AMD PACE - 高性能平台感知计算引擎
Apr 09, 2026

简介
AMD PACE(AMD 平台感知计算引擎)是经过优化的高性能推理服务框架,适用于基于现代 CPU 的服务器。在本博文中,我们将了解 AMD PACE 如何通过利用第五代 AMD EPYC(霄龙)处理器的微架构优势,为 Transformer 模型优化推理性能,尤其是在数据中心环境中。我们将展示这些优化背后的技术方法,并分享性能基准测试结果。性能评估结果均基于基准测试。有关 AMD PACE 的更多信息,请访问:https://github.com/amd/AMD-PACE
技术总览:AMD PACE 推理服务框架
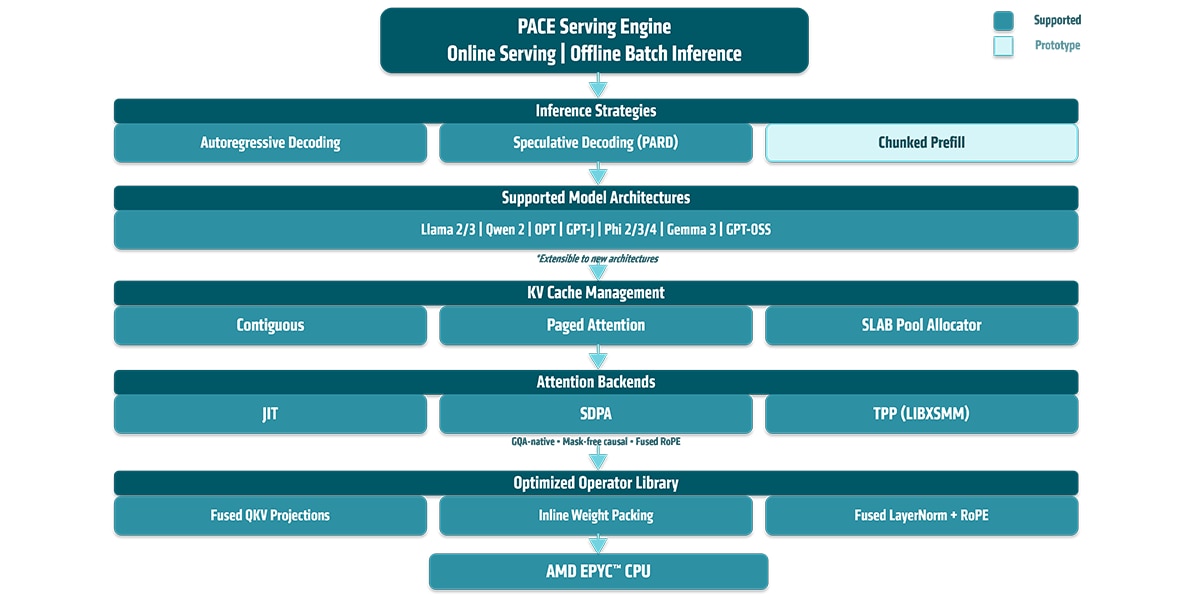
AMD PACE 采用一个统一调度器,通过工作负载分区来运行预填充(完整提示词处理)和单 Token 解码阶段,从而使这些阶段能够高效地协同执行。
作为完整的推理服务堆栈,它支持连续批量解码以进行标准的自回归生成,并针对推测解码进行优化以实现更高的吞吐量。
AMD PACE 可面向公开和主权 AI 模型提供大语言模型推理服务。支持的公开模型包括:Llama4 Causal、GPT-OSS、Gemma3、Phi3/4、Qwen 2、OPT 和 GPT-J;支持的主权 AI 模型涵盖参数规模从 20 亿到 70 亿的 Sarvam AI 模型。
AMD PACE 支持一系列广泛的注意力管理方案,并配备面向 AMD CPU 的高性能后端和优化库。
基于第五代 EPYC(霄龙)处理器架构的高效推理
AMD EPYC(霄龙)9005 系列服务器 CPU 采用混合多芯片设计,旨在应对数据中心面临的各类挑战。这种全新架构的核心优势是,在虚拟化和云环境中提供卓越性能、密度和效率,同时支持新型 AI 工作负载。 基于 EPYC(霄龙)9005 系列的服务器利用矢量化神经网络指令 (Vectorized Neural Network Instructions, VNNI) 来加速神经网络推理。每个插槽配备 128 个物理核心(256 个逻辑核心),时钟频率为 2.6GHz;在双插槽配置下,采用 BFloat16 精度时,理论硬件性能可达到 90-100 万亿次运算/秒 (TOPS)。
深入探究:AMD PACE 如何加速推理性能
AMD PACE 可实现先进的推理服务,并针对 AMD EPYC(霄龙)CPU 对大语言模型流水线中的每一层进行优化,包括调度、KV 缓存管理、注意力机制和 MLP 内核,涵盖从服务策略到内核级优化的方方面面。
1.服务部署策略
