如何在本地运行万亿参数级大语言模型:AMD 锐龙 AI Max+ 集群构建指南
Feb 26, 2026

1.简介
本篇博文将详细介绍如何基于 AMD 锐龙 AI Max+ AI PC 平台搭建小规模分布式推理集群,并通过 llama.cpp RPC 运行万亿参数级大语言模型。
我们采用四节点 Framework Desktop 系统集群,演示先进的万亿参数 Kimi K2.5 开源模型的分布式本地推理功能。
Kimi K2.5 是由月之暗面 (Moonshot AI) 推出的前沿开源推理模型,定位为能够出色处理编码、长程推理及智能体式工作流程的一流开源模型。Kimi K2.5 非常擅长处理软件工程任务,同时属于原生多模态模型,除文本外,还可对图像和视频输入内容进行逻辑推理。
本文将介绍整个过程,从系统设置和驱动程序配置,到构建支持 ROCm 的 llama.cpp,再到最后编排四台计算机以实现多节点协同推理,就像让它们成为一台逻辑 AI 加速器一样。
2.设置详情
硬件: |
4 台 Framework Desktop - AMD 锐龙 AI Max+ 395 - 128GB |
AI 框架 |
AMD ROCm |
推理引擎: |
Llama.cpp RPC |
操作系统: |
Ubuntu 24.04.3 LTS |
模型: |
|
网络互连 |
5Gbps 以太网 |
3.技术设置
每个锐龙 AI Max+ 系统均需按照以下步骤完成配置。
3a. 通过修改 TTM 扩展 VRAM 分配
注意:
在 BIOS 中将 iGPU Memory Size 设置为 512MB,然后再继续
对于 Framework Desktop 锐龙 AI Max+ 395 128GB 配置,在每个节点的系统 BIOS 中可设置为专用显存 (VRAM) 的最大内存量为 96GB,相当于四个节点总共有 384GB。
但是,在 Linux 中,我们可以使用转换表管理器 (Translation Table Manager, TTM) 内核参数,将每个节点的最大 VRAM 分配增加到 120GB,即四个节点总共 480GB。要配置内核参数并重启系统,可在终端中输入以下命令:
sudo nano /etc/default/grub
查找以下列内容开头的行:
GRUB_CMDLINE_LINUX_DEFAULT=
在引号内附加以下参数:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash ttm.pages_limit=30720000 amdgpu.gttsize=120000"
保存并退出(依次按 Ctrl+O、Enter、Ctrl+X)。
sudo update-grub
sudo reboot
注意:
TTM 限值以 4KB 页为单位进行表示。该值的计算方式为:
([size in GB] * 1024 * 1024) / 4.096
以 120GB 为例:
(120 * 1024 * 1024) / 4.096 = 30720000
系统重启后,可以验证 AMD GPU 驱动程序是否已正确配置为 120GB 显存分配:
$ sudo dmesg | grep "amdgpu.*memory"
[drm] amdgpu: 512M of VRAM memory ready
[drm] amdgpu: 120000M of GTT memory ready.
3b.选项 1:推荐设置 (Lemonade SDK)
为了充分简化设置过程,建议使用预构建的 Lemonade SDK 二进制文件。
Lemonade SDK 项目提供带有 AMD ROCm 7 加速功能的 llama.cpp 每日构建版,面向采用 gfx1151(Strix Halo/锐龙 AI Max+ 395)以及其他最新 Radeon 架构的 GPU。
要安装预构建的 Lemonade SDK 二进制文件,请前往最新版本发布页面:
