
-
Vivado IP Integrator 主要功能與優點
- Vivado 整合設計環境中的緊密整合
- 將 IP integrator 階層式子系統無縫整合到整體設計中
- 快速擷取和打包 IP Integrator 設計,以供重複使用
- 支援圖形化和 TCL 式的設計流程
- 多個設計視圖之間的快速模擬和交互定位
- 支援所有設計領域
- 支援處理器或無處理器設計
- 整合演算法(Vitis HLS 和模型編輯器)和 RTL 層級 IP
- 結合數位訊號處理 (Digital Signal Processing, DSP)、影片、類比、嵌入式、連線能力和邏輯
- 支援以專案為基礎的動態功能交換 (Dynamic Function eXchange, DFX) 流程
- 專為設計人員的工作效率打造
- 支援在設計組裝過程中,對複雜介面層級連線進行 DRC
- 識別和修正常見設計錯誤
- 將 IP 參數自動同步套用到互連的 IP
- 系統層級最佳化
- 自動化設計者協助
- 增強的協作支援
- 增強的協作支援
- 使用 Block Design Container 的跨團隊協作式設計,實現了可重複使用性和模組化設計
- 改善修訂版控制,將來源檔案與生成的檔案分開
- 提供 Block Design Diff 工具,用以比較兩款區塊設計
概述
AMD Vivado™ 支援以傳統硬體描述語言 (Hardware Description Language, HDL) 進行設計輸入,如超高速積體電路硬體描述語言 (Very High-Speed Integrated Circuit Hardware Description Language, VHDL) 和 Verilog。它也支援稱為 IP Integrator (IPI) 的圖形使用者介面工具,提供即插即用的 IP 整合設計環境。
Vivado 為現今複雜的現場可程式化閘陣列 (Field Programmable Gate Array, FPGA) 和晶片上系統 (System-on-Chip, SoC) 提供同類最佳的合成與實作能力,並具有時序收斂與方法的內建功能。
Vivado 預設流程中提供的 UltraFast™ Methodology 報告 (report_methodology) 可幫助使用者限制設計、分析結果並收斂時序。
功能
以下是 Vivado™ Design Suite 設計輸入及實作功能的快速概覽。按一下其他索引標籤,以查看完整的功能詳細資料。
