
-
Vivado IP インテグレーターの主な機能と利点
- Vivado 統合設計環境に密接統合
- IP インテグレーターの階層的サブシステムをデザインにシームレスに統合
- IP インテグレーター デザインをすばやく統合して再利用のためにパッケージ化
- グラフィカルおよび Tcl ベースのデザイン フローをサポート
- 迅速なシミュレーションおよび複数のデザイン ビューでクロスプロービングが可能
- あらゆるデザイン ドメインをサポート
- プロセッサを使用するデザインおよびプロセッサなしのデザインをサポート
- アルゴリズムの統合 (Vivado HLS および Model Composer) および RTL レベル IP の統合
- DSP、ビデオ、アナログ、エンベデッド、コネクティビティ、およびロジックの組み合わせ
- DFX フロー ベースのプロジェクトをサポート
- 設計者の生産性向上
- デザイン アセンブリ中に複雑なインターフェイス レベルの接続に対して DRC を実行
- 一般的な設計エラーの検証および修正
- 相互接続された IP へパラメーターを自動的に伝搬
- システム レベルの最適化
- 自動化された設計アシスト機能
- コラボレーション サポートを向上
- コラボレーション サポートを向上
- ブロック デザイン コンテナーを用いたチームベースの設計により、再利用性とモジュール設計を実現
- ソース ファイルと生成ファイルを分けることでリビジョン管理が改善
- 2 つのブロック デザインを比較するための Block Design Diff ツール
概要
AMD Vivado™ は、VHDL や Verilog などの従来の HDL を使用したデザイン入力をサポートしています。また、IP インテグレーター (IPI) という GUI ベースのツールもサポートしており、プラグアンドプレイの IP 統合デザイン環境を提供します。
Vivado は、最先端の複雑な FPGA および SoC 向けに最高レベルの合成/インプリメンテーション機能を提供し、タイミング クロージャやメソドロジのための設計を効率化する機能を提供します。
Vivado のデフォルト フローで利用できる UltraFast™ 設計手法レポート (report_methodology) は、デザインへの制約の適用、結果の分析およびタイミング クロージャの達成に有効です。
機能
Vivado™ Design Suite のデザイン入力とインプリメンテーション機能について簡単に説明します。各機能の詳細は、タブをクリックしてください。
- IP インテグレーター
- ロジック合成
- 設計手法
- インプリメンテーション