https://github.com/lemonade-sdk/llamacpp-rocm/releases/latest/
从发布资源中,下载与您所用平台和目标 GPU 相匹配的压缩包:
-
llama-bxxxx-ubuntu-rocm-gfx1151-x64.zip
下载后,解压压缩包并准备二进制文件:
unzip llama-bxxxx-ubuntu-rocm-gfx1151-x64.zip
cd llama-bxxxx-ubuntu-rocm-gfx1151-x64
chmod +x llama-cli llama-server rpc-server
此目录现在包含支持 ROCm 的 llama-cli、llama-server 和 rpc-server 构建版本,这些版本已针对锐龙 AI Max+ 系统进行预编译。
为确保 llama.cpp 已正确配置为使用 Radeon GPU,可以执行 llama-cli 二进制文件
$ ./llama-cli --list-devices
ggml_cuda_init: found 1 ROCm devices:
Device 0: AMD Radeon Graphics, gfx1151 (0x1151), VMM: no, Wave Size: 32
Available devices:
ggml_backend_cuda_get_available_uma_memory: final available_memory_kb: 127697544
ROCm0: AMD Radeon Graphics (120000 MiB, 124704 MiB free)
为每个节点准备好 llama.cpp 后,即可继续执行步骤 4. 推理配置方案,以配置 RPC 端点并在整个集群中启动 Kimi K2.5。
3c. 选项 2:手动设置(源代码构建)
1.如何安装 ROCm 7.0.2
开始之前,应确认内核版本是否符合 ROCm 系统要求。
如需获取更细致的安装说明,请参阅 Linux 上的 ROCm 详细安装概述。
对于 Ubuntu 24.04.3,ROCm 7.0.2 安装方式如下所示:
ROCm 安装
wget https://repo.radeon.com/amdgpu-install/7.0.2/ubuntu/noble/amdgpu-install_7.0.2.70002-1_all.deb
sudo apt install ./amdgpu-install_7.0.2.70002-1_all.deb
sudo apt update
sudo apt install python3-setuptools python3-wheel
sudo usermod -a -G render,video $LOGNAME # Add the current user to the render and video groups
sudo apt install rocm
export PATH=$PATH:/opt/rocm-7.0.2/bin
export LD_LIBRARY_PATH=/opt/rocm-7.0.2/lib
前提条件:
Git
Cmake
可以通过 git 克隆并进入 llama.cpp 代码库,如下所示:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
要为锐龙 AI Max 395+ 系统构建 llama.cpp,我们将使用以下构建命令:
cmake -B rocm -DGGML_HIP=ON -DGGML_RPC=ON -DGGML_HIP_ROCWMMA_FATTN=ON -DAMDGPU_TARGETS="gfx1151"
cmake --build rocm --config Release -j$(nproc)
注意:
