ZenDNN 5.2:在 AMD EPYC(霄龙)CPU 上加速 vLLM V1 引擎和推荐系统推理
Mar 13, 2026

AMD 作出了一个明确的判断:AI 推理的未来将是灵活、高效的,并且越来越多地依赖于你机架中已有的 CPU。的确,在 AI 领域,GPU 一直占据主导地位。这也不难理解——GPU 的地位没有动摇。它们强大的并行处理能力仍然是处理高吞吐量 LLM 推理等繁重工作负载的金标准。然而,CPU 不再仅仅是旁观者;它本身也正在被用作 LLM 推理的高性能引擎。
随着最新发布的 ZenDNN 5.2,AMD 正在颠覆人们对 x86 架构在 AI 时代处理能力的预期。这并非简单的性能提升,而是相比以往版本高达 200% 的惊人飞跃,使 AMD EPYC(霄龙)处理器上处理 AI 工作负载的效率翻了一番。
为什么这很重要:从智能体到边缘 AI
这不仅仅关乎原始数据;它关乎开启计算领域的新篇章:
- 智能体 AI:要高效运行自主智能体,您需要低延迟、可靠的计算资源。针对 vLLM 集成和 INT4 量化的优化,使得复杂的 LLM 智能体能够以即插即用的便捷方式直接在 CPU 基础设施上运行。
- 离线和边缘应用场景:隐私和网络连接并非始终都能得到保障。AMD 通过突破仅权重量化 (WOQ) 的极限,使大型模型能够在本地高效运行,而无需依赖专用数据中心 GPU。
- 利用现有硬件加速 AI 推理:在大多数标准服务器部署中,CPU 仍然是技术栈的支柱,并且始终存在;利用它进行 AI 可以降低总体拥有成本 (TCO)。
到底发生了什么?
5.2 版本标志着架构的重大转变。AMD 已从传统库迁移到新的 ZenDNNL,利用低开销 API (LOA) 简化了 MatMul 和 Softmax 等算子内核。
本次更新的主要亮点:
- 无缝 vLLM V1 集成:全新 vLLM-ZenTorch 插件支持零代码更改加速,使高吞吐量推理比以往任何时候都更容易实现。
- 量化支持:实验性支持 INT4 for LLM 以及专门用于推荐系统的 UINT4/W8A8 量化 (DLRM-v2)。
- BFloat16 和图形优化:增强的 EPYC(霄龙)处理器专用内核和高级模式识别确保 CPU 的每个周期都得到充分利用,从而实现最大的 AI 性能。
- 现代化技术栈:完全支持 TensorFlow 2.20,PyTorch 2.10.0,以及 Python 3.13。
- Llama.cpp 的 ZenDNN 后端:此项集成是在 5.2 开发周期中设计的。它使 Llama.cpp 用户能够利用 ZenDNN 的低延迟内核在 AMD EPYC(霄龙)处理器上实现卓越的执行性能。

ZenDNN 为 vLLM V1 引擎加速
利用 CPU 进行 LLM 推理正迅速从一种小众方案发展成为一种成熟且经济高效的生产负载策略。在 ZenDNN 5.2 中,我们升级了插件,以支持最先进的 vLLM V1 引擎。团队秉持“零代码更改”的理念,为 vLLM 0.12.0 至 0.15.1 版本提供真正的即插即用体验,同时在底层实现了大幅加速。在我们对非精选模型进行的测试中,vLLM 与 ZenTorch 的组合性能比在标准 CPU 配置上运行原生 vLLM 提升了高达 239%。
