在 AMD Instinct GPU 上部署 OpenHands 编码智能体
Jan 28, 2026

编码智能体
编码智能体是指能够单独或与开发者协作,完成代码生成、分析、调试及软件工件文档编写等工作的 AI 智能体。智能体正通过自动化复杂任务、加速生产力提升以及开启全新软件生成范式,重塑软件开发格局。OpenHands 是一款广受欢迎的开源编码智能体,不仅为开发者提供可与之协作的软件智能体,还提供了软件智能体 SDK,帮助开发者构建自己的编码智能体。
在本博客中,我们将展示如何充分发挥 AMD Instinct GPU 的强大能力。您将学习如何在 AMD Developer Cloud 上使用 vLLM 推理引擎部署先进的 Qwen3-Coder 模型,以及如何使用 OpenHands SDK 在自托管基础设施上构建智能体工作流程。
AMD AI 开发者计划
本博客所展示的工作流程由 AMD AI 开发者计划提供支持;该计划提供计算基础设施、工具、培训等资源,以支持社区的 AI 开发。下图总结了该计划提供的权益。了解更多信息并立即加入。

开始在 AMD Developer Cloud 上使用 OpenHands
首先,我们需要在 AMD Developer Cloud 上运行一个模型。我们将在单个 AMD Instinct MI300X GPU 上使用 vLLM 推理引擎运行 Qwen3-Coder-30B-A3B-Instruct。
- 注册 AMD AI 开发者计划,即可获得价值 100 美元的 AMD Developer Cloud 信用值。
- 通过 DigitalOcean 控制面板在 AMD Developer Cloud 上创建一个帐户。
- 使用 AMD ROCm 软件包创建 Droplet。对于此工作流程,一个 MI300X GPU 已足以运行 Qwen3-Coder-30B-A3B 模型。
- 注意:我们使用 ROCm 软件包而非 vLLM 镜像,以便拉取最新的 vLLM 镜像,确保支持最新模型。