-DGGML_HIP=ON允许在 llama.cpp 中使用 ROCm 软件栈-DGGML_RPC=ON启用用于分布式推理的通信协议 RPC-DGGML_HIP_ROCWMMA_FATTN=ON启用 rocWMMA 库以增强 AMD GPU 上的 Flash Attention 性能-DAMDGPU_TARGETS="gfx1151"将锐龙 AI Max 395+ (Radeon 8060S GPU) 指定为构建目标- 如需详细了解参数用法,请参阅 llama.cpp build 文档
为确保 llama.cpp 已成功构建并正确配置为使用 Radeon GPU,我们可以访问构建的二进制文件目录并执行 llama-cli 二进制文件
cd rocm/bin
$ ./llama-cli --list-devices
ggml_cuda_init: found 1 ROCm devices:
Device 0: AMD Radeon Graphics, gfx1151 (0x1151), VMM: no, Wave Size: 32
Available devices:
ggml_backend_cuda_get_available_uma_memory: final available_memory_kb: 127697544
ROCm0: AMD Radeon Graphics (120000 MiB, 124704 MiB free)
为每个节点准备好 llama.cpp 后,即可继续执行步骤 4. 推理配置方案,以配置 RPC 端点并在整个集群中启动 Kimi K2.5。
4.推理配置方案
4a. 如何在每台计算机上启动 RPC 端点
为了让四台计算机形成一个协同工作的统一推理运行时环境,我们使用 llama.cpp RPC 引擎。RPC (Remote Procedure Call) 是指远程过程调用,允许单个 llama.cpp 实例将模型的不同部分通过网络分载到远程工作节点,同时保持统一的执行图。
在实践中,这意味着有一台计算机充当主控制器。它负责词元化处理、调度和编排。其余计算机则运行轻量级 RPC 服务器,向主控制器开放自身的本地 GPU 显存和计算资源。从模型视角来看,层可以放置在任何可用设备上,无论是本地还是远程设备。
这种设计与锐龙 AI Max+ 系统非常契合。每个节点都贡献大量 GPU 可寻址显存和计算资源,而 llama.cpp 在加载模型时会将模型分片到各个节点。加载模型后,推理任务就像是在单个超大加速器上运行一样,而 RPC 在后台处理张量传输和同步。
网络拓扑的简化示意图如下所示:
图像缩放

在远程主机(计算机 2-4)上创建端点
要创建主机(计算机 1)可以连接到的 RPC 端点,必须先在计算机 2-4 上执行 rpc-server 二进制文件,如下所示:
./rpc-server -p 50053 -c --host 0.0.0.0
注意:
-p是将为计算机设置的端口,用于让计算机广播 RPC 服务器-c将允许使用本地缓存来存储大型张量,并避免在加载模型时通过网络重复传输--host是将为计算机设置的 IP 地址,用于让计算机广播 RPC 服务器- 如需详细了解参数用法,请参阅 llama.cpp rpc 文档
4b. 模型启动命令
启用远程 RPC 主机后,即可通过两个不同接口在主机(计算机 1)上开始运行 Kimi K2.5 大语言模型推理。
llama-cli
llama-cli 提供基于终端的轻量级接口,用于直接与模型交互。它非常适合基准测试、调试和底层实验,因为在这些场景中您需要对参数拥有完全控制权并获得即时反馈。
由于 llama-cli 完全在终端中运行,因此开销极小,并让您能轻松观察启动时间、提示处理行为和 token 生成性能。
要启动 llama-cli 并运行 Kimi K2.5,可以运行以下命令:
./llama-cli \
-m /path/to/Kimi-K2.5-UD-Q2_K_XL-00001-of-00008.gguf \
-c 32768 \
