推理性能的多重维度
Mar 19, 2026

推理性能涉及多个维度
在 GTC 2026 大会上,NVIDIA 基于 SemiAnalysis“InferenceX”的基准测试数据展示了推理性能表现,结果显示 GB300 NVL72(FP4、MTP)的单位功耗 token 处理量是上一代 Hopper (FP8) 的 50 倍,每 token 成本是上一代的 1/35。事实上,在相同运行模式下,AMD Instinct MI355X GPU 的表现旗鼓相当或更胜一筹。
什么是 InferenceX? SemiAnalysis InferenceX 是一个独立的推理基准测试框架,可在各种配置下对 NVIDIA 和 AMD GPU 进行测试。该框架全面覆盖并发级别、输入和输出序列长度、数据类型、推测性解码设置、服务框架以及部署拓扑等参数的各种不同组合。这种覆盖广度正是关键所在,因为没有任何一种运行配置能够全面反映实际性能情况。
在该框架所覆盖的大量配置中,一些配置与常见的实际部署场景相匹配。一些配置则适合长上下文处理或批处理作业等特殊工作负载。还有一些配置在技术上可行,但在实际中并未被采用。
推理性能取决于一系列参数(这些参数会显著影响性能结果):
- 并发度和批量大小
- 数据类型:INT4、FP4、FP8、BF16、FP16
- 推测解码和多 Token 预测 (MTP) 设置
