Advancing AI Performance on AMD EPYC CPUs: ZenDNN 5.1 Brings New Optimizations
Aug 19, 2025

We’re excited to announce the latest updates to our ZenDNN library and ZenTorch and ZenTF Plugins, bringing significant performance boosts and new features for AI workloads on AMD EPYC™ CPUs. This release continues our commitment to optimizing inference performance for both Large Language Models (LLMs) and Recommender Systems, with a host of enhancements designed to push the boundaries of efficiency and speed.
Key Highlights of the Release
This update focuses on three key areas: framework compatibility, performance optimizations, and ecosystem contributions.
Enhanced Framework Compatibility & New Plugins
We have updated our plugins to maintain full compatibility with the latest AI frameworks, including PyTorch 2.7 and TensorFlow 2.19. This seamless integration allows you to leverage our optimizations with the newest versions of your preferred frameworks.
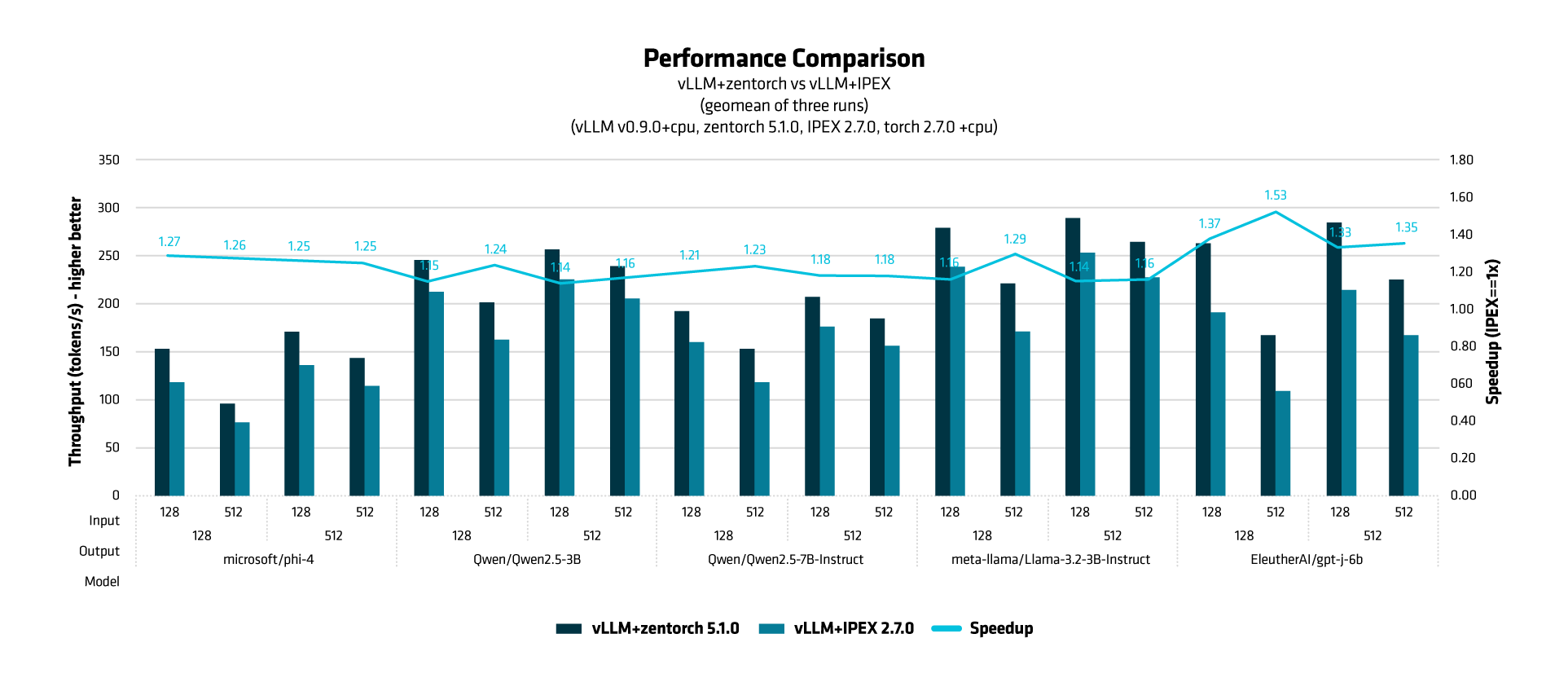
A major addition in this release is the new vLLM + ZenTorch plugin. vLLM is a popular, high-performance library for LLM inference, and our new plugin delivers a significant performance uplift of up to 24% over vLLM-IPEX across a variety of popular models, including Llama 3.2, Phi-4, and Qwen-2.5. The plugin is designed for seamless, “plug-and-play” integration; once installed, it automatically replaces vLLM's default attention mechanism with our highly optimized ZenTorch PagedAttention kernel, requiring zero code changes from the user.
