Windows 本地 AI:使用 Windows ML 在 AMD NPU 上部署 AI 模型
Apr 21, 2026

设备端 AI 的兴起已重塑智能应用构建方式。借助 Windows ML 和 AMD 锐龙 AI NPU,开发者现在可以直接在 Windows 设备上部署高性能 AI 模型,从而加快推理速度、增强隐私保护并降低延迟。本博客将探讨如何利用 Windows ML 在 AMD NPU 上部署 ONNX 模型,内容涵盖从环境设置到执行的全过程。
什么是 Windows ML?
Windows ML 是 Microsoft Windows AI 平台的一部分,该平台包含三大核心组件:
Windows Foundry |
描述 |
| Windows AI API | 支持访问预训练 AI 模型,以执行光学字符识别 (OCR)、对象检测、图像分割和语言检测等常见任务 |
| Foundry Local | 一种面向大语言模型的设备端 AI 运行时,可自动检测可用硬件(CPU、GPU、NPU)并下载兼容的模型 |
| Windows ML | 一种共享运行时,可跨 CPU、GPU 和 NPU 管理 ONNX Runtime 执行提供程序 |

借助 Windows ML,开发者能够使用 C++、C# 或 Python 在本地运行 ONNX 模型,并跨不同的硬件加速器自动管理执行提供程序 (EP)。Windows ML 支持将来自 PyTorch、TensorFlow、TFLite 和 scikit-learn 等主流框架的模型转换为 ONNX 格式后进行部署。
Windows ML 的主要功能特性
- 自动执行提供程序管理:Windows ML 会根据可用硬件自动下载最新的执行提供程序
- 共享 ONNX Runtime:通过整个 Windows 系统共享的 ONNX Runtime,可有效减小应用大小
- 广泛的硬件支持:通过 ONNX Runtime 无缝支持 CPU、GPU 和 NPU
- 灵活的部署方式:支持多种编程语言和模型类型
为什么应用开发者应选择 Windows ML?
简化 AI 集成流程
Windows ML 消除了手动配置硬件和集成框架的复杂流程。该平台会自动检测并使用合适的硬件(NPU、GPU 或 CPU),无需开发者编写特定于设备的代码。而且,会自动下载和注册执行提供程序,省去了繁琐的设置过程。此外,Windows ML 可通过 ONNX 转换,无缝支持来自 PyTorch、TensorFlow、TFLite 和 scikit-learn 等框架的模型,让您的模型开发工作流程更加灵活。
降低开发复杂度
该平台通过提供整个 Windows 共享的 ONNX Runtime,充分减小应用大小,进而显著降低开发复杂度。得益于灵活的多语言支持,开发者可以根据偏好和项目需求,使用 C#、C++ 或 Python 部署解决方案。此外,统一的 API 设计确保相同的代码能在不同的硬件加速器上无缝运行,从而无需针对不同硬件平台重写代码。
优化用户体验
该解决方案通过设备端推理消除了网络往返,实现低延迟和更快的响应速度,从而优化用户体验。由于敏感数据始终在设备本地处理,用户得以完全掌控自己的信息,隐私得到充分保障。离线功能意味着,AI 功能在没有互联网连接的情况下也能完全正常工作,使应用在任何环境中都能可靠运行。此外,该解决方案还极具成本效益,因为它消除了云端 API 的使用费用和使用限制,让您无需持续投入就能无限执行 AI 操作。
获得稳定可靠的出色性能
该平台利用 AMD 锐龙 AI 处理器实现高效 AI 处理,凭借稳定可靠的出色性能,充分加速 AI 工作负载。模型会针对目标硬件自动完成优化,无需手动调优,确保在不额外增加开发工作量的情况下实现卓越性能。系统还具备灵活的回退功能,当 NPU 不可用时,可自动切换到 GPU 或 CPU,确保在不同硬件配置下都能保持正常运行,同时确保您的应用在任何设备上都能可靠运行。
AMD NPU 执行提供程序
Windows ML 会自动为 AMD 硬件注册多个执行提供程序:
- VitisAIExecutionProvider`:适用于 AMD 锐龙 AI 处理器
- MIGraphXExecutionProvider`:使用 ROCm 软件实现 AMD GPU 加速
- CPUExecutionProvider`:在默认 CPU 上运行
先决条件
在开始之前,请确保您具备以下条件:
- 操作系统:Windows 11 24H2(内部版本 26100 或更高版本)
- 开发工具:Visual Studio 2022(最新版本)、VS Code with AI Toolkit