图像缩放
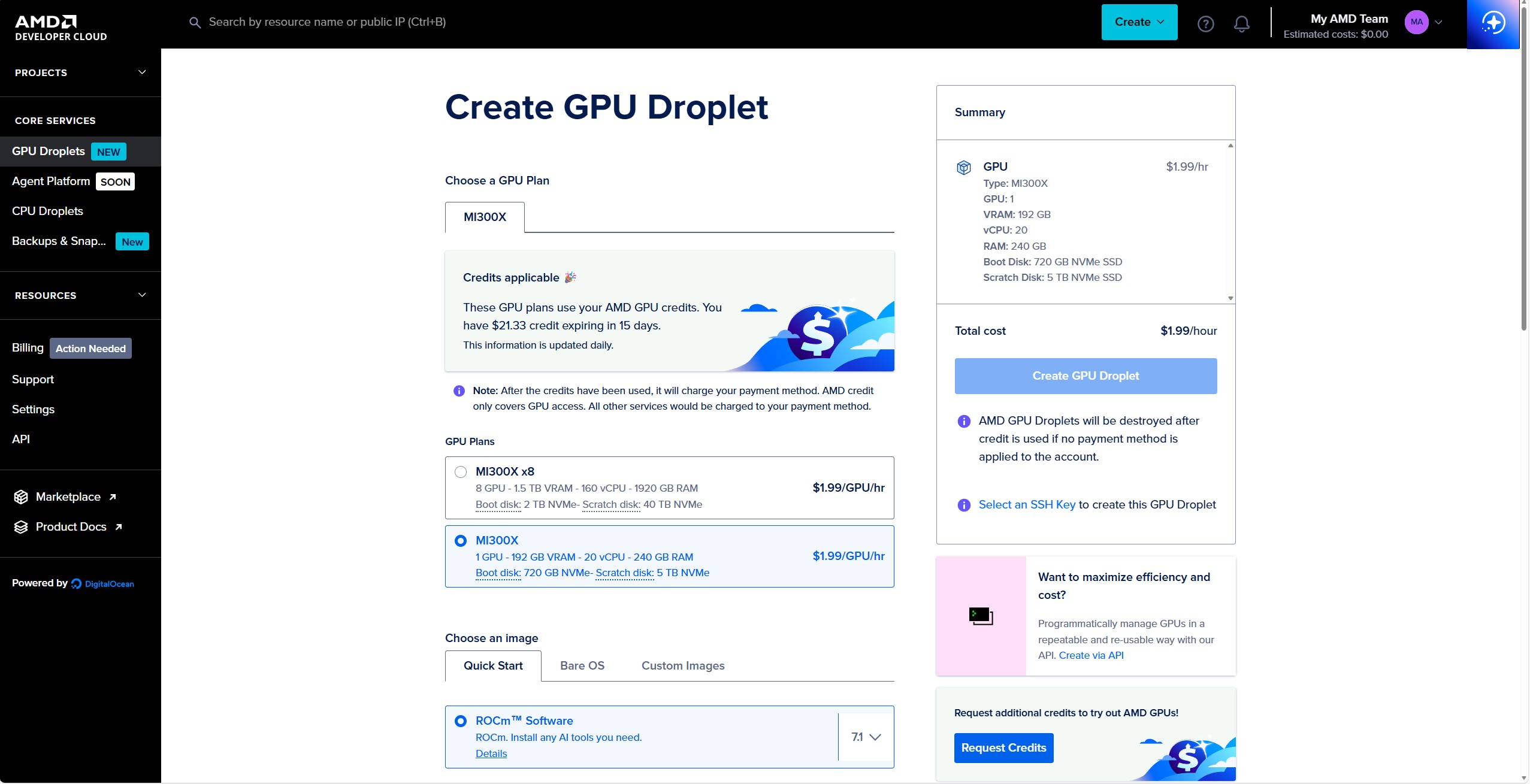
4. 创建 Droplet 后,可通过 SSH 访问该实例。注意:创建的帐户用户名将为 root。要访问 Droplet,请使用:
ssh root@<ipv4-address>
注意:确保上传 SSH 密钥并将其添加到 Droplet 以允许访问机器。
5. 登录机器后,必须拉取 vLLM Docker 容器。这些容器可在 rocm/vll 仓库(rocm/vllm - Docker 镜像)中找到。使用以下命令拉取最新的 rocm/vllm Docker 容器:
docker pull rocm/vllm:latest
注意:对于刚发布的模型,可能需要使用 ROCm vLLM 每日构建版本。这些版本可在 rocm/vllm-dev 仓库(rocm/vllm-dev - Docker 镜像)中找到,并可使用以下命令拉取:
docker pull rocm/vllm-dev:nightly
6. 拉取 Docker 容器镜像后,即可运行它。执行以下命令以运行 Docker 容器:
docker run -it --rm --device=/dev/kfd --device=/dev/dri -p 8000:8000 --group-add video --shm-size 16G --security-opt seccomp=unconfined --security-opt apparmor=unconfined <docker-image-name> /bin/bash
7. 现在您将进入 Docker 容器内的 shell,请执行以下命令以使用 vLLM 运行 Qwen3-Coder-30B-A3B-Instruct:
vllm serve Qwen/Qwen3-Coder-30B-A3B-Instruct --max-model-len 32000 --enable-auto-tool-choice --tool-call-parser qwen3_coder
