
-
Principais recursos e benefícios do Vivado IP Integrator
- Perfeita integração dentro do ambiente de projeto incorporado do Vivado
- Inclusão contínua de subsistemas hierárquicos do IP Integrator no projeto geral
- Captura e empacotamento rápidos de projetos do IP Integrator para reutilização
- Suporte para fluxos de projeto gráficos e baseados em Tcl
- Simulação rápida e teste cruzado entre várias visualizações de projeto
- Suporte para todos os domínios de projeto
- Suporte para projetos com ou sem processador
- Integração de IP algorítmico (Vitis HLS e Compositor de modelos) e de nível RTL
- Combinação de DSP, vídeo, analógico, incorporado, conectividade e lógica
- Suporte para fluxo de DFX baseado em projeto
- Foco na produtividade do projetista
- DRCs em conexões complexas no nível de interface durante a montagem do projeto
- Reconhecimento e correção de erros comuns de projeto
- Propagação automática de parâmetros de IP para IP interconectado
- Otimizações no nível de sistema
- Assistência ao designer automatizada
- Suporte à colaboração avançada
- Suporte à colaboração avançada
- Os projetos baseados em equipe que usam o Block Design Container possibilitam a reutilização e projetos modulares
- Melhorias no controle de revisão que separam os arquivos de origem dos arquivos gerados
- Ferramenta Block Design Diff para comparar dois projetos de bloco
Visão geral
O AMD Vivado™ oferece suporte para a entrada de projeto no HDL tradicional, como VHDL e Verilog. Ele também oferece suporte a uma ferramenta baseada em interface gráfica do usuário chamada IP Integrator (IPI), que permite um ambiente de design de integração de IP plug-and-play.
O Vivado oferece melhor síntese e implementação para FPGAs e SoCs complexos da atualidade, com capacidades incorporadas para fechamento de tempo e metodologia.
O relatório da metodologia UltraFast™ (report_methodology) que está disponível no fluxo padrão do Vivado ajuda os usuários a restringir seu projeto, analisar resultados e fechar o tempo.
Recursos
Veja uma visão geral rápida dos recursos do Vivado™ Design Suite para entrada e implementação de projetos. Clique nas outras guias para obter detalhes completos do recurso.
- IP Integrator
- Síntese lógica
- Metodologia de projeto
- Implementação
IP Integrator
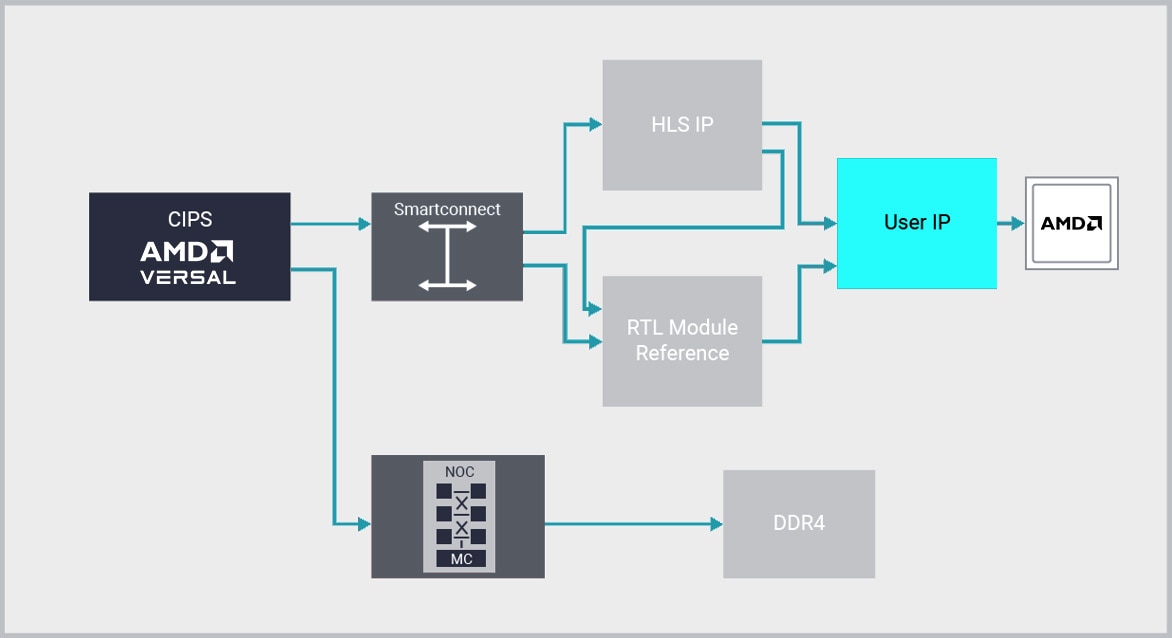
O AMD Vivado™ rompe a estagnação da produtividade de projeto de RTL fornecendo o primeiro ambiente de projeto de integração de IP plug-and-play da indústria, com seu recurso de IP Integrator.
