
-
Hauptmerkmale und Vorteile des Vivado IP Integrator
- Enge Integration in die integrierte Vivado Designumgebung
- Nahtlose Einbindung der hierarchischen Subsysteme von IP Integrator in das Gesamtdesign
- Schnelle Erfassung und Verpackung von IP Integrator Designs für die Wiederverwendung
- Unterstützung sowohl für grafische als auch für Tcl-basierte Design-Flows
- Schnelle Simulation und Cross-Probing zwischen mehreren Designansichten
- Unterstützung für alle Designdomänen
- Unterstützung für Designs mit und ohne Prozessor
- Integration von Algorithmus-IP (Vitis HLS und Model Composer) und IP auf RTL-Ebene
- Kombination aus DSP, Video, Analog, Embedded, Konnektivität und Logik
- Unterstützung für projektbasierten DFX-Flow
- Fokus auf Designerproduktivität
- DRCs auf komplexen Verbindungen auf Schnittstellenebene während der Designmontage
- Erkennung und Korrektur häufiger Designfehler
- Automatische Propagierung von IP-Parametern an miteinander verbundene IP
- Optimierungen auf Systemebene
- Automatisierte Designerunterstützung
- Verbesserte Unterstützung für die Zusammenarbeit
- Verbesserte Unterstützung für die Zusammenarbeit
- Teambasierte Designs unter Verwendung von Block Design Container ermöglichen Wiederverwendbarkeit und modulare Designs
- Verbesserungen bei der Versionskontrolle durch Trennen von Quelldateien von generierten Dateien
- Block Design Diff Tool zum Vergleich von zwei Blockdesigns
Übersicht
AMD Vivado™ unterstützt den Designeinstieg in traditionellen Hardwarebeschreibungssprachen (HDL) wie VHDL und Verilog. Außerdem wird ein Tool mit grafischer Benutzeroberfläche namens IP Integrator (IPI) unterstützt, mit dem man eine Designumgebung für die IP-Integration per Plug-and-Play verbinden kann.
Vivado bietet erstklassige Synthese- und Implementierungsfunktionen für die komplexen FPGAs und adaptiven SoCs von heute und umfasst integrierte Optionen für Timing-Closure und Methodik.