除了软件栈的改进之外,我们还通过优化硬件的数据处理方式,进一步提升了性能。通过使用 numactl 部署多个 vLLM 实例,并交错访问每个实例的内存,我们有效地最大化了 DRAM 内存带宽。这种方法不仅确保 CPU 的处理速度更快,而且能够更高效地接收数据,从而显著提升了总解码吞吐量。
部署:最大化吞吐量
高效扩展:虽然现代 AMD EPYC(霄龙)处理器拥有惊人的核心密度,但简单地在插槽的全部 128 个核心上运行单个庞大的 vLLM 实例通常会导致收益递减。当我们使用 0-127 核心全盘测试原生 vLLM 时,如此庞大的计算架构和内存争用带来了极高的管理复杂性,导致性能出乎意料地低。
为了解决这个问题,我们实施了一种更高效的扩展策略:将工作负载拆分为两个独立的 vLLM 实例,每个实例分配 64 个核心。通过“交错”使用这些核心并将它们绑定到各自的本地内存池,我们大幅提高了总吞吐量。这种方法有效地利用了可用的 DRAM 带宽并降低了同步开销,从而使硬件能够发挥其最大潜力。正如我们最新的基准测试所示,这种多实例配置是释放高核心数 CPU 架构真正性能的关键。
您可以使用 numactl 将特定的 vLLM 实例绑定到专用的 CPU 核心及其本地内存池。以下简要介绍如何实现上述内存交错策略:
- 安装插件:只需将 vLLM-ZenTorch 插件放到您现有的 vLLM 环境中即可。
- 绑定实例:使用 numactl 将特定的 vLLM 实例绑定到特定的 CPU 核心。
- 交错内存:以非顺序方式访问物理内核,以确保内存带宽分布在所有可用的 DRAM 通道上,防止解码阶段出现瓶颈。
例如,以下命令启动一个绑定到偶数编号核心(0、2、4……直到 126)的单个 vLLM 实例,并将其内存分配限制在插槽 0(内存池 0):
numactl --physcpubind=$(seq -s, 0 2 127) --membind=0 \
vllm bench throughput --model meta-llama/Llama-3.1-8B-Instruct\
--random-input-len 128 --random-output-len 128 \
--num-prompts 1024 --max-num-seqs 128
通过这种模式,您可以启动映射到剩余核心和插槽的额外实例来扩展部署。这种“隔离式”方法可防止不同的 AI 工作负载争用相同的缓存或内存带宽,从而有效地最大化整个服务器的总解码吞吐量。
此外,为了提高 CPU 推理性能,我们启用了冻结功能,方法是设置环境变量 export TORCHINDUCTOR_FREEZING=1。该环境变量从 vLLM 版本 0.12.0 开始提供。更多信息请参见此处。简而言之,冻结功能允许 runtime 将模型参数视为不可变参数。这通常可以减少内存占用并增强缓存局部性,从而使模型数据更紧凑,更有可能保留在 AMD EPYC 处理器的 L3 缓存中。
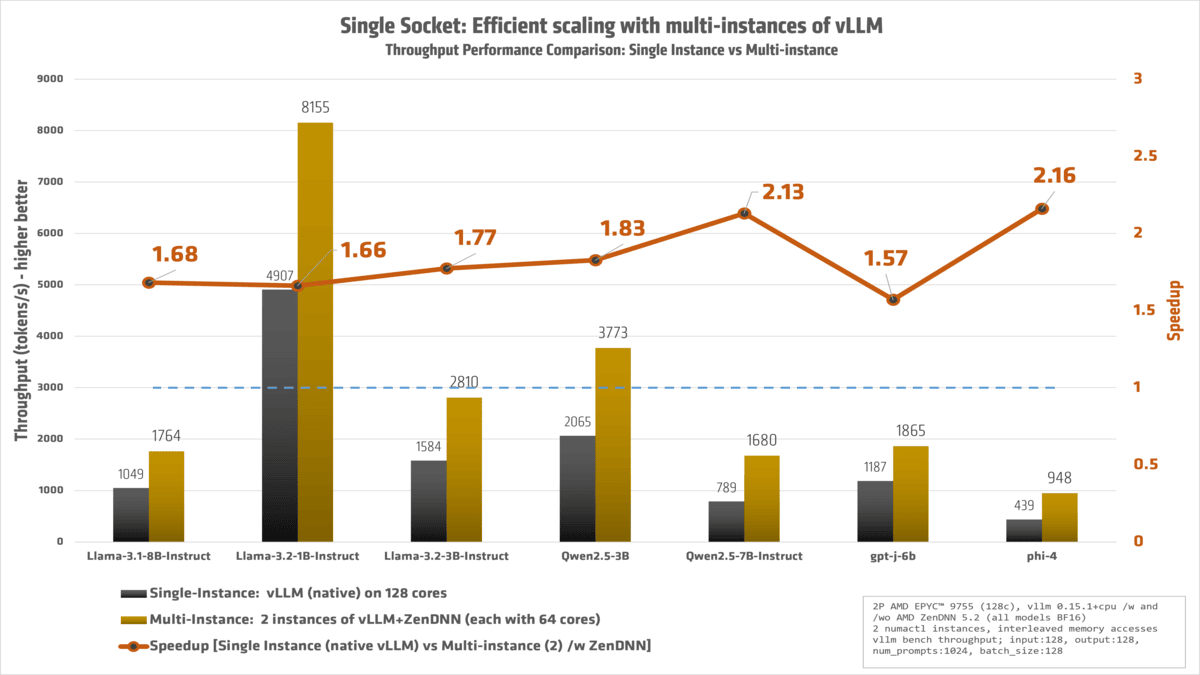
我们采用的是双路系统。还可以有更大提升吗?当然!