O Vivado IP Integrator fornece um fluxo de desenvolvimento de projeto gráfico e baseado em Tcl, correto por construção. Ele fornece um ambiente interativo com reconhecimento de dispositivo e plataforma que oferece suporte à conexão automática inteligente das principais interfaces de IP, geração de subsistema IP com um clique, DRCs em tempo real e propagação de alterações de interface, combinados com uma poderosa capacidade de depuração.
Os projetistas trabalham no nível de abstração de "interface" e não de "sinal" ao fazer conexões entre IP, aumentando muito a produtividade. Muitas vezes, isso é feito usando interfaces padrão da indústria AXI4, mas dezenas de outras interfaces também são compatíveis com o IP Integrator.
Trabalhando no nível de interface, as equipes de projeto podem montar rapidamente sistemas complexos que aproveitam o IP criado com o Vitis HLS, Compositor de modelos, AMD SmartCore™ e LogiCORE™ IP, Alliance Member IP, bem como seu próprio IP. Ao aproveitar a combinação de Vivado IPI e HLS, os clientes estão economizando até 15X em custos de desenvolvimento em comparação com uma abordagem de RTL.
Ampliar imagem
Síntese lógica
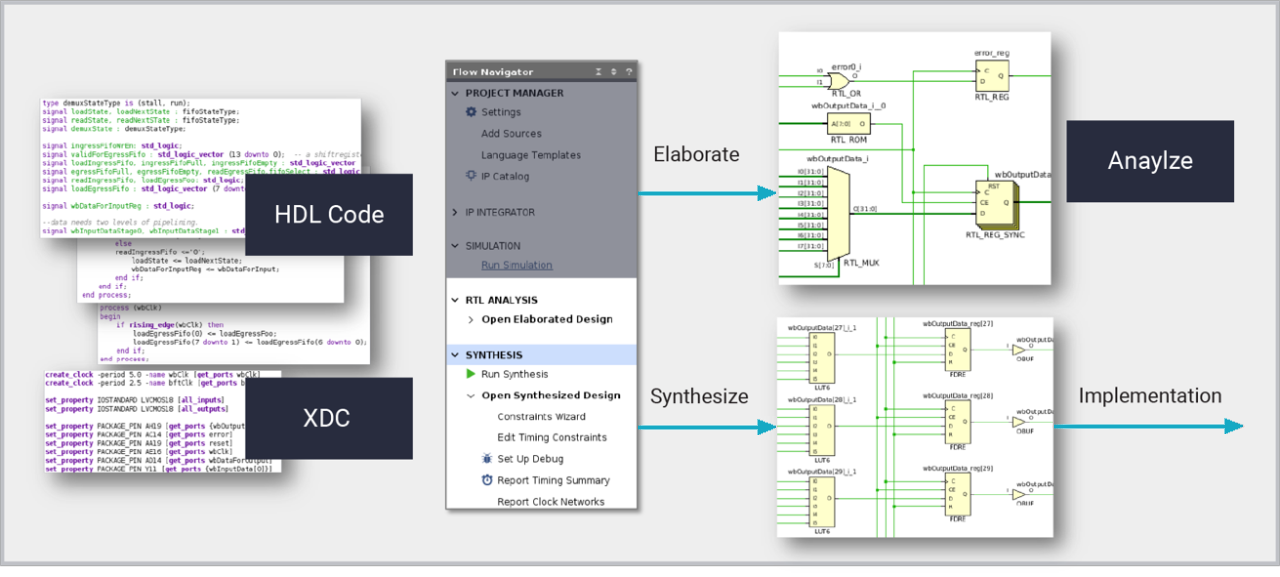
A síntese lógica do Vivado é uma ferramenta de criação de projeto que permite aos projetistas de hardware produzir plataformas, IP e projetos personalizados ideais para todos os dispositivos AMD mais recentes. A síntese lógica traduz os projetos de Nível de transferência de registro (RTL) escritos em SystemVerilog, VHDL e Verilog em uma netlist sintetizada de células da biblioteca para implementação subsequente. Estando ciente da tecnologia de destino, a síntese pode inferir funções de descrições de RTL que mapeiam diretamente para estruturas de chip dedicadas, incluindo LUTRAMs, RAMs de bloco, registros de mudança, somadores-subtratores e blocos de DSP. Os resultados da síntese são orientados usando atributos, opções de ferramentas e Restrições de projeto Xilinx (XDC) para atender às metas de projeto. A síntese lógica funciona dentro dos projetos do Vivado e dos scripts Tcl e fornece uma base sólida para outros métodos de projeto de alto nível que geram descrições de RTL, incluindo Síntese de alto nível e IP Integrator.
A síntese lógica introduziu o Aprendizado de máquina (Machine Learning, ML) para ajudar a acelerar a compilação. Os modelos de ML melhoram a eficiência geral ao prever as otimizações de síntese necessárias para diferentes partes do projeto.
Ampliar imagem
-
Principais recursos
- Suporte a linguagens