As a preview, across all tested LLMs and input/output combinations vLLM + ZenTorch 5.1.0 consistently achieves higher throughput and is significantly faster than vLLM + IPEX 2.7.0 for CPU-based inference:
We’ve also extended our support for TensorFlow-Java by enabling the PluggableDevice feature, which is essential for our enTF plugin to function effectively. Our team contributed this work directly to the official TensorFlow-Java repository, strengthening the core capabilities of the framework and enabling developers to easily integrate custom hardware accelerators and plugins. Our early testing shows this integration has higher performance for models like DIEN and Wide & Deep compared to the native TensorFlow-Java implementation.
Deeper Performance Optimizations
This release introduces several new optimizations that operate at every level, from individual operator kernels to comprehensive graph fusions.
Recommender System (RecSys) Improvements: We have made significant strides in optimizing DLRMv2 and other RecSys models. New "out" variants of the EmbeddingBag operator now write directly to a shared output buffer, eliminating the need for a separate concatenation operation. We also introduced a new fusion that fuses concatenation after Bottom MLP and EmbeddingBag for the DLRMv2 model.
New Operator Fusions: We’ve added new operator fusions to accelerate common computational patterns found in deep learning models, particularly in RNN and attention layers. These fusions include:
- MatMul + BiasAdd + Tanh
- MatMul + BiasAdd + Sigmoid
These fusions reduce memory traffic and kernel launch overhead, leading to significant performance gains: up to 25% uplift for the DIEN BF16 model, as per internal tests.
Kernel and ZenDNN Enhancements: A new kernel for BF16/FP32 MatMul has been introduced to eliminate overheads in less compute-intensive operations. Additionally, we now support Ahead of Time (AOT) Reordering for MatMul kernels across various data types (INT8, BF16, and FP32), to further improve efficiency. We have also added support for MatMul(+fused) Low Overhead API (LOA) to improve performance of small matrix shapes.
Our Commitment to Open Source
A key part of our strategy is to contribute our work back to the open-source community. We have been actively upstreaming our optimizations directly into the core PyTorch codebase. Similarly, our work on the PluggableDevice feature was contributed and accepted into the TensorFlow-Java repository. These regular contributions strengthen the native performance and capabilities of these frameworks, benefiting all users.
The Result: Real-World Performance Gains
These software enhancements deliver tangible performance improvements for a wide range of AI workloads on AMD EPYC™ CPUs. By optimizing at the kernel, graph, and framework levels, we enable developers to achieve higher throughput and lower latency for their inference tasks without complex configuration.
We encourage you to try out the upgraded plugins (zentorch and zentf)and optimizations and share your feedback with us on Github. For detailed installation instructions and further information, please refer to our documentation and GitHub pages.


Related Blogs
-
The Journey Begins: AMD, SUSE and Rancher Government Solutions (RGS) Team Up on Initial Validation of Enterprise AI Blueprints
AMD, SUSE, and RGS are delivering a secure, open AI platform to accelerate private, sovereign, and enterprise AI deployments.