我们利用一台双路 AMD EPYC(霄龙)高性能处理器,将机器的性能发挥到极致,确保每个核心都投入使用并以最高效率运行。
结果:
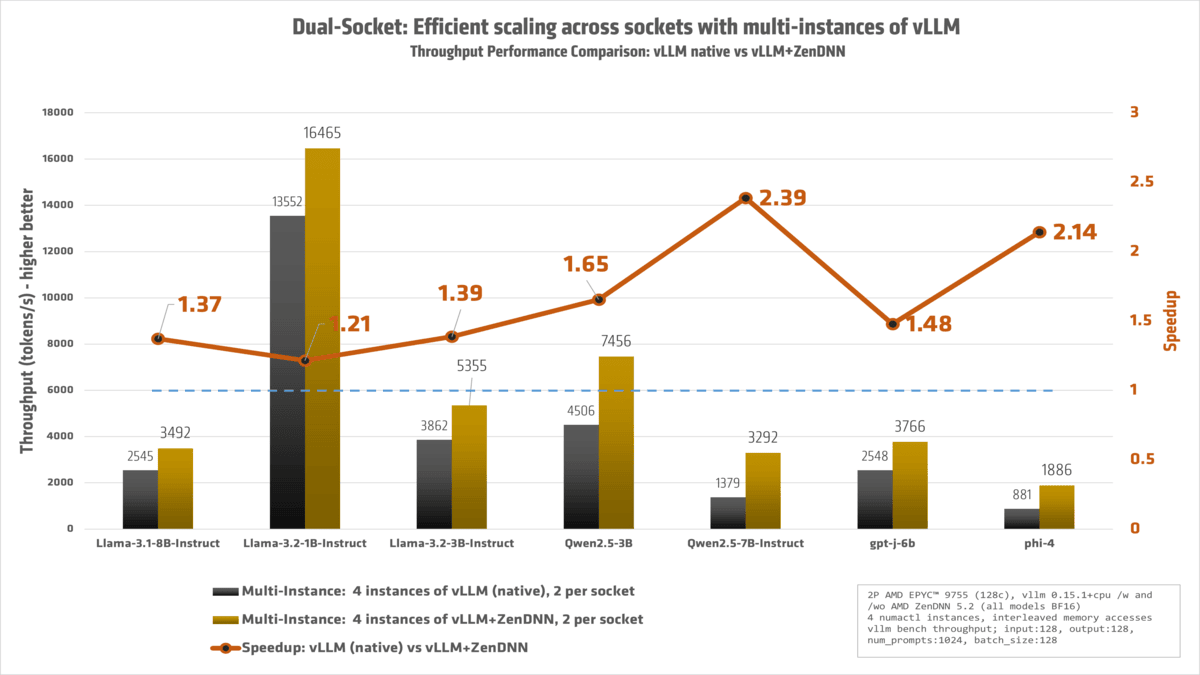
结论:赋能柔性 AI 的未来
ZenDNN 5.2 的发布标志着我们对 AI 基础设施的思考方式发生了重大转变。虽然 GPU 仍然是处理大规模并行工作负载的黄金标准,但 CPU 已经从辅助角色发展成为能够独立承担重任的高性能引擎。ZenDNN 5.2 实现了超过 200% 的性能提升,并与 vLLM 和 Llama.cpp 等行业巨头实现了无缝的插件和集成。我们赋予开发者在最合适的地方运行复杂 AI 的自由 —— 无论是在高密度数据中心还是在边缘。
我们对生态系统的持续承诺
正如我们在 5.1 版本中所做的那样,我们的战略仍然植根于开源社区。我们将继续把我们的优化成果整合到 PyTorch 核心代码 以及 TensorFlow 代码库,确保我们围绕 ZenDNNL 低开销 API (LOA) 和可插拔设备所做的工作,让所有开发者,无论使用何种技术栈,都能受益。通过增强这些框架的原生功能,我们不仅提升了 AMD 硬件的性能,也改善了整个 AI 生态系统。
适用于所有机架的实际应用效果
我们所做的技术革新 —— 从实验性的 INT4 量化到 NUMA 感知内存交错等设计“巧思”—— 都直接转化为切实的商业价值。现在,您可以使用现有的 AMD EPYC(霄龙)硬件,为智能体 AI 和离线应用场景实现更高的吞吐量和更低的延迟。
行动起来:
我们鼓励您亲身体验这些优势。下载更新后的 AMD ZenDNN PyTorch 插件( zentorch) 和 AMD ZenDNN TensorFlow 插件 ( zentf)(可通过 pip 安装或从GitHub下载),探索我们在 GitHub 上的最新优化,并与我们一道,共同开创 x86 架构的性能新极限。
立即体验:
- 下载:访问我们的 GitHub 代码库
- 文档:阅读完整的 ZenDNN 5.2 发行说明
我们非常希望了解您的性能提升情况——请在我们的 Github 页面上提交问题或发起讨论!
