
-
Funciones y beneficios clave del integrador de IP Vivado
- Estrecha integración dentro del entorno de diseño integrado Vivado
- Inclusión sin interrupciones de los subsistemas jerárquicos del integrador de IP en el diseño general
- Captura y empaquetado rápidos de diseños del integrador de IP para la reutilización
- Compatibilidad para flujos de diseño gráficos y basados en Tcl
- Rápida simulación y cross-probing (sondeo cruzado) entre múltiples vistas de diseño
- Compatibilidad para todos los dominios de diseño
- Compatibilidad para diseños de procesador o sin procesador
- Integración de algorítmicos (Vitis HLS y Model Composer) e IP de nivel RTL
- Combinación de DSP, video, sistemas analógicos, integración, conectividad y lógica
- Compatibilidad para flujo DFX basado en proyectos
- Enfoque en la productividad del diseñador
- DRC en conexiones complejas de nivel de interfaz durante el ensamblaje del diseño
- Reconocimiento y corrección de errores comunes de diseño
- Propagación automática de parámetros IP a IP interconectada
- Optimizaciones a nivel de sistema
- Asistencia automatizada del diseñador
- Asistencia de colaboración mejorada
- Asistencia de colaboración mejorada
- Los diseños basados en equipos que utilizan el contenedor de diseño de bloques permiten la reutilización y los diseños modulares
- Mejoras de control de revisión que separan los archivos de origen de los archivos generados
- Herramienta de diferencia de diseño de bloques para comparar dos diseños de bloques
Descripción general
AMD Vivado™ es compatible con la entrada de diseño en el HDL (Hardware Description Language, lenguaje de descripción de hardware) tradicional, como VHDL y Verilog. También es compatible con una herramienta gráfica basada en interfaz de usuario llamada IPI (Inter-Processor Interrupt, interrupciones entre procesadores) que permite un entorno de diseño de integración IP de conexión rápida (plug-and-play).
Vivado proporciona las mejores síntesis e implementación de su tipo para las FPGA y los SoC complejos de la actualidad, con capacidades integradas para el cierre de temporización y la metodología.
El informe de la metodología UltraFast™ (report_methodology) que está disponible en el flujo predeterminado de Vivado ayuda a los usuarios a restringir su diseño, analizar resultados y cerrar la temporización.
Características
Te presentamos una descripción general rápida de las funciones de Vivado™ Design Suite para la entrada y la implementación de diseño. Haz clic en las otras pestañas para conocer detalles completos de la función.
- Integrador de IP
- Síntesis lógica
- Metodología de diseño
- Implementación
Integrador de IP
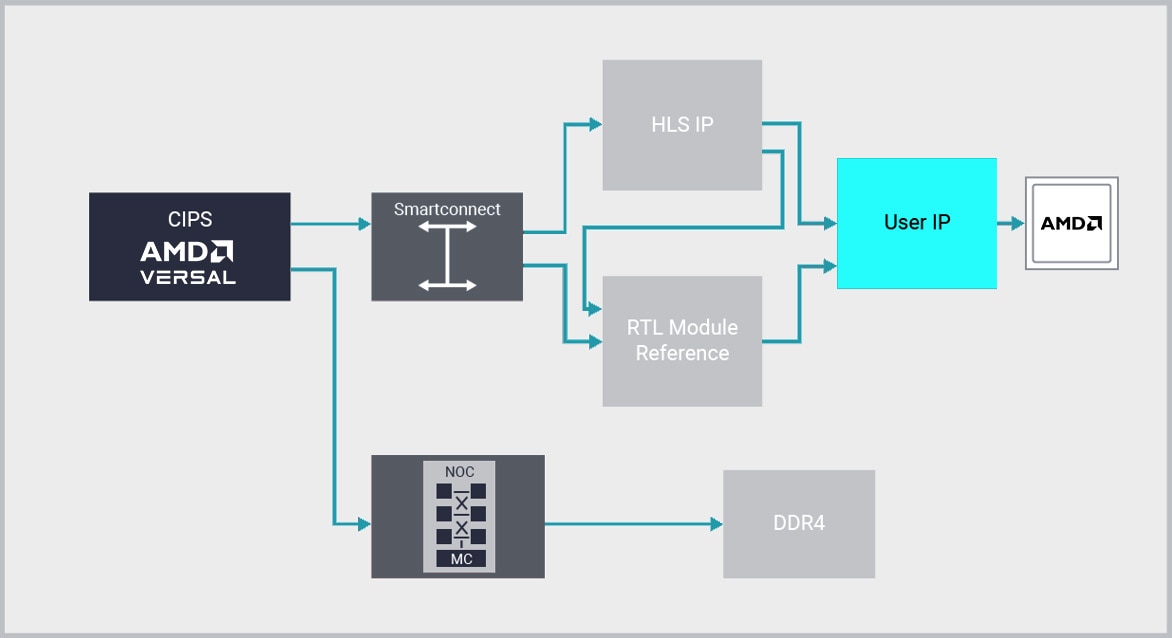
AMD Vivado™ rompe el estancamiento de la productividad del diseño RTL mediante la entrega del primer entorno de diseño de integración IP de conexión rápida (plug-and-play) de la industria, con su función de integrador de IP.