July 22, 2026
-
Deploy an Imaging AMD Solution Blueprint on AMD Radeon™ GPUs — ROCm Blogs
Learn how to deploy AMD Solution Blueprints on AMD Radeon™ GPUs by following a hands-on example of deploying the MRI Analysis Tool Solution Blueprint
July 21, 2026
-
Introducing ROCm™ AMD Infinity Context: A Purpose-Built KV Cache Tier for Distributed Inference — ROCm Blogs
Explore ROCm AMD Infinity Context (AIC), AMD's open KV cache tier built on AMD Infinity Storage for distributed LLM inference.
July 21, 2026
-
Kimi Code in MXFP4 on AMD GPUs
Discover how ATOM accelerates Kimi K2.5, K2.6, and K2.7-Code inference with optimized serving on AMD Instinct™ GPUs.
July 21, 2026
-
AMD Data Intelligence Platform: Open Modular Blueprint
See how AMD built OPTIMA, an open data intelligence platform that connects enterprise data for AI agents, analytics, and automation.
July 21, 2026
-
Rebuilding Agentic AI for AMD GPU
AMD and Moonshot AI built an agentic AI serving stack that optimizes KV cache, scheduling, and GPU performance on AMD Instinct™ GPUs
July 21, 2026
-
Efficient MiniMax-M3 Inference on AMD Instinct GPUs with ATOM and ATOMesh — ROCm Blogs
Serve and benchmark MiniMax-M3 on AMD Instinct MI355X GPUs using ATOM and ATOMesh with EAGLE3 speculative decoding.
July 20, 2026
-
Train and Run Models on AMD GPUs with Unsloth
Train, fine-tune, run AI models with Unsloth on AMD GPUs across Windows, WSL and Linux, with native inference for leading models.
July 20, 2026








Footnotes
Footnote:
ZD-058:
Testing conducted internally by AMD as of 06/27/2025. The environment settings for this configuration are as follows:
The operating system is Ubuntu 22.04 LTS, running on a 2-socket AMD EPYC™ 9755 128-Core Processor system with SMT enabled and 2 NUMA nodes, Python 3.11.8; zentorch 5.1.0; vLLM 0.9.0+cpu; IPEX 2.7.0; LLVM OpenMP 18.1.8=hf5423f3_1. Core binding is set for 96 cores per instance. The VLLM_CPU_KVCACHE_SPACE is set to 90, and VLLM_CPU_OMP_THREADS_BIND is set to 0-95.
ZenDNN variables include ZENDNN_TENSOR_POOL_LIMIT=1024, ZENDNN_MATMUL_ALGO=FP32:4,BF16:0, ZENDNN_PRIMITIVE_CACHE_CAPACITY=1024, and ZENDNN_WEIGHT_CACHING=1.
For model testing, the number of prompts is 512, with a maximum number of sequences of 32.
Datatype is BFloat16. All performance metrics are based on throughput in tokens per second.
model output_len input_len vLLM+zentorch 5.1.0 vLLM+IPEX 2.7.0 Speedup
microsoft/phi-4 128 128 151.8294537 119.1399245 1.27
microsoft/phi-4 128 512 96.863873 76.8731383 1.26
microsoft/phi-4 512 128 171.4570229 136.693467 1.25
microsoft/phi-4 512 512 143.4388875 114.772913 1.25
Qwen/Qwen2.5-3B 128 128 244.7217902 212.5098186 1.15
Qwen/Qwen2.5-3B 128 512 200.8506422 162.2628558 1.24
Qwen/Qwen2.5-3B 512 128 256.5140076 225.1190505 1.14
Qwen/Qwen2.5-3B 512 512 238.5087328 205.2969589 1.16
Qwen/Qwen2.5-7B-Instruct 128 128 192.4150592 159.5727 1.21
Qwen/Qwen2.5-7B-Instruct 128 512 143.529983 116.2419905 1.23
Qwen/Qwen2.5-7B-Instruct 512 128 207.351553 175.2798501 1.18
Qwen/Qwen2.5-7B-Instruct 512 512 185.0314871 156.7501855 1.18
meta-llama/Llama-3.2-3B-Instruct 128 128 277.8863782 239.084652 1.16
meta-llama/Llama-3.2-3B-Instruct 128 512 221.9389208 171.8899209 1.29
meta-llama/Llama-3.2-3B-Instruct 512 128 290.0127427 254.1709159 1.14
meta-llama/Llama-3.2-3B-Instruct 512 512 264.4799039 227.8941912 1.16
EleutherAI/gpt-j-6b 128 128 262.4814183 191.0104725 1.37
EleutherAI/gpt-j-6b 128 512 167.1430942 109.5319672 1.53
EleutherAI/gpt-j-6b 512 128 284.5393133 214.4331284 1.33
EleutherAI/gpt-j-6b 512 512 224.6661979 166.5562967 1.35
Results may vary based on system configurations and settings.