PACE 支持在线服务部署和离线批量推理服务,采用三种互补模式:
- 连续批量处理:PACE 支持连续批量处理推理请求以充分提高吞吐量。
- 最大批量解码:通过批量解码对请求进行分组,以充分提高硬件利用率。调度和填充策略经过调优,可在不同的序列长度和批量大小下维持高吞吐量。
- 推测解码:多 Token 解码针对 AMD 并行草稿 (Parallel Draft, PARD) 推测解码进行了优化(详见之前的博文),并通过高效批量处理来处理多个推测 Token,充分降低开销。
2.模型级优化
在支持的所有架构(Llama 2/3、Qwen 2、OPT、GPT-J、Phi 2/3/4、Gemma 3、GPT-OSS)上,PACE 都会应用模型级转换以提高效率:
- 最小化内存操作:消除冗余转置以及 KV 头扩展操作(例如重复操作)。GQA 在注意力后端原生处理,避免了标准框架中主导 CPU 解码的成本高昂的扩展-重塑-复制 (expand-reshape-copy) 模式。
- 经过优化的注意力内核:移除冗余的因果掩码 (causal-mask) 操作,以提高吞吐量和缩短首 Token 延迟 (Time to First Token)。
- 跨层操作:融合 LayerNorm 和最优 RoPE 内核,可改善数据重用,而跨步写入 (strided write) 可改善顺序内存访问。
3.KV 缓存管理
PACE 提供了三种 KV 缓存后端,每种都针对 AMD EPYC(霄龙)处理器的不同工作负载特征而设计:
- 连续分配器 (Contiguous Allocator) 将 KV 缓冲区存储在连续的内存区域中,并支持密集内核执行。
- SLAB 内存池分配器 (SLAB Pool Allocator) 使用按序列级分配的块,支持可变块大小,以及单个预分配的 BF16 内存池(采用固定大小的块,且会根据 L2 缓存大小自动调优)。该分配器可简化内存管理,并支持连续批量处理,其中预填充和解码序列可以在同一个池中共存。
- 分页注意力 (Paged Attention) 机制可实现 vLLM 分页注意力设计,专门针对大批次和长上下文进行优化。
4.注意力后端
PACE 通过可插拔的后端分派注意力:
- 支持的后端:支持三种后端:
- JIT (OneDNN):融合 matmul-softmax-matmul 流水线,支持 MHA 和 GQA。
- SLAB:一个统一的 AVX-512 注意力调度器,根据查询长度对每个序列进行分类,并将其路由到合适的内核:支持 GQA 的解码(采用 online softmax)、用于推测校验的多 Token 解码以及分块式预填充。