El integrador de IP Vivado proporciona un flujo de desarrollo de diseño gráfico y basado en Tcl, correcto por construcción. Proporciona un entorno interactivo consciente del dispositivo y la plataforma que admite la conexión automática inteligente de interfaces IP clave, generación de subsistemas IP con un solo clic, DRC en tiempo real y propagación de cambios de interfaz, combinado con una potente capacidad de depuración.
Los diseñadores trabajan en el nivel de abstracción de “interfaz” y no de “señal” cuando hacen conexiones entre IP, lo que aumenta enormemente la productividad. A menudo, utilizan para esto interfaces AXI4 estándar de la industria, pero muchas otras interfaces también son compatibles con el integrador de IP.
Trabajando a nivel de interfaz, los equipos de diseño pueden ensamblar rápidamente sistemas complejos que utilizan la IP creada con Vitis HLS, Model Composer, AMD SmartCore™ y LogiCORE™ IP, la IP de miembro de Alliance, así como tu propia IP. Al aprovechar la combinación de IPI (Inter-Processor Interrupt, interrupciones entre procesadores) y HLS de Vivado, los clientes ahorran hasta 15 veces en costos de desarrollo en comparación con un enfoque RTL.
Zoom de imagen
Síntesis lógica
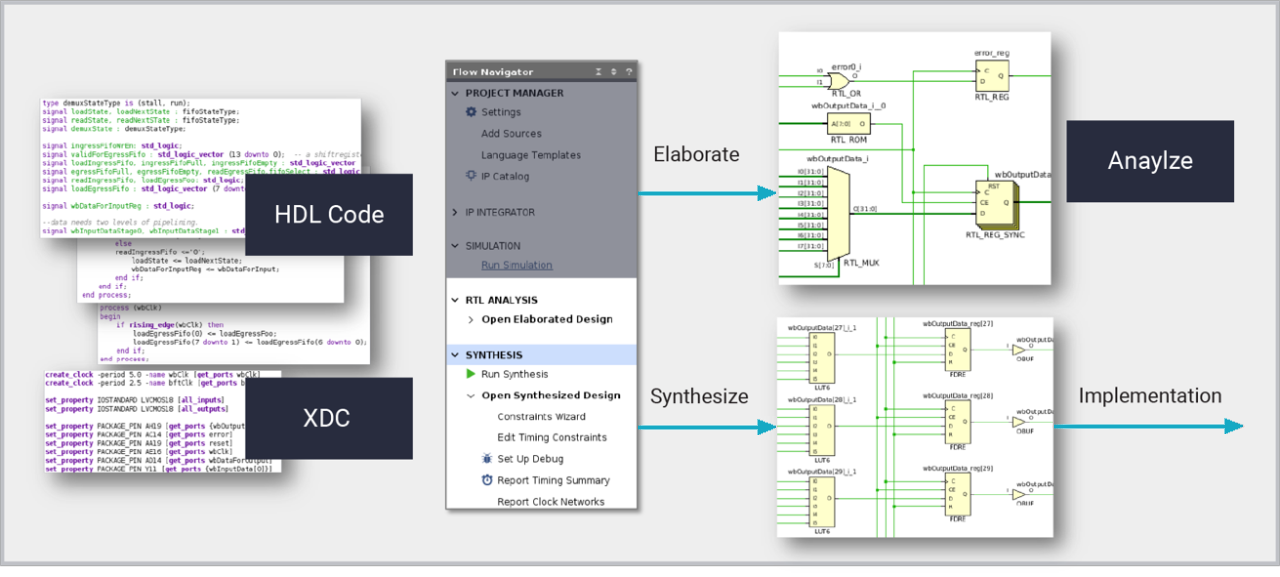
La síntesis lógica de Vivado es una herramienta de creación de diseño que permite a los diseñadores de hardware producir plataformas óptimas, IP y diseños personalizados dirigidos a los dispositivos AMD más recientes. La síntesis lógica traduce diseños de RTL (Register Transfer Level, nivel de transferencia de registro) escritos en SystemVerilog, VHDL y Verilog en una lista de conexiones sintetizada de celdas de biblioteca para la implementación posterior. Al ser consciente de la tecnología de destino, la síntesis puede inferir funciones de descripciones RTL que se asignan directamente a estructuras de chip dedicadas, incluidos LUTRAM, RAM de bloque, registros de cambios, adicionadores-sustractores y bloques DSP. Los resultados de la síntesis se generan mediante atributos, opciones de herramientas y XDC (Xilinx Design Constraints, restricciones de diseño de Xilinx) para cumplir con los objetivos de diseño. La síntesis lógica funciona dentro de proyectos Vivado y scripting Tcl, y proporciona una base sólida para otros métodos de diseño de alto nivel que generan descripciones RTL, incluidos síntesis de alto nivel e integrador de IP.
La síntesis lógica introdujo el aprendizaje automático para ayudar a acelerar la compilación. Los modelos de AA mejoran la eficiencia general mediante la predicción de las optimizaciones de síntesis necesarias para diferentes partes del diseño.
Zoom de imagen
-
Características principales
- Compatibilidad de lenguajes