附注
ZD-059 :结果基于 AMD 内部测试,截至 2026 年 3 月 10 日。
工作负载配置:原生 vllm 1.15.1+cpu, zenTorch 5.2, PyTorch 2.10.0+cpu,输入:128,输出:128,num_prompts:1024,batch_size:128。 2 个 NUMA 节点,Python 3.13,BFloat16,每秒令牌数,singlevllm :原生 vLLM 单实例,singlezendnn:单实例 ZenDNN 5.2,multivllm:原生 vLLM 多实例,multizendnn:ZenDNN 5.2 多实例
单路 AMD EPYC 9755 参考系统,共 128 个核心,1536GB (12x128GB) DDR5-6400,BIOS RVOT1004C,Ubuntu 22.04 LTS 5.15.0-170-generic,SMT=off, Mitigations=off,Power Determinism = Power
结果:
模型 singlevllm singlezendnn multivllm multizendnn multizendnnvssinglevllm
Llama-3.1-8B-Instruct 1048.853 1205.183 1403.56 1764.403 1.682
Llama-3.2-1B-Instruct 4907.087 4460.023 7043.177 8154.797 1.662
Llama-3.2-3B-Instruct 1584.057 1837.58 2306.23 2809.573 1.774
Mixtral-8x7B-Instruct-v0.1 399.493 396.66 435.693 442.237 1.107
Qwen2.5-3B 2065.21 2102.967 2699.733 3772.503 1.827
Qwen2.5-7B-Instruct 788.613 1209.833 891.033 1680.34 2.131
gpt-j-6b 1187.337 1420.78 1489.067 1864.55 1.57
phi-4 438.83 704.983 564.103 948.24 2.161
Llama-3.3-70B-Instruct 152.83 185.22 169.483 219.403 1.436
结果可能因系统配置、软件版本和 BIOS 设置等因素而异。
ZD-060:结果基于 AMD 内部测试,截至 2026 年 3 月 10 日。
工作负载配置:原生 vllm 1.15.1+cpu,zenTorch 5.2,PyTorch 2.10.0+cpu,输入:128,输出:128,num_prompts: 1024,batch_size: 128,2 个 NUMA 节点,Python 3.13,BFloat16,每秒令牌数,basevllm:原生 vLLM 单实例,multivllm :原生vLLM多实例,multizendnn:ZenDNN 5.2 多实例
双路 AMD EPYC 9755 参考系统,共 256 个核心,3072GB (24x128GB) DDR5-6400 内存,BIOS 版本 RVOT1004C,Ubuntu 22.04 LTS 5.15.0-170-generic,SMT=off, Mitigations=off,Power Determinism = Power
结果:
模型 basevllm multivllm multizendnn multizendnnvsmultivllm
Llama-3.1-8B-Instruct 946 2544.557 3491.72 1.372
Llama-3.2-1B-Instruct 4881.917 13551.903 16464.78 1.215
Llama-3.2-3B-Instruct 1692.653 3862.13 5354.943 1.387
Mixtral-8x7B-Instruct-v0.1 543.367 881.453 892.83 1.013
Qwen2.5-3B 1998.08 4505.807 7455.653 1.655
Qwen2.5-7B-Instruct 838.42 1379.403 3291.7132.386
gpt-j-6b 1171.3 2547.607 3766.347 1.478
phi-4 420.453 880.917 1885.667 2.141
Llama-3.3-70B-Instruct 142.1 324.223 438.723 1.353
结果可能因系统配置、软件版本和 BIOS 设置等因素而异。
附注
ZD-059 :结果基于 AMD 内部测试,截至 2026 年 3 月 10 日。
工作负载配置:原生 vllm 1.15.1+cpu, zenTorch 5.2, PyTorch 2.10.0+cpu,输入:128,输出:128,num_prompts:1024,batch_size:128。 2 个 NUMA 节点,Python 3.13,BFloat16,每秒令牌数,singlevllm :原生 vLLM 单实例,singlezendnn:单实例 ZenDNN 5.2,multivllm:原生 vLLM 多实例,multizendnn:ZenDNN 5.2 多实例
