
-
Vivado IP Integrator의 주요 특징 및 이점
- Vivado 통합 설계 환경에서의 긴밀한 통합
- IP Integrator 계층적 하위 시스템을 전체 설계에 원활하게 포함
- 재사용을 위한 IP Integrator 설계의 신속한 캡처 및 패키징
- 그래픽 및 Tcl 기반 설계 흐름 지원
- 여러 설계 뷰 간의 빠른 시뮬레이션 및 크로스 프로빙
- 모든 설계 도메인 지원
- 프로세서 또는 비프로세서 설계 지원
- 알고리즘(Vitis HLS 및 모델 컴포저) 및 RTL 수준 IP 통합
- DSP, 비디오, 아날로그, 내장형, 연결, 로직의 조합
- 프로젝트 기반 DFX 흐름 지원
- 설계자 생산성에 집중
- 설계 결합 중 복잡한 인터페이스 수준 연결에 대한 DRC
- 일반적인 설계 오류 인식 및 수정
- 상호 연결된 IP로 IP 매개변수 자동 전파
- 시스템 수준 최적화
- 자동화된 설계 지원
- 강화된 협업 지원
- 강화된 협업 지원
- 블록 디자인 컨테이너를 사용한 팀 기반 설계로 재사용성과 모듈식 설계 가능
- 소스 파일과 생성된 파일을 분리하는 개정 제어 개선
- 두 블록 디자인을 비교하는 블록 디자인 차이 도구
개요
AMD Vivado™는 VHDL 및 Verilog와 같은 전통적인 HDL(Hardware Description Language)의 설계 입력을 지원합니다. 또한 플러그 앤 플레이 IP 통합 설계 환경을 구현하는 IPI(Inter Processor Integrator)라는 그래픽 사용자 인터페이스 기반 도구도 지원합니다.
Vivado는 오늘날의 복잡한 FPGA 및 SoC에 맞춰 동급 최상의 합성과 구현을 제공하며 타이밍 클로저와 방법론에 관한 기능이 내장되어 있습니다.
Vivado의 기본 흐름에서 사용할 수 있는 UltraFast™ 방법론 보고서(report_methodology)는 사용자가 설계를 제한하고, 결과를 분석하고, 타이밍을 클로징하는 데 도움이 됩니다.
기능
다음은 설계 입력 및 구현을 위한 Vivado™ Design Suite 기능에 대한 간략한 개요입니다. 전체 기능에 대한 세부 정보를 보려면 다른 탭을 클릭하세요.
- IP Integrator
- 로직 합성
- 설계 방법론
- 구현
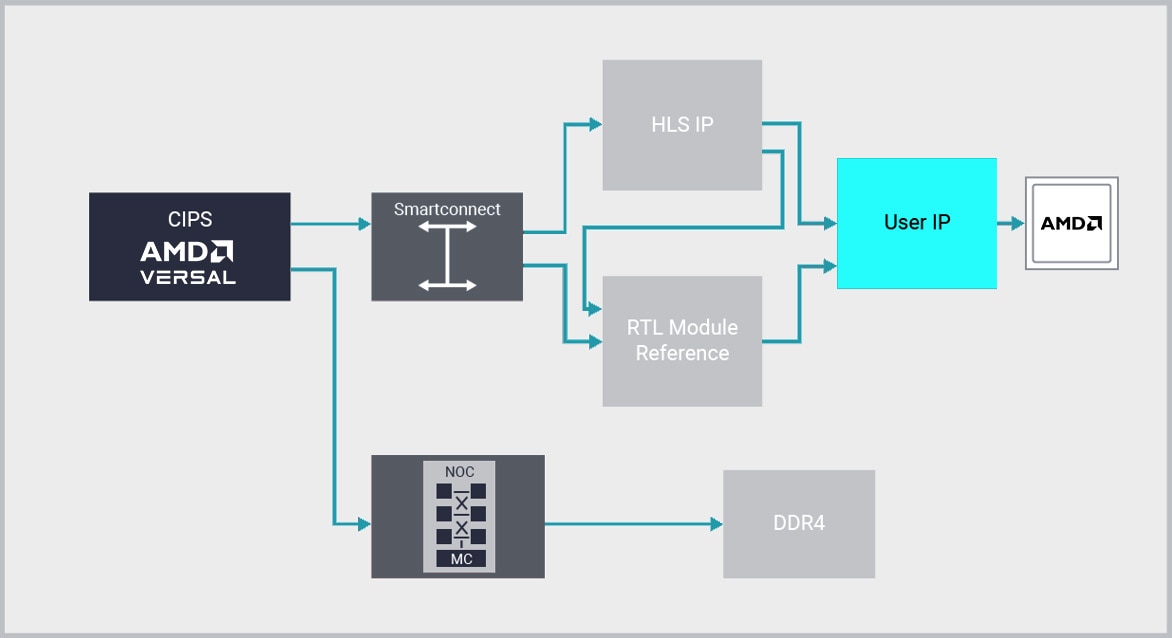
IP Integrator
AMD Vivado™는 IP Integrator 기능을 통해 업계 최초의 플러그 앤 플레이 IP 통합 설계 환경을 제공함으로써 RTL 설계 생산성 수준을 한층 높여줍니다.