La síntesis lógica admite las últimas construcciones sintetizables compatibles con los estándares de la industria:
- Los HDL (Hardware Description Languages, lenguajes de descripción de hardware) SystemVerilog, Verilog, VHDL y VHDL-2008
- Capacidad de mezclar diferentes tipos de HDL en el mismo diseño y transmitir parámetros y genéricos a cada tipo
- Plantillas de lenguaje para garantizar una asignación confiable de funciones complejas inferidas a recursos de dispositivo adecuados
Las descripciones de HDL pueden revisarse visualmente utilizando un esquema de diseño elaborado con sondeo cruzado al código fuente HDL relacionado.- Control de optimización
La síntesis lógica proporciona control sobre todos los aspectos de inferencia y optimización. Las asignaciones se pueden hacer:
- Globalmente usando opciones de herramientas y comandos
- En módulos específicos o instancias de jerarquía lógica usando la restricción BLOCK_SYNTH XDC
- En celdas y redes usando atributos HDL
Los tipos de control incluyen las siguientes alternativas:- Mantener, aplanar y reconstruir la jerarquía
- Inferir o no inferir estructuras específicas de la tecnología
- Seleccionar el tipo de recursos de memoria dedicados utilizados para la asignación de matrices de memoria
- Asignar el tipo de codificación para FSM (Finite State Machines, máquinas de estados finitos)
- Priorizar el rendimiento, la utilización o la energía
- Aplicar optimizaciones avanzadas como la retemporización lógica
- Convertir relojes cerrados para registrar señales de habilitación
- Opciones de compilación
La síntesis lógica de Vivado admite todos los niveles de personalización, desde la operación de pulsadores hasta la exploración de diferentes estrategias de compilación.
Síntesis lógica:
- Funciona con proyectos Vivado y flujos no relacionados con proyectos
- Se puede ejecutar de forma interactiva o en modo por lotes utilizando Tcl
- Ejecuta múltiples procesos para reducir los tiempos de compilación
- Proporciona estrategias de compilación con el propósito de explorar soluciones para diferentes objetivos de diseño
- Admite un modo de compilación incremental que reutiliza datos de ejecuciones anteriores para acelerar las iteraciones de compilación
Metodología de diseño
Cuando se utiliza con Vivado, la metodología UltraFast ayuda a definir las restricciones adecuadas, ayuda a conducir correctamente las herramientas y analizar los resultados, y mejora la productividad general. La metodología de diseño UltraFast™ es una colección de prácticas recomendadas de diseño de hardware acumuladas de muchos años de experiencia de expertos de Vivado y sus éxitos en el cierre de diseños de clientes que van más allá de los límites de las herramientas y la tecnología.