Mit dem UltraFast™-Methodikbericht (report_methodology), der im Standard-Flow von Vivado verfügbar ist, können Benutzer ihr Design einschränken, Ergebnisse analysieren und Close-Timing herbeiführen.
Funktionen
Hier finden Sie einen kurzen Überblick über die Funktionen der Vivado™ Design Suite für den Designeinstieg und die entsprechende Implementierung. Klicken Sie auf die anderen Registerkarten, um vollständige Details zu den Funktionen anzuzeigen.
- IP Integrator
- Logic Synthesis
- Design Methodology
- Implementierung
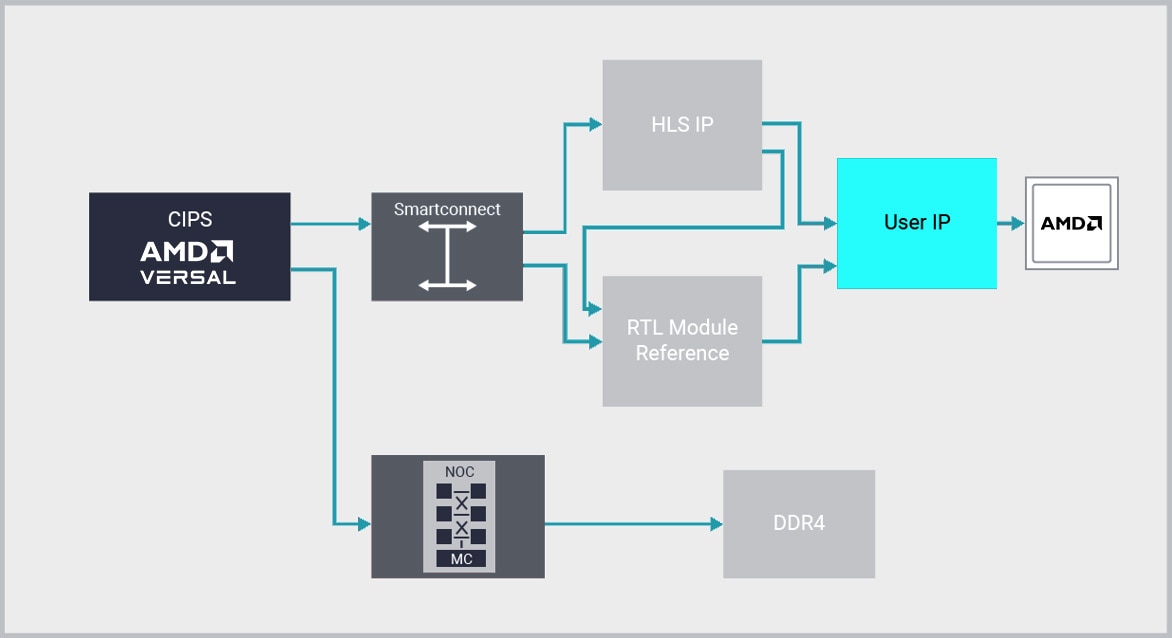
IP Integrator
AMD Vivado™ durchbricht das Produktivitätsplateau des RTL-Designs, indem es mit seiner IP Integrator-Funktion die branchenweit erste Designumgebung für die IP-Integration per Plug-and-Play bereitstellt.
Vivado IP Integrator bietet einen grafischen und Tcl-basierten Correct-by-Construction-Designentwicklungs-Flow. Er stellt eine Chip- und Plattform-orientierte, interaktive Umgebung bereit, die eine intelligente automatische Verbindung wichtiger IP-Schnittstellen, die Erstellung von IP-Subsystemen per einfachem Mausklick, Echtzeit-DRCs und das Propagieren von Schnittstellenänderungen unterstützt. Dazu kommt eine leistungsstarke Debugging-Funktion.
Designer arbeiten bei der Herstellung von Verbindungen zwischen IP auf der „Schnittstellen“- und nicht auf der „Signal“-Ebene, wodurch die Produktivität erheblich gesteigert wird. Oft werden dabei dem Branchenstandard entsprechende AXI4-Schnittstellen verwendet. IP Integrator unterstützt aber auch Dutzende anderer Schnittstellen.
Auf Schnittstellenebene können Designteams schnell komplexe Systeme zusammenstellen, die IP nutzen, die mit Vitis HLS, Model Composer, AMD SmartCore™ und LogiCORE™ IP, Alliance Member IP sowie Ihrer eigenen IP erstellt wurden. Durch die Nutzung der Kombination aus Vivado IPI und HLS sparen Kunden bis zum 15-Fachen an Entwicklungskosten im Vergleich zu einem RTL-Ansatz.
