推动学术界 AI 研究:混合模型与更智能的系统
Feb 12, 2026

随着人工智能技术日趋成熟,研究人员开始提出不同的问题。仅追求更高的准确率已远远不够。如今,可扩展性、效率和可持续性才是推动研究发展的核心动力。这些问题在学术界尤为重要,因为学术界往往需要在紧张有限的算力资源下开展创新研究。
AMD 做出了重大贡献,通过助力开展研究来解决这些难题,将模型设计、系统效率与实际应用紧密结合。本博文将探讨 AI 研究领域中的新兴主题,包括混合架构、硬件感知优化技术以及正在改变 AI 研究实践的 AI 辅助研究工作流程。
ICLR 2026 学术研究影响力
AMD 在 ICLR 2026 上展现出强劲的学术实力,共有六篇论文成功录用,研究方向涵盖高效推理、扩散模型加速、多模态推理、混合语言模型以及 AI 驱动的研究系统等领域。这些成果共同彰显了 AMD 对于推动可扩展、实用且开放的 AI 研究的坚定承诺。
通过合成数据增强学习与推理
AI 技术在学术界的一项核心价值在于增强模型学习与推理能力,特别是在数学等复杂领域。SAND‑Math 提出了一种利用大语言模型生成高难度数学题及对应解法的流程。该流程会从零开始生成题目,并通过内置的“难度递增”(Difficulty Hiking) 步骤系统性地提升题目复杂度,然后再将题目添加到数据集。与其他合成数据集相比,使用该合成数据对推理模型进行微调后,模型在 AIME25 等基准测试中的性能表现实现了显著提升。
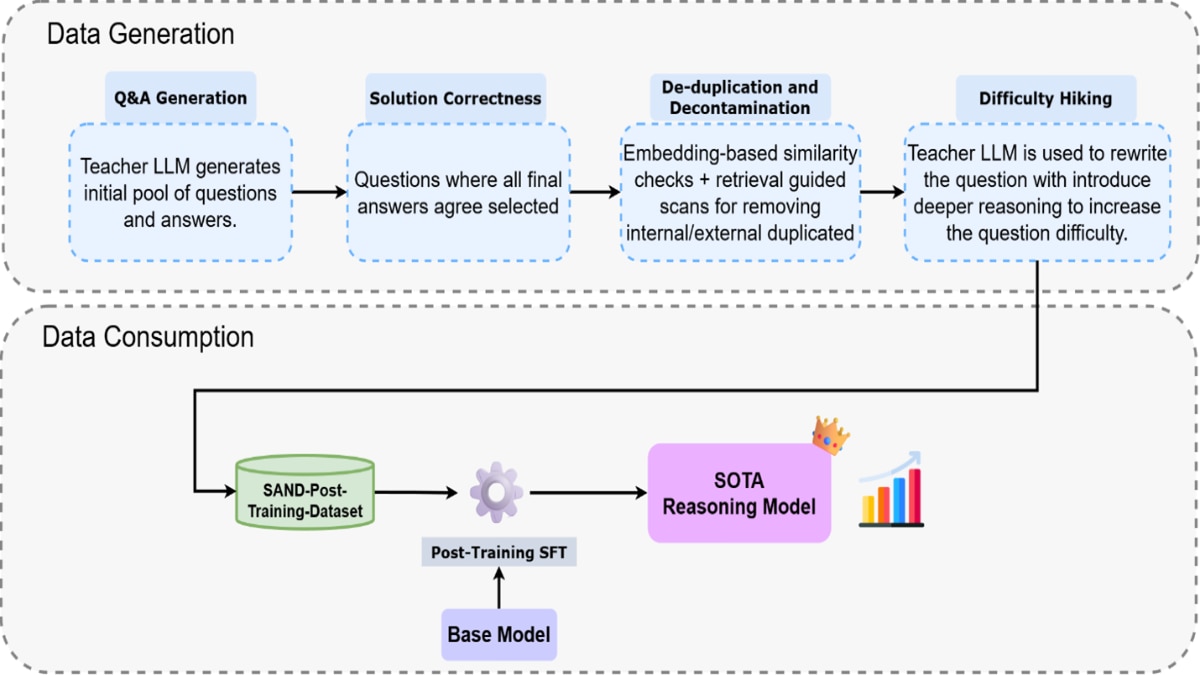
核心理念包括:
- 自动生成新颖且具有挑战性的数学题目,而不仅仅是简单地重新组合现有数据集。
- 通过一种“难度递增”机制提升题目复杂度,让模型在基于增强型数据集进行微调后,获得显著的性能提升。
这项研究工作展示了合成数据流水线如何弥合模型训练中的关键缺口,尤其适用于经过精心整理的高质量数据数量有限的领域。
SANDMath:生成高难度数学数据集
AI 生成的 GPU 内核代码及评估基准