A síntese lógica suporta as mais recentes construções sintetizáveis consistentes com os padrões da indústria:
- Linguagens de descrição de hardware (HDLs) SystemVerilog, Verilog, VHDL e VHDL-2008
- Capacidade de misturar diferentes tipos de HDL no mesmo projeto e aprovar parâmetros e genéricos para cada tipo
- Modelos de linguagem para garantir o mapeamento confiável de funções complexas inferidas para recursos de dispositivo adequados
As descrições de HDL podem ser visualmente revisadas usando um esquema de projeto elaborado que realiza os testes cruzados para o código-fonte de HDL relacionado.- Controle de otimização
A síntese lógica fornece controle sobre todos os aspectos de inferência e otimização. As atribuições podem ser feitas:
- Usando globalmente as opções de ferramentas e comandos
- Em módulos específicos ou instâncias de hierarquia lógica usando a restrição XDC BLOCK_SYNTH
- Em células e redes usando atributos HDL
Os tipos de controle incluem:- Manter, nivelar e reconstruir a hierarquia
- Inferir ou não inferir estruturas específicas de tecnologia
- Selecionar o tipo de recursos de memória dedicados usados para mapear matrizes de memória
- Atribuir o tipo de codificação para máquinas de estado finito (FSMs)
- Priorizar desempenho, utilização ou energia
- Aplicar otimizações avançadas, como retemporização lógica
- Conversão de clocks bloqueados para registrar os sinais de ativação
- Opções de compilação
A síntese lógica do Vivado é compatível com todos os níveis de personalização, desde a operação por botão até a exploração de diferentes estratégias de compilação.
Síntese lógica:
- Trabalha com projetos do Vivado e fluxos não relacionados ao projeto
- Pode ser executado interativamente ou em modo de lote usando Tcl
- Executa vários processos para reduzir os tempos de compilação
- Fornece estratégias de compilação para explorar soluções para diferentes objetivos do projeto
- É compatível com um modo de compilação incremental que reutiliza dados de execuções anteriores para acelerar as iterações de compilação
Metodologia de projeto
Quando usada com o Vivado, a metodologia UltraFast ajuda a definir restrições adequadas, a orientar adequadamente as ferramentas e analisar os resultados, além de melhorar a produtividade geral. A metodologia de projeto UltraFast™ é um conjunto de práticas recomendadas de projeto de hardware acumuladas a partir de muitos anos de experiência dos especialistas Vivado e seus sucessos de fechamento de projeto em projetos de clientes que ultrapassam os limites das ferramentas e da tecnologia.