8.要验证 vLLM 服务器是否正在运行,请在 Web 浏览器中访问 http://<ipv4-address>:8000/v1/models/。它应列出服务器上运行的所有模型,在本例中仅为 Qwen3-Coder-30B-A3B-Instruct:
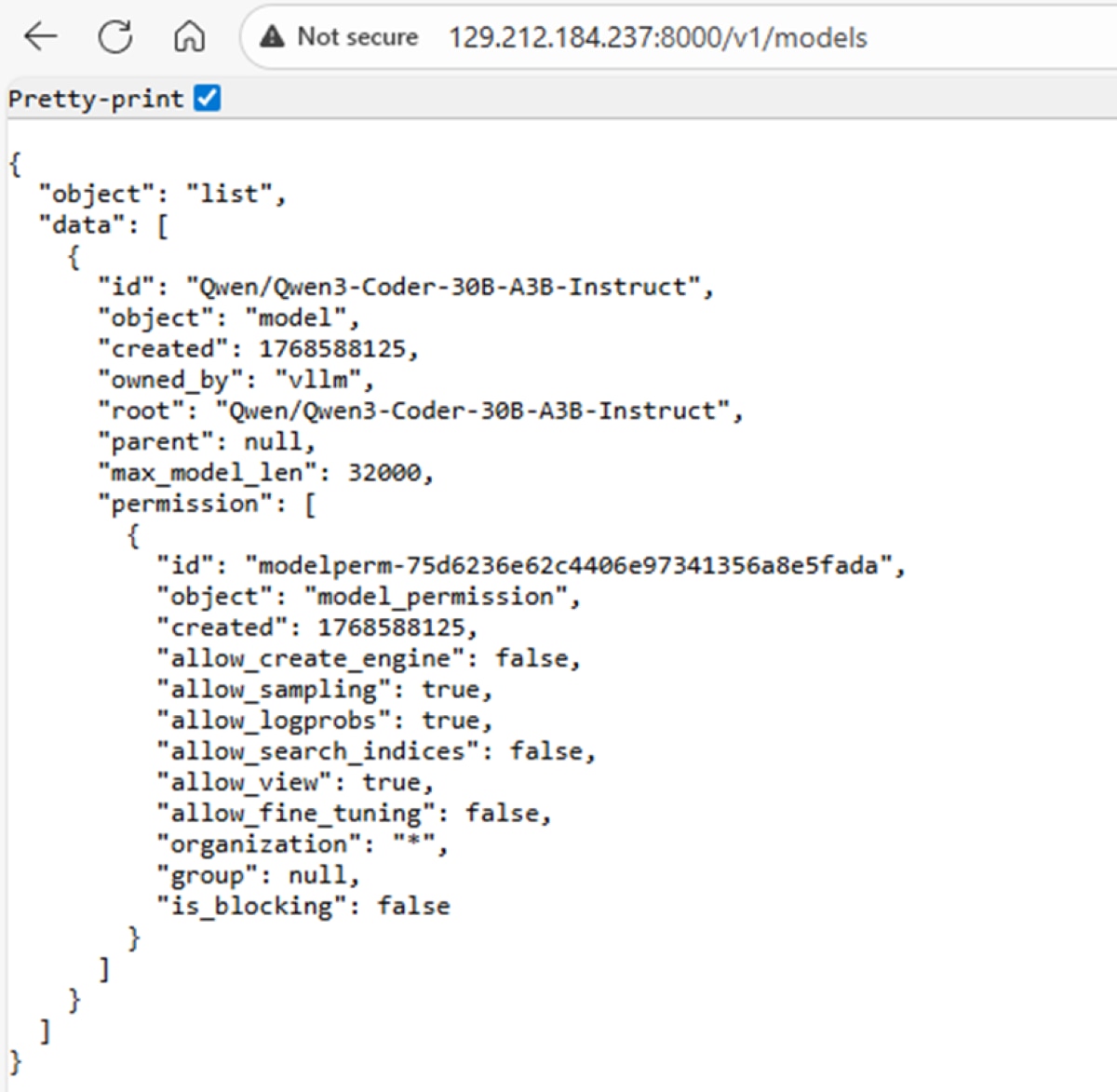
注意:我们使用的 Qwen3-Coder-30B 模型可在单个 GPU 上运行。根据提供给智能体的任务的复杂性,可能需要使用更大的模型,如 Qwen3-Coder-480B-A35B-Instruct。对于这些模型,需要租用配备 8 个 GPU 的节点。配备 8 个 GPU 的节点也可通过 AMD Developer Cloud 租用;有关如何启动模型的 vLLM 配方,可在以下网址找到:vLLM 配方。
将 OpenHands 命令行接口连接到 GPU 实例
现在 vLLM 推理引擎已在 GPU 实例上运行,我们可以利用该计算资源,在刚刚创建的 GPU 实例上运行软件智能体。首先,运行 OpenHands 命令行接口,并调用 OpenHands 编码智能体来生成软件:
- 按照 OpenHands 文档启动 OpenHands CLI:OpenHands/OpenHands-CLI:二进制可执行文件形式的轻量级 OpenHands CLI。
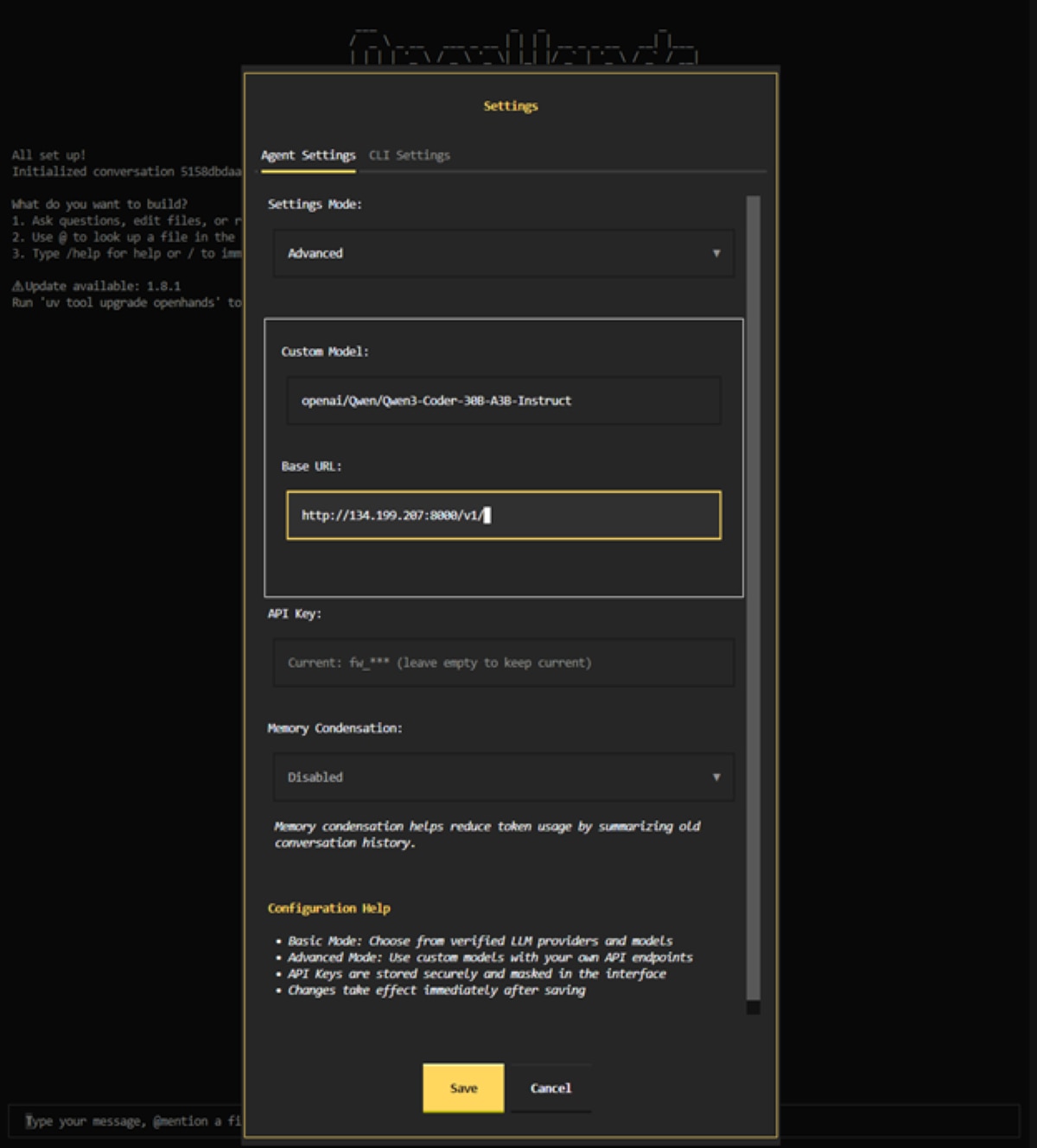
- OpenHands CLI 将首先提示配置提供程序设置。首先,将“Settings Mode”(设置模式)设为“Advanced”(高级),如下所示。然后,使用 openai/Qwen/Qwen3-Coder-30B-A3B-Instruct 作为模型,并使用 http://<ipv4-address>:8000/v1/ 作为基础 URL。API 密钥可设置为任意值,因为我们未在 vLLM 实例上设置 API 密钥。