- 框架:开源 SGLang、vLLM 或专有的闭源框架 (TRT-LLM)
- 服务拓扑:单节点与多节点解耦、机架级
- 以及其他参数,如输入和输出序列长度 (ISL/OSL)
以上每一个参数都是软件优化的关键点。供应商可以找到一种具有显著优势的配置。真正的问题不在于哪种配置能让 GPU 表现最佳,而是针对给定的工作负载和交互性目标,每 token 的成本是多少。
解析 GTC 基准测试
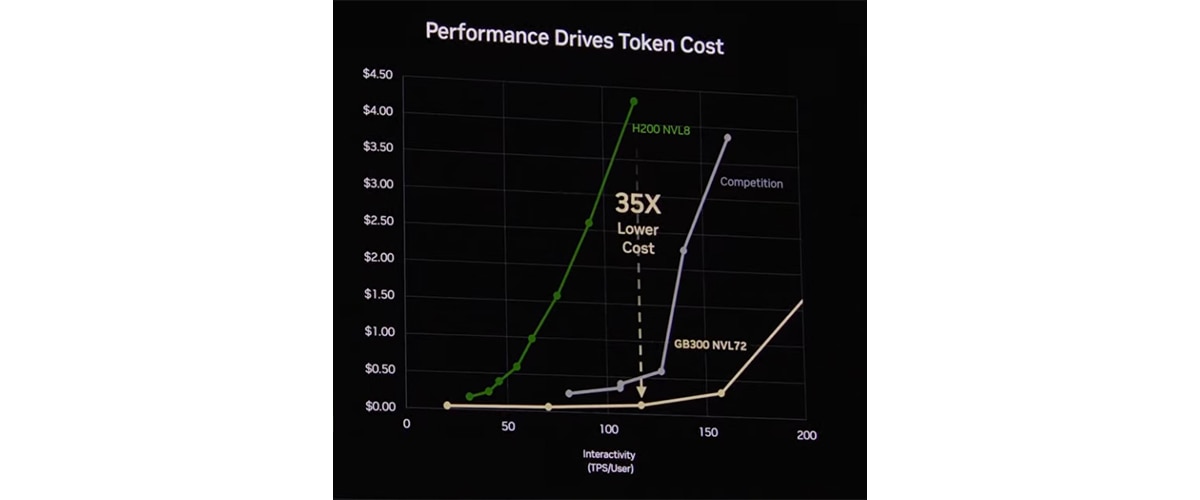
在 GTC 大会上,NVIDIA 的每百万 token 成本基准测试采用了 FP4、MTP=3 以及 3 月 7 日的 DeepSeek 1k/1k 数据集:这些选择均有利于 NVIDIA 的测试结果。
MTP 确实是一种吞吐量优化技术,但其带来的性能提升会因数据集和配置的不同而有所差异。NVIDIA 的基准测试采用 MTP=3;而 AMD 当前默认采用 MTP=1。数据类型同样重要:此次测试数据点展示的是 FP4,但 FP8 也是常见的生产环境选择。
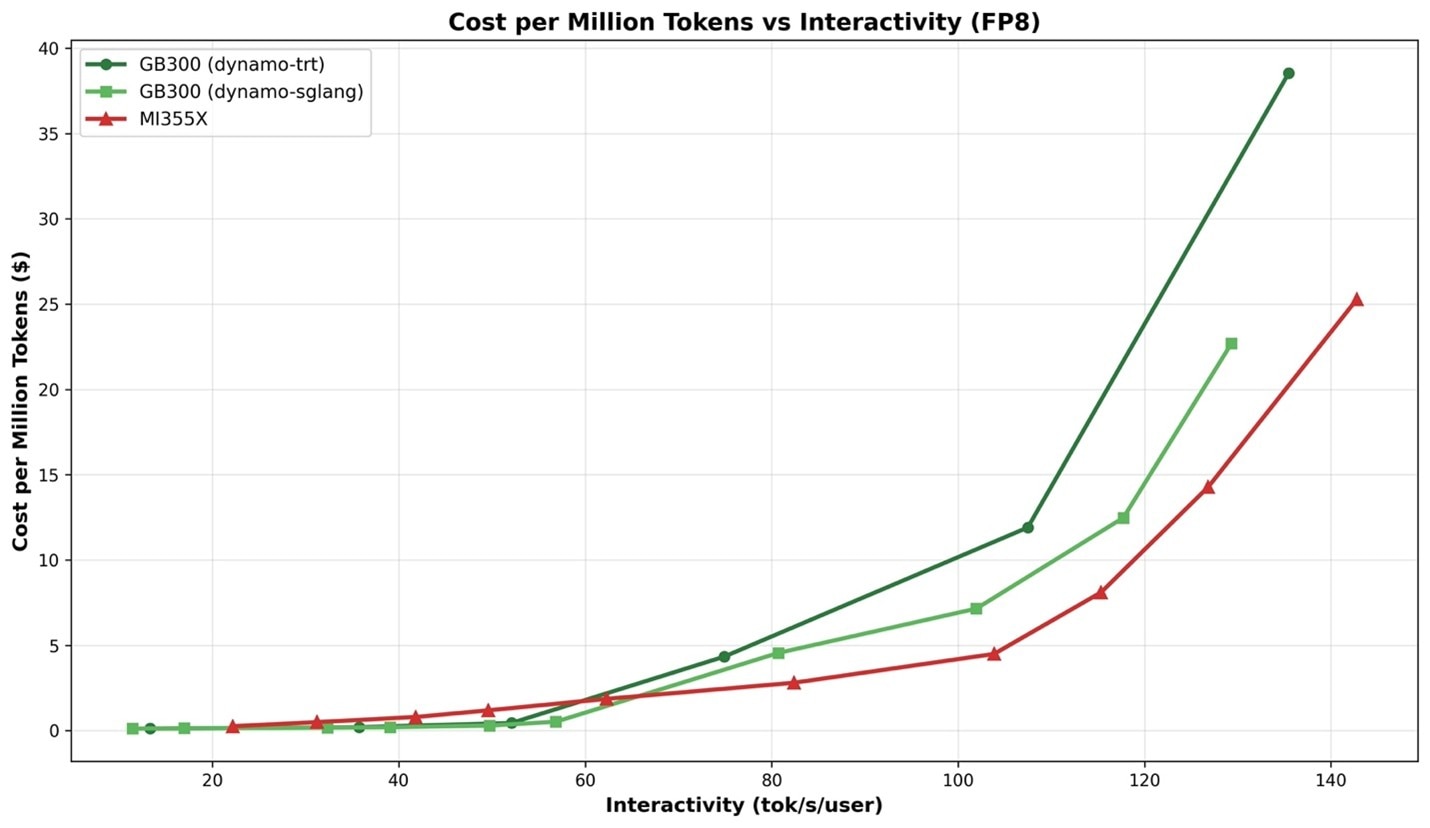
在同等条件下(即关闭 MTP 且均采用 FP8),当并发度较高(每用户每秒 60 个以上 token)时,MI355X 的每 token 成本优势比较明显(图 1)。
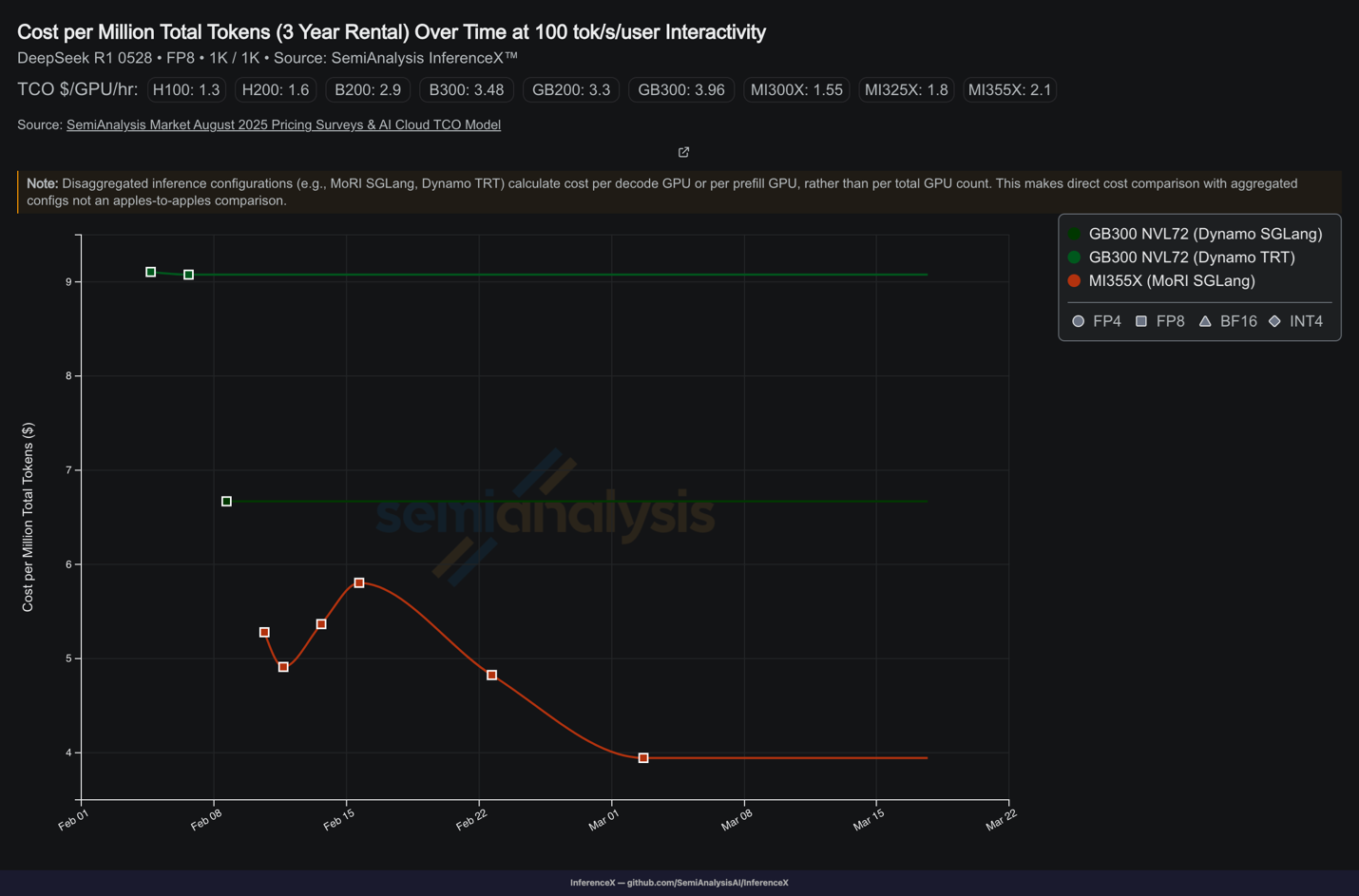
