeepSeek-R1-0528-MXFP4-v2, the system uses FP4 dispatch + FP8 combine, achieving a 2.56× overall round-trip bandwidth reduction (from 28,672 to 11,200 bytes per token).
Blockwise quantization preserves accuracy through fine-grained scaling. By default, FP8 blockwise uses per-128-element FP32 scale factors. It achieves a good tradeoff between performance and accuracy.
The quantization mode is auto detected from the model's weight format and can be overridden via SGLANG_MORI_DISPATCH_DTYPE and SGLANG_MORI_COMBINE_DTYPE environment variables.
Adaptive kernel selection
MoRI dynamically selects the optimal communication kernel based on workload characteristics:
Kernel |
Condition |
Optimized For |
IntraNode |
Single-node (≤8 GPUs) |
Shared memory / P2P |
InterNodeV1 |
Multi-node, >256 tokens/rank |
High throughput, staged RDMA |
InterNodeV1LL |
Multi-node, ≤256 tokens/rank |
Low latency |
AsyncLL |
SDMA-enabled paths |
Fully async send/recv split |
The switching threshold is automatically configured based on the decode batch size, ensuring that prefill phases (large batches) use high-throughput kernels while decode phases (smaller per-rank batches) use low-latency kernels.
How MoRI's KV Cache Backend Accelerates Transfer
Inline transfer for high-concurrency KV migration
- Lock-free inline execution. Transfer requests execute directly in the caller path instead of being dispatched to worker threads. Transfer plans are precomputed once and reused across all layers, eliminating per-layer scheduling overhead and reducing lock contention.
- Robust at scale. Default RDMA parallelism is increased to 4 queue pairs and 4 workers per transfer, with thread-safe connection reuse that prevents port exhaustion under thousands of concurrent requests.
Broader model coverage
Beyond standard MLA-based KV cache, MoRI adds state transfer support for hybrid architectures- Mamba (SSM state), SWA, and NSA - enabling disaggregated serving for models like Qwen3.5-397B-A17B. It also handles TP-mismatch scenarios where prefill and decode use different tensor-parallel degrees, correctly mapping replicated attention heads across ranks.
Metric |
MoRI-IO |
Mooncake |
Request throughput |
7.49 req/s |
6.80 req/s |
Input token throughput |
31,111 tok/s |
28,257 tok/s |
Output token throughput |
3,775 tok/s |
3,428 tok/s |
Total token throughput |
34,886 tok/s |
31,685 tok/s |
MoRI-IO delivers ~10% higher throughput than Mooncake across all metrics, with comparable single-request latency (~7 ms TPOT) and high accuracy (GSM8K 5-shot: 0.970).
Computation-Communication Overlap - Two-Batch Overlap (TBO) with SDMA
Even with 2–4× bandwidth reduction from quantization, all-to-all communication remains significant. Two-Batch Overlap (TBO) hides this latency by interleaving communication and compute across two micro-batches:
- MicroBatch A dispatch sends quantized tokens over the network on a dedicated communication stream
- While network transfer is in flight, MicroBatch B attention computes on the main compute stream
- MicroBatch A arrives; MoE GEMM runs
- MicroBatch A combine sends results back on the communication stream
- Meanwhile, MicroBatch B dispatch begins
The dispatch and combine operations are split into A/B phases - dispatch_a for local quantization on the compute stream, dispatch_b for network transfer on the communication stream. A CommStreamPool manages dedicated streams, and events synchronize handoff points.
When SDMA is enabled (MORI_ENABLE_SDMA=true), data transfers run on the AMD dedicated System DMA engines that move data between GPU memory and network interfaces without consuming any compute units. This achieves true zero-compute-overhead communication, keeping every compute unit available for GEMM operations throughout the pipeline.