Zoom de imagen
Características principales
Metodología integrada
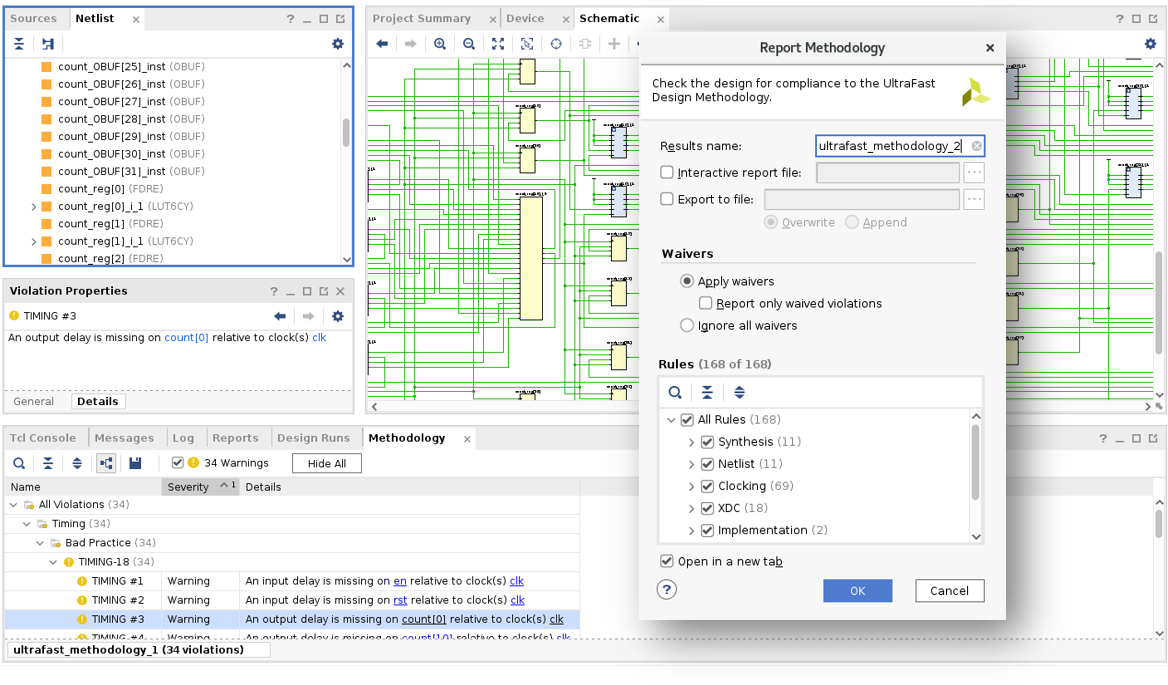
Para facilitar el cumplimiento de las directrices de la metodología UltraFast, los informes de esta metodología se integran en Vivado y se generan de manera predeterminada para los proyectos Vivado, lo que proporciona los beneficios de UltraFast sin leer una sola línea de documentación. La función de metodología de informes genera una lista de infracciones de la metodología encontradas en el diseño actual, desglosadas por categoría y nivel de gravedad para la revisión interactiva. La revisión y el abordaje de las infracciones de la metodología garantiza que los diseños tengan el punto de partida óptimo para la implementación, lo que brinda las mayores posibilidades de cierre exitoso del diseño en el menor tiempo posible. Las infracciones que se consideren aceptables pueden ignorarse para que no vuelvan a aparecer en los informes.
Proporcionar restricciones completas y correctas es una parte importante de la metodología UltraFast. El TCW (Timing Constraints Wizard, asistente de restricciones de temporización) analiza las restricciones de temporización y proporciona orientación paso a paso sobre cómo suministrar restricciones faltantes y corregir restricciones no válidas. La integridad de las restricciones reduce las posibilidades de errores de hardware resultantes de rutas de temporización sin restricciones, mientras que las restricciones no válidas pueden desviar el esfuerzo de compilación hacia una criticidad de temporización falsa.