- IP Integrator
- 邏輯合成
- 設計方法
- 實作
IP Integrator
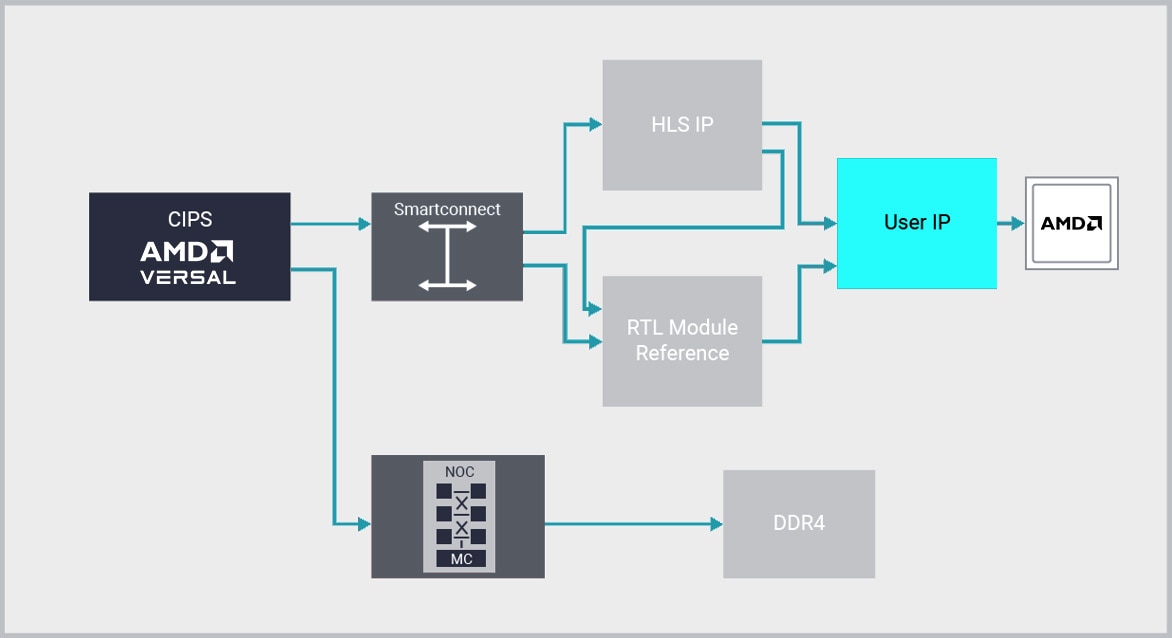
AMD Vivado™ 以其 IP Integrator 功能,提供業界第一個即插即用的 IP 整合設計環境,突破 RTL 設計工作效率屏障。
Vivado IP Integrator 提供圖形化和以工具命令語言 (Tool Command Language, TCL) 為基礎、設計修正並行的設計開發流程。它提供一個器件和平台感知的互動式環境,支援關鍵 IP 介面的智慧型自動連接、一鍵式 IP 子系統生成、即時設計規則檢查 (Design Rule Checking, DRC),以及介面變更同步套用,並結合強大的除錯功能。
連接不同 IP 時,設計人員是在「介面」而不是「訊號」抽象化層級進行作業,可大幅提高工作效率。通常,這種方法是使用業界標準的 AXI4 介面,但 IP Integrator 也支援許多其他介面。
設計團隊在介面層級上進行作業的優點是可以快速組裝使用 IP 的複雜系統,無論是運用 Vitis HLS 或模型編輯器建立而成的 IP、AMD SmartCore™ 或 LogiCORE™ IP、第三方合作廠商的 IP,還是團隊自行開發的 IP。透過 Vivado IP Integrator (IP Integrator, IPI) 和高階合成 (High-level synthesis, HLS) 的搭配使用,在與 RTL 方法相較之下,客戶可節省高達 15 倍的開發成本。
影像縮放
邏輯合成
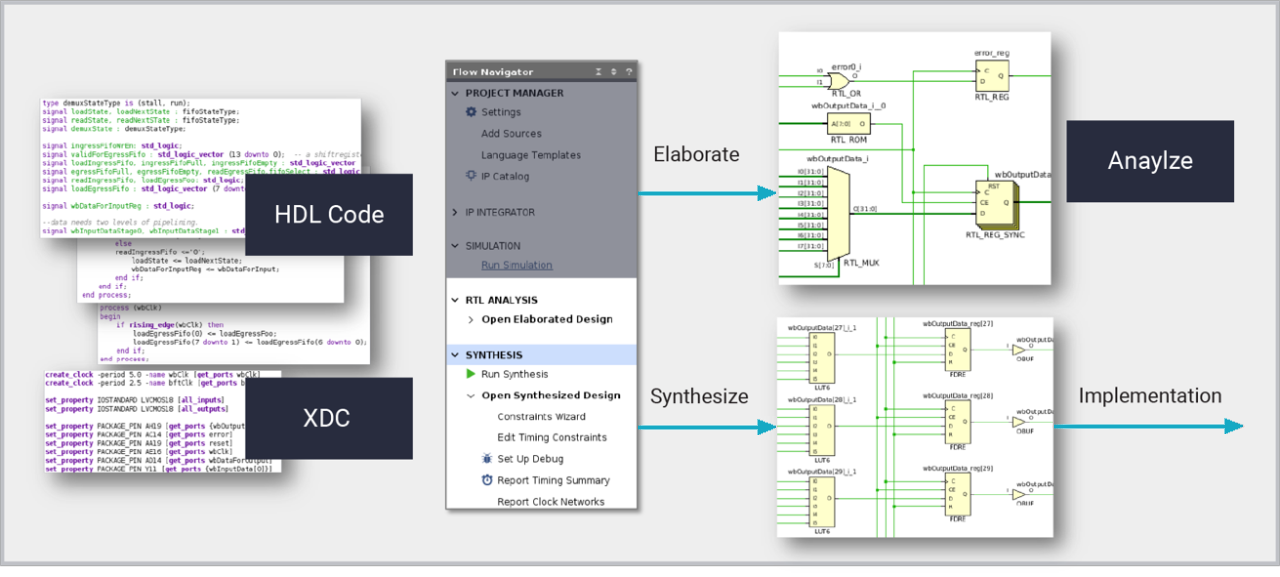
Vivado 邏輯合成是一種設計建立工具,讓硬體設計人員能夠針對所有最新的 AMD 器件,製作最佳平台、IP 和客製設計。邏輯合成會將以 SystemVerilog、VHDL 和 Verilog 編寫的暫存器傳輸層 (RTL) 設計,轉換為由程式庫邏輯單元組成的合成網路連線表,以用於下游實作。由於具備感知目標技術的能力,合成功能可將 RTL 描述直接對映至專用晶片結構,包括 LUTRAM、區塊 RAM、移位暫存器、加法器和減法器,以及 DSP 區塊,然後從這些描述中推論出相應的函數。最後 Vivado 會以設計目標為依歸,根據屬性、工具選項和賽靈思設計限制 (XDC) 來產出合成結果。邏輯合成可在 Vivado 專案和 TCL 腳本編寫模式中運作,為生成 RTL 描述的其他高階設計方法,包括高階合成和 IP Integrator,提供了堅實的基礎。