FlyDSL FusedMoE for High-Performance MoE Compute
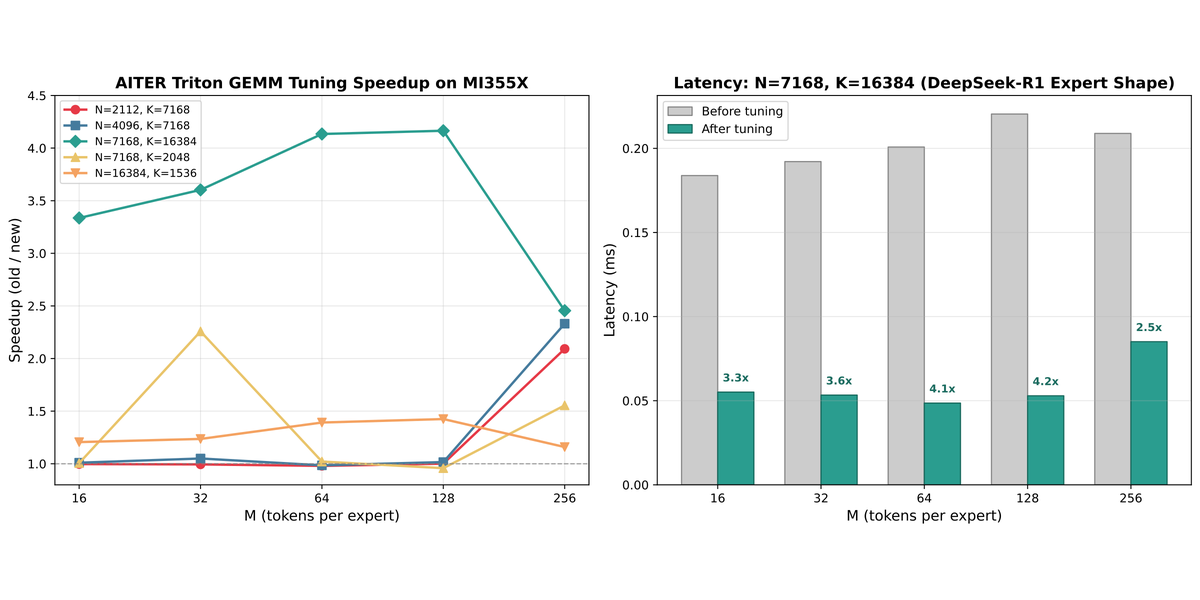
Traditionally, FusedMoE kernels on AMD relied solely on Composable Kernel (CK) - hand-tuned templates that are performant but inflexible. AITER introduces FlyDSL (Flexible Layout Python DSL), a Python DSL backed by an MLIR stack for authoring GPU kernels with explicit layouts and tiling, as a competitive FusedMoE kernel path for mixed-precision MoE (e.g., A4W4) on MI355X. FlyDSL enables rapid exploration of kernel configurations beyond what hand-tuned CK templates cover, and at a typical concurrency of 512, we gained up to 1.6× latency reduction for the FusedMoE compute.
MoE GEMM performance is shape-dependent, and the dominant shapes differ by serving scenario. In low-latency pure TP deployments, each GPU processes all experts with small batch sizes, producing tall-skinny GEMMs. In high-throughput DP+EP deployments, tokens are distributed across expert-parallel ranks, yielding different N/K dimensions per expert. FlyDSL allows us to provide separate tuning configurations for each scenario to maximize MI355X utilization.
Triton blockscale GEMM tuning - alongside FlyDSL, the A8W8 blockscale GEMM path uses per-shape tuned configurations for MI355X (gfx950). Key shapes like (N=7168, K=16384) and (N=16384, K=1536) - matching DeepSeek-R1's expert dimensions - are tuned with optimized block sizes, warp counts, pipeline stages, and k-splitting parameters. Special-case tuning for ultra-small M values (≤8, ≤256) targets the small per-expert batches typical in EP decode.
How Specv2 enablement on AMD GPU accelerates decoding
DeepSeek supports Multi-Token Prediction (MTP) via the NEXTN speculative decoding algorithm, predicting 2 additional tokens per step. MTP creates a compounding effect with quantized communication: it increases the decode batch size by 3x (original + 2 speculative tokens), improving all-to-all bandwidth utilization at larger batch sizes, while FP4/FP8 quantization keeps per-token communication cost low despite the larger batches.
SGLang's Specv2 pipeline overlaps the draft and verify phases by running verification preparation on a separate GPU stream while the draft model executes. This hides scheduling overhead and is now the default path in SGLang. We enabled it on the ROCm™ software with AMD specific attention backends (AITER) for draft CUDA graph capture and a targeted stream synchronization fix that ensures correct draft-to-verify data handoff.
With our optimization, MTP on the MI355X GPU runs with full overlap scheduling, combining multi-token prediction throughput gains with hidden scheduling latency.
How CPU Streaming Overhead Is Optimized for High Throughput
Under high-concurrency PD disaggregation (e.g., 2,048 concurrent requests), the GPU pipeline is no longer the bottleneck - the decode-side CPU path becomes the limiter. We optimized the asyncio notification batching and SSE serialization hot path in SGLang's tokenizer manager and API layer, reducing CPU overhead without affecting inter-token latency.
Future Plan
The next frontier for distributed inference is shifting from chat-style workloads toward agentic applications - tools like Claude Code, Codex, and Cursor that drive deep multi-turn, tool-augmented conversations with long context windows (up to 1M tokens), extremely high KV cache reuse, and rapid-fire request bursts from parallel subagent spawning. InferenceX is developing an agentic coding benchmark to capture these patterns, moving toward a true end-to-end system benchmark. Our future optimizations on AMD Instinct™ MI355X GPUs will target this workload by leveraging more advanced asynchronous parallelism strategies such as DWDP (Disaggregated Wide Data Parallelism), as well as exploiting ROCm software specific capabilities like SDMA for fully asynchronous, zero-compute-overhead data movement - ultimately pushing disaggregated MoE serving to match the burst-traffic, cache-heavy demands of agentic inference at scale.
Beyond inference, SDMA's zero-compute-overhead communication capability is not limited to serving workloads. We are exploring the potential of extending SDMA to **training and reinforcement learning frameworks** such as Miles. Early validation in the DeepSpeed training framework has already demonstrated **~10% performance gains** [8], suggesting that dedicated DMA engines can meaningfully accelerate collective communication in large-scale distributed training as well.