Bildzoom
Logic Synthesis
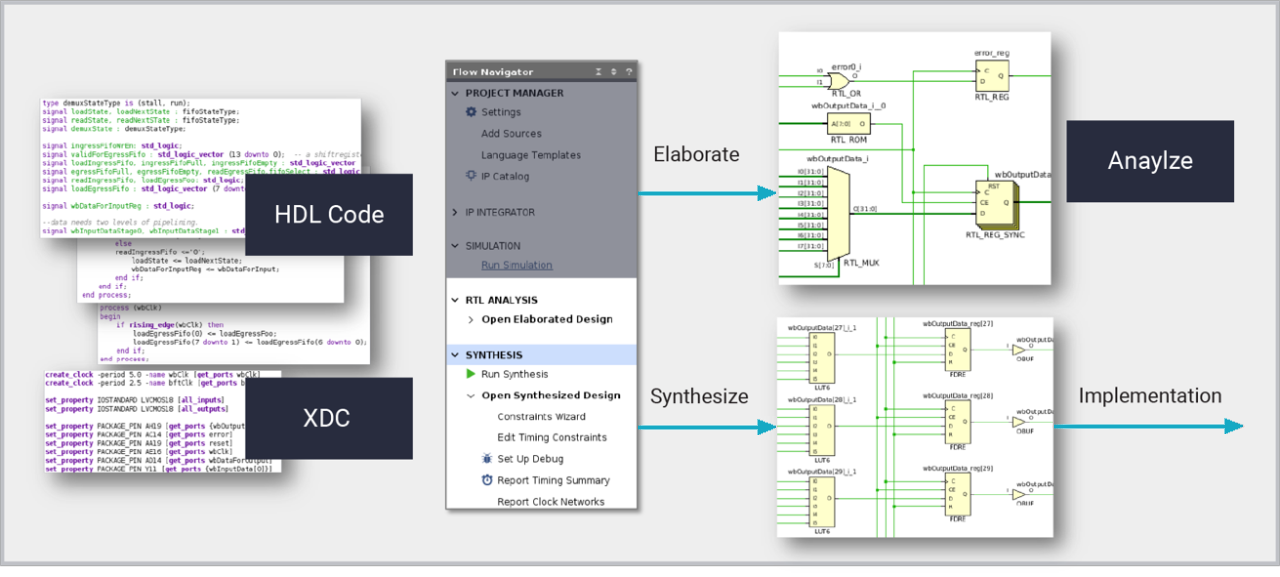
Vivado Logic Synthesis ist ein Tool zur Designerstellung, mit dem Hardwareentwickler optimale Plattformen, IP und benutzerdefinierte Designs für alle neuesten AMD Chips erstellen können. Logic Synthesis übersetzt in SystemVerilog, VHDL und Verilog geschriebene Register Transfer Level(RTL)-Designs in eine synthetisierte Netzliste von Bibliothekszellen für die nachgelagerte Implementierung. Die Synthese erkennt die Zieltechnologie und kann Funktionen aus RTL-Beschreibungen ableiten, die direkt auf dedizierte Siliziumstrukturen wie LUTRAMs, Block-RAMs, Schieberegister, Addierer-Subtrahierer und DSP-Blöcke abgebildet werden. Syntheseergebnisse werden mithilfe von Attributen, Tool-Optionen und Xilinx Design-Einschränkungen (Xilinx Design Constraints, XDC) gesteuert, um Designziele zu erreichen. Logic Synthesis funktioniert innerhalb von Vivado-Projekten und Tcl-Scripting und bietet eine solide Grundlage für andere hochrangige Designmethoden, die RTL-Beschreibungen generieren, einschließlich High-Level-Synthese und IP Integrator.
Logic Synthesis verwendet jetzt auch maschinelles Lernen, um eine schnellere Kompilierung zu unterstützen. ML-Modelle verbessern die Gesamteffizienz, indem sie die für verschiedene Teile des Designs erforderlichen Syntheseoptimierungen vorhersagen.
Bildzoom
-
Hauptmerkmale
- Sprachunterstützung
Logic Synthesis unterstützt die neuesten synthetisierbaren Konstrukte, die Branchenstandards entsprechen:
- SystemVerilog, Verilog, VHDL und VHDL-2008 Hardware Description Languages (HDLs)
- Möglichkeit, verschiedene HDL-Typen im gleichen Design zu mischen und Parameter und Generics an jeden Typ zu übergeben
- Sprachvorlagen, um eine zuverlässige Zuordnung von abgeleiteten komplexen Funktionen zu geeigneten Chipressourcen zu gewährleisten
HDL-Beschreibungen können visuell anhand eines ausgeklügelten Designschemas überprüft werden, das mittels Cross-Probing auf den zugehörigen HDL-Quellcode referenziert.- Optimierungssteuerung
Logic Synthesis ermöglicht die Steuerung aller Aspekte der Inferenz und Optimierung. Zuweisungen können wie folgt vorgenommen werden:
- Globale Verwendung von Tool- und Befehlsoptionen
- Bei bestimmten Modulen oder Instanzen der logischen Hierarchie unter Verwendung der BLOCK_SYNTH XDC-Einschränkung
- Auf Zellen und Netzen, die HDL-Attribute verwenden
Zu den Steuerungsarten gehören:- Hierarchie beibehalten, reduzieren und neu aufbauen
- Technologiespezifische Strukturen ableiten oder nicht ableiten
- Den Typ dedizierter Speicherressourcen auswählen, die für die Zuordnung von Speicher-Arrays verwendet werden
- Codierungstyp für Finite State Machines (FSMs) zuweisen
- Leistung, Auslastung oder Energieverbrauch priorisieren
- Erweiterte Optimierungen wie logisches Retiming anwenden
- Konvertierung von Gated Clocks zur Registrierung von Aktivierungssignalen
- Kompilierungsoptionen
Vivado Logic Synthesis unterstützt alle Ebenen der Anpassung, von der Bedienung per Tastendruck bis hin zur Erforschung verschiedener Kompilierungsstrategien.