- 编程语言:C++20 及更高版本或 Python 3.10-3.12
- 驱动程序:已安装最新的 AMD NPU 驱动程序
- SDK:Windows App SDK 1.8.5 或更高版本(包括 Windows ML)
模型部署工作流程
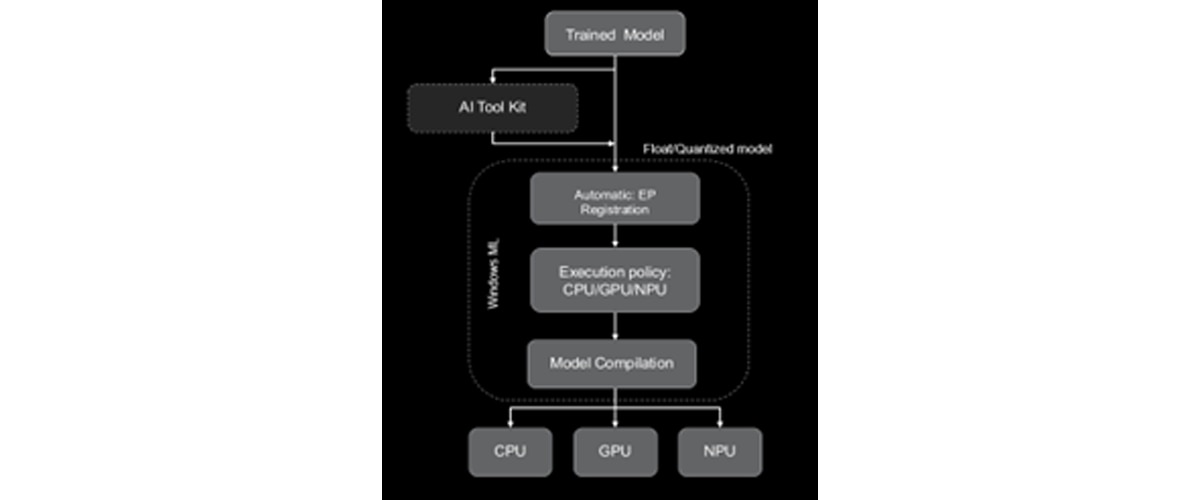
第 1 步:模型准备
首先,从 PyTorch、TensorFlow 或其他框架导出一个 FP32 ONNX 模型。您有两个选择:
- 直接使用原始 FP32 模型:Windows ML 会自动将其转换为 BF16 格式以供 NPU 执行
- 对模型进行量化:使用 VS Code AI Toolkit 以提升性能
- 对于 CNN 模型,使用 A8W8 量化
- 对于 Transformer 模型,使用 A16W8 量化
第 2 步:自动执行提供程序管理
Windows ML 会自动发现、下载并注册最新的执行提供程序。无需手动配置。
第 3 步:设置执行策略
配置您的会话以优先使用 NPU 执行推理,并在必要时自动回退到 CPU。
可用的执行策略:
- PREFER_CPU:使用 CPUExecutionProvider
- PREFER_GPU:使用 DmlExecutionProvider/MLGraphXExecutionProvider
- PREFER_NPU:使用 VitisAIExecutionProvider
第 4 步:模型编译
Windows ML 会为目标执行提供程序进行一次性的编译:
- 浮点模型:使用 VAIML 编译器自动转换为 BF16
- 量化模型:使用 X2/X1 编译器进行编译
第 5 步:运行推理
使用配置好的执行提供程序运行模型,享受 AMD NPU 带来的加速推理体验。
- ResNet:https://github.com/amd/RyzenAI-SW/tree/main/WinML/CNN/ResNet
- 基于 AMD NPU 的 OpenAI CLIP:https://github.com/amd/RyzenAI-SW/tree/main/WinML/Transformers/clip-vit-base-patch16
在 AMD NPU 上运行语言模型
在 Windows 上,主要可通过两种方法在 AMD NPU 上启用语言模型 (LLM/SLM):Foundry Local;Windows ML API 与 ONNX Runtime GenAI (OGA)。
Foundry Local 提供了一个简化的高级接口,消除了 NPU 部署的复杂流程。它会自动检测可用的 AMD 硬件,下载预优化的模型,并配置运行时环境,无需人工干预。这种方法在底层利用 Windows ML,同时提供简化的开发体验,非常适合快速原型开发和对部署便捷性要求较高的应用。
Windows ML API 与 OGA 则提供了一种更精细化的方法,非常适合需要直接控制推理流水线的开发者。Windows ML API 负责自动管理执行提供程序。通过 ONNX Runtime GenAI API,开发者可以加载自定义或预量化的 ONNX 模型,配置面向 NPU 的执行提供程序,并微调批量大小、序列长度和内存分配等推理参数。这种方法既支持 AMD 的预优化模型,也支持已量化并转换为 ONNX 格式的自定义模型,让开发者可以更加灵活地进行性能优化并与现有应用集成。
这两种方法利用相同的底层 NPU 加速能力,选择哪种方法取决于具体应用场景所需的控制级别和定制化程度。
系统要求
要运行语言模型,您的系统必须安装 Windows 10 或 Windows 11。最低配置要求包括 8GB RAM 和 3GB 可用磁盘空间;但是,为了充分提升性能,建议配置 16GB RAM 和 15GB 磁盘空间。开发的应用可以利用 AMD NPU 加速,在兼容的 AMD 锐龙 AI 处理器上实现高效 AI 处理。
针对语言模型,以下是可在 AMD NPU 上运行的不同部署方案:
通过 Foundry Local 部署预优化模型
这种部署方案提供了极少的控制权,非常适合没有深厚机器学习专业知识却想要快速上手的开发者。这种方案无需深厚的 AI/机器学习专业知识,只需对模型推理有基本了解,非常适合设置过程极其简单的快速原型开发和测试场景。
使用以下命令运行 Foundry Local 支持的模型:
cd <RyzenAI-SW>\WinML\LLM
winget install Microsoft.FoundryLocal
foundry model run phi-4-mini
示例输出:
Downloading phi-4-mini-instruct-vitis-npu:2...