Vivado IP Integrator는 그래픽 및 Tcl 기반의 CbC(Correct-by-Construction) 설계 개발 흐름을 제공합니다. 주요 IP 인터페이스의 지능형 자동 연결, 원클릭 IP 하위 시스템 생성, 실시간 DRC, 인터페이스 변경 전파를 지원하며 강력한 디버그 기능이 결합된 디바이스 및 플랫폼 인식 대화형 환경을 제공합니다.
설계자가 IP 간 연결을 만들 때 추상화의 "신호" 수준이 아닌 "인터페이스"에서 작업하므로 생산성이 크게 향상됩니다. 산업 표준 AXI4 인터페이스를 사용하는 경우가 많지만 IP Integrator는 기타 수십 가지의 인터페이스도 지원합니다.
인터페이스 수준에서 작업하는 설계 팀은 자체 IP뿐만 아니라 Vitis HLS, 모델 컴포저, AMD SmartCore™, LogiCORE™ IP, Alliance Member IP로 만든 IP도 활용하여 복잡한 시스템을 빠르게 조립할 수 있습니다. Vivado IPI와 HLS의 조합을 활용함으로써 고객은 RTL 접근 방식에 비해 개발 비용을 최대 15배 절감할 수 있습니다.
이미지 확대
로직 합성
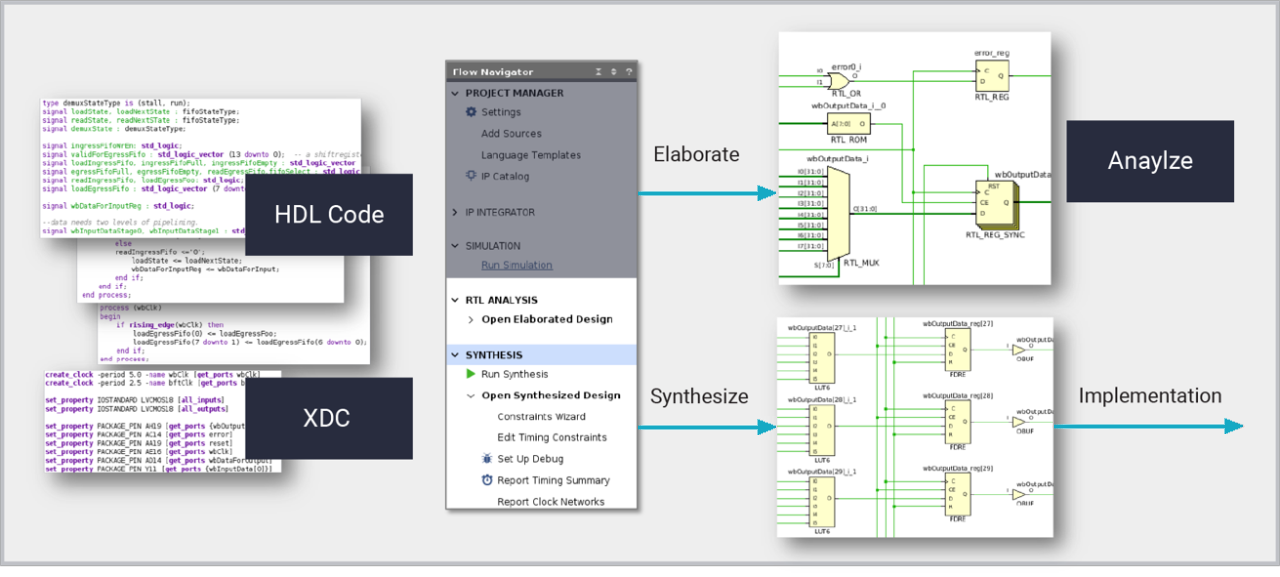
Vivado 로직 합성은 하드웨어 설계자가 모든 최신 AMD 디바이스를 대상으로 최적의 플랫폼, IP, 맞춤형 설계를 제작할 수 있는 설계 제작 도구입니다. 로직 합성은 SystemVerilog, VHDL, Verilog로 작성된 RTL(레지스터 전송 수준) 설계를 다운스트림 구현을 위한 라이브러리 셀의 합성 넷리스트로 변환합니다. 타겟 기술을 인식하고 있으면 합성은 LUTRAM, 블록 RAM, 시프트 레지스터, 가산기-감산기, DSP 블록을 포함한 전용 실리콘 구조에 직접 매핑되는 RTL 설명에서 함수를 추론할 수 있습니다. 합성 결과는 설계 목표를 달성하기 위해 속성, 도구 옵션, XDC(Xilinx Design Constraints)를 사용하여 도출됩니다. 로직 합성은 Vivado 프로젝트 및 Tcl 스크립팅 내에서 작동하며, HLS(High-Level Synthesis) 및 IP Integrator를 포함하여 RTL 설명을 생성하는 기타 고급 설계 방법을 위한 견고한 토대를 제공합니다.