Logic Synthesis:
- Funktioniert mit Vivado-Projekten und nicht projektbezogenen Flows
- Kann interaktiv oder im Batch-Modus mithilfe von Tcl ausgeführt werden
- Führt mehrere Prozesse aus, um die Kompilierungszeiten zu verkürzen
- Bietet Kompilierungsstrategien, um Lösungen für verschiedene Designziele zu untersuchen
- Unterstützt einen inkrementellen Kompilierungsmodus, der Daten aus früheren Durchläufen wiederverwendet, um Kompilierungsiterationen zu beschleunigen
Design Methodology
Bei Verwendung mit Vivado hilft die UltraFast Methodik dabei, die richtigen Einschränkungen zu definieren, die Tools korrekt zu steuern, Ergebnisse zu analysieren und die Gesamtproduktivität zu verbessern. Die Ultrafast™ Design-Methodik ist eine Sammlung bewährter Praktiken beim Hardware-Design, die auf der langjährigen Erfahrung von Vivado Experten und deren Erfolgen im Bereich Design-Closure beruhen und die Leistungsgrenzen von Tools und Technologien voll ausreizen.
Bildzoom
Hauptmerkmale
Integrierte Methodik
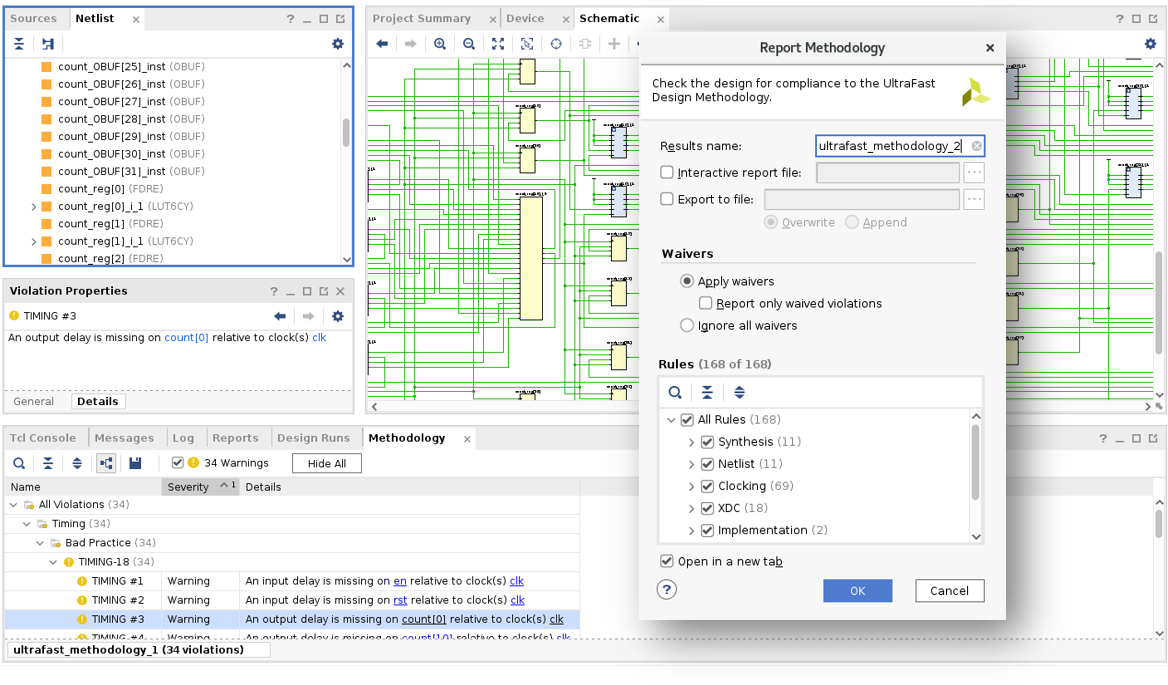
Um die Einhaltung der Richtlinien für die UltraFast Methodik zu erleichtern, sind UltraFast Methodology Reports in Vivado integriert und werden standardmäßig für Vivado-Projekte erstellt. Dadurch lassen sich die Vorteile von UltraFast nutzen, ohne dass eine einzige Dokumentationszeile gelesen werden muss. Die Report Methodology Funktion generiert eine Liste der im aktuellen Design gefundenen Methodikverletzungen, aufgeschlüsselt nach Kategorie und Schweregrad für die interaktive Prüfung. Durch die Überprüfung und Behebung von Verstößen gegen die Methodik erhalten Designs den optimalen Ausgangspunkt für die Implementierung und haben somit die besten Chancen für eine erfolgreiche Design-Closure in kürzester Zeit. Verstöße, die als akzeptabel gelten, können ignoriert werden, sodass sie nicht erneut in Berichten erscheinen.
