AMD PACE - High-Performance Platform Aware Compute Engine
Apr 08, 2026

Introduction
AMD PACE (AMD Platform Aware Compute Engine) is a high-performance inference server optimized for modern CPU-based servers. In this blog, we will explore how AMD PACE optimizes inference performance for Transformer models, particularly in data center environments by leveraging the micro-architectural strengths of the 5th Gen AMD EPYC™ processor. We present the technical approach behind these optimizations and share results from performance benchmarks. The results of performance evaluations are based on benchmark tests. You can learn more about AMD PACE at https://github.com/amd/AMD-PACE
Technical Overview: AMD PACE Inference Server
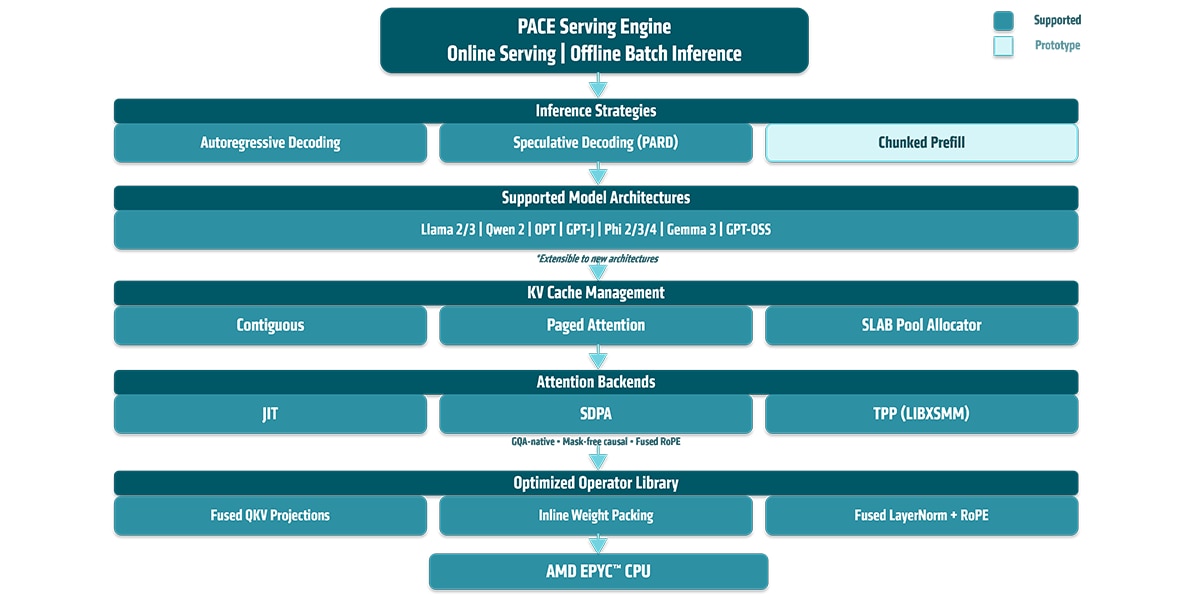
AMD PACE uses a unified scheduler that runs prefill (full-prompt processing) and single-token decode with workload partitioning, so these phases execute together efficiently.
As a serving stack, it supports continuous and batch decode for standard auto-regressive generation and optimized for speculative decode for higher throughput.
AMD PACE serves LLM inference for both public and sovereign AI model families. Supported public model families include, Llama4 Causal, GPT-OSS, Gemma3, Phi3/4, Qwen 2, OPT and GPT-J; sovereign AI support covers Sarvam AI models from 2B to 7B parameters.
AMD PACE enables a wide range of Attention management schemes with performance backends and optimized libraries for AMD CPUs.
Efficient Inference on the 5th Gen EPYC™ Processor Architecture
The AMD EPYC™ 9005 Series sever CPUs uses a hybrid, multi-chip design cores to address challenges in data centers. This new architecture prioritizes leadership performance, density, and efficiency in virtualized and cloud environments while supporting new AI workloads. Servers based on the EPYC 9005 Series leverage Vectorized Neural Network Instructions (VNNI) to accelerate neural network inference. Each socket, featuring 128 physical (256 logical) cores and operating at a clock frequency of 2.6 GHz, delivers a theoretical hardware performance of 90-100 tera operations per second (TOPS) using BFloat16 precision across two sockets.