Ampliar imagem
Principais recursos
Metodologia incorporada
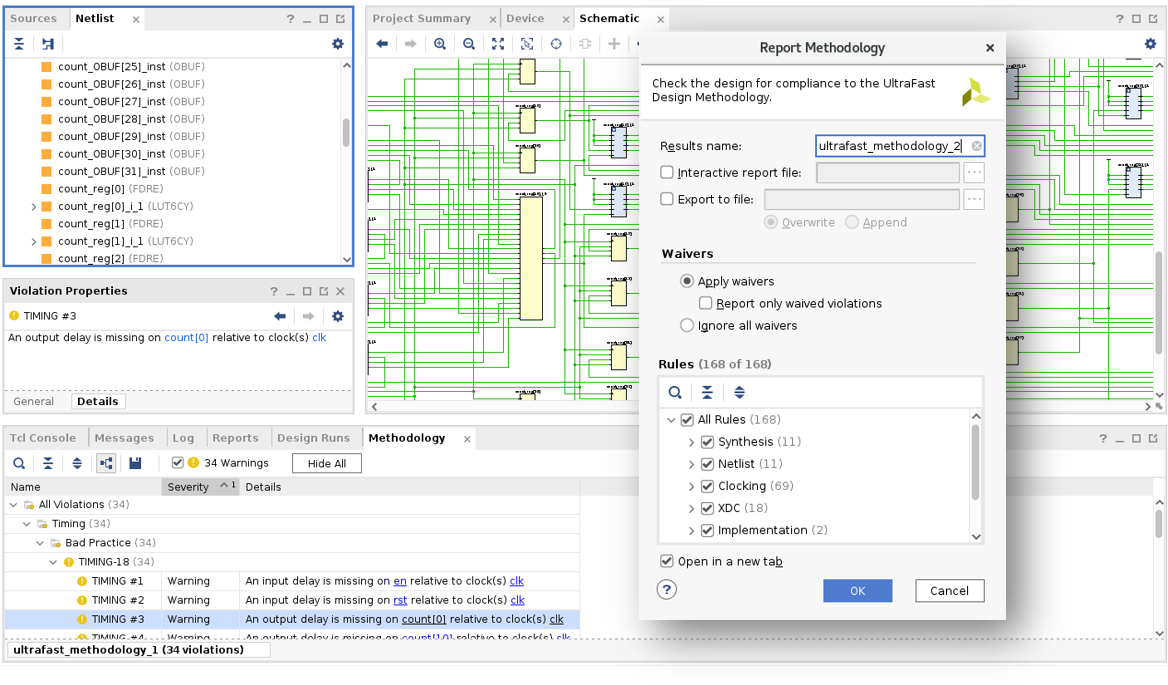
Para facilitar a conformidade com as diretrizes da metodologia UltraFast, os relatórios dessa metodologia são incorporados ao Vivado e gerados por padrão para projetos do Vivado, fornecendo os benefícios da UltraFast sem a leitura de uma única linha de documentação. O recurso Metodologia de relatório gera uma lista de violações de metodologia encontradas no projeto atual, divididas por categoria e nível de gravidade para revisão interativa. Revisar e abordar as violações da metodologia garante que os projetos recebam o ponto de partida ideal para implementação, oferecendo as maiores chances para um fechamento bem-sucedido do projeto no menor tempo possível. Violações consideradas aceitáveis podem ser dispensadas para que não reapareçam nos relatórios.
Fornecer restrições completas e corretas é uma parte importante da Metodologia UltraFast. O Assistente de restrições de tempo (TCW) analisa as restrições de tempo e fornece orientação passo a passo sobre como fornecer restrições ausentes e corrigir restrições inválidas. A integridade da restrição reduz as chances de bugs de hardware resultantes de caminhos de tempo sem restrições, enquanto restrições inválidas podem direcionar erroneamente o esforço de compilação para falsa criticidade de tempo.