Die Bereitstellung vollständiger und korrekter Einschränkungen ist ein wichtiger Bestandteil der UltraFast Methodik. Der Timing Constraints Wizard (TCW) analysiert zeitliche Einschränkungen und bietet schrittweise Anleitungen zur Bereitstellung fehlender und zum Beheben ungültiger Einschränkungen. Die Vollständigkeit von Einschränkungen verringert die Wahrscheinlichkeit von Hardwarefehlern, die aus uneingeschränkten Timing-Pfaden resultieren, während sich bei ungültigen Einschränkungen der Kompilierungsaufwand fälschlicherweise auf die Timing-Kritikalität konzentriert.
Die Qualität der Energieeinschränkung ist für eine genaue Energieverbrauchsanalyse von entscheidender Bedeutung. Der Power Constraints Advisor analysiert die Umschaltfunktionen eines Designs, ermittelt Bereiche, die scheinbar falsch spezifiziert sind, und generiert schlüsselfertige XDC-Energieeinschränkungen für eine ordnungsgemäße Analyse. Die Energieverbrauchsberichte von Vivado enthalten auch ein Vertrauensniveau, das eine Spezifikation für eine niedrige, mittlere oder hohe Qualität der Energieeinschränkungen anzeigt und Rückmeldungen zu deren Vollständigkeit gibt. Ein hohes Konfidenzniveau gewährleistet eine äußerst genaue Energieverbrauchsanalyse, die genau auf die Hardwaremessungen abgestimmt ist.
Implementierung
Die Vivado-Implementierung ist das Positionierungs- und Routing-Tool für AMD Chips, das Bitströme und Baustein-Images aus einer synthetisierten Netzliste generiert. Sie ermöglicht die Erstellung von Plattformen und benutzerdefinierten Designs aller Größen, von den kleinsten MPSoCs bis hin zu den größten monolithischen und Stacked Silicon Interconnect Technology(SSIT)-Chips mit Millionen von Logikzellen. Die Vivado.-Implementierung basiert auf hochmodernen Algorithmen für Partitionierung, Platzierung und Routing, die von maschinellen Lernprozessen gesteuert werden. Dank der Anwendung von ML-Modellen kann die Implementierung in kürzerer Zeit eine höhere Ergebnisqualität (QoR) erzielen und dabei Routing-Verzögerungen und -Engpässe genau vorhersagen. Implementierungsprozesse werden durch Xilinx Design-Einschränkungen (Xilinx Design Constraints, XDC) vorangetrieben, um die Designziele für Leistung, Auslastung und Energieverbrauch zu erfüllen, und Logic Synthesis funktioniert innerhalb Vivado-Projekten und Tcl-Scripting.