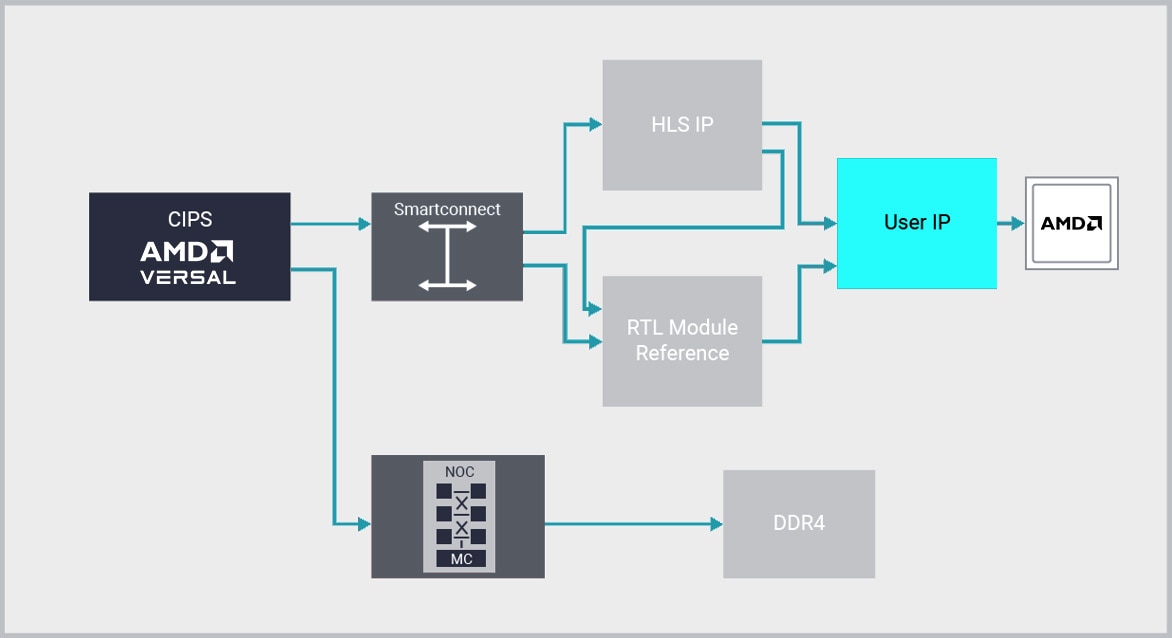
IP インテグレーター
AMD Vivado™ は、業界初のプラグアンドプレイ IP を使用する統合設計環境を提供し、その IP インテグレーター機能を活用することによって、従来の RTL 設計の限界を超える優れた生産性をもたらします。
Vivado IP インテグレーターは、グラフィカルおよび Tcl ベースで、検証しながら開発を進めることができるデザイン開発フローを提供します。この機能は、主要 IP インターフェイスの自動接続、ワンクリックでの IP サブシステム生成、リアルタイム DRC、インターフェイス変更伝搬、そして高性能デバッグ機能の併用をサポートする、デバイスとプラットフォームに対応できる対話型の環境です。
設計者は、IP 間の接続を行う際に信号レベルのアブストラクションではなく、インターフェイス レベルで対応できるため、生産性が劇的に向上します。多くの場合、AXI4 インターフェイス規格を使用しますが、IP インテグレーターでは、その他にもさまざまなインターフェイスがサポートされています。
インターフェイス レベルで作業を進められるため、デザイン チームは、Vitis HLS や Model Composer、AMD SmartCore™、LogiCORE™ IP、アライアンス メンバー IP、あるいはユーザーが独自に開発した IP を利用する複雑なシステムをすばやく組み立てることができます。Vivado の IP インテグレーターおよび HLS 機能を組み合わせて利用することによって、RTL デザインより最大 15 倍の開発コスト削減が可能です。
画像を拡大
ロジック合成
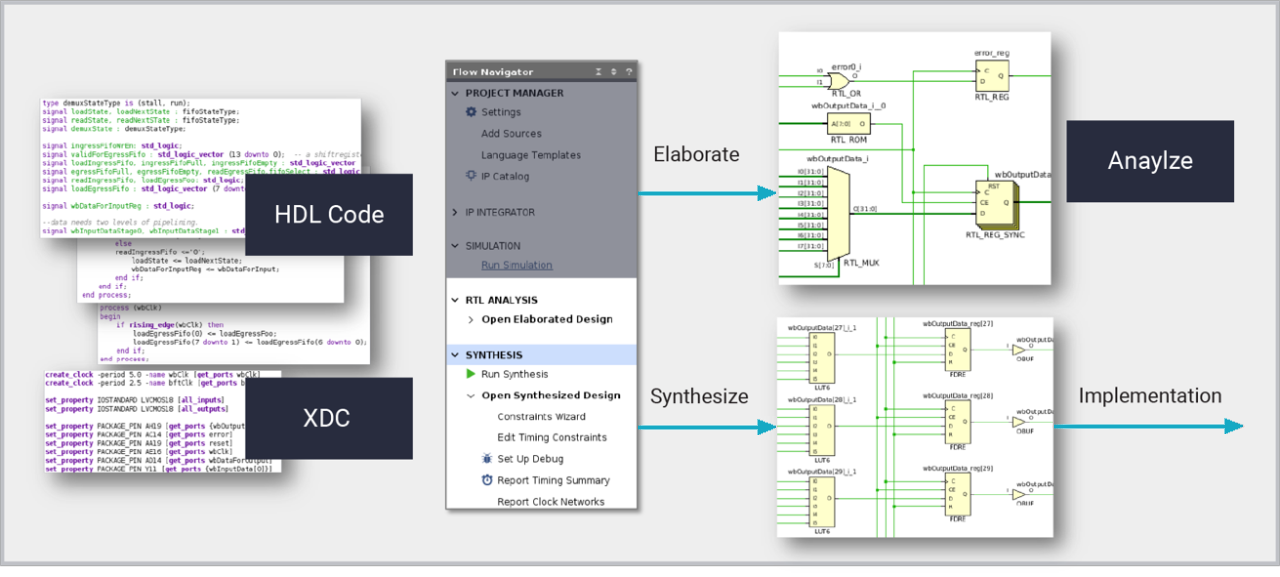
Vivado 論理合成は、すべての最新 AMD デバイスを対象とするデザイン作成ツールであり、最適なプラットフォーム、IP、カスタム デザインを作成できます。論理合成は、SystemVerilog、VHDL、Verilog で記述された RTL (レジスタ転送レベル) デザインを、ダウンストリーム インプリメンテーション用にライブラリ セルの合成済みネットリストに変換します。合成はターゲット テクノロジを認識するため、専用のシリコン構造 (LUTRAM、ブロック RAM、シフト レジスタ、 加算器/減算器、DSP ブロック) に直接マップする RTL 記述から関数を推論できます。デザインの目標を達成するために、属性、ツール オプション、XDC 制約を使用して合成結果が出力されます。論理合成は Vivado プロジェクトや Tcl スクリプト内で動作し、高位合成や IP インテグレーターなど、RTL 記述を生成するその他の高位設計手法のための強固な基盤を提供します。