Deep Dive: How AMD PACE Accelerates Inference Performance
AMD PACE implements state-of-the-art inference serving and optimizes each layer of the LLM pipeline; from scheduling and KV cache management to attention and MLP kernels, for AMD EPYC CPUs from serving strategies to kernel-level optimizations.
1. Serving Strategies
PACE supports online serving and offline batch inference with three complementary modes:
- Continuous batching: PACE enables contiguous batching of inference requests to maximize throughput.
- Maximal batch decode: Batched decoding groups requests to maximize hardware utilization. Scheduling and padding strategies are tuned to sustain high throughput across varying sequence lengths and batch sizes.
- Speculative decoding: Multi-token decode is optimized for AMD Parallel Draft (PARD) speculative decoding (see our previous blog for details) and uses efficient batching to handle multiple speculated tokens with minimal overhead.
2. Model-Level Optimizations
Across all supported architectures (Llama 2/3, Qwen 2, OPT, GPT-J, Phi 2/3/4, Gemma 3, GPT-OSS), PACE applies model-level transformations to improve efficiency:
- Minimized memory operations: Redundant transposes and KV head expansions (e.g., repeats) are eliminated. GQA is handled natively in the attention backend, avoiding the costly expand-reshape-copy pattern that dominates CPU decode in standard frameworks.
- Optimized attention kernels: Redundant casual-mask operations are removed, to improve throughput and Time to First Token.
- Cross-layer operations: Fused LayerNorm and optimal RoPE kernels improve data reuse, while strided writes improve sequential memory access.
3. KV Cache Management
PACE provides three KV cache backends, each designed for different workload profiles for AMD EPYC processor
- Contiguous Allocator stores KV buffers in contiguous memory regions and supports dense kernel execution.
- SLAB Pool Allocator uses sequence-level allocated blocks, supports variable block sizes, and a single pre-allocated BF16 memory pool with fixed-size blocks auto-tuned based on L2 cache size. It simplifies memory management and supports continuous batching where prefill and decode sequences can coexist in the same pool.
- Paged Attention implements the vLLM paged-attention design, tailored for large batches and long context lengths.
4. Attention Backends
PACE dispatches attention through pluggable backends:
- Backend support: Three backends are available:
- JIT (OneDNN): Fused matmul-softmax-matmul pipelines with MHA and GQA.
- SLAB: A unified AVX-512 attention dispatcher that classifies each sequence by query length and routes it to a suitable kernel: GQA-aware decode with online softmax, multi-token decode for speculative verification or tiled prefill.
- PAGED: vLLM Style Paged attention.
5. MLP
MLP layers use kernel blocking aligned to L1 and L2 cache sizes so that matmuls remain cache-resident, and memory bandwidth is used efficiently. Weight matrices are pre-packed into blocked layouts that match the SIMD tile dimensions, eliminating the runtime reordering
6. Kernel-Level Optimizations
At the operator level, PACE applies fusions and layout optimizations that keep data on chip:
- Inline weight packing and fused QKV projections reduce memory traffic and kernel launch overhead.
- Optimized kernels provide platform-tuned implementations for linear algebra primitives across AMD EPYC generations.
- Causal tile-skipping for SDPA
- Cache-blocked micro-kernels and inline RoPE fusion.
Evaluation
| Feature | Specification |
| CPU | AMD EPYC™ 9755, codename “Turin” |
| Architecture | Zen 5 |
| Cores | 128 cores per socket |
| RAM | 1.5 TB |
| Precision | BF16 |
| Sockets | 2 |
In this section, we conduct experiments with various LLMs to demonstrate the benefits of the PACE across a wide range of models and scenarios over vLLM 0.17.