随着工作负载的要求日益严苛,硬件优化代码(尤其是 GPU 内核)已成为性能瓶颈。GEAK 研究论文通过利用大语言模型自动生成并优化用 Triton(一种基于 Python 的高性能 GPU 编程语言)编写的 GPU 内核,解决了这一问题。GEAK 不再依赖手动优化的代码,而是采用一种受智能体 AI 启发的推理循环,结合基准测试套件,通过多次迭代自动优化内核代码。
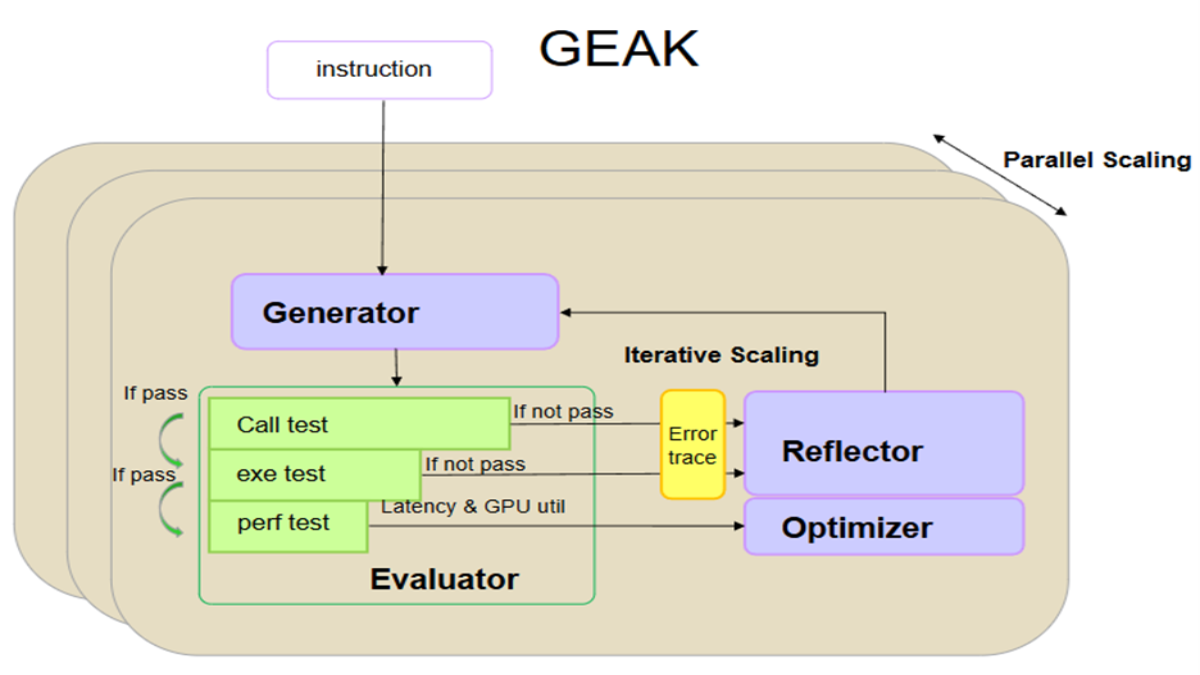
亮点包括:
- 提出一种利用 AI 生成 GPU 内核的框架,该框架专为现代 GPU 架构等硬件而设计。
- 基准测试和评估套件显示,与基线生成流水线相比,执行速度提升高达约 2.6 倍,且正确率高。
这项研究工作展现了智能体 AI 在系统编程领域的巨大潜力,该技术既能减轻开发者负担,又可在多种硬件上实现更接近专业级性能的出色表现。
GEAK:AI 生成的 GPU 内核优化
让混合语言模型更高效、更易使用
大语言模型具备非凡能力,但严苛的内存和算力需求却成为其落地部署与实验的一大障碍。
Zebra-Llama 提出了一种混合建模方法,融合了:
- 状态空间模型 (SSM)
- 多头潜在注意力 (MLA)
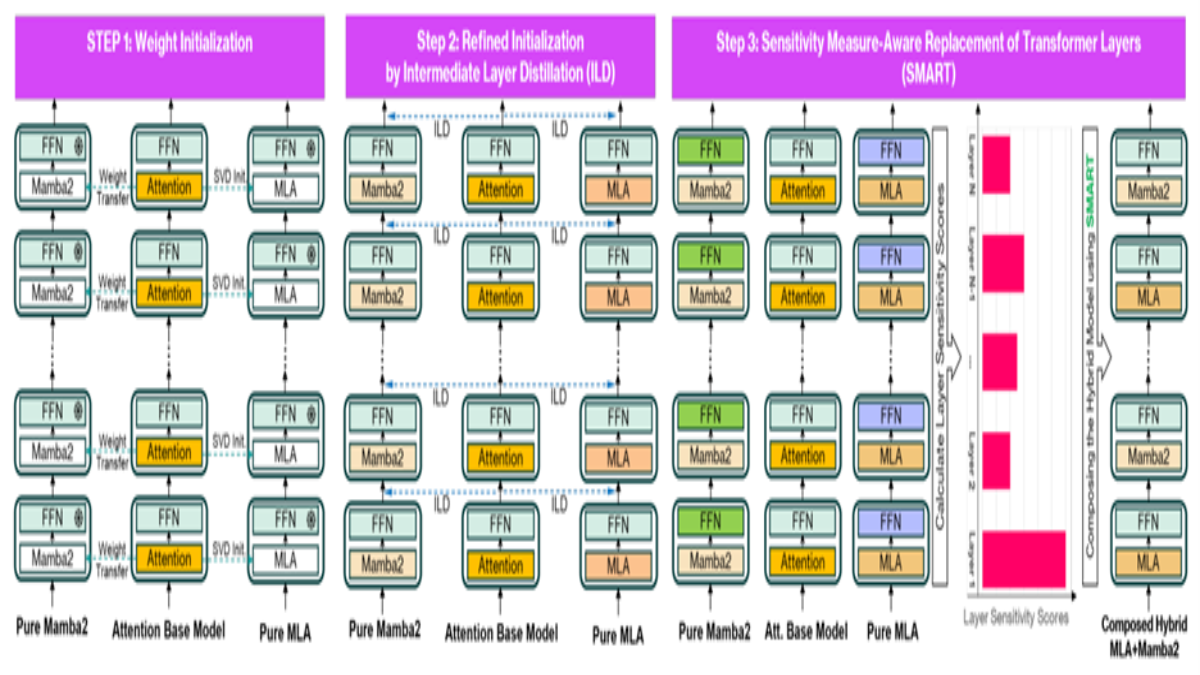
目标是直接基于预训练的 Transformer 模型,通过精细的初始化和训练后流程,创建高效的混合模型,而无需从头开始。
主要成果:
- 混合模型可达到与 Transformer 模型相当的准确率,而且内存占用和训练数据量远低于传统方案。
- 键值缓存大小显著缩减(仅为原大小的百分之几),有效提升吞吐量并降低推理成本。
Zebra-Llama 研究表明,通过灵活组合模型组件实现算法创新,可以在保持性能的同时实现切实的效率提升。
Zebra-Llama:高效的混合大语言模型
AI 智能体作为研究协作者
部分研究不仅将 AI 视为预测工具,更将其视为研究过程中的合作伙伴。Agent Laboratory 开发了一种框架,其中专业化的大语言模型智能体(如“研究员”、“审稿人”和“顾问”智能体)在研究工作流程中协同合作:
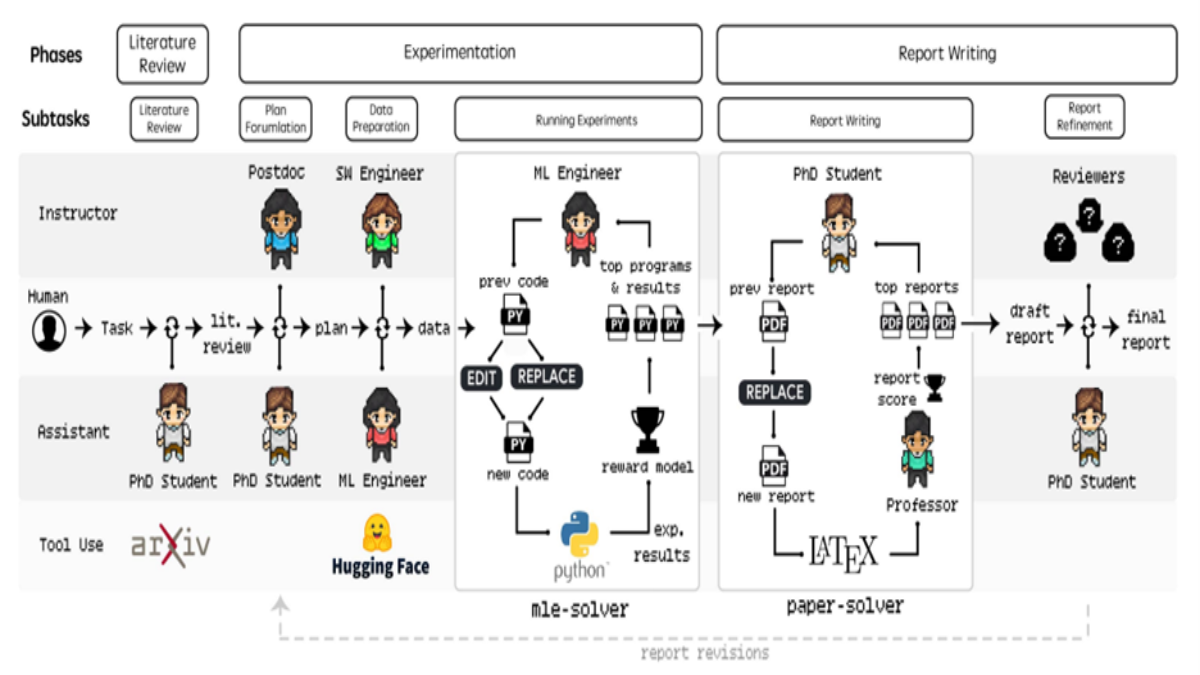
- 汇总梳理文献资料
- 生成并运行代码
- 记录结果与撰写学术文稿