論理合成には、コンパイル時間を短縮するために機械学習を導入しました。ML モデルは、デザインのあらゆる部分に対して合成の最適化を予測することで、全体的な効率を向上させます。
画像を拡大
-
主な特長
- 言語サポート
論理合成では、業界標準に準拠した最新の合成可能な構造をサポートしています。
- SystemVerilog、Verilog、VHDL、VHDL-2008 ハードウェア記述言語 (HDL)
- 同一デザインに異なるタイプの HDL を混在させ、それぞれのタイプにパラメーターとジェネリック文を渡すことが可能
- 推論された複雑な関数を適切なデバイス リソースに確実にマッピングするための言語テンプレート
エラボレート済みデザインの回路図を使用することで HDL 記述を可視化でき、関連する HDL ソース コードにクロスプローブできます。- 最適化制御
論理合成は、推論と最適化のすべての側面を制御します。次の割り当てが可能です。
- ツールやコマンド オプションを使用してグローバルに割り当てる
- BLOCK_SYNTH XDC 制約を使用して論理階層の特定モジュールまたはインスタンスに割り当てる
- HDL 属性を使用してセルやネットに割り当てる
制御の種類:- 階層を維持、フラット化、再構築する
- テクノロジ固有の構造を推論する/推論しない
- メモリ アレイのマッピングに使用する専用のメモリ リソース タイプを選択する
- 有限ステート マシン (FSM) のエンコーディング タイプを割り当てる
- 性能、使用率、消費電力に優先順位を付ける
- 論理リタイミングなどの高度な最適化を適用する
- ゲーテッド クロックをレジスタ イネーブル信号へ変換する
- コンパイル オプション
Vivado 論理合成は、プッシュボタン操作の簡単なフローから、異なるコンパイル ストラテジを使用して模索するフローまであらゆるレベルのカスタマイズをサポートします。
論理合成:
- Vivado プロジェクト フローと非プロジェクト フローをサポート
- 対話形式または Tcl スクリプトを使用してバッチ モードで実行
- 複数のプロセスを実行してコンパイル時間を短縮
- さまざまなデザイン目標のソリューションを探求するためのコンパイル ストラテジを提供
- 以前の実行からのデータを再利用してコンパイル時間を短縮するインクリメンタル コンパイル モードをサポート
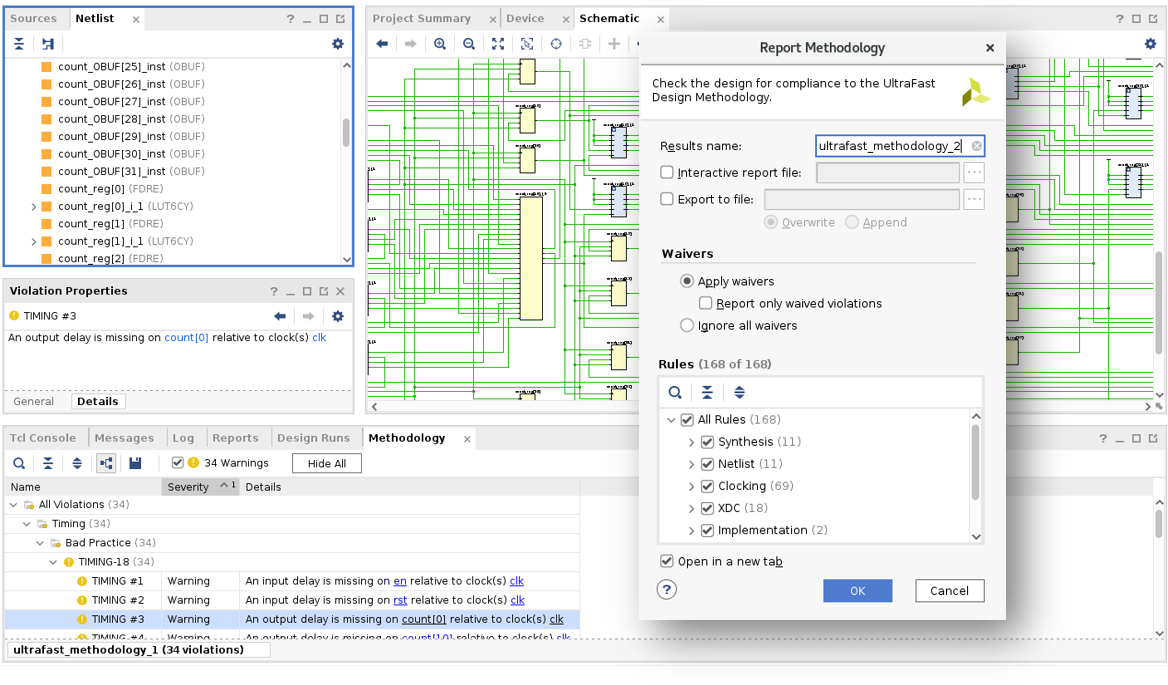
設計手法