图像缩放
3.开启新对话,并通过 CLI 让 OpenHands 智能体为您编程。
例如,我们使用以下提示让模型生成一个乒乓球街机游戏:“使用 Pygame 创建一个乒乓球街机游戏。”
在 GPU 实例上使用 OpenHands 开发软件智能体
OpenHands 还提供软件智能体 SDK,开发者可以使用它构建定制化软件智能体。按照以下步骤使用 OpenHands 软件智能体 SDK 构建智能体
- 根据文档克隆并构建 OpenHands software-agent-sdk:OpenHands/software-agent-sdk:一套简洁的模块化 SDK,助力基于 OpenHands V1 构建 AI 智能体。
- 将以下内容写入名为 fact-agent.py 的新文件,以创建一个智能体,该智能体会遍历当前项目并将 3 条关于项目的事实信息写入名为 FACTS.txt 的文件中:
import os
from openhands.sdk import LLM, Agent, Conversation, Tool
from openhands.tools.file_editor import FileEditorTool
from openhands.tools.task_tracker import TaskTrackerTool
from openhands.tools.terminal import TerminalTool
llm = LLM(
model="openai/Qwen/Qwen3-Coder-30B-A3B-Instruct",
api_key="no-key-needed",
base_url=”http://<ipv4-address>:8000/v1/”
)
agent = Agent(
llm=llm,
tools=[
Tool(name=TerminalTool.name),
Tool(name=FileEditorTool.name),