通过协调这些智能体并让人类参与监督,此系统能够显著减少从概念构思、可运行代码实现到书面报告撰写的整个研究产出过程所需的时间和精力。这项研究工作表明:
- 通过利用 AI 工具处理常规任务,可缩短研究周期。
- 人类与 AI 相结合的工作流程可赋能研究人员,而非取代他们。
统一宗旨:效率与创新相结合
在混合模型架构、硬件感知系统和 AI 辅助工作流程等领域,这些学术成果揭示了几个关键主题:
- 效率至关重要:降低内存、算力和能耗成本有助于推动更广泛的采用。
- 复用与适配:利用现有模型或硬件平台比从头开始重新训练更加可持续。
- 系统与算法同步演进:当模型充分考虑部署环境时,优化效果最佳。
- AI 赋能研究:除了建模,AI 还能加速科学研究进程,使研究更高效且更具可重复性。
上述研究成果共同表明,AI 的进步不仅在于构建更庞大的模型,更在于构建更智能的系统和工作流程。
AMD 亮相 ICLR 2026
AMD 的研究成果在 ICLR 2026 上大放异彩,获录用的论文包括:
- PARD: Accelerating LLM Inference with Low‑Cost PARallel Draft Model Adaptation(PARD:利用低成本并行草稿模型适配加速大语言模型推理)。作者:Zihao An、Huajun Bai、Ziqiong Li、Dong Li、Emad Barsoum。
- Diffsparse: Accelerating Diffusion Transformers With Learned Token Sparsity(Diffsparse:利用学习型 Token 稀疏性加速扩散 Transformer 模型)。作者:Haowei Zhu、Ji Liu、Ziqiong Liu、Dong Li、Jun-Hai Yong、Bin Wang、Emad Barsoum
- Training-Free Loosely Speculative Decoding: Accepting Semantically Correct Drafts Beyond Exact Match(免训练松散推测解码:接受超越精确匹配的语义正确草稿)。作者:Jinze Li、Yixing Xu、Guanchen Li、Shuo Yang、Jinfeng Xu、Xuanwu Yin、Dong Li、Edith C. H. Ngai、Emad Barsoum
