The Many Aspects of Inference Performance
Mar 18, 2026

Inference Performance is Multifaceted
At GTC 2026, NVIDIA showed an inference performance comparison based on benchmarking data from SemiAnalysis "InferenceX", showing GB300 NVL72 (FP4, MTP) delivering 50X higher tokens-per-watt and 35X lower cost-per-token than last-generation Hopper (FP8) and shows the "competition" in-between. In fact, when comparing the same operating modes, AMD Instinct™ MI355X GPU often delivers comparable or better results than GB300 NVL72.
What is InferenceX? SemiAnalysis InferenceX is an independent inference benchmarking framework that tests NVIDIA and AMD GPUs across a very broad universe of configurations. It sweeps across combinations of concurrency levels, input and output sequence lengths, data types, speculative decode settings, serving frameworks, and deployment topologies. This breadth is the point; no single operating point can tell the whole story.
Within this universe, some configurations match the most common real-world deployments. Others suit specialized workloads like long-context processing or batch jobs. Some are technically valid, but not used in practice.
Inference performance depends on a wide set of parameters that shift the outcome materially:
- Concurrency and batch size
- Data type: INT4, FP4, FP8, BF16, FP16
- Speculative decode and Multi-Token Prediction (MTP) settings
- Framework: open-source SGLang, vLLM, or proprietary closed source (TRT-LLM)
- Serving topology: single node vs. multi-node disaggregated, rack-scale
- and other parameters such as input and output sequence length (ISL/OSL)
Every one of these is a software optimization point. Vendors can find a configuration that shows a large advantage. The right question is not which configuration makes a GPU look best, but rather what the cost per token is for a given workload and interactivity target.
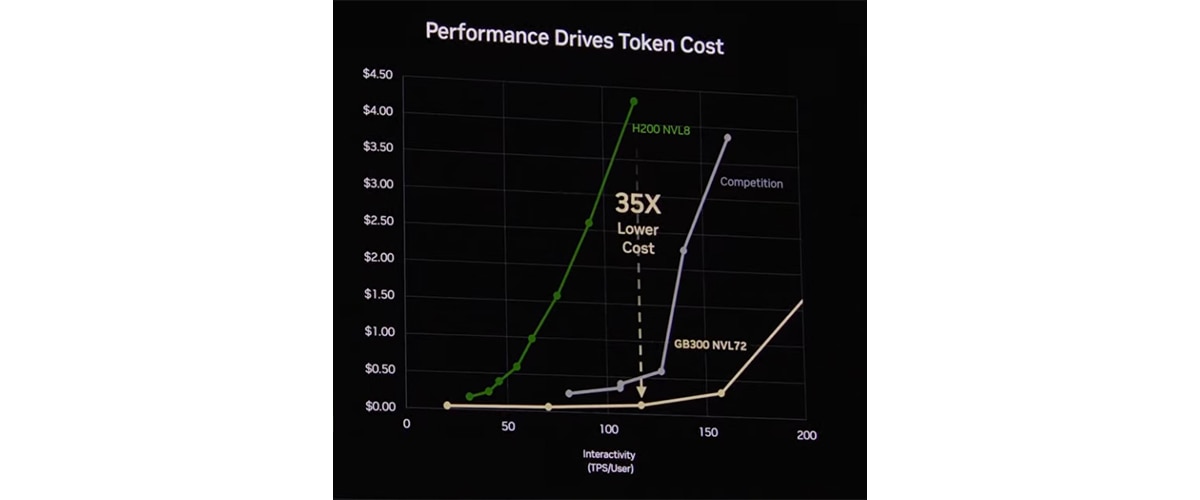
Unpacking the GTC benchmark
At GTC, NVIDIA's cost-per-million-token benchmark used FP4, MTP=3, and March 7 data on DeepSeek 1k/1k: each choice favors NVIDIA's result.
MTP is a genuine throughput technique, but gains vary by dataset and configuration. NVIDIA's benchmark used MTP=3; AMD defaults to MTP=1 at this time. Data type also matters: this data point showed FP4 but FP8 is a also common production choice.