展示软件优化对每 token 成本的影响:自 2 月以来,MI355X GPU 的每 token 成本已大幅下降(图 2)。
即将推出的技术创新
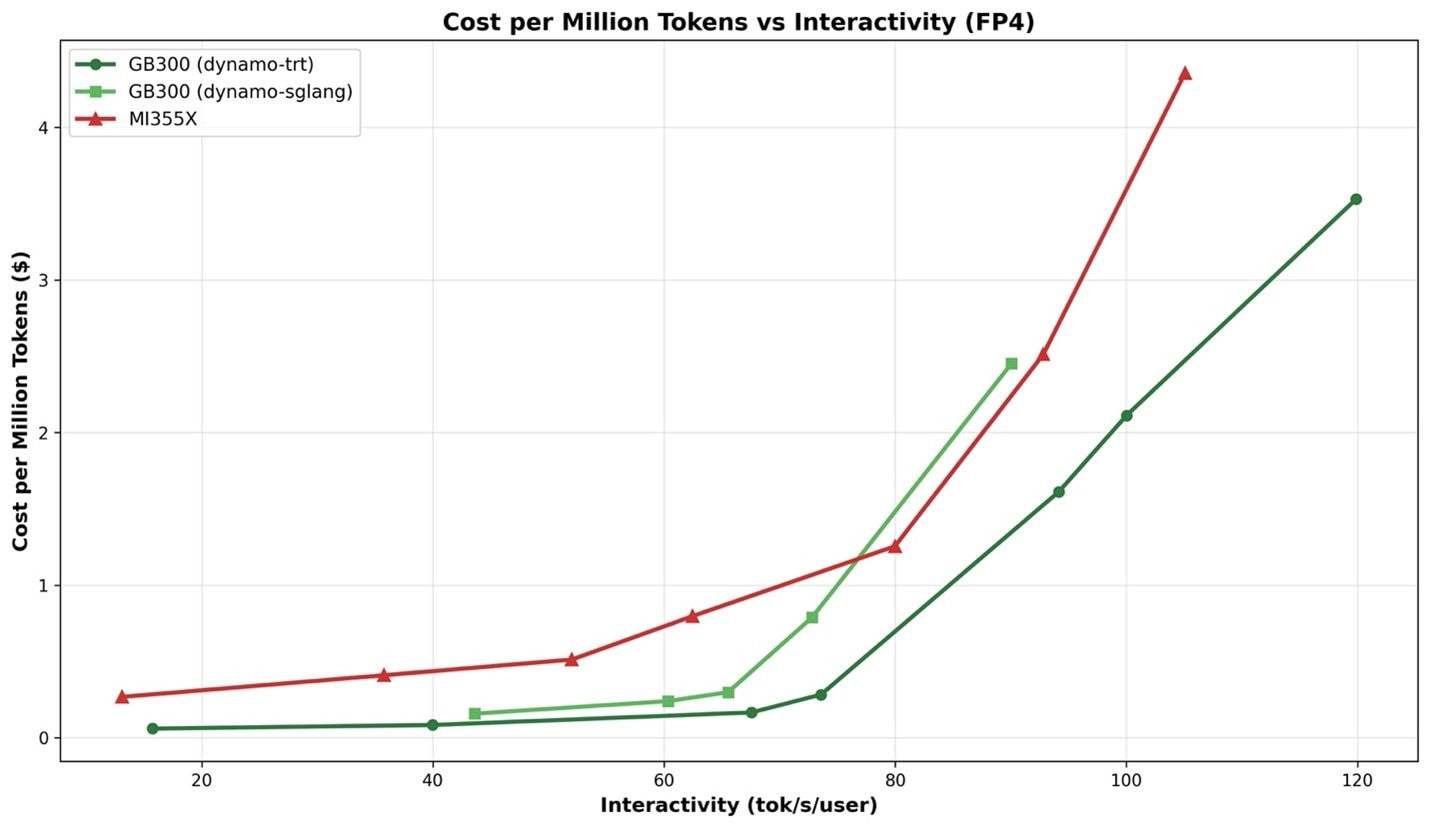
AMD 将于 3 月底面向基于 AMD Instinct MI350 系列的分布式推理推出经过优化的 FP4 方案。 在分布式推理领域,AMD 最初将重心放在 FP8 上。而在 FP4 精度下,即使未经优化,在每用户每秒 80 个以上 token 的情况下,MI355X SGLang 的表现也已出色(图 3);预计 3 月底将推出进一步的优化方案。
机架级解决方案将于下半年随 AMD Helios (MI450) 推出。具备更高纵向扩展能力的机架级架构,在低交互场景中能切实创造价值,因为在此类场景中更大的批量大小和更高的 GPU 并行度至关重要。AMD 机架级解决方案“Helios”搭载 MI450 GPU,正是针对这类场景而设计,计划于 2026 年下半年推出。
总结
选择哪种平台进行推理,应取决于具体的工作负载特征和需求。正确的评估方式是,按照您实际所需的上下文长度、延迟目标和并发度,在两个平台上分别运行自己的模型。这正是 AMD 准备进行的基准测试。
请联系您的 AMD 客户团队,安排并行评估。


Related Blogs
-