- PAGED:vLLM 风格的分页注意力机制。
5.MLP
MLP 层使用与 L1 和 L2 缓存大小对齐的内核分块,使 matmul 运算保留在缓存中,从而高效利用内存带宽。权重矩阵被预打包成与 SIMD 分块维度匹配的分块式布局,无需进行运行时重排
6.内核级优化
在算子级别,PACE 通过应用融合和布局优化,使数据保留在芯片上:
- 内联权重打包和融合 QKV 投影 (Fused QKV Projections) 可减少内存流量及内核启动开销。
- 经过优化的内核为跨 AMD EPYC(霄龙)代际的线性代数原语提供平台调优的实现方案。
- 针对 SDPA 的因果分块跳过
- 缓存分块微内核和内联 RoPE 融合。
评估
| 特性 | 规格 |
| CPU | AMD EPYC(霄龙)9755,代号“Turin” |
| 架构 | Zen 5 |
| 核心 | 每个插槽 128 个核心 |
| RAM | 1.5TB |
| 精度 | BF16 |
| 插槽数 | 2 |
在本节中,我们使用各种大语言模型进行实验,旨在展示 PACE 在各类模型与场景下,相对 vLLM 0.17 所具备的性能优势。
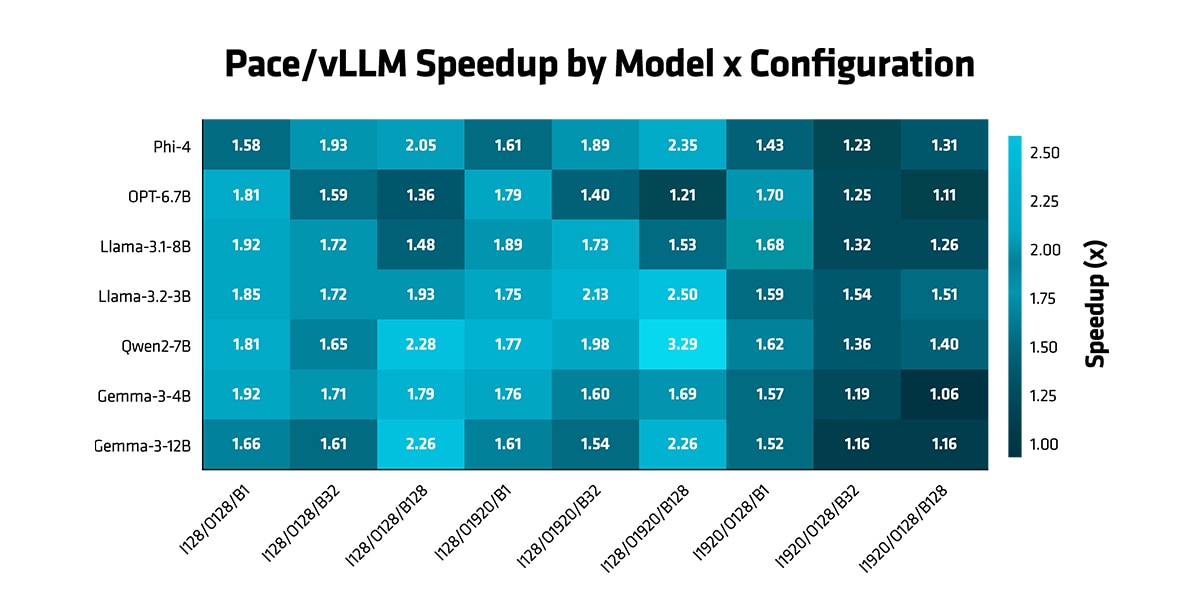
- 自回归模式:在所有测试配置下,AMD PACE 性能表现始终优于 vLLM,实现了 1.60 倍的几何平均加速比。
图 2(PACE/vLLM 加速比)展示了,针对多种不同架构和规模的模型,在不同输入长度 (128, 1920)、输出长度 (128, 1920) 和批量大小 (1, 32, 128) 下,PACE 相对于 vLLM 的性能优势:Phi-4、OPT-6.7B、Llama-3.1-8B、Llama-3.2-3B、Qwen2-7B、Gemma-3-4B 和 Gemma-3-12B。
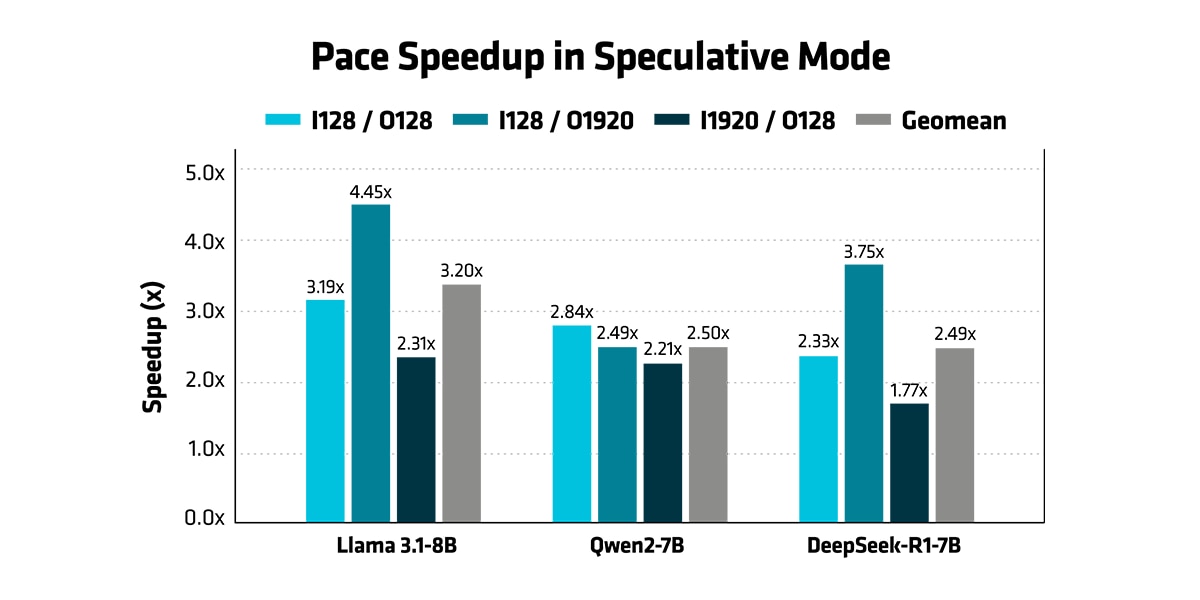
- 推测模式:对于 Llama 3.1-8B、Qwen2-7B 和 DeepSeek-R1-7B,在批量大小为 1 时,AMD PACE 推测解码相比 vLLM 自回归模式实现了 2.5 至 3.2 倍的几何平均加速比。在 Llama 模型长输出序列下,峰值加速比可达 4.45 倍。在所有三个模型以及各种输入/输出配置下,PACE 均展现出显著优势,这证明 AMD PACE 带来的优化能够应用于不同的模型架构。
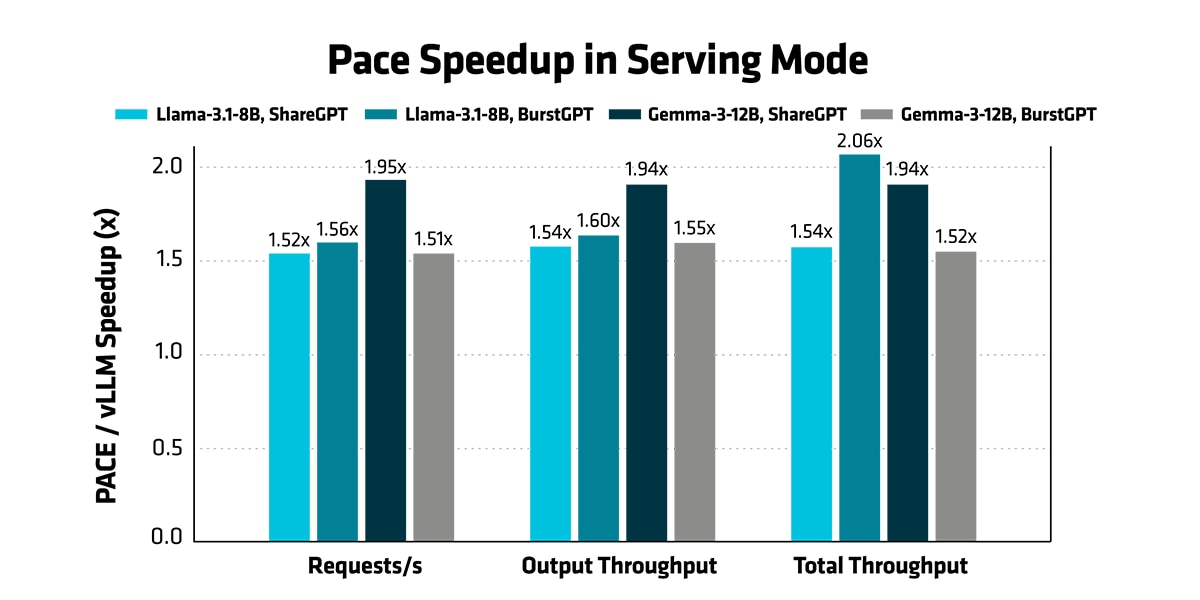