Die Implementierung unterstützt alle Betriebsarten, vom Drucktastenmodus für einfache Bedienung bis hin zu ausgeklügelten, maßgeschneiderten Tcl-Formeln für die Bearbeitung von Designs mit den höchsten Leistungsanforderungen. Eine detaillierte Analyse von Timing, Auslastung, Energieverbrauch und anderen Kennzahlen für die Designqualität kann in jeder Kompilierungsphase durchgeführt werden: vor der Platzierung, nach der Platzierung und nach dem Routing. Die Designdatenbank kann auch in jeder Kompilierungsphase mithilfe von Design Checkpoint(DCP)-Dateien gespeichert und wiederhergestellt werden. Das Design kann visualisiert und entsprechend eingeschränkt werden.
Bildzoom
Hauptmerkmale
-
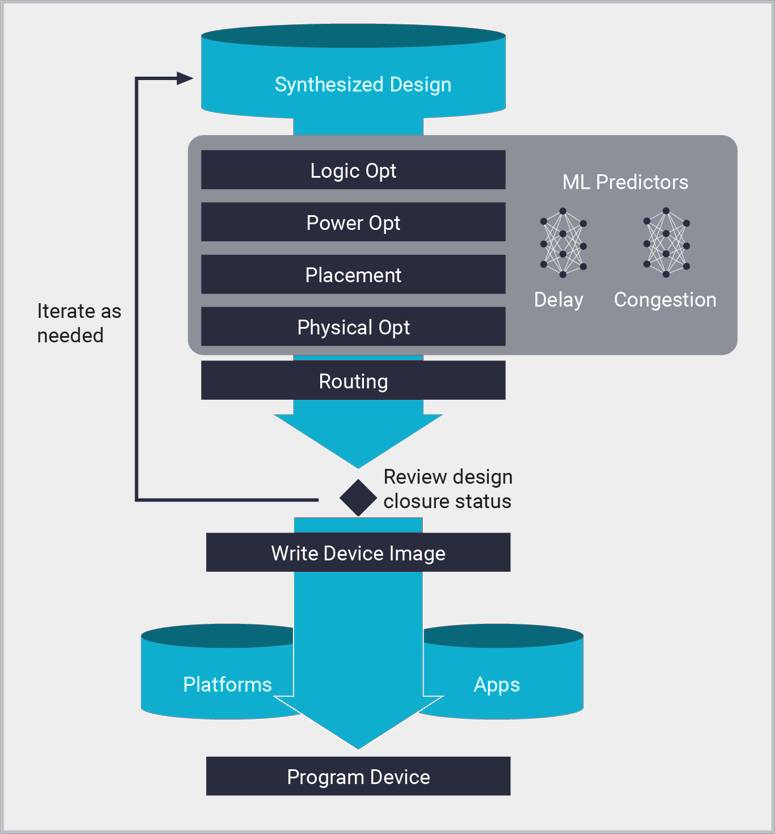
Implementierungsprozesse von Vivado
- Logikoptimierung:
Nach der Synthese wird die logische Netzliste auf globaler Ebene weiter optimiert, um Auslastung und logische Ebenen zu reduzieren.
- Energieoptimierung:
Der Energieverbrauch des Designs wird durch Activity-Gating-Techniken reduziert, ohne dass ein Eingreifen oder Änderungen an der Funktionalität erforderlich sind, und die Auswirkungen auf das Timing sind minimal.