邏輯合成導入機器學習,可協助加快編譯速度。透過預測設計中不同部分所需的合成最佳化,ML 模型可以提高整體效率。
影像縮放
-
主要功能
- 語言支援
邏輯合成支援符合業界標準的最新可合成結構:
- SystemVerilog、Verilog、VHDL 和 VHDL-2008 硬體描述語言 (HDL)
- 能夠在同一設計中混合不同 HDL 類型,並將參數和泛型傳遞給每種類型
- 語言範本可確保將推論的複雜函數,可靠地對映至合適的器件資源
用詳細的設計示意圖,以視覺化的方式呈現 HDL 描述,且支援相關 HDL 原始程式碼的交互定位。- 最佳化控制
設計人員可控制邏輯合成推論和最佳化的所有層面。可針對以下階層進行指派:
- 全域,使用工具和指令選項
- 特定模組或邏輯階層實體,使用 BLOCK_SYNTH XDC 限制
- 單元和網路,使用 HDL 屬性
控制類型包括:- 保持、平坦化和重建階層
- 推論或不推論特定技術的結構
- 選取用於對映記憶體陣列的專用記憶體資源類型
- 為有限狀態機 (FSM) 指派編碼類型
- 將優先目標設為效能、使用率或功耗
- 套用進階最佳化,例如邏輯重定時
- 將閘控時脈轉換為暫存器啟用訊號
- 編譯選項
Vivado 邏輯合成支援從按鈕式操作到探索不同編譯策略等每種層級的客製化。
邏輯合成:
- 可與 Vivado 專案和非專案流程搭配使用
- 可以互動方式執行,也可使用 TCL 在批次模式中執行
- 可執行多個流程以減少編譯時間
- 可提供編譯策略,以探索不同設計目標的解決方案
- 支援漸進式編譯模式,重複使用以前執行的資料,以加快編譯迭代
設計方法
當與 Vivado 搭配使用時,UltraFast Methodology 有助於定義適當的限制、正確地驅動工具和分析結果,並提高總體生產力。UltraFast™ 設計方法集結了 Vivado 專家多年的經驗,以及其在客戶設計方面成功收斂設計的最佳硬體設計實務,是突破工具和技術極限的絕佳利器。
影像縮放
主要功能
內建方法
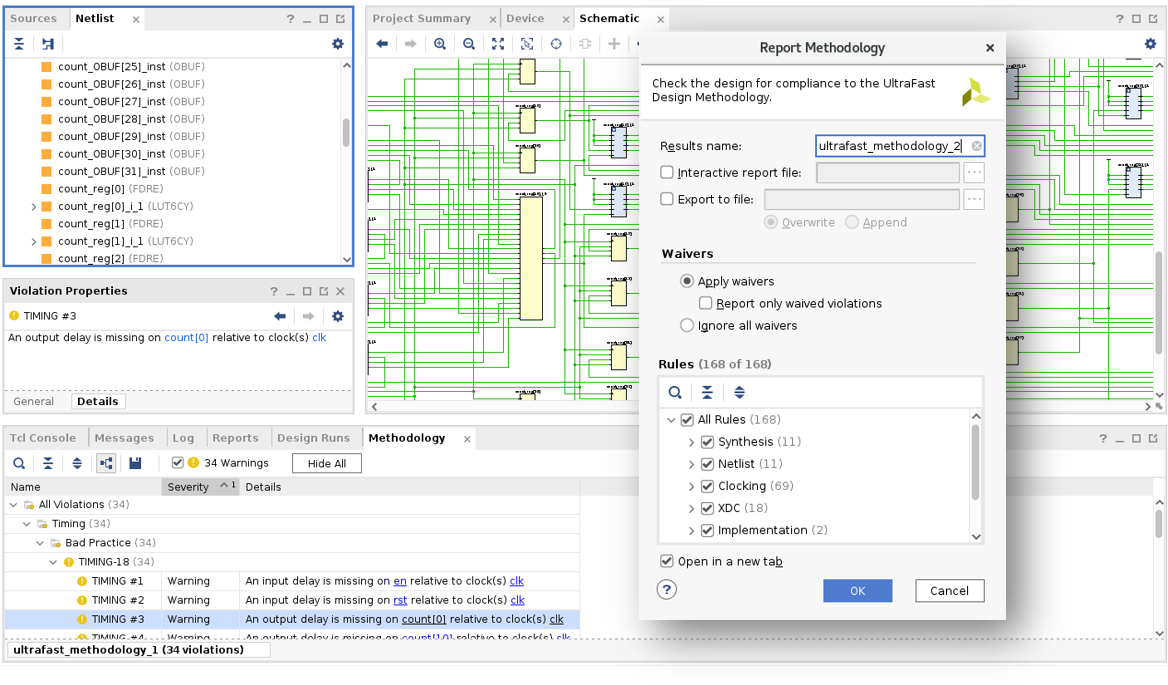