-fa on \
-ngl 999 \
--no-mmap \
--rpc <RPC_WORKER_1_IP>:50053,<RPC_WORKER_2_IP>:50053,<RPC_WORKER_3_IP>:50053
注意:
-m指定 gguf 模型文件路径;请将下载的 Kimi K2.5 00001-of-00008.gguf 文件的路径放在此处
-c指定上下文窗口大小,也即模型可以处理和生成的 token 数量;上下文窗口越大,占用的内存就越多-fa on将启用专门的 rocWMMA Flash Attention 以提高性能;有关详细结果,请参见步骤 5. 性能优化参数调优-ngl指定 GPU 层数,也即将存储在 VRAM 中的层数;可将此数值设置为 999,以始终确保模型完全分载到 Radeon 8060S GPU 上--no-mmap将禁用模型内存映射模式;当模型大小超过系统内存大小但不超过 VRAM 限值时,这将显著缩短模型加载时间--rpc允许输入设置的远程主机 IP 和端口,详情参见步骤 4a. 如何在每台计算机上启动 RPC 端点- 如需详细了解参数用法,请参阅 llama.cpp cli 文档
llama-server
llama-server 与 llama-cli 采用相同的推理引擎,但通过常驻服务器进程对外提供该引擎。它内置一个用于交互的集成式 Web UI,并提供一个与 OpenAI 兼容的 HTTP API,支持以编程方式进行访问。
这使得 llama-server 成为长时间运行部署、多用户访问以及与外部工具集成时的首选接口。内置 Web UI 可用于快速测试和演示,而 API 层可支持与聊天前端、智能体框架和工作流程自动化工具的集成。
要启动 llama-server 并运行 Kimi K2.5,可以运行以下命令:
./llama-server \
-m /path/to/Kimi-K2.5-UD-Q2_K_XL-00001-of-00008.gguf \
-c 32768 \
-fa on \
-ngl 999 \
--no-mmap \
--host 0.0.0.0 \
--port 8081 \
--rpc <RPC_WORKER_1_IP>:50053,<RPC_WORKER_2_IP>:50053,<RPC_WORKER_3_IP>:50053
注意:
-
-m指定 gguf 模型文件路径;请将下载的 Kimi K2.5 00001-of-00008.gguf 文件的路径放在此处 -
-c指定上下文窗口大小,也即模型可以处理和生成的 token 数量;上下文窗口越大,占用的内存就越多 -
-fa on将启用专门的 rocWMMA Flash Attention 以提高性能;有关详细结果,请参见步骤 5. 性能优化参数调优 -ngl指定 GPU 层数,也即将存储在 VRAM 中的层数;可将此数值设置为 999,以始终确保模型完全分载到 Radeon 8060S GPU 上--no-mmap将禁用模型内存映射模式;当模型大小超过系统内存大小但不超过 VRAM 限值时,这将显著缩短模型加载时间-
--host是将为主机设置的 IP 地址,用于让主机广播 llama-server 端点 --port是将为计算机设置的端口,用于让计算机广播 llama-server 端点--rpc允许输入设置的远程主机 IP 和端口,详情参见步骤 4a. 如何在每台计算机上启动 RPC 端点- 如需详细了解参数用法,请参阅 llama.cpp server 文档
现在,我们可以通过导航到主机的 IP 和指定的端口,来访问 llama-server 实例的 Web UI 界面。
4c. 如何通过 OpenAI API 与第三方应用集成
llama-server 实例对外提供与 OpenAI 兼容的 API,这意味着它采用与 OpenAI 聊天补全 (Chat Completions) 和嵌入 (Embeddings) 端点相同的请求与响应模式。这使得原本为 OpenAI API 设计的现有应用只需少量修改或无需修改即可正常使用。