La calidad de las restricciones de energía es fundamental para un análisis preciso de la energía. Power Constraints Advisor analiza la actividad de conmutación de diseño, identifica áreas que parecen estar mal especificadas y genera restricciones de energía de XDC de uso inmediato para un análisis adecuado. Los informes de energía de Vivado también incluyen un nivel de confianza que indica una especificación de restricción de energía de baja, media o alta calidad, lo que proporciona información sobre la integridad de la restricción de energía. Un alto nivel de confianza garantiza el análisis de energía más preciso, que coincide estrechamente con las mediciones de hardware.
Implementación
La implementación de Vivado es la herramienta de colocación y enrutamiento para dispositivos AMD, que genera secuencias binarias e imágenes de dispositivos a partir de una lista de conexiones sintetizada. La implementación permite la creación de plataformas y diseños personalizados de todos los tamaños, desde los MPSoC más pequeños hasta los dispositivos monolíticos y de tecnología de interconexión de chips apilados (SSIT) más grandes que contienen millones de celdas lógicas. La implementación de Vivado se basa en algoritmos avanzados de particionamiento, colocación y enrutamiento guiados por predictores basados en aprendizaje automático. La aplicación de modelos de AA permite que la implementación logre una mayor QoR (Quality-of-Results, calidad de los resultados) en menos tiempo con una predicción precisa de retrasos en el enrutamiento y congestión. La implementación es impulsada por XDC (restricciones de diseño de Xilinx) para cumplir con los objetivos de diseño de rendimiento, utilización, energía y trabajos de síntesis dentro de proyectos Vivado y scripting Tcl.
La implementación admite todos los modos de operación, desde el modo de pulsador para facilitar el uso hasta sofisticadas recetas de Tcl personalizadas para manipular diseños con los requisitos de rendimiento más exigentes. El análisis detallado de temporización, utilización, energía y otras métricas de calidad de diseño se puede realizar en cualquier etapa de la compilación: antes de la colocación, después de la colocación y después del enrutamiento. La base de datos de diseño también se puede guardar y restaurar en cualquier etapa de la compilación utilizando archivos de DCP (Design Checkpoint, punto de control de diseño) y el diseño se puede visualizar y restringir en consecuencia.
Zoom de imagen
Características principales
-
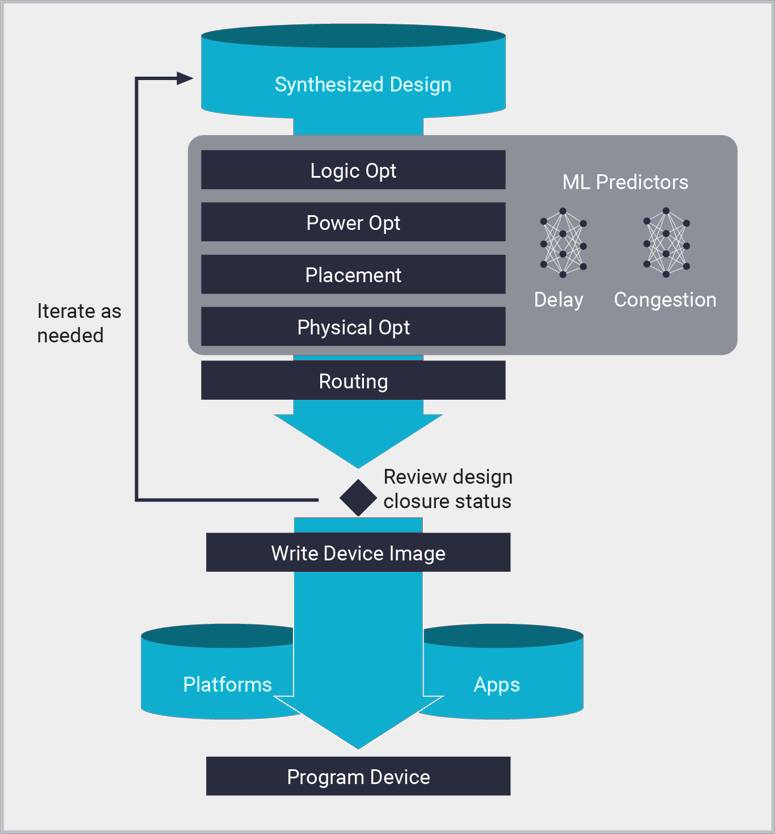
Procesos de implementación de Vivado
- Optimización lógica:
Después de la síntesis, la lista de conexiones lógicas se optimiza aún más a nivel global para reducir la utilización y los niveles lógicos.