- Latent Visual Reasoning(潜在视觉推理)。作者:Bangzheng Li、Ximeng Sun、Jiang Liu、Ze Wang、Jialian Wu、Xiaodong Yu、Hao Chen、Emad Barsoum、Muhao Chen、Zicheng Liu
- XModBench: Benchmarking Cross-Modal Capabilities and Consistency in Omni-Language Models(XModBench:面向全语言模型的跨模态能力与一致性基准测试)。作者:Xingrui Wang、Jiang Liu、Chao Huang、Xiaodong Yu、Ze Wang、Ximeng Sun、Jialian Wu、Alan Yuille、Emad Barsoum、Zicheng Liu
- ImageDoctor: Diagnosing Text-to-Image Generation via Grounded Image Reasoning(ImageDoctor:基于接地图像推理的文生图诊断)。作者:Yuxiang Guo、Jiang Liu、Ze Wang、Hao Chen、Ximeng Sun、Yang Zhao、Jialian Wu、Xiaodong Yu、Zicheng Liu、Emad Barsoum
展望未来
随着 AI 持续发展,聚焦性能、效率和实用性的研究将变得愈发重要。通过持续产出学术研究成果,AMD 希望帮助确立性能、效率和实用性之间的平衡。我们正在推进混合模型架构和硬件感知优化技术,并探索能够让研究过程更加顺畅的 AI 辅助研究工具。