為促進 UltraFast Methodology 準則的遵守工作,Vivado 內建 UltraFast Methodology 報告功能,並預設針對 Vivado 專案生成報告,讓您無須閱讀任何文件內容,即可享有 UltraFast 優勢。針對在目前設計發現的方法違規,報告方法功能可生成清單,並依據類別和嚴重程度加以細分,以便進行互動式檢閱。檢閱並處理方法違規問題,不僅可確保設計贏在實作的起跑點起點,在最短時間內實現成功設計收斂的可能性也最高。被視為可接受的違規行為,可透過放棄剔除於報告之中。
提供完整且正確的限制是 UltraFast Methodology 中重要的一環。Timing Constraints Wizard (TCW) 可分析時序限制,並提供有關供應所缺限制和修正無效限制的逐步指引。限制之完整可減少因不受限制的時序路徑所導致的硬體錯誤機率,而無效的限制則可能會將編譯工作誤導至錯誤的時序關鍵性。
功耗限制品質對於準確的功率分析至關重要。Power Constraints Advisor 會分析設計切換活動、找出可能未正確指定的區域,並生成統包式 XDC 功耗限制,以進行正確分析。Vivado 功率報告還提供信賴水準,用於表示功耗限制規格品質是高,是中,是低,進而對功耗限制完整性提供回饋。高信賴水準能確保最準確的功率分析,並與硬體測量高度相符。
實作
Vivado 實作是 AMD 器件的佈局和佈線工具,可從合成網路連線表生成位元流和器件映像。透過實作,設計人員可以建立各種規模的平台和客製設計,最小可小至多處理器晶片上系統 (Multiprocessor system-on-chip, MPSoC),最大則上達內含數百萬邏輯單元的單體和晶片堆疊互連技術 (SSIT) 器件。Vivado 實作以先進分區、佈局和佈線演算法為基礎,由機器學習型預測模型引導。ML 模型的運用可讓實作準確預測佈線延遲和壅塞,在更短的時間內,實現更高的結果品質 (QoR)。實作會根據賽靈思設計限制 (XDC),在 Vivado 專案和 TCL 腳本編寫模式中,達到效能、使用率、功耗和合成作業設計目標。
實作支援所有操作模式,從易於使用的按鈕模式到複雜的客製化 TCL 程式庫都有支援,可處理效能要求最為嚴苛的設計。可在任何編譯階段(佈局前、佈局後和佈線後)執行時序、使用率、功耗和其他設計品質指標的詳細分析。此外,也可在任何編譯階段中使用設計檢查點 (DCP) 檔案,來儲存和還原設計資料庫,同時還可以對設計進行相應的視覺化和限制。
影像縮放
主要功能
-
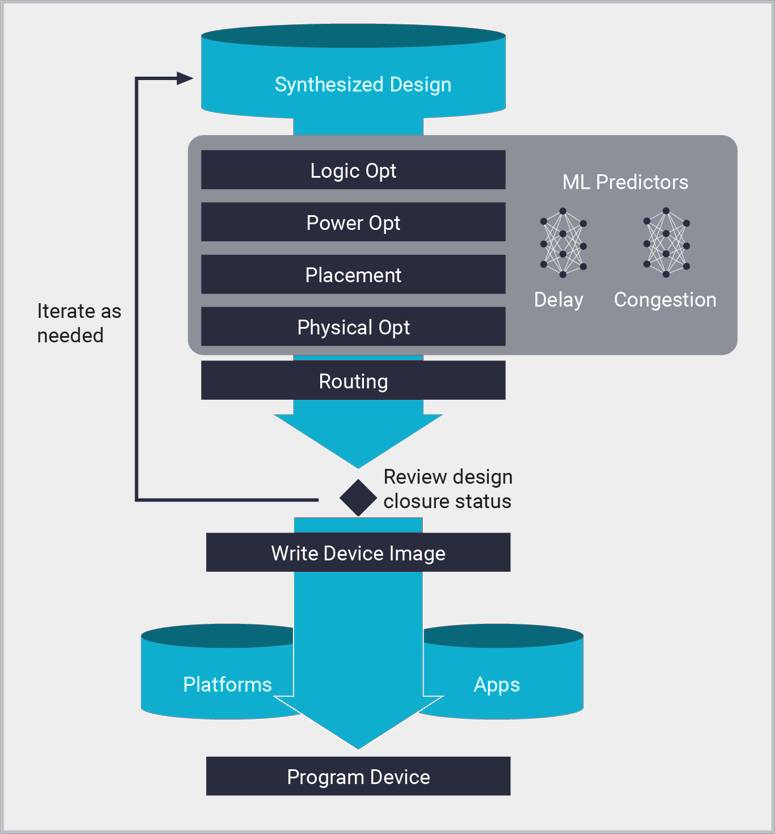
Vivado 實作流程
- 邏輯最佳化:
合成後,會在全域層級進一步將邏輯網路連線表最佳化,以降低使用率並減少邏輯分層。