- Optimización de energía:
La energía de diseño se reduce utilizando técnicas de activación de actividad, sin intervención requerida y sin cambios en la funcionalidad, y con un impacto mínimo de tiempo.
- Colocación:
Las celdas de la lista de conexiones lógicas se colocan en los recursos del dispositivo físico de acuerdo con las restricciones de XDC que incluyen temporización, plano de planta y requisitos de colocación manual. La colocación comienza con recursos globales, incluidos los recursos de E/S y reloj y los clústeres lógicos basados en la jerarquía de diseño. La fase global de colocación es seguida por las fases detalladas de colocación y optimización posterior a la colocación. La colocación es guiada por modelos de AA que predicen los retrasos y la congestión en el enrutamiento, lo que proporciona una mayor precisión y una compilación más rápida en comparación con los métodos estadísticos tradicionales.
- Enrutamiento:
Las conexiones entre los componentes de la lista de conexiones se asignan a los recursos de interconexión de dispositivos físicos. De manera similar a la colocación, el enrutamiento comienza con recursos globales como E/S y reloj y, luego, prioriza las asignaciones de recursos de acuerdo con las restricciones de tiempo de XDC. Las fases finales de enrutamiento optimizan aún más las rutas para cumplir con los requisitos de configuración y retención de cierre de sesión. La congestión del enrutamiento se reduce mediante el uso de predicción de congestión de enrutamiento por ML durante la colocación.
- Optimización física:
La optimización física es un proceso basado en el tiempo que se produce a lo largo de la colocación y el enrutamiento. A diferencia de la optimización lógica, la optimización física utiliza los datos de temporización más precisos disponibles en función de la colocación y el enrutamiento. El impacto en el tiempo se evalúa de tal manera que solo la optimización realizada dé como resultado una mejora de temporización. Las técnicas de optimización incluyen replicación, retemporización y reubicación de registro, así como otras optimizaciones específicas para la arquitectura de destino. La optimización física también se puede ejecutar por separado después de la colocación y después del enrutamiento para mejorar aún más los resultados.
- El centro de capacidades de análisis:
Un diseño puede analizarse en cualquier etapa de compilación dentro de la implementación. Un sistema integral de administración de restricciones de XDC que permite la modificación y la verificación de temporización, energía y restricciones físicas.
- Resumen de temporización del informe:
Un potente analizador de temporización estático que admite las restricciones de XDC para impulsar la implementación hacia objetivos de temporización específicos. Genera informes de temporización de rutas fundamentales, interacción de reloj y CDC (Clock Domain Crossings, cruces de dominio de reloj).
- Energía del informe:
Propagación sin vectores que admite la actividad de conmutación de XDC para el análisis de energía. Genera informes para identificar áreas de mayor consumo energético.
- Vista de dispositivo:
Una representación gráfica de la colocación y el enrutamiento del diseño, junto con esquemas de listas de conexiones lógicas. Permite el cross-probing (sondeo cruzado) entre vistas de diseño de código físico, lógico y fuente para rastrear rápidamente las fuentes de rutas de temporización fundamentales.
-
Opciones de compilación
- Implementación de Vivado
Es compatible con todos los niveles de personalización, desde la operación de pulsadores hasta la exploración de diferentes estrategias de compilación y flujos iterativos para diseños con requisitos difíciles de cumplir.
- Implementación
- Funciona con proyectos Vivado y flujos no relacionados con proyectos
- Se puede ejecutar de forma interactiva o en modo por lotes utilizando Tcl
- Ejecuta múltiples subprocesos para reducir los tiempos de compilación
- Proporciona estrategias de compilación con el propósito de explorar soluciones para diferentes objetivos de diseño
- Admite un modo de compilación incremental que reutiliza datos de ejecuciones anteriores que pueden priorizar la aceleración de la compilación o el cierre de temporización