로직 합성에는 컴파일 속도를 높이기 위해 머신 러닝이 도입되었습니다. ML 모델은 설계의 다양한 부분에 필요한 합성 최적화를 예측하여 전반적인 효율성을 향상합니다.
이미지 확대
-
주요 특징
- 언어 지원
로직 합성은 업계 표준과 일치하는 다음과 같은 최신 합성 가능 구조를 지원합니다.
- SystemVerilog, Verilog, VHDL, VHDL-2008 HDL(Hardware Description Language)
- 동일한 설계에서 다양한 HDL 유형을 혼합하고 각 유형에 매개변수 및 제네릭 전달 가능
- 추론된 복합 함수를 적합한 디바이스 리소스에 안정적으로 매핑하는 언어 템플릿
HDL 설명은 관련 HDL 소스 코드와 크로스 프로브하는 정교한 설계도를 사용하여 시각적으로 검토할 수 있습니다.- 최적화 제어
로직 합성을 통해 추론 및 최적화의 모든 측면을 제어할 수 있습니다. 할당은 다음과 같이 이루어질 수 있습니다.
- 도구 및 명령 옵션을 전역적으로 사용
- BLOCK_SYNTH XDC 제약 조건을 사용하여 특정 모듈 또는 논리적 계층 구조의 인스턴스에서
- HDL 속성을 사용하여 셀 및 네트에서
제어 유형은 다음과 같습니다.- 계층 구조 유지, 평면화, 재구축
- 기술별 구조를 유추하거나 유추하지 않음
- 메모리 어레이 매핑에 사용되는 전용 메모리 리소스의 유형 선택
- FSM(Finite State Machine)에 대한 인코딩 유형 할당
- 성능, 활용성 또는 전력 우선순위 지정
- 논리적 리타이밍과 같은 고급 최적화 적용
- 활성화 신호를 등록하기 위한 게이트 클럭 변환
- 컴파일 옵션
Vivado 로직 합성은 푸시 버튼 작동부터 다양한 컴파일 전략 탐색에 이르기까지 모든 수준의 사용자 정의를 지원합니다.