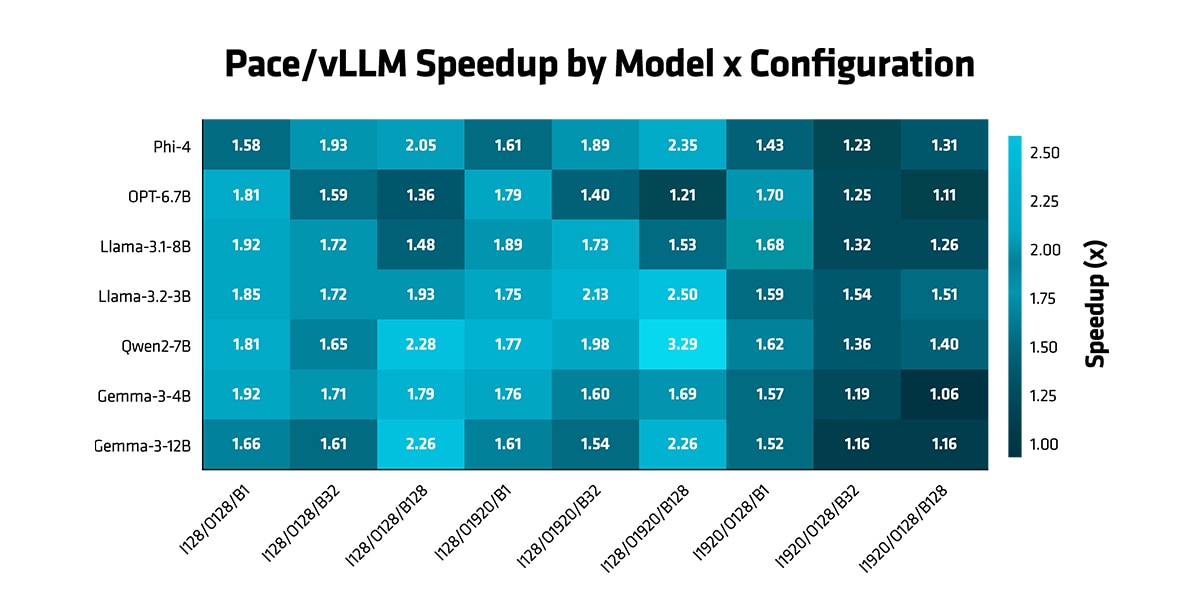
- Auto-regressive mode: AMD PACE consistently outperforms vLLM across all evaluated configurations, achieving a geometric mean speedup of 1.60x.
Figure 2 (PACE/vLLM Speedup) demonstrates these gains across input lengths (128, 1920), output lengths (128, 1920), and batch sizes (1, 32, 128) over a diverse set of models spanning multiple architectures and scales : Phi-4, OPT-6.7B, Llama-3.1-8B, Llama-3.2-3B, Qwen2-7B, Gemma-3-4B, and Gemma-3-12B.
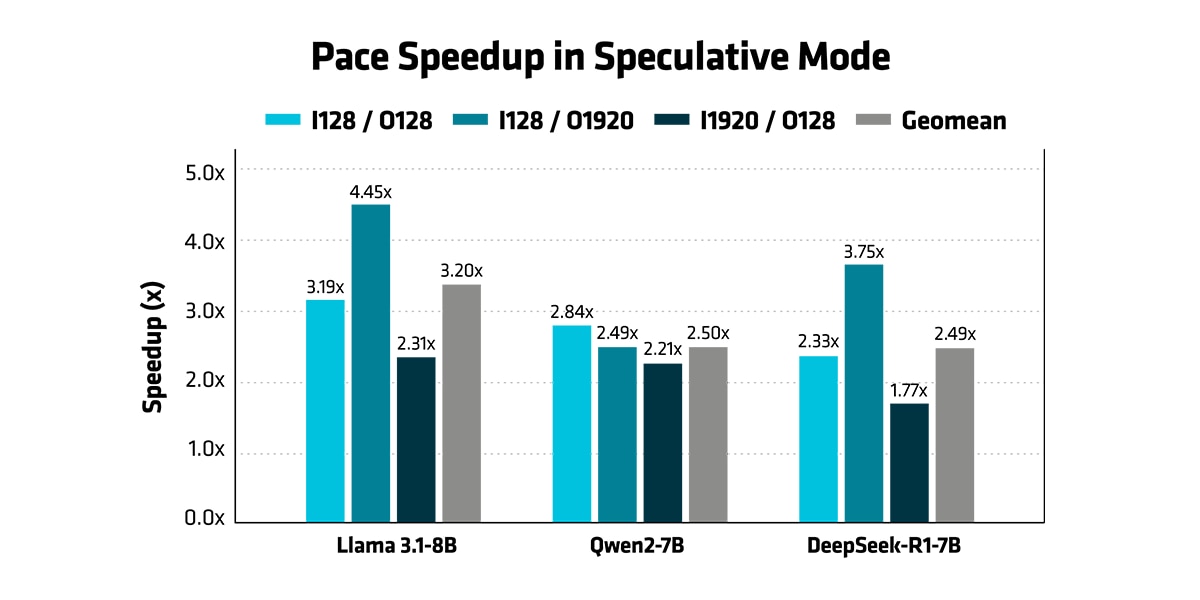
- Speculative mode: AMD PACE speculative decoding achieves 2.5–3.2x geometric mean speedup over vLLM autogressive mode across Llama 3.1-8B, Qwen2-7B, and DeepSeek-R1-7B at batch size 1, peaking at 4.45x on Llama with long output sequences. The gains are consistent across all three models and input/output configurations, demonstrating that AMD PACE's optimizations generalize across model architectures.