Vivado 環境で UltraFast 設計手法を使用することで、適切な制約を定義し、ツールを起動して正しく結果を分析できるため、全体的な生産性を向上させることができます。UltraFast™ 設計手法とは、Vivado エキスパートたちが長年培ってきた経験と、ツールやテクノロジを駆使したカスタマー デザインのデザイン クロージャ成功事例に基づいた最善の設計ガイドラインです。
画像を拡大
主な特長
ビルトイン設計手法
UltraFast 設計手法ガイドラインに従った設計をサポートするため、Vivado には UltraFast 設計手法レポートが組み込まれています。Vivado プロジェクトに対応するレポートがデフォルトで生成されるため、資料を一切読まずに UltraFast の機能を活用できます。Report Methodology 機能によって、現デザインで検出された設計手法の違反リストが生成され、これらはすぐに確認できるようにカテゴリ別と重要度別に分類されます。設計手法の違反内容を確認して対処することで、インプリメンテーション プロセスを進めることができ、最短時間でデザイン クロージャを達成できる可能性が高くなります。容認できると判断された違反については、今後レポートされないように無効化できます。
UltraFast 設計手法の重要な項目の一つに、完全かつ正確な制約を指定することがあります。タイミング制約ウィザード (TCW) では、タイミング制約を分析し、不足している制約を補ったり、正しくない制約を修正するための手順ガイドを提供します。完全な制約は、制約が適用されていないタイミング パスに起因するハードウェアのバグの発生を低減できる一方で、無効な制約は、間違ったタイミング クリティカリティへとコンパイル プロセスをミスリードする可能性があります。
正確な電力解析には、正確な電力制約が不可欠です。消費電力制約アドバイザーは、デザインのスイッチング アクティビティを分析し、不適切な指定が疑われる部分をピンポイントで特定し、適切な解析のためのターンキー XDC 電力制約を生成します。Vivado の電力レポートにも、電力制約の詳細として低/中/高品質を示す信頼性レベルが含まれ、電力制約の完成度をフィードバックします。信頼性レベルが「高」の場合は、最も正確な電力解析が可能になり、これはハードウェアの測定値に近いものになります。
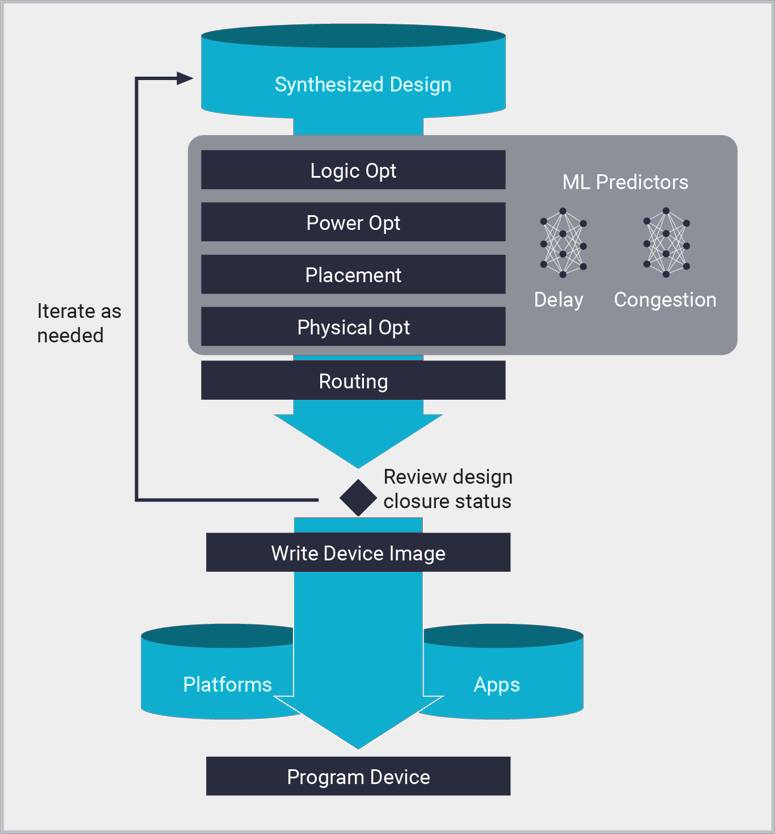
インプリメンテーション