로직 합성:
- Vivado 프로젝트 및 비프로젝트 흐름과 함께 작동
- 대화식으로 또는 Tcl을 사용하여 배치 모드로 실행 가능
- 여러 프로세스를 실행하여 컴파일 시간 단축
- 다양한 설계 목표를 위한 솔루션을 탐색할 수 있는 컴파일 전략 제공
- 컴파일 반복 속도를 높이기 위해 이전 실행의 데이터를 재사용하는 증분 컴파일 모드 지원
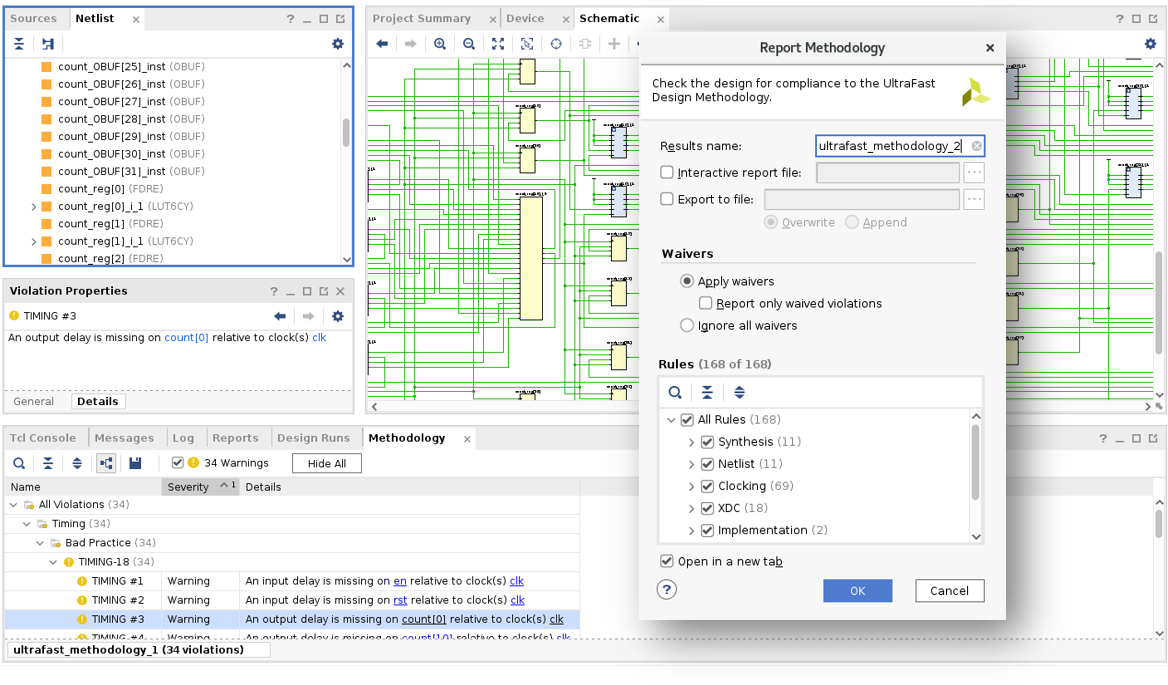
설계 방법론
Vivado와 함께 사용할 경우 UltraFast 방법론은 적절한 제약 조건을 정의하고 도구를 적절하게 구동하며 결과를 분석하는 데 도움이 되고, 전반적인 생산성을 향상합니다. UltraFast™ 설계 방법론은 Vivado 전문가의 수년에 걸친 경험과 도구 및 기술의 한계를 극복하는 고객 설계에 대한 설계 완료 성공으로부터 축적된 최상의 하드웨어 설계 사례 모음입니다.
이미지 확대
주요 특징
기본 제공 방법론
UltraFast 방법론 가이드라인 준수를 촉진하기 위해 UltraFast 방법론 보고서는 Vivado에 내장되어 Vivado 프로젝트에 대해 기본적으로 생성되므로 문서를 일일이 읽지 않고도 UltraFast의 이점을 활용할 수 있습니다. 보고 방법론 기능은 현재 설계에서 발견된 방법론 위반 목록을 생성하며, 이러한 위반은 대화형 검토를 위해 범주 및 심각도 수준별로 분류됩니다. 방법론 위반을 검토하고 해결하면 설계에 구현을 위한 최적의 출발점이 제공되므로 짧은 시간 내에 성공적으로 설계를 완료할 수 있는 최고의 기회가 부여됩니다. 허용 가능한 것으로 간주되는 위반은 보고서에 다시 나타나지 않도록 면제될 수 있습니다.
완전하고 정확한 제약 조건을 제공하는 것은 UltraFast 방법론의 중요한 요소입니다. TCW(Timing Constraints Wizard)는 타이밍 제약 조건을 분석하며, 누락된 제약 조건을 제공하고 잘못된 제약 조건을 수정하는 단계별 지침을 제공합니다. 제약 조건을 완전히 갖추면 제한되지 않은 타이밍 경로로 인해 하드웨어 버그가 발생할 가능성을 줄일 수 있는 반면, 잘못된 제약 조건은 컴파일 작업 시 잘못된 타이밍 중요도로 오도할 수 있습니다.