- 服务部署模式:在服务部署模式下,AMD PACE 在 ShareGPT 和 BurstGPT 工作负载跟踪测试中,相比 vLLM 实现了 1.51 至 2.06 倍的端到端吞吐量提升。所有实验均使用 vLLM 的原生 bench serve 基准测试套件,并在现实场景、压力测试和最大吞吐量服务部署模式下分别进行评估。
结语
AMD PACE 标志着基于第五代 AMD EPYC(霄龙)处理器的大语言模型推理取得重大突破。PACE 可降低 Token 间延迟、提升吞吐量和效率,同时在基准测试中保持准确性。AMD PACE 开源版本即将发布,我们期待广大开发者社区能够采纳这些优化成果,并在此基础上持续迭代,打造新一代 AI 系统。我们计划在未来支持多模态大语言模型推理,并针对下一代 EPYC(霄龙)核心和 SoC 进行进一步优化。
资源
如需详细了解如何使用 AMD PACE 增强 AI 模型,请参阅我们的文档,并关注即将发布的开源版本。我们期待收到您的反馈,并与您携手推动 AI 推理变革。
- AMD PACE GitHub 代码库:https://github.com/amd/AMD-PACE
- PARD GitHub 代码库:https://github.com/AMD-AGI/PARD
- 白皮书:https://www.amd.com/content/dam/amd/en/documents/epyc-business-docs/white-papers/5th-gen-amd-epyc-processor-architecture-white-paper.pdf
- 数据手册:https://www.amd.com/content/dam/amd/en/documents/epyc-business-docs/datasheets/amd-epyc-9005-series-processor-datasheet.pdf
附注
附注
配备 AMD EPYC(霄龙)9755 处理器的系统显示,使用 AMD PACE PARD 时,Llama 3 8B 在自回归模式下相比 vLLM 0.17 实现了 1.60 倍的几何平均加速比。在推测模式下,当批量大小为 1 时,加速比提升至 4.45 倍。在服务部署模式下,端到端加速比最高达 2.06 倍。AMD 于 2026 年 4 月 2 日进行了测试;结果可能因配置、使用方式、软件版本和优化程度而异。
系统配置
系统型号:Supermicro
CPU:AMD EPYC(霄龙)9755 128 核处理器(2 个插槽,每个插槽 128 个核心,每个核心 2 个线程)
NUMA 配置:每个插槽 1 个 NUMA 节点
内存:1536GB(24 个 DIMM,6400MT/s,64GiB/DIMM)