Vivado インプリメンテーションは、AMD デバイス用の配置配線ツールであり、合成済みネットリストからビットストリームやデバイス イメージを生成します。これにより、最小規模の MPSoC から、最大規模のモノリシック デバイスや数百万個のロジック セルを含む SSIT (スタックド シリコン インターコネクト テクノロジ) デバイスまで、あらゆるサイズのプラットフォームおよびカスタム デザインを構築できます。Vivado インプリメンテーションは、機械学習の予測機能でガイドされ、最先端のパーティショニング、配置、および配線アルゴリズムで実行されます。ML モデルを適用することで、配線の遅延や密集度を正確に見積もり、短時間でより高い QoR (結果の品質) を達成できます。XDC 制約でインプリメンテーションが推進され、性能、リソース使用量、消費電力の目標デザインを達成し、Vivado プロジェクトや Tcl スクリプト内でデザインが合成されます。
インプリメンテーションは、簡単操作のプッシュボタン モードから、性能要求が厳しいデザインに対応する高度にカスタマイズされた Tcl スクリプトまで、あらゆる操作モードをサポートしています。配置前、配置後、配線後など、任意のコンパイル ステージでタイミング、使用率、消費電力、その他デザインの品質を評価する詳細な解析を実行できます。デザインのデータベースは、デザイン チェックポイント (DCP) ファイルを使用して任意のコンパイル ステージを保存/復元でき、これらを可視化して必要に応じて制約を適用することも可能です。
画像を拡大
主な特長
-
Vivado インプリメンテーション プロセス
- ロジックの最適化:
合成後、ロジック ネットリストはグローバル レベルでさらに最適化され、使用率やロジック段数の削減が図られます。
- 消費電力の最適化:
アクティビティ ゲーティング手法を使用してデザインの消費電力を削減します。ユーザーによる介入は不要で、機能が変更されることもなく、タイミングに最小限の影響のみ発生します。
- 配置:
タイミング要件、フロアプラン要件、手動の配置要件などを含む XDC 制約に従って、論理ネットリストのセルが物理的なデバイス リソースに配置されます。配置は、デザイン階層に基づいて、I/O やクロッキング リソース、ロジック クラスターなどのグローバル リソースから開始されます。グローバル配置、詳細配置、そして配置後の最適化が実行されます。配置は、配線の遅延や密集度を概算するために ML モデルでガイドされるため、従来の統計的手法に比べて、より高速に高精度なコンパイルが可能です。
- 配線:
ネットリスト コンポーネント間の接続がデバイスの物理的なインターコネクト リソースに割り当てられます。配置と同様に、配線も I/O やクロッキングなどのグローバル リソースから開始し、その後 XDC タイミング制約に従ってリソースの割り当てに優先順位が付けられます。最後の配線フェーズでは、配線をさらに最適化して最終的なセットアップとホールド要件を満たします。配置段階で配線密集度を予測する ML モデルを使用した場合は、配線密度が軽減されています。