전력 제약 조건 품질은 정확한 전력 분석을 위해 매우 중요합니다. Power Constraints Advisor는 설계 전환 활동을 분석하고, 부적절하게 지정된 것으로 보이는 영역을 정확히 찾아내며, 적절한 분석을 위해 턴키 XDC 전력 제약 조건을 생성합니다. Vivado 전력 보고서에는 또한 전력 제약 조건의 낮음, 중간 또는 높은 품질을 나타내는 신뢰 수준이 포함되어 있어 전력 제약 조건 완전성에 대한 피드백을 제공합니다. 높은 신뢰도 수준은 하드웨어 측정치와 거의 일치하는 가장 정확한 전력 분석을 보장합니다.
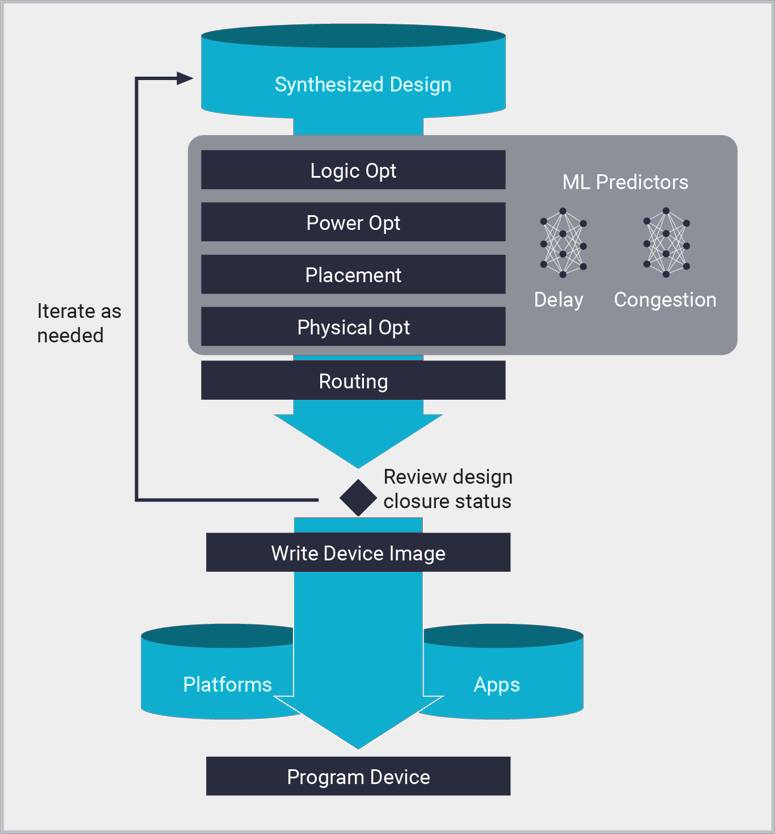
구현
Vivado 구현은 AMD 디바이스를 위한 배치 및 라우팅 도구로, 합성 넷리스트로부터 비트스트림과 디바이스 이미지를 생성합니다. 구현을 통해 가장 작은 MPSoC부터 수백만 개의 로직 셀이 포함된 가장 큰 모놀리식 및 SSIT(Stacked Silicon Interconnect Technology) 디바이스에 이르기까지 모든 크기의 플랫폼과 맞춤형 설계를 생성할 수 있습니다. Vivado 구현은 머신 러닝 기반 예측기의 안내에 따른 최첨단 파티셔닝, 배치, 라우팅 알고리즘을 기반으로 구축됩니다. ML 모델을 적용하면 라우팅 지연 및 정체를 정확하게 예측하여 더 짧은 시간에 더 높은 QoR(Quality-of-Results)을 달성할 수 있습니다. 구현은 Vivado 프로젝트 및 Tcl 스크립트 내에서 성능, 활용성, 전력 및 합성 작업에 대한 설계 목표를 달성하기 위해 XDC(Xilinx Design Constraints)에 따릅니다.
구현은 사용 편의성을 위한 푸시 버튼 모드부터 성능 요구 사항이 가장 까다로운 설계를 처리하기 위한 정교한 맞춤형 Tcl 레시피에 이르기까지 모든 작동 모드를 지원합니다. 타이밍, 활용성, 전력, 기타 설계 품질 지표에 대한 상세한 분석은 배치 전, 배치 후, 라우팅 후 등 모든 컴파일 단계에서 수행할 수 있습니다. 설계 데이터베이스도 DCP(설계 체크포인트) 파일을 사용하여 모든 컴파일 단계에서 저장 및 복원할 수 있으며, 그에 따라 설계를 시각화하고 제한할 수 있습니다.
