AMD Quark Model Optimization Library Now Available as Open-Source
May 12, 2025

AMD is excited to open-source AMD Quark, a new model optimization library, with a focus on AI model quantization. AMD Quark (called “Quark” from this point on) is designed to streamline and enhance the process of model quantization for a wide range of deployment scenarios. In today's rapidly evolving AI landscape, efficient model inference is paramount, and model optimization techniques, such as quantization and pruning, play a crucial role in achieving this. Quark is built with flexibility and broad compatibility in mind, aiming to empower users with the best quantization strategies for their specific needs. In this blog, we will introduce Quark highlighting its design goals and capabilities. We will provide an overview of some of the key quantization flows for various hardware backends.
AMD has a variety of hardware (HW) backends for accelerating AI workloads for different user scenarios. They range from data center GPUs (e.g. AMD Instinct™ MI300X), data center CPUs (AMD EPYC ™ series), to AMD Ryzen™ AI (NPU + iGPU for AI PCs) to embedded SoCs. Quark is designed to be a unified tool for model optimization for all these different backends. Quark provides unified API, features, and tooling for various quantization flows needed by these hardware backends.
AMD Quark - Overview
At its core, Quark is agnostic to the downstream execution (inference) runtime. This is necessary to support different input model formats, ecosystems, and execution stacks for different hardware. The two popular model ecosystems that Quark supports are PyTorch and ONNX. It can load and optimize models from native PyTorch format, Hugging Face format(s), and ONNX model format. Quark produces models that can be loaded in different execution stacks, such as native PyTorch, ONNXRuntime, vLLM, SGLang and Llama.cpp. Some of the popular output formats that are supported are native PyTorch, ONNX, Hugging Face format, including multiple Hugging Face sub-formats such as Quark’s native format and autofp8, autoawq, and GGUF.
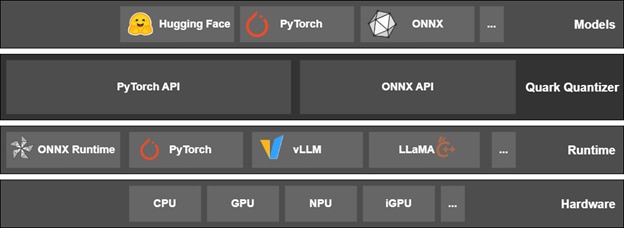
Quark adopts a strategic approach by offering three popular user-facing quantization flows to cater to diverse user preferences and existing workflows. This strategy aims to “meet customers where they are”. The first is the PyTorch flow, which operates on a PyTorch model to produce the quantized counterpart. Quark produced models are composable with PyTorch native technologies like torch.compile. The second flow operates on ONNX model and produces a quantized ONNX model. The third flow is a hybrid flow, which starts with a PyTorch model, quantizes it, and exports it for efficient execution on ONNXRuntime using open-source OnnxRuntime-GenAI library’s model builder. In addition to these flows, users can compose other flows easily using the Quark APIs.
Quark has rich feature support along various dimensions of quantization, such as datatypes, quantization