Tool(name=TaskTrackerTool.name),
],
)
cwd = os.getcwd()
conversation = Conversation(agent=agent, workspace=cwd)
conversation.send_message("Write 3 facts about the current project into FACTS.txt.")
conversation.run()
print("All done!")
3.检查新创建的 FACTS.txt,其中将写入关于当前项目的 3 条事实信息。
这是使用 OpenHands 智能体 SDK 创建的一个简单智能体。我们建议读者参考 software-agent-sdk 代码库中的示例,其中包含更多关于如何使用 OpenHands 构建自定义智能体的示例:software-agent-sdk/examples/01_standalone_sdk at main · OpenHands/software-agent-sdk
销毁 GPU 实例
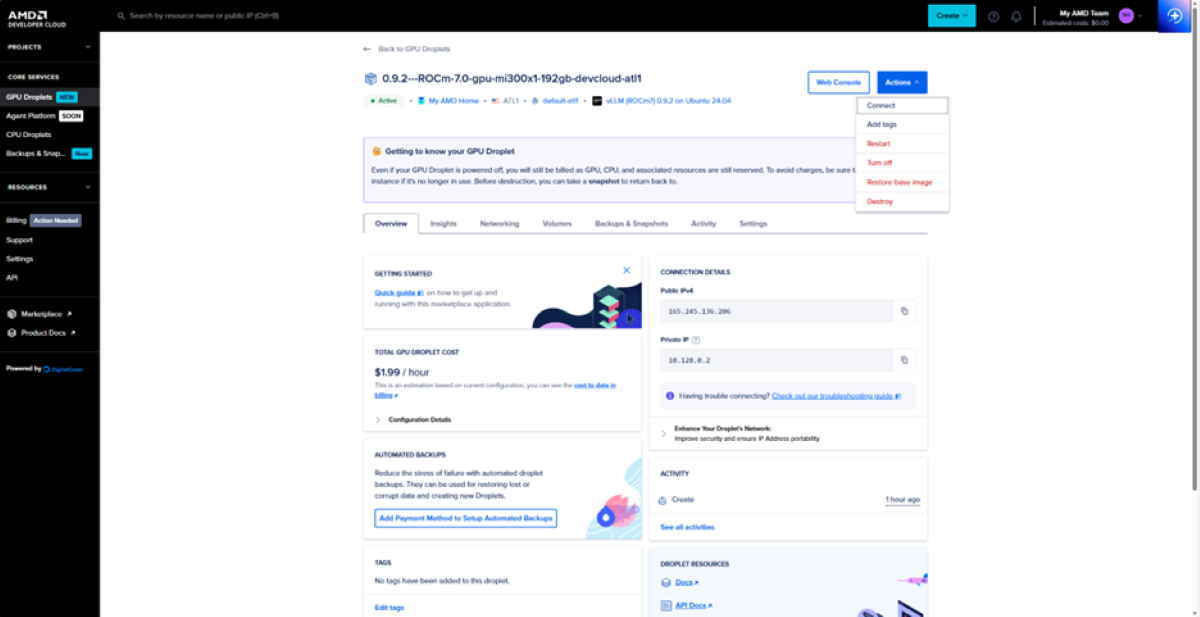
使用完 GPU 实例后,必须将其删除。请注意,即使处于关机状态,GPU Droplet 仍会因为资源占用而被计费。要删除该实例,请转到“Actions”(操作)并单击“Delete”(删除)。您也可以创建快照以便跨实例保持状态。
图像缩放
后续步骤与社区参与
本博客介绍了在 AMD Instinct GPU 上部署 OpenHands 编码智能体的完整工作流程,使开发者能够在自行管理的基础设施上运行、定制和扩展软件智能体。
在此基础上,可从多个方向进行拓展。开发者可以使用 OpenHands 智能体 SDK 构建专用智能体,将 OpenHands 编码智能体集成到现有开发工作流程中以加速软件开发,或专注于优化模型吞吐量和延迟,以支持更快、响应更迅速的大规模智能体。