이미지 확대
주요 특징
-
Vivado 구현 프로세스
- 논리적 최적화:
합성 후에는 논리적 넷리스트가 활용도를 줄이고 논리 수준을 낮추기 위해 글로벌 수준에서 더욱 최적화됩니다.
- 전력 최적화:
활동 게이팅 기법을 사용하여 개입과 기능 변경 없이 최소한의 타이밍 영향으로 설계 전력이 줄어듭니다.
- 배치:
논리적 넷리스트 셀은 타이밍, 평면도, 수동 배치 요구 사항을 포함한 XDC 제약 조건에 따라 물리적 디바이스 리소스에 배치됩니다. 배치는 설계 계층 구조에 따라 IO 및 클러킹 리소스와 로직 클러스터를 포함한 글로벌 리소스로 시작됩니다. 글로벌 배치 단계 이후에는 세부 배치 및 배치 후 최적화 단계가 있습니다. 배치는 라우팅 지연과 라우팅 정체를 예측하는 ML 모델에 따르며, 이는 기존의 통계적 방법에 비해 더 높은 정확도와 빠른 컴파일을 제공합니다.
- 라우팅:
넷리스트 구성 요소 간의 연결은 물리적 디바이스 상호 연결 리소스에 할당됩니다. 배치와 마찬가지로 라우팅은 IO 및 클러킹과 같은 글로벌 리소스로 시작되어 XDC 타이밍 제약 조건에 따라 리소스 할당의 우선순위를 지정합니다. 최종 라우팅 단계는 승인 설정 및 대기 요구 사항을 충족하도록 경로를 더욱 최적화합니다. 배치 중 ML 라우팅 정체 예측을 사용하면 라우팅 정체가 완화됩니다.
- 물리적 최적화:
물리적 최적화는 배치 및 라우팅 전반에 걸쳐 발생하는 타이밍 기반 프로세스입니다. 논리적 최적화와 달리 물리적 최적화는 배치 및 라우팅을 기반으로 사용 가능한 가장 정확한 타이밍 데이터를 사용합니다. 타이밍 영향은 최적화를 수행했을 때만 타이밍이 개선되도록 평가됩니다. 최적화 기법에는 복제, 리타이밍, 레지스터 재배치뿐만 아니라 대상 아키텍처와 관련된 기타 최적화도 포함됩니다. 물리적 최적화를 배치 후 및 라우팅 후에 별도로 실행하여 결과를 더욱 개선할 수도 있습니다.
- 분석 기능의 중심:
구현 내의 모든 컴파일 단계에서 설계를 분석할 수 있습니다. 타이밍, 전력, 물리적 제약 조건을 수정하고 검증할 수 있는 포괄적인 XDC 제약 조건 관리 시스템입니다.
- 타이밍 요약 보고:
지정된 타이밍 목표에 맞춰 구현할 수 있도록 XDC 제약 조건을 지원하는 강력한 정적 타이밍 분석기입니다. 중요한 타이밍 경로, 클럭 상호 작용, CDC(클럭 도메인 크로싱)에 대한 타이밍 보고서를 생성합니다.
- 전력 보고:
전력 분석을 위한 XDC 전환 활동을 지원하는 벡터리스 전파입니다. 전력 소비량이 더 높은 영역을 식별하는 보고서를 생성합니다.
- 디바이스 보기:
설계 배치 및 라우팅의 그래픽 표현과 논리적 넷리스트 회로도입니다. 물리적 보기, 논리적 보기, 소스 코드 설계 보기 간의 크로스 프로빙을 통해 중요한 타이밍 경로의 소스를 빠르게 추적할 수 있습니다.
-
컴파일 옵션
- Vivado 구현
푸시 버튼 작동부터 다양한 컴파일 전략 탐색, 충족하기 어려운 요구 사항이 있는 설계의 반복적 흐름까지 모든 수준의 사용자 정의를 지원합니다.
- 구현
- Vivado 프로젝트 및 비프로젝트 흐름과 함께 작동
- 대화식으로 또는 Tcl을 사용하여 배치 모드로 실행 가능
- 여러 스레드를 실행하여 컴파일 시간 단축
- 다양한 설계 목표를 위한 솔루션을 탐색할 수 있는 컴파일 전략 제공
- 컴파일 가속 또는 타이밍 클로저의 우선순위를 지정할 수 있는 이전 실행의 데이터를 재사용하는 증분 컴파일 모드를 지원합니다.