Summary
This post demonstrates how AMD Instinct MI355X GPU with MoRI on SGLang achieves competitive TCO for large-scale DeepSeek disaggregated inference. At 129 tok/s/user interactivity, the MI355X GPU delivers inference at $0.173 per million tokens with 2,378 tok/s/GPU - 2.9% lower cost than Nvidia B200 TRT-LLM and 1.22x higher throughput per GPU than Nvidia B200 SGLang.
This result is driven by a full-stack optimization effort across compute, communication, and serving:
- MoRI quantized all-to-all - hybrid FP4/FP8 communication with adaptive kernel selection, reducing round-trip bandwidth by up to 2.56x
- MoRI-IO KV cache backend - lock-free inline transfer with high-concurrency RDMA, delivering ~10% higher throughput than Mooncake
- Two-Batch Overlap with SDMA - hiding communication latency behind compute using AMD's dedicated DMA engines
- AITER GEMM tuning + FlyDSL FusedMoE - platform-tuned compute kernels for both TP and DP+EP scenarios on MI355X
- Specv2 MTP on ROCm software - full overlap scheduling for multi-token prediction, increasing effective decode batch size by 3x
- CPU streaming optimization - asyncio batching and SSE fast path, unlocking +20% output throughput at 2,048 concurrency
Combined with the MI355X GPU's hardware cost advantage ($1.48/hr/GPU vs $1.95 for B200), these software optimizations translate competitive throughput into a TCO win.
The results are open-source and continuously validated via InferenceX. Together, these innovations define a practical, reproducible blueprint for cost-effective large-scale MoE inference on AMD platforms.
References
- SGLang: Fast Serving Framework for Large Language and Vision Models
- MoRI: Modular RDMA Interface for AMD GPUs
- AITER: AMD Instinct Tensor Engine Runtime
- InferenceX: Open-Source Continuous Inference Benchmark
- InferenceXv2: NVIDIA Blackwell Vs AMD vs Hopper | SemiAnalysis
- Practical, Fault-Robust Distributed Inference for DeepSeek on AMD MI300X
- DeepSeek-V3 Technical Report | DeepSeek-AI
- DeepSpeed SDMA Integration on AMD Instinct
Footnotes
Endnotes
System configuration for AMD Instinct™ MI355X benchmark:
- GPU: 8× AMD Instinct™ MI355X per node
- Host CPU: AMD EPYC™ processors
- Network: AMD AINIC (ionic) RDMA, 8 NICs per node
- Software: SGLang v0.5.10+, AITER, MoRI, ROCm 7.2
- Model: amd/DeepSeek-R1-0528-MXFP4-v2
- TCO estimates sourced from SemiAnalysis InferenceXv2 analysis. Hardware costs reflect hyperscaler pricing models.
- Performance results measured by SemiAnalysis InferenceX continuous benchmark platform. Benchmark methodology and raw data available at https://github.com/SemiAnalysisAI/InferenceX.
Disclaimers
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED "AS IS" WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.
Footnotes
Endnotes
System configuration for AMD Instinct™ MI355X benchmark:
- GPU: 8× AMD Instinct™ MI355X per node
- Host CPU: AMD EPYC™ processors
- Network: AMD AINIC (ionic) RDMA, 8 NICs per node
- Software: SGLang v0.5.10+, AITER, MoRI, ROCm 7.2
- Model: amd/DeepSeek-R1-0528-MXFP4-v2
- TCO estimates sourced from SemiAnalysis InferenceXv2 analysis. Hardware costs reflect hyperscaler pricing models.
- Performance results measured by SemiAnalysis InferenceX continuous benchmark platform. Benchmark methodology and raw data available at https://github.com/SemiAnalysisAI/InferenceX.
Disclaimers
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED "AS IS" WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.



Related Blogs
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026
-
Enabling Language-specific Reasoning in Multilingual Models with Reinforcement Learning — ROCm Blogs
Learn how to train multilingual reasoning models with reinforcement learning and extend context windows on AMD Instinct GPUs.
July 23, 2026
-
Agentic AI Workflows Simplified
Rocm.AI simplifies how developers build and serve with ROCm on AMD GPU’s
July 23, 2026
-
AMD Launches Helios™: The Highest Performing Rackscale AI Infrastructure Solution
AMD launches Helios, an open rack-scale AI platform connecting 72 AMD Instinct™ MI455X GPUs for frontier AI inference and training
July 23, 2026
-
Run Hugging Face Models
Launch Hugging Face models instantly with One-Click notebooks on AMD GPUs.
July 23, 2026
-
Agentic AI: AMD EPYC™ 9005 CPUs Wins Today, EPYC 9006, formerly code-named “Venice”, Takes It to a New Level
AMD EPYC 9006 Series Server CPUs deliver up to 256 cores, faster memory and I/O, and a strong foundation for enterprise AI workloads, helping advance your data center for the agentic era.
July 23, 2026
-
AI Networking Built for Scale
AMD AI networking unifies front-end, scale-up, and scale-out infrastructure to accelerate training, inference, and agentic AI.
July 23, 2026