我们期待看到社区的下一步发展。您可以通过 AMD 开发者社区 Discord 频道,与基于 AMD Developer Cloud 进行开发的其他开发者分享项目、想法和反馈。
此外,还可以通过 OpenHands Slack 与 OpenHands 团队及更广泛的社区进行协作。
致谢
衷心感谢 Robert Brennan、Ben Solari、Graham Neubig、Joe Pelletier 和 Xingyao Wang,感谢他们在 OpenHands 项目中积极协作并开发出卓越技术。


Related Blogs
-
-
Gartner 将 AMD 评为 Gartner® AI 供应商竞争中的当前领先企业
Gartner 在一份报告中将 AMD 称为企业级 AI 服务器 CPU 领域的当前领跑者。
June 24, 2026
-
-
-
AMD 推出全新锐龙 AI Halo 开发者平台和锐龙 AI Max PRO 400 系列处理器,助力新一代智能体计算机发展
AMD 推出面向本地智能体 AI PC 和工作站的锐龙 AI Halo 和锐龙 AI Max PRO 400 系列。
May 20, 2026
-
AMD携手联想百应打造x86全栈算力+端云混合+智能体服务
联想百应AI Max+395系列旨在给开发者、中小企业的AI本地化智能体提供 “隐私可控的创作自由和使用自由”。
April 28, 2026
-
跳出概念炒作:将 AI PC 的潜在价值转化为切实商业收益
AI PC 正在重塑企业战略。了解 AMD 计算连续体如何帮助首席信息官跳出概念炒作,通过部署 AI 创造切实商业价值。
April 23, 2026
-
基于 AMD 锐龙 AI Max+ 处理器和 Radeon GPU,在本地高效运行 Hermes Agent
本指南演示了如何在配备 AMD 锐龙 AI Max+ 处理器和 Radeon GPU 的 Windows 系统上,使用 WSL2 和 LM Studio 运行 Hermes Agent。
April 21, 2026