[####################################] 100.00 % [Time remaining: about 0s] 53.7 MB/s
Unloading existing models. Use --retain true to keep additional models loaded.
🕘 Loading model...
🟢 Model phi-4-mini-instruct-vitis-npu:2 loaded successfully
Interactive Chat. Enter /? or /help for help.
Press Ctrl+C to cancel generation. Type /exit to leave the chat.
Interactive mode, please enter your prompt
> What is an AI accelerator?
🧠 Thinking...
🤖 An AI accelerator is specialized hardware designed to enhance the training and inference tasks of AI and machine learning models. Just as GPUs (Graphics Processing Units) are specialized hardware used to improve the training and execution of deep learning tasks, AI accelerators are similarly specialized and optimized hardware designed to provide faster and more energy-efficient training and inference operations for AI tasks.
有关分步说明,请参阅以下示例:
https://github.com/amd/RyzenAI-SW/tree/main/WinML/LLM#running-llm-using-foundry-local
通过 Windows ML 和 OGA API 部署自定义语言模型
此方案让您对部署过程拥有最大程度的控制权,非常适合需要完全掌控模型架构、进行自定义优化以及针对特定应用场景进行微调的高级用户。此方案要求具备高级 AI/机器学习专业知识,包括对模型架构、量化和优化技术的深入理解。
使用以下命令设置 Python 环境并安装依赖项:
conda create -n winml_olive python=3.10
conda activate winml_olive
cd <RyzenAI-SW>\WinML\LLM
pip install --force-reinstall -r requirements_olive.txt
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128
对于 `Phi-4-mini-Instruct` 模型,下载模型并使用 Olive recipe 进行量化/优化。
olive run --config Phi-4-mini-instruct_quark_vitisai_llm.json
然后,使用生成的 ONNX 模型以及 run_genai_llm.py 推理脚本,在 AMD NPU/CPU 上运行模型
cd <RyzenAI-SW>\WinML\LLM
conda create -n winml_llm --clone python=3.11
conda activate winml_llm
pip install -r .\requirements.txt
python run_genai_llm.py --model models\phi-4-mini-instruct-vai-npu --interactive
============================================================
Registering Execution Providers
============================================================
[INFO] Initializing WinAppSDK 2.0-experimental5...
[INFO] WinAppSDK 2.0-experimental5 initialized
[INFO] Available Execution Providers in WinML catalog:
(Note: CPU EP is built-in to ONNX Runtime and not shown here)
1. VitisAIExecutionProvider (Status: NOT_READY)
[INFO] Ensuring VitisAIExecutionProvider (state: 1)...
[INFO] VitisAIExecutionProvider is ready
[INFO] Registered VitisAIExecutionProvider to ONNX GenAI
[INFO] Library path: C:\Program Files\WindowsApps\MicrosoftCorporationII.WinML.AMD.NPU.EP.1.8_1.8.51.0_x64__8wekyb3d8bbwe\ExecutionProvider\onnxruntime_providers_vitisai.dll
C:\Users\dwchenna\github\dwchenna\RyzenAI-SW\WinML\LLM\run_genai_llm.py:347: RuntimeWarning: Shutdown object was not called before being garbage collected.
if not register_vitisai_ep():
============================================================
Loading model from: models\Phi-4-mini-instruct-vai-npu
============================================================
[INFO] Using VitisAI Execution Provider (configured in genai_config.json)
[INFO] Loading model (this may take a minute)...
[INFO] ✓ Model loaded successfully
[INFO] Creating tokenizer...
[INFO] ✓ Tokenizer created
============================================================
Interactive Mode
============================================================
Type your prompt and press Enter
Type 'quit', 'exit', or 'q' to exit
Press Enter without text for default prompt
============================================================
Prompt: What is AI accelerator?