从客户端的角度来看,唯一需要更改的是基础 URL (Base URL) 和 API 密钥 (API key)。基础 URL 需设置为您的 llama-server 实例的地址,而 API 密钥可以是任意值,因为身份验证在本地处理。
若要在诸如 Open WebUI 等与 OpenAI 兼容的第三方程序中使用 llama-server 实例,只需将应用指向您的本地服务器,而不是 OpenAI 端点。
在实践中,这意味着:
Base URL:设置为 llama-server 地址(例如,http://<HOST_IP>:8081)API key:设置为任何占位符字符串(例如none),因为身份验证在本地处理
5.性能优化参数调优
Flash Attention
注意力 (Attention) 机制是 Kimi K2.5 等大语言模型能够遵循指令、跟踪上下文并在长提示中“不偏离主题”的核心原因之一。在推理阶段,注意力计算也是整个前向传播过程中开销最大的运算环节之一。
随着上下文长度增加,注意力计算开销也会随之上升,原因是模型需要参考不断扩大的历史 token 序列。在实际应用中,上下文长度增加会加剧算力与内存压力,注意力计算也极易成为解码阶段吞吐性能的瓶颈。
Flash Attention 是 Transformer 注意力运算的优化实现方案,旨在破解上述性能瓶颈。Flash Attention 不是在内存中生成大型中间矩阵并反复读写这些矩阵,而是以更融合、分块式的方式执行计算,从而显著减少内存流量。
在锐龙 AI Max+ 300 系列上,我们通过 llama.cpp 中由 rocWMMA 支持的内核路径启用 Flash Attention。rocWMMA 是一个 ROCm API,支持从底层直接调用 AMD GPU 矩阵运算,从而使注意力机制的核心数学运算在 AMD Radeon 8060S RDNA 3.5 计算单元上高效运行。
要启用 rocWMMA Flash Attention,可以先使用 -DGGML_HIP_ROCWMMA_FATTN=ON 构建参数,并在模型启动时添加 -fa on 参数(详情参见步骤 4b. 模型启动命令)
衡量性能影响
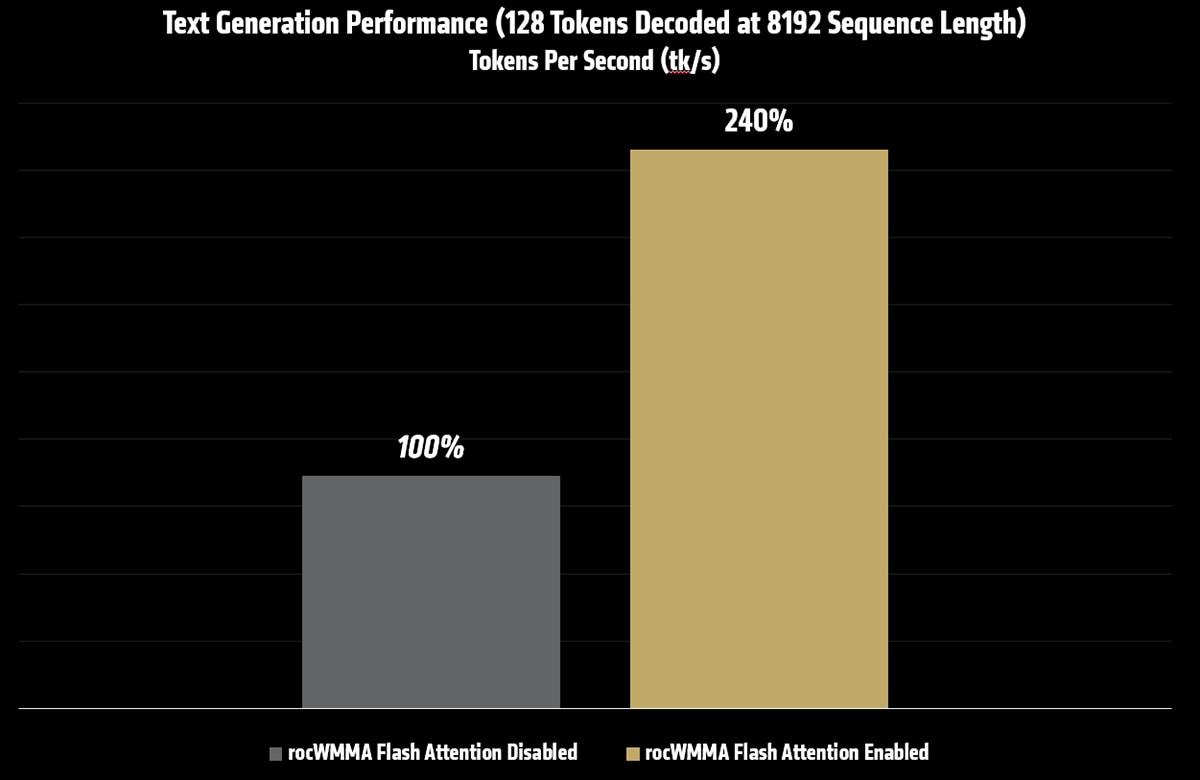
下表显示了在启用和未启用 Flash Attention 的情况下,Kimi K2.5 在序列长度为 8192 时的文本生成吞吐量。
测试 |
文本生成 – 禁用 Flash Attention |
文本生成 – 启用 Flash Attention |
解码 128 个 token |
8.81tk/s |
9.45tk/s |
解码 128 个 token,序列长度为 8192 |
3.46tk/s |
8.30tk/s |
批量 (Batch) 与微批量 (UBatch)
提示处理时间通常称为首 token 延迟,是大语言模型最显著的性能特征之一。在生成第一个 token 之前,模型必须遍历每一层以完成处理整个输入提示。对于较长的上下文,该阶段是延迟的主要来源。
在 llama.cpp 中,提示处理性能主要由两个密切相关的参数控制:
n_batch 和 n_ubatch
概括而言:
n_batch是指推理引擎在 API 级别每一步可处理的最大 token 数量。n_ubatch(micro-batch,微批量)是指在设备上每一步实际处理的最大 token 数量。
衡量性能影响
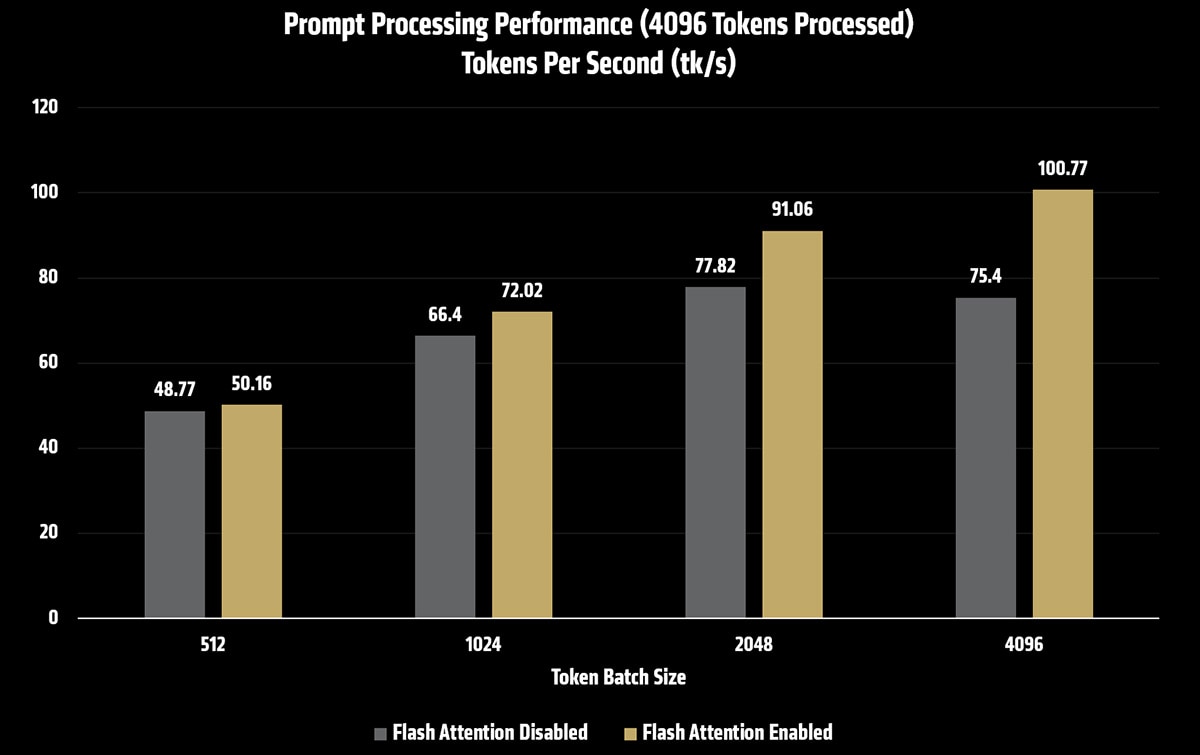
下表显示了在启用和未启用 Flash Attention 的情况下,Kimi K2.5 在不同批量和微批量大小配置下的提示处理吞吐量。
批量与微批量大小 |
提示处理性能 (tk/s) – 禁用 Flash Attention |