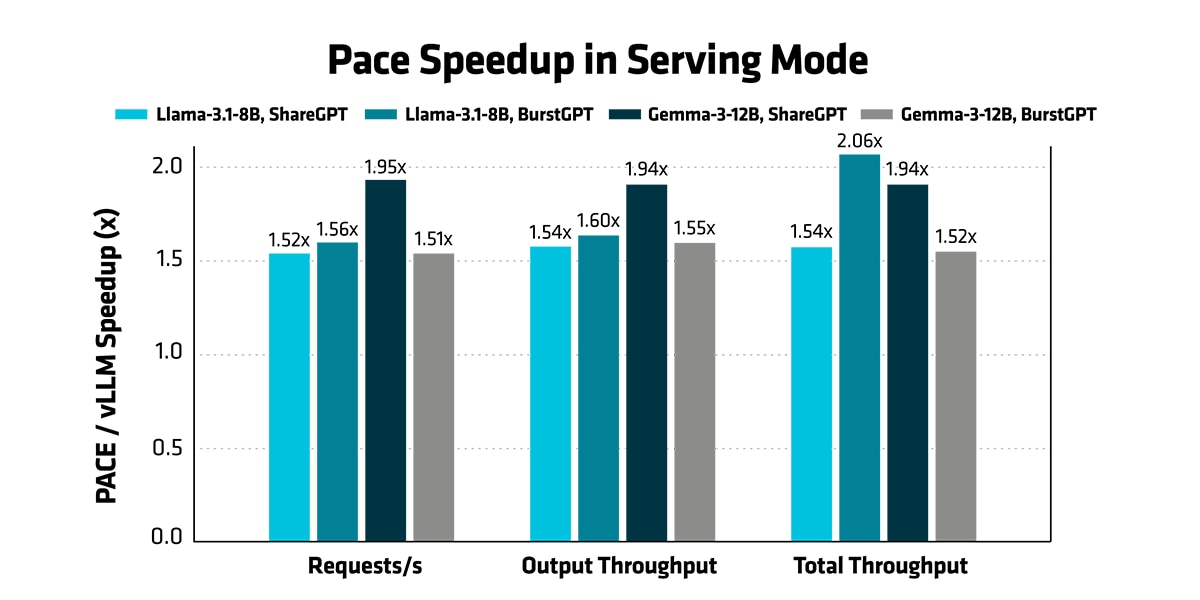
- Serving Mode: In serving mode, AMD PACE achieves a 1.51–2.06x end-to-end throughput improvement over vLLM on both ShareGPT and BurstGPT workload traces. All experiments use vLLM’s native bench serve benchmark suite and are evaluated under realistic, stress test, and maximum throughput serving modes.
Conclusion
AMD PACE marks a major step forward for LLM inference on 5th Gen AMD EPYC processors. It reduces inter-token latency, increases throughput, and improves efficiency while maintaining accuracy in benchmark tests. With the upcoming AMD PACE’s open-source release, we look forward to the broader community adopting and building upon these improvements for the next generation of AI systems. Future plans include support for multi-modal LLM inference and further enhancements for next-generation EPYC cores and SoCs.