- 物理的な最適化:
配置配線全体をとおして発生するタイミング主導のプロセスです。ロジックの最適化とは異なり、物理的な最適化では、配置配線の結果に基づく最も正確なタイミング データが使用されます。タイミング インパクトが評価され、実行した最適化のみがタイミングの改善につながります。最適化の手法には、複製、リタイミング、レジスタの再配置のほか、ターゲット アーキテクチャに固有の手法があります。また、配置後と配線後に個別に物理的な最適化を実行することで、結果をさらに向上させることができます。
- 主な解析機能:
デザイン解析は、インプリメンテーションのどの段階でも実行できます。タイミング、電力、および物理的制約の変更と検証を可能にする包括的な XDC 制約管理システム。
- Report Timing Summary:
特定のタイミング目標に向けてインプリメンテーションを進める、XDC 制約をサポートする画期的なスタティック タイミング解析ツールです。クリティカル タイミング パス、クロックの関連性、およびクロック ドメイン クロッシング (CDC: クロック乗せ換え) のタイミング レポートを生成します。
- Report Power:
XDC スイッチング アクティビティを活用したベクターレス伝搬による消費電力解析を行います。電力消費の多いエリアを特定するためのレポートを生成する。
- デバイス ビュー:
論理ネットリストの回路図とともに、デザインの配置や配線を視覚的に表現したものです。物理的、論理的、ソース コードのデザイン ビューを使用してクロスプローブが可能になり、クリティカル タイミング パスをすばやく特定してトレースできる。
-
コンパイル オプション
- Vivado インプリメンテーション
プッシュボタン操作の簡単なフローから、異なるコンパイル ストラテジを使用して模索したり、タイミング要件が厳しいデザインでは反復実行できる、あらゆるレベルのフローに対応します。
- インプリメンテーション
- Vivado プロジェクト フローと非プロジェクト フローをサポート
- 対話形式または Tcl スクリプトを使用してバッチ モードで実行
- 複数のスレッドを実行してコンパイル時間を短縮
- さまざまなデザイン目標のソリューションを探求するためのコンパイル ストラテジを提供
- 以前の実行からのデータを再利用するインクリメンタル コンパイル モードをサポート (コンパイルの高速化またはタイミング クロージャのいずれを優先するかを指定可能