Response: An AI accelerator is specialized hardware designed to enhance the efficiency and speed of training and deploying AI and deep learning models.
有关分步说明,请参阅 GitHub 示例:https://github.com/amd/RyzenAI-SW/tree/main/WinML/LLM#run-custom-llm-model-using-windows-ml-apis
基于 AMD NPU 的不同 LLM 部署方案汇总:
| 部署方案 | 控制 | 所需的专业知识 | 适合的应用场景 |
通过 Foundry Local 部署预优化模型 |
极低 |
无需深厚的 AI/机器学习知识;仅需对模型推理有基本了解 |
设置过程非常简单的快速原型开发与测试场景;适合没有深厚机器学习专业知识却想要快速上手的开发者 |
通过 Windows ML 和 OGA API 部署自定义语言模型 |
极高 |
需要具备高级 AI/机器学习专业知识;深入理解模型架构、量化及优化技术 |
适合需要完全掌控模型架构、进行自定义优化及针对特定应用场景微调的高级用户 |
表 2:基于 AMD NPU 的不同 LLM 部署方案汇总
其他示例
在 RyzenAI-SW 资源库中探索更多高级示例:
- ResNet:https://github.com/amd/RyzenAI-SW/tree/main/WinML/CNN/ResNet
- GoogleBERT Transformer:https://github.com/amd/RyzenAI-SW/tree/main/WinML/Transformers/GoogleBert
- 基于 AMD NPU 的 OpenAI CLIP:https://github.com/amd/RyzenAI-SW/tree/main/WinML/Transformers/clip-vit-base-patch16
- 基于 AMD NPU 的 LLM:https://github.com/amd/RyzenAI-SW/tree/main/WinML/LLM
结语
AMD 提供了多种部署路径,以满足不同专业水平的开发者的需求。无论您是希望通过 Foundry Local 实现快速部署,还是需要通过 Windows ML 和 OGA API 部署自定义模型以获得最大程度的控制,您都能找到符合需求的部署方案。预优化的 AMD 模型在性能和易用性之间实现了出色平衡。
参考资料
- AMD Ryzen AI 文档,WinML:Ryzen AI 软件 — Ryzen AI 软件 1.7.0 文档
- AMD Ryzen AI-SW GitHub 资源库,WinML 示例:https://github.com/amd/RyzenAI-SW/tree/main/WinML [CD1]
- Windows ML 文档:Windows 上的 Microsoft Foundry | Microsoft Developer
- ONNX Runtime GenAI (OGA) 文档:Microsoft/onnxruntime-genai:Generative AI extensions for onnxruntime(面向 onnxruntime 的生成式 AI 扩展)


Related Blogs
-
AMD Advancing AI 2026 前瞻:精彩内容抢先看
抢先了解“AMD Advancing AI 2026”大会,探索塑造 AI 未来的核心议题、会议环节及创新技术。了解行业领军者如何携手合作,共同探讨实际应用场景以及在企业范围内规模化部署 AI 的策略。
July 14, 2026
-
-
AMD 亮相 Microsoft Build 2026
在旧金山举办的 Microsoft Build 2026 大会上,开发者、工程师和 AI 构建者们齐聚一堂,AMD 举办了四场实操工作坊,向参会者全方位展示 AMD AI 生态系统
June 12, 2026
-
AMD Silo AI 与 Delphyr AI 强强联手,推动实用临床 AI 规模化落地
AMD Silo AI 与 Delphyr AI 联合推出可扩展、隐私保护优先的临床 AI 解决方案:实现更快速的电子病历 (EHR) 检索、高性能嵌入以及无缝工作流程集成。
June 02, 2026
-
跳出概念炒作:将 AI PC 的潜在价值转化为切实商业收益
AI PC 正在重塑企业战略。了解 AMD 计算连续体如何帮助首席信息官跳出概念炒作,通过部署 AI 创造切实商业价值。
April 23, 2026
-
基于 AMD 锐龙 AI Max+ 处理器和 Radeon GPU,在本地高效运行 Hermes Agent
本指南演示了如何在配备 AMD 锐龙 AI Max+ 处理器和 Radeon GPU 的 Windows 系统上,使用 WSL2 和 LM Studio 运行 Hermes Agent。
April 21, 2026
-
为现代工作室的生产引擎添能助力:AMD 亮相 NAB 2026
2026 年美国广播电视展 (NAB Show) 将于 4 月 18 日至 22 日在拉斯维加斯举行。整个行业正发生着令人振奋的新变化,我们期待在展会上与您相见!
April 17, 2026
-
针对 AMD Versal™ 自适应 SoC 设计,采用渐进式方法加速系统级验证
系统级验证变得越来越复杂。依托 AMD Vitis™ 软件平台,开发者可以采用渐进式验证方法。
April 17, 2026