单路 AMD EPYC 9755 参考系统,共 128 个核心,1536GB (12x128GB) DDR5-6400,BIOS RVOT1004C,Ubuntu 22.04 LTS 5.15.0-170-generic,SMT=off, Mitigations=off,Power Determinism = Power
结果:
模型 singlevllm singlezendnn multivllm multizendnn multizendnnvssinglevllm
Llama-3.1-8B-Instruct 1048.853 1205.183 1403.56 1764.403 1.682
Llama-3.2-1B-Instruct 4907.087 4460.023 7043.177 8154.797 1.662
Llama-3.2-3B-Instruct 1584.057 1837.58 2306.23 2809.573 1.774
Mixtral-8x7B-Instruct-v0.1 399.493 396.66 435.693 442.237 1.107
Qwen2.5-3B 2065.21 2102.967 2699.733 3772.503 1.827
Qwen2.5-7B-Instruct 788.613 1209.833 891.033 1680.34 2.131
gpt-j-6b 1187.337 1420.78 1489.067 1864.55 1.57
phi-4 438.83 704.983 564.103 948.24 2.161
Llama-3.3-70B-Instruct 152.83 185.22 169.483 219.403 1.436
结果可能因系统配置、软件版本和 BIOS 设置等因素而异。
ZD-060:结果基于 AMD 内部测试,截至 2026 年 3 月 10 日。
工作负载配置:原生 vllm 1.15.1+cpu,zenTorch 5.2,PyTorch 2.10.0+cpu,输入:128,输出:128,num_prompts: 1024,batch_size: 128,2 个 NUMA 节点,Python 3.13,BFloat16,每秒令牌数,basevllm:原生 vLLM 单实例,multivllm :原生vLLM多实例,multizendnn:ZenDNN 5.2 多实例
双路 AMD EPYC 9755 参考系统,共 256 个核心,3072GB (24x128GB) DDR5-6400 内存,BIOS 版本 RVOT1004C,Ubuntu 22.04 LTS 5.15.0-170-generic,SMT=off, Mitigations=off,Power Determinism = Power
结果:
模型 basevllm multivllm multizendnn multizendnnvsmultivllm
Llama-3.1-8B-Instruct 946 2544.557 3491.72 1.372
Llama-3.2-1B-Instruct 4881.917 13551.903 16464.78 1.215
Llama-3.2-3B-Instruct 1692.653 3862.13 5354.943 1.387
Mixtral-8x7B-Instruct-v0.1 543.367 881.453 892.83 1.013
Qwen2.5-3B 1998.08 4505.807 7455.653 1.655
Qwen2.5-7B-Instruct 838.42 1379.403 3291.7132.386
gpt-j-6b 1171.3 2547.607 3766.347 1.478
phi-4 420.453 880.917 1885.667 2.141
Llama-3.3-70B-Instruct 142.1 324.223 438.723 1.353
结果可能因系统配置、软件版本和 BIOS 设置等因素而异。

Contributors


Related Blogs
-
-
Gartner 将 AMD 评为 Gartner® AI 供应商竞争中的当前领先企业
Gartner 在一份报告中将 AMD 称为企业级 AI 服务器 CPU 领域的当前领跑者。
June 24, 2026
-
-
-
AMD 推出全新锐龙 AI Halo 开发者平台和锐龙 AI Max PRO 400 系列处理器,助力新一代智能体计算机发展
AMD 推出面向本地智能体 AI PC 和工作站的锐龙 AI Halo 和锐龙 AI Max PRO 400 系列。
May 20, 2026
-
AMD携手联想百应打造x86全栈算力+端云混合+智能体服务
联想百应AI Max+395系列旨在给开发者、中小企业的AI本地化智能体提供 “隐私可控的创作自由和使用自由”。
April 28, 2026
-
跳出概念炒作:将 AI PC 的潜在价值转化为切实商业收益
AI PC 正在重塑企业战略。了解 AMD 计算连续体如何帮助首席信息官跳出概念炒作,通过部署 AI 创造切实商业价值。
April 23, 2026
-
基于 AMD 锐龙 AI Max+ 处理器和 Radeon GPU,在本地高效运行 Hermes Agent
本指南演示了如何在配备 AMD 锐龙 AI Max+ 处理器和 Radeon GPU 的 Windows 系统上,使用 WSL2 和 LM Studio 运行 Hermes Agent。
April 21, 2026