Footnotes
Footnote:
ZD-058:
Testing conducted internally by AMD as of 06/27/2025. The environment settings for this configuration are as follows:
The operating system is Ubuntu 22.04 LTS, running on a 2-socket AMD EPYC™ 9755 128-Core Processor system with SMT enabled and 2 NUMA nodes, Python 3.11.8; zentorch 5.1.0; vLLM 0.9.0+cpu; IPEX 2.7.0; LLVM OpenMP 18.1.8=hf5423f3_1. Core binding is set for 96 cores per instance. The VLLM_CPU_KVCACHE_SPACE is set to 90, and VLLM_CPU_OMP_THREADS_BIND is set to 0-95.
ZenDNN variables include ZENDNN_TENSOR_POOL_LIMIT=1024, ZENDNN_MATMUL_ALGO=FP32:4,BF16:0, ZENDNN_PRIMITIVE_CACHE_CAPACITY=1024, and ZENDNN_WEIGHT_CACHING=1.
For model testing, the number of prompts is 512, with a maximum number of sequences of 32.
Datatype is BFloat16. All performance metrics are based on throughput in tokens per second.
model output_len input_len vLLM+zentorch 5.1.0 vLLM+IPEX 2.7.0 Speedup
microsoft/phi-4 128 128 151.8294537 119.1399245 1.27
microsoft/phi-4 128 512 96.863873 76.8731383 1.26
microsoft/phi-4 512 128 171.4570229 136.693467 1.25
microsoft/phi-4 512 512 143.4388875 114.772913 1.25
Qwen/Qwen2.5-3B 128 128 244.7217902 212.5098186 1.15
Qwen/Qwen2.5-3B 128 512 200.8506422 162.2628558 1.24
Qwen/Qwen2.5-3B 512 128 256.5140076 225.1190505 1.14
Qwen/Qwen2.5-3B 512 512 238.5087328 205.2969589 1.16
Qwen/Qwen2.5-7B-Instruct 128 128 192.4150592 159.5727 1.21
Qwen/Qwen2.5-7B-Instruct 128 512 143.529983 116.2419905 1.23
Qwen/Qwen2.5-7B-Instruct 512 128 207.351553 175.2798501 1.18
Qwen/Qwen2.5-7B-Instruct 512 512 185.0314871 156.7501855 1.18
meta-llama/Llama-3.2-3B-Instruct 128 128 277.8863782 239.084652 1.16
meta-llama/Llama-3.2-3B-Instruct 128 512 221.9389208 171.8899209 1.29
meta-llama/Llama-3.2-3B-Instruct 512 128 290.0127427 254.1709159 1.14
meta-llama/Llama-3.2-3B-Instruct 512 512 264.4799039 227.8941912 1.16
EleutherAI/gpt-j-6b 128 128 262.4814183 191.0104725 1.37
EleutherAI/gpt-j-6b 128 512 167.1430942 109.5319672 1.53
EleutherAI/gpt-j-6b 512 128 284.5393133 214.4331284 1.33
EleutherAI/gpt-j-6b 512 512 224.6661979 166.5562967 1.35
Results may vary based on system configurations and settings.