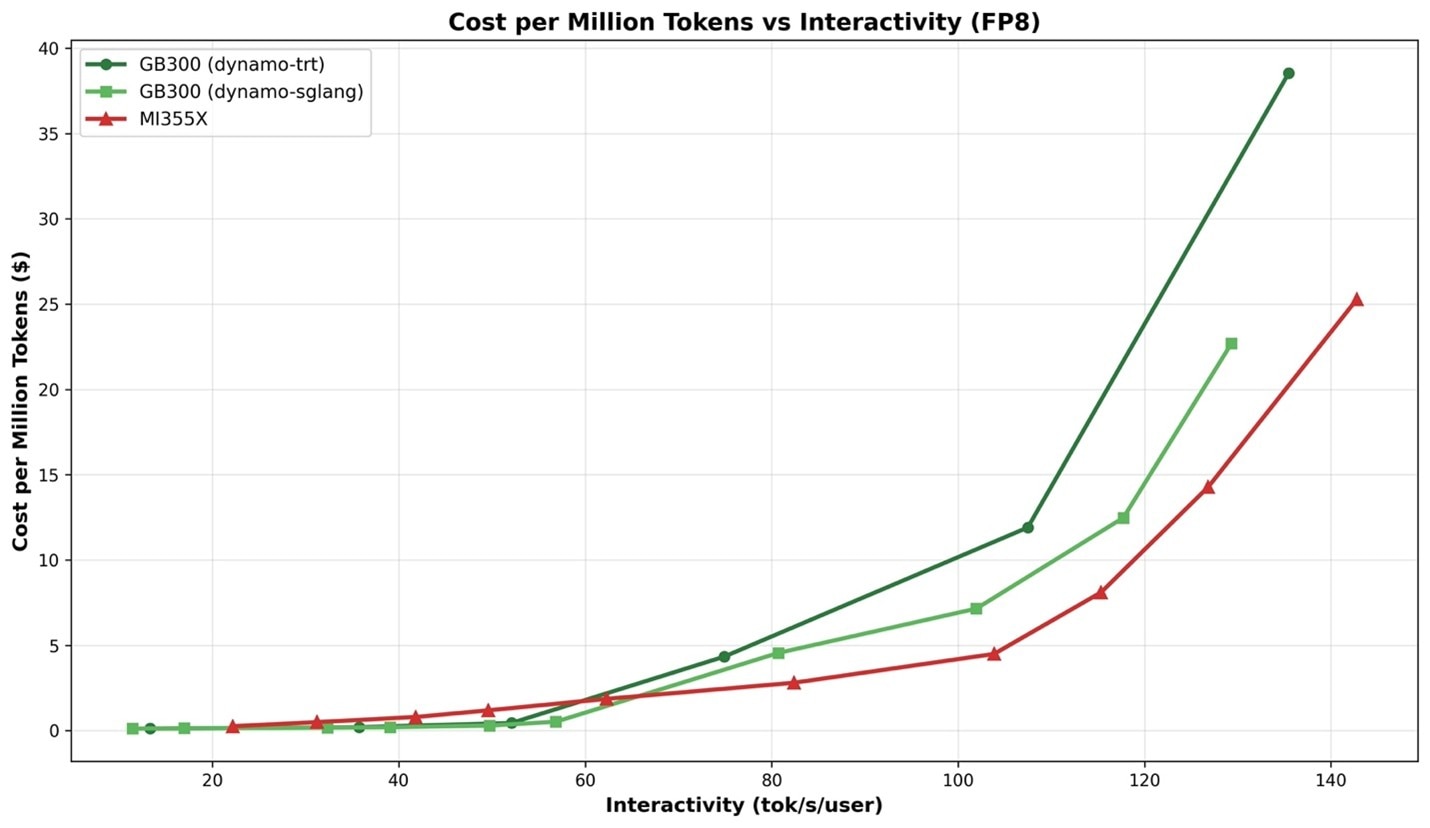
On equal footing, MTP off and FP8 for both, MI355X cost-per-token is materially lower than GB300 NVL72 at high concurrency, 60+ TPS/user (Figure 1).