A qualidade de restrição de energia é essencial para uma análise precisa do consumo de energia. O Power Constraints Advisor analisa a atividade de comutação de projeto, identifica áreas que parecem estar especificadas incorretamente e gera restrições de energia XDC prontas para uso para análise adequada. Os relatórios de energia do Vivado também incluem um nível de confiança que indica uma qualidade baixa, média ou alta da especificação de restrição de energia, fornecendo feedback sobre a integridade da restrição de energia. Um alto nível de confiança garante a análise de energia mais precisa, correspondendo de perto às medições de hardware.
Implementação
A implementação do Vivado é a ferramenta de posicionamento e roteamento para dispositivos AMD, gerando fluxos de bits e imagens de dispositivos a partir de uma netlist sintetizada. A implementação possibilita a criação de plataformas e projetos personalizados de todos os tamanhos, desde os menores MPSoCs até os maiores dispositivos monolíticos e de SSIT (Stacked Silicon Interconnect Technology) contendo milhões de células lógicas. A implementação do Vivado é baseada em algoritmos de particionamento, posicionamento e roteamento de última geração, orientados por indicadores baseados no Aprendizado de máquina. A aplicação de modelos de ML permite que a implementação alcance maior QoR (Qualidade dos resultados) em menos tempo, com uma previsão precisa dos atrasos de roteamento e congestionamento. A implementação é orientada pelas Restrições de projeto Xilinx (XDC) para atender às metas de projeto para desempenho, utilização e trabalhos de energia e síntese dentro dos projetos do Vivado e scripts Tcl.
A implementação é compatível com todos os modos de operação, do modo de botão para facilidade de uso a receitas Tcl personalizadas e sofisticadas para lidar com projetos com os requisitos de desempenho mais difíceis. Análises detalhadas de tempo, utilização, energia e outras métricas de qualidade de projeto podem ser realizadas em qualquer estágio de compilação: pré-posicionamento, pós-posicionamento e pós-roteamento. O banco de dados do projeto também pode ser salvo e restaurado em qualquer estágio de compilação usando arquivos de DPC (Design Checkpoint, ponto de verificação de projeto) e o projeto pode ser visualizado e restrito conforme necessário.
Ampliar imagem
Principais recursos
-
Processos de implementação do Vivado
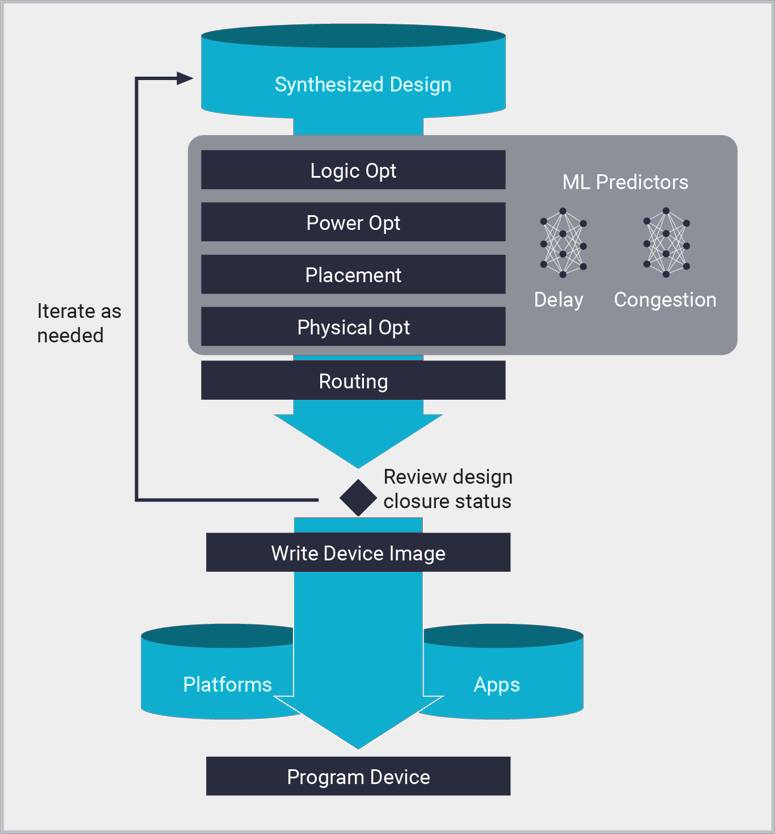
- Otimização lógica:
Após a síntese, a netlist lógica é otimizada ainda mais em nível global para reduzir a utilização e os níveis lógicos.