AMD Advancing AI 2026 前瞻:精彩内容抢先看
抢先了解“AMD Advancing AI 2026”大会,探索塑造 AI 未来的核心议题、会议环节及创新技术。了解行业领军者如何携手合作,共同探讨实际应用场景以及在企业范围内规模化部署 AI 的策略。
July 14, 2026
-
-
Gartner 将 AMD 评为 Gartner® AI 供应商竞争中的当前领先企业
Gartner 在一份报告中将 AMD 称为企业级 AI 服务器 CPU 领域的当前领跑者。
June 24, 2026
-
-
-
AMD 推出全新锐龙 AI Halo 开发者平台和锐龙 AI Max PRO 400 系列处理器,助力新一代智能体计算机发展
AMD 推出面向本地智能体 AI PC 和工作站的锐龙 AI Halo 和锐龙 AI Max PRO 400 系列。
May 20, 2026
-
AMD携手联想百应打造x86全栈算力+端云混合+智能体服务
联想百应AI Max+395系列旨在给开发者、中小企业的AI本地化智能体提供 “隐私可控的创作自由和使用自由”。
April 28, 2026
-
跳出概念炒作:将 AI PC 的潜在价值转化为切实商业收益
AI PC 正在重塑企业战略。了解 AMD 计算连续体如何帮助首席信息官跳出概念炒作,通过部署 AI 创造切实商业价值。
April 23, 2026