这些努力充分表明我们致力于推动开放包容的协作型研究,旨在将算法、系统与实际部署需求紧密结合。通过与更广泛的社区分享洞见、工具和方法,AMD 致力于确保 AI 发展不再仅依赖于模型规模扩大,而是依托精密设计和易用性。随着研究人员基于这些现有成果持续探索混合模型、智能体式工作流程以及系统感知优化技术,学术界与产业界的深度协作将继续发挥关键作用,助力打造更强大、更高效、更具影响力的 AI 技术。
探索更多 AMD 研究
如需阅读更多 AMD 研究博客、技术深度解析及公开学术成果,请访问 ROCm 博客。


Related Blogs
-
-
AMD 推出全新锐龙 AI Halo 开发者平台和锐龙 AI Max PRO 400 系列处理器,助力新一代智能体计算机发展
AMD 推出面向本地智能体 AI PC 和工作站的锐龙 AI Halo 和锐龙 AI Max PRO 400 系列。
May 20, 2026
-
AMD携手联想百应打造x86全栈算力+端云混合+智能体服务
联想百应AI Max+395系列旨在给开发者、中小企业的AI本地化智能体提供 “隐私可控的创作自由和使用自由”。
April 28, 2026
-
跳出概念炒作:将 AI PC 的潜在价值转化为切实商业收益
AI PC 正在重塑企业战略。了解 AMD 计算连续体如何帮助首席信息官跳出概念炒作,通过部署 AI 创造切实商业价值。
April 23, 2026
-
基于 AMD 锐龙 AI Max+ 处理器和 Radeon GPU,在本地高效运行 Hermes Agent
本指南演示了如何在配备 AMD 锐龙 AI Max+ 处理器和 Radeon GPU 的 Windows 系统上,使用 WSL2 和 LM Studio 运行 Hermes Agent。
April 21, 2026
-
为现代工作室的生产引擎添能助力:AMD 亮相 NAB 2026
2026 年美国广播电视展 (NAB Show) 将于 4 月 18 日至 22 日在拉斯维加斯举行。整个行业正发生着令人振奋的新变化,我们期待在展会上与您相见!
April 17, 2026
-
针对 AMD Versal™ 自适应 SoC 设计,采用渐进式方法加速系统级验证
系统级验证变得越来越复杂。依托 AMD Vitis™ 软件平台,开发者可以采用渐进式验证方法。
April 17, 2026
-