提示处理性能 (tk/s) – 启用 Flash Attention |
512 |
48.77 |
50.16 |
1024 |
66.40 |
72.02 |
2048 |
77.82 |
91.06 |
4096 |
75.40 |
100.77 |
提示长度(token 数量) |
首 token 延迟 (s) - 禁用 Flash Attention |
首 token 延迟 (s) - 启用 Flash Attention |
4096 |
53.7s |
39.7s |
8192 |
内存不足 (OOM) |
90.5s |
16384 |
内存不足 (OOM) |
239.1s |
注意:测试首 Token 延迟时,采用的参数为:n_batch=4096 and n_ubatch=4096
随着批量和微批量大小增加,提示处理吞吐量也随之提高。搭配 rocWMMA Flash Attention 机制后,性能增益会叠加放大,大幅缩短长上下文提示的首 token 延迟。
在这种配置下,优化 n_batch 和 n_ubatch 参数后,提示处理性能相比基准配置(禁用 FA,批量和微批量大小为 512)最高可实现 2 倍提升,让长上下文推理的响应速度与实用性大幅提升。
注意:增加 n_batch 和 n_ubatch 将提升模型上下文的内存占用
6.总结与结语
本文中的演示表明,大规模推理不再局限于传统服务器级 GPU 或纯云部署。通过利用 AMD 锐龙 AI Max+ 平台的统一内存架构和 llama.cpp RPC 的灵活性,我们能够组建一个小型 AI PC 集群作为一个协同工作的统一推理系统,在一万亿参数的先进模型上高效进行推理。
展望未来,本演示所体现的核心原则并不局限于四节点锐龙 AI Max+ 集群;您可以根据模型的 VRAM 需求与工作负载需求,灵活增减集群节点数量。
使用像万亿参数级 Kimi K2.5 这样的开源大语言模型进行分布式本地推理,既能产出高质量的 AI 推理结果,又无需按 token 持续付费,同时所有数据与计算均可自主掌控,满足云端服务难以保障的隐私与合规要求。
对于许多原型设计、研究及企业应用场景而言,这类四节点锐龙 AI Max+ 自托管集群提供了经济高效、保护隐私的解决方案,可与付费云服务形成补充,帮助团队探索万亿参数模型、完成分布式推理战略的原型设计,以及在扩展到更大规模的云或生产环境之前验证工作负载。


Related Blogs
-
-
Gartner 将 AMD 评为 Gartner® AI 供应商竞争中的当前领先企业
Gartner 在一份报告中将 AMD 称为企业级 AI 服务器 CPU 领域的当前领跑者。
June 24, 2026
-
-
-
AMD 推出全新锐龙 AI Halo 开发者平台和锐龙 AI Max PRO 400 系列处理器,助力新一代智能体计算机发展
AMD 推出面向本地智能体 AI PC 和工作站的锐龙 AI Halo 和锐龙 AI Max PRO 400 系列。
May 20, 2026
-
AMD携手联想百应打造x86全栈算力+端云混合+智能体服务
联想百应AI Max+395系列旨在给开发者、中小企业的AI本地化智能体提供 “隐私可控的创作自由和使用自由”。
April 28, 2026
-
跳出概念炒作:将 AI PC 的潜在价值转化为切实商业收益
AI PC 正在重塑企业战略。了解 AMD 计算连续体如何帮助首席信息官跳出概念炒作,通过部署 AI 创造切实商业价值。
April 23, 2026
-
基于 AMD 锐龙 AI Max+ 处理器和 Radeon GPU,在本地高效运行 Hermes Agent
本指南演示了如何在配备 AMD 锐龙 AI Max+ 处理器和 Radeon GPU 的 Windows 系统上,使用 WSL2 和 LM Studio 运行 Hermes Agent。
April 21, 2026