- Platzierung:
Logische Netzlistenzellen werden gemäß den XDC-Einschränkungen, u. a. Timing, Grundriss und manuelle Platzierung, in physischen Chipressourcen platziert. Die Platzierung beginnt mit globalen Ressourcen, einschließlich I/O- und Taktressourcen und Logikclustern, die auf der Designhierarchie basieren. Auf die globale Platzierungsphase folgen die detaillierten Platzierungs- und Optimierungsphasen nach der Platzierung. Die Platzierung erfolgt anhand von ML-Modellen, die Routingverzögerungen und Routing-Engpässe vorhersagen. Dadurch wird im Vergleich zu herkömmlichen statistischen Methoden eine größere Genauigkeit und schnellere Kompilierung ermöglicht.
- Routing:
Verbindungen zwischen Netzlistenkomponenten werden physischen Chipverbindungsressourcen zugewiesen. Ähnlich wie bei der Platzierung beginnt das Routing mit globalen Ressourcen wie IO und Taktung und priorisiert dann Ressourcenzuweisungen gemäß XDC-Timing-Einschränkungen. Letzte Routingphasen optimieren das Routing zusätzlich, um die Setup- und Hold-Anforderungen zu erfüllen. Routing-Engpässe werden durch die Verwendung der Vorhersage von ML Routing-Engpässen während der Platzierung reduziert.
- Physische Optimierung:
Die physische Optimierung ist ein Timing-gesteuerter Prozess, der während der Platzierung und des Routings stattfindet. Im Gegensatz zur logischen Optimierung verwendet die physische Optimierung die basierend auf Platzierung und Routing genauesten verfügbaren Timing-Daten. Die Auswirkungen auf das Timing werden so bewertet, dass nur die durchgeführte Optimierung zu einem verbesserten Timing führt. Zu den Optimierungstechniken gehören Replikation, Retiming und Neuplatzierung von Registern sowie weitere Optimierungen speziell für die Zielarchitektur. Die physische Optimierung kann auch nach der Platzierung und dem Routing separat ausgeführt werden, um die Ergebnisse weiter zu verbessern.
- Mittelpunkt der Analysefunktionen:
Ein Design kann in jeder Kompilierungsphase innerhalb der Implementierung analysiert werden. Ein umfassendes XDC Constraint Management-System, das Änderungen und Verifizierungen von Timing-, Energie- und physischen Einschränkungen ermöglicht.
- Report Timing Summary:
Ein leistungsstarker Analysator für das statische Timing, der XDC-Einschränkungen unterstützt, um die Implementierung bestimmter Timing-Ziele zu beschleunigen. Generiert Timing-Berichte zu kritischen Timing-Pfaden, Taktinteraktionen und Clock Domain Crossings (CDCs).
- Report Power:
Vektorlose Propagierung unterstützt XDC-Switching-Aktivität für die Energieverbrauchsanalyse. Erstellt Berichte, um Bereiche mit höherem Energieverbrauch zu identifizieren.
- Chipansicht:
Eine grafische Darstellung von Platzierung und Routing des Designs zusammen mit logischen Netzlistenschemata. Ermöglicht ein Cross-Probing zwischen physischen, logischen und Quellcode-Designansichten, um die Quellen kritischer Timing-Pfade schnell nachzuverfolgen.
-
Kompilierungsoptionen
- Implementierung von Vivado
Sie unterstützt alle Ebenen der benutzerspezifischen Anpassung, von der Bedienung per Tastendruck bis hin zur Untersuchung verschiedener Kompilierungsstrategien und iterativer Flows für Designs mit schwer zu erfüllenden Anforderungen.
- Implementierung
- Funktioniert mit Vivado-Projekten und nicht projektbezogenen Flows
- Kann interaktiv oder im Batch-Modus mithilfe von Tcl ausgeführt werden
- Führt mehrere Threads aus, um die Kompilierungszeiten zu verkürzen
- Bietet Kompilierungsstrategien, um Lösungen für verschiedene Designziele zu untersuchen
- Unterstützt einen inkrementellen Kompilierungsmodus, der Daten aus früheren Läufen wiederverwendet, die entweder die Kompilierungsbeschleunigung oder die Timing-Closure priorisieren können