Resources
Please refer to our documentation for more information on how to enhance your AI models with AMD PACE and look out for the upcoming open-source release. We look forward to hearing from you and working with you as we continue to revolutionize AI inference.
- AMD PACE GitHub repository: https://github.com/amd/AMD-PACE
- PARD GitHub repository: https://github.com/AMD-AGI/PARD
- Whitepaper: https://www.amd.com/content/dam/amd/en/documents/epyc-business-docs/white-papers/5th-gen-amd-epyc-processor-architecture-white-paper.pdf
- Data sheet: https://www.amd.com/content/dam/amd/en/documents/epyc-business-docs/datasheets/amd-epyc-9005-series-processor-datasheet.pdf
Footnotes
Footnote
A system configured with an AMD EPYC™ 9755 processor shows that, with AMD PACE PARD, Llama 3 8B running in autoregressive mode achieves a 1.60x geometric mean speedup over vLLM 0.17. In speculative mode, the speedup increases up to 4.45x at batch size 1. In serving mode, end-to-end speedup is up to 2.06x. Testing done by AMD on 04/02/2026, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro
CPU: AMD EPYC 9755 128-Core Processor (2 sockets, 128 cores per socket, 2 threads per core)
NUMA Config: 1 NUMA node per socket
Memory: 1536 GB (24 DIMMs, 6400 MT/s, 64 GiB/DIMM)
Host OS: Ubuntu 24.04.2 LTS 6.8.0-86-generic
System Bios Vendor: American Megatrends International, LLC
Footnotes
Footnote
A system configured with an AMD EPYC™ 9755 processor shows that, with AMD PACE PARD, Llama 3 8B running in autoregressive mode achieves a 1.60x geometric mean speedup over vLLM 0.17. In speculative mode, the speedup increases up to 4.45x at batch size 1. In serving mode, end-to-end speedup is up to 2.06x. Testing done by AMD on 04/02/2026, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
System Model: Supermicro
CPU: AMD EPYC 9755 128-Core Processor (2 sockets, 128 cores per socket, 2 threads per core)
NUMA Config: 1 NUMA node per socket
Memory: 1536 GB (24 DIMMs, 6400 MT/s, 64 GiB/DIMM)
Host OS: Ubuntu 24.04.2 LTS 6.8.0-86-generic
System Bios Vendor: American Megatrends International, LLC


Related Blogs
-
Open Standards, Real Solutions: AMD at SIGGRAPH 2026
AMD heads to DigiPro and SIGGRAPH 2026 to discuss open standards, production technology, and the fine art of Gaussian splatting.
July 17, 2026
-
FastFlowLM Joins AMD to Advance AI Inference
The FastFlowLM team has joined AMD, marking another key step in AMD’s strategy to advance AI performance and efficiency across the stack.
July 17, 2026
-
Running Cloud Agents? Your Most Important Upgrade Could be an AMD Zen 5 CPU
As agents begin navigating applications, coordinating tools and completing real work, the local CPU is becoming a critical part of the AI execution pipeline.
July 16, 2026
-
From Vector Search to Agentic RAG: Building an Enterprise Research Analyst with hipVS — ROCm Blogs
Learn how to build an agentic RAG research assistant using hipVS GPU-accelerated vector search on AMD Instinct GPUs, with multi-query decomposition, parallel retrieval, and cited sources synthesis.
July 14, 2026
-
When a Faster Kernel Doesn’t Speed Up Serving: Profiling FP8 KV Cache on AMD Instinct MI308X — ROCm Blogs
Learn how a 34% faster FP8 KV cache kernel delivered 0% E2E speedup, and how profiling attribution exposed the hidden dtype-cast cost on MI308X.
July 14, 2026
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026
-
Local Image and Video Generation on AMD Ryzen™ AI Max+ Processor (Windows) — ROCm Blogs
Run ComfyUI natively on Windows on AMD Ryzen AI Max+ with ROCm 7.2.1—SDXL, Flux, and video workflows on the Radeon 8060S, no WSL.
July 13, 2026
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026