主机操作系统: Ubuntu 24.04.2 LTS 6.8.0-86-generic
系统 BIOS 供应商: American Megatrends International, LLC
附注
附注
配备 AMD EPYC(霄龙)9755 处理器的系统显示,使用 AMD PACE PARD 时,Llama 3 8B 在自回归模式下相比 vLLM 0.17 实现了 1.60 倍的几何平均加速比。在推测模式下,当批量大小为 1 时,加速比提升至 4.45 倍。在服务部署模式下,端到端加速比最高达 2.06 倍。AMD 于 2026 年 4 月 2 日进行了测试;结果可能因配置、使用方式、软件版本和优化程度而异。
系统配置
系统型号:Supermicro
CPU:AMD EPYC(霄龙)9755 128 核处理器(2 个插槽,每个插槽 128 个核心,每个核心 2 个线程)
NUMA 配置:每个插槽 1 个 NUMA 节点
内存:1536GB(24 个 DIMM,6400MT/s,64GiB/DIMM)
主机操作系统: Ubuntu 24.04.2 LTS 6.8.0-86-generic
系统 BIOS 供应商: American Megatrends International, LLC


Related Blogs
-
AMD Advancing AI 2026 前瞻:精彩内容抢先看
抢先了解“AMD Advancing AI 2026”大会,探索塑造 AI 未来的核心议题、会议环节及创新技术。了解行业领军者如何携手合作,共同探讨实际应用场景以及在企业范围内规模化部署 AI 的策略。
July 14, 2026
-
-
Gartner 将 AMD 评为 Gartner® AI 供应商竞争中的当前领先企业
Gartner 在一份报告中将 AMD 称为企业级 AI 服务器 CPU 领域的当前领跑者。
June 24, 2026
-
-
-
AMD 亮相 Microsoft Build 2026
在旧金山举办的 Microsoft Build 2026 大会上,开发者、工程师和 AI 构建者们齐聚一堂,AMD 举办了四场实操工作坊,向参会者全方位展示 AMD AI 生态系统
June 12, 2026
-
-
AMD Silo AI 与 Delphyr AI 强强联手,推动实用临床 AI 规模化落地
AMD Silo AI 与 Delphyr AI 联合推出可扩展、隐私保护优先的临床 AI 解决方案:实现更快速的电子病历 (EHR) 检索、高性能嵌入以及无缝工作流程集成。
June 02, 2026