- Otimização de energia:
A energia do projeto é reduzida usando técnicas de controle de atividade, sem intervenção necessária e sem alterações na funcionalidade, e impacto mínimo no tempo.
- Posicionamento:
As células da netlist lógica são colocadas em recursos de dispositivos físicos de acordo com as restrições XDC, que incluem requisitos de tempo, plano de layout de circuito integrado e posicionamento manual. O posicionamento começa com recursos globais, incluindo recursos de E/S e clocking e clusters lógicos com base na hierarquia de projeto. A fase de posicionamento global é seguida pelas fases detalhadas de otimização de posicionamento e pós-posicionamento. O posicionamento é orientado por modelos de ML que preveem atrasos de roteamento e congestionamento de roteamento, o que fornece maior precisão e compilação mais rápida em comparação aos métodos estatísticos tradicionais.
- Roteamento:
As conexões entre os componentes da netlist são atribuídas a recursos de interconexão de dispositivos físicos. Semelhante ao posicionamento, o roteamento começa com recursos globais, como E/S e clocking, e depois prioriza as atribuições de recursos de acordo com as restrições de tempo XDC. As fases finais de roteamento otimizam ainda mais as rotas para atender aos requisitos de configuração e espera de aprovação. O congestionamento de roteamento é reduzido pelo uso da previsão de congestionamento de roteamento de ML durante o posicionamento.
- Otimização física:
A otimização física é um processo orientado por tempo que ocorre durante o posicionamento e o roteamento. Ao contrário da otimização lógica, a otimização física usa os dados de tempo mais precisos disponíveis com base no posicionamento e no roteamento. O impacto no tempo é avaliado de modo que apenas a otimização realizada resulta em um melhor tempo. As técnicas de otimização incluem replicação, retemporização e reposicionamento de registro, bem como outras otimizações específicas para a arquitetura de destino. A otimização física também pode ser executada separadamente após o posicionamento e após o roteamento para melhorar ainda mais os resultados.
- O centro das capacidades de análise:
Um projeto pode ser analisado em qualquer estágio de compilação dentro da implementação. Um sistema abrangente de gerenciamento de restrições XDC que permite a modificação e a verificação de restrições físicas, de tempo e de energia.
- Resumo do tempo do relatório:
Um poderoso analisador de tempo estático que oferece suporte a restrições XDC para orientar a implementação em direção a metas de tempo especificadas. Gera relatórios de tempo de caminhos de tempo críticos, interação de clock e cruzamentos de domínio de clock (CDCs).
- Energia do relatório:
Propagação sem vetor que oferece suporte à atividade de comutação XDC para análise de energia. Gera relatórios para identificar áreas de maior consumo de energia.
- Visualização do dispositivo:
Uma representação gráfica do posicionamento e do roteamento do projeto, juntamente com esquemas de netlist lógica. Possibilita o teste cruzado entre visualizações de projeto físico, lógico e de código-fonte para rastrear rapidamente as fontes de caminhos de tempo críticos.
-
Opções de compilação
- Implementação do Vivado
Ele oferece suporte a todos os níveis de personalização, desde a operação com botão até a exploração de diferentes estratégias de compilação e fluxos iterativos para projetos com requisitos difíceis de atender.
- Implementação
- Trabalha com projetos do Vivado e fluxos não relacionados ao projeto
- Pode ser executado interativamente ou em modo de lote usando Tcl
- Executa vários threads para reduzir os tempos de compilação
- Fornece estratégias de compilação para explorar soluções para diferentes metas do projeto
- É compatível com um modo de compilação incremental que reutiliza dados de execuções anteriores que podem priorizar a aceleração da compilação ou o encerramento de temporização