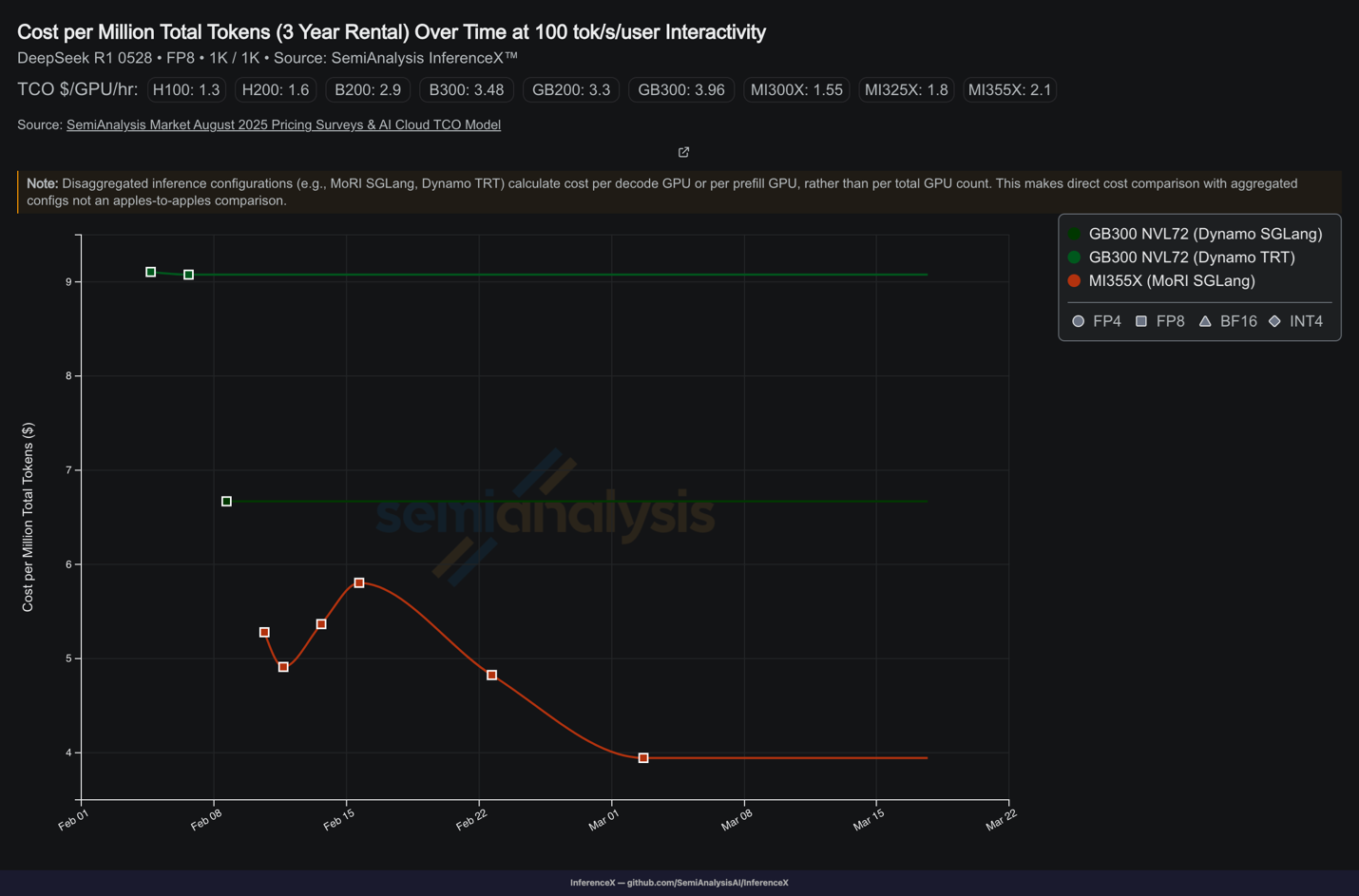
To illustrate the impact of software optimization on cost per token: since February, MI355X GPU cost per token has dropped significantly, while GB300 NVL72 remains higher and unchanged (Figure 2).
Upcoming Innovations
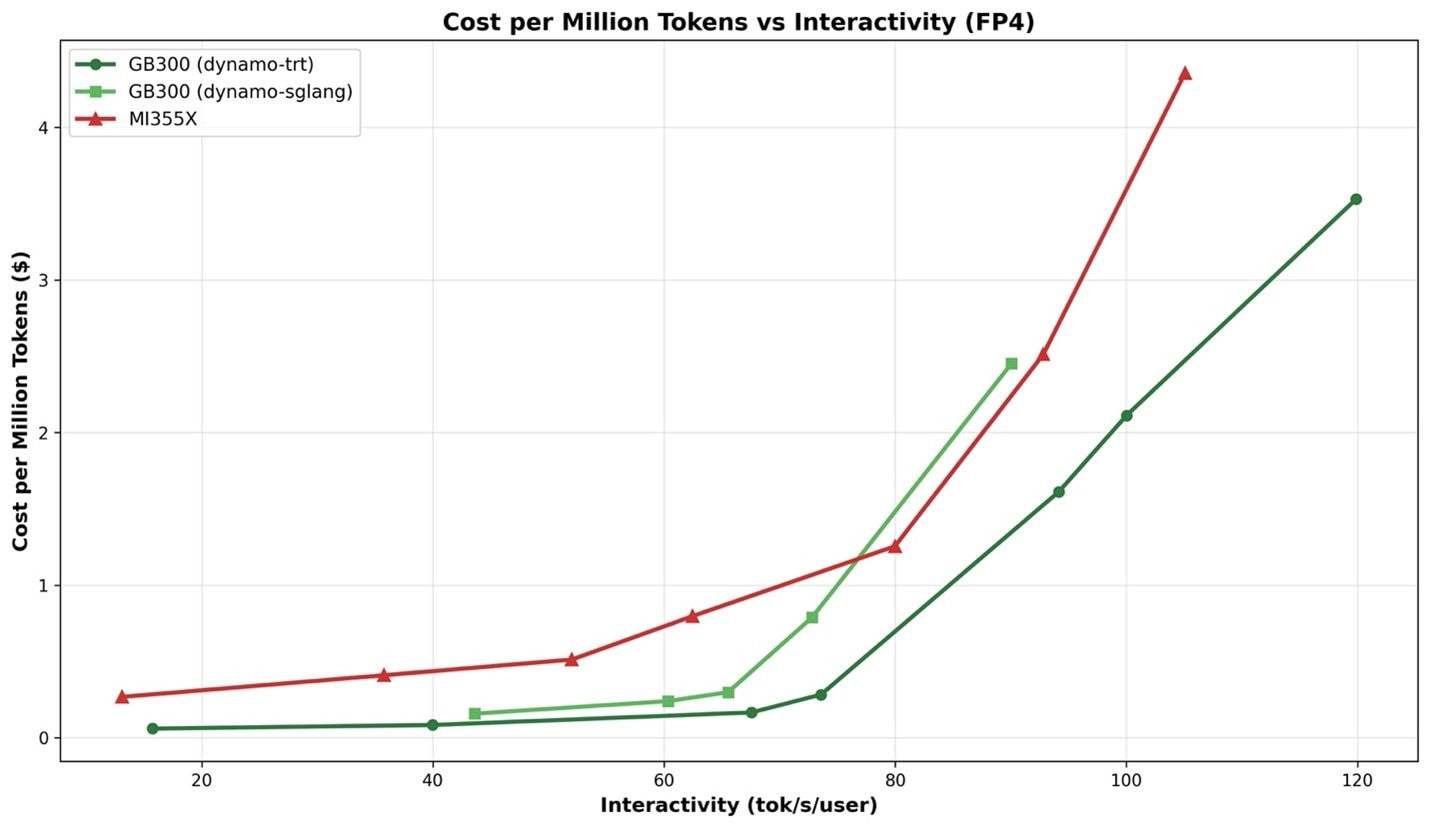
Optimized FP4 for Distributed inference on AMD Instinct MI350 Series is coming end of March. The initial focus of AMD for Distributed Inference was on FP8. However, for FP4, MI355X SGLang is already ahead of GB300 SGLang at 80+ TPS/user on unoptimized FP4 (Figure 3), with further optimizations expected by the end of March.
Rack scale is coming in 2H with AMD Helios (MI450). Rack-scale architectures with higher scale-up domains provide real value at low interactivity, where larger batch sizes and higher GPU parallelism help most. rack-scale answer from AMD is “Helios” with MI450 GPUs, planned for 2H 2026, targeting exactly that regime.
The bottom line
What you run for inference depends on your workload characteristics and requirements. The right evaluation is to run your model, with your context length, latency target, and concurrency, on both platforms. That is the benchmark AMD is ready to run.
Contact your AMD account team to schedule a side-by-side evaluation.


Related Blogs
-
Running Cloud Agents? Your Most Important Upgrade Could be an AMD Zen 5 CPU