- 功耗最佳化:
使用活動閘控技術降低設計功耗,無須干預也無須變更功能,同時還能大幅降低時序影響。
- 佈局:
根據 XDC 限制(包括時序、布局規劃和手動佈局要求),將邏輯網路連線表單元放置到實體器件資源中。佈局會從全域資源開始實施,包括 IO 和時脈資源,以及以設計階層為基礎的邏輯叢集。全域佈局階段之後,是詳細的佈局和佈局後最佳化階段。佈局由預測佈線延遲和預測佈線壅塞的 ML 模型指引,與傳統統計方法相比,前者的準確性更高,編譯速度也更快。
- 佈線:
亦即將網路連線表元件之間的連線關係指派給實體器件互連資源。與佈局類似,佈線從全域資源(例如 IO 和時脈)開始實施,然後根據 XDC 時序限制,確定資源指派的優先順序。最終佈線階段會進一步將路線最佳化,以滿足最後一關的設置時間與保持時間要求。透過在佈局過程中使用 ML 佈線壅塞預測,進而減少佈線壅塞。
- 實體最佳化:
實體最佳化是一種時序驅動型流程,在整個佈局和佈線過程中都會發生。與邏輯最佳化不同,實體最佳化使用的是最準確的時序資料,而且是直接根據設計的佈局與佈線。它會對時序影響進行評估,確保其所執行的最佳化一律只會對時序產生正面效益。最佳化技術包括複製、重定時、暫存器重新佈局,以及其他針對特定目標架構的最佳化。實體最佳化也可以在佈局後和佈線後單獨執行,以進一步改善結果。
- 分析功能的中心:
可在實作過程中的任何編譯階段對設計進行分析。全方位的 XDC 限制管理系統,允許修改和驗證時序、功耗和實體限制。
- 報告時序摘要:
功能強大的靜態時序分析工具,支援 XDC 限制,以將實作推向指定的時序目標。可生成關鍵時序路徑、時脈互動和跨時域 (CDC) 的時序報告。
- 報告功率:
無向量傳播,支援用於功率分析的 XDC 切換活動。可生成報告,以識別耗電量較高的區域。
- 器件視圖:
提供設計佈局和佈線的圖形化表示,以及邏輯網路連線表示意圖。可啟用實體、邏輯和原始程式碼設計檢視介面之間的交互定位,以快速追蹤關鍵時序路徑的來源。
-
編譯選項
- Vivado 實作
支援所有層級的客製化,從按鈕式操作到探索不同的編譯策略,以及嚴苛設計要求的迭代流程皆涵蓋在內。
- 實作
- 可與 Vivado 專案和非專案流程搭配使用
- 可以互動方式執行,也可使用 Tcl 在批次模式中執行
- 可執行多個執行緒以縮短編譯時間
- 可提供編譯策略,以探索不同設計目標的解決方案
- 支援重複使用先前執行中之資料的漸進式編譯模式,該模式可以優先處理編譯加速或時序收斂