As agents begin navigating applications, coordinating tools and completing real work, the local CPU is becoming a critical part of the AI execution pipeline.
July 16, 2026
-
From Vector Search to Agentic RAG: Building an Enterprise Research Analyst with hipVS — ROCm Blogs
Learn how to build an agentic RAG research assistant using hipVS GPU-accelerated vector search on AMD Instinct GPUs, with multi-query decomposition, parallel retrieval, and cited sources synthesis.
July 14, 2026
-
When a Faster Kernel Doesn’t Speed Up Serving: Profiling FP8 KV Cache on AMD Instinct MI308X — ROCm Blogs
Learn how a 34% faster FP8 KV cache kernel delivered 0% E2E speedup, and how profiling attribution exposed the hidden dtype-cast cost on MI308X.
July 14, 2026
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026
-
Local Image and Video Generation on AMD Ryzen™ AI Max+ Processor (Windows) — ROCm Blogs
Run ComfyUI natively on Windows on AMD Ryzen AI Max+ with ROCm 7.2.1—SDXL, Flux, and video workflows on the Radeon 8060S, no WSL.
July 13, 2026
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026
-
GEAK Agent-Driven Optimization of the DeepSeekV4 MLA Kernel — ROCm Blogs
GEAK Agent accelerates DeepSeekV4 MLA kernel optimization with Triton and delivers SGLang E2E gains on AMD GPUs.
July 12, 2026
-
ZenDNN 6.0 FP16 Inference and MoE Acceleration
ZenDNN 6.0 takes the next step: FP16 functional support for AMD’s 6th Gen EPYC™ processors, MoE model optimization, and the vLLM compatibility window.
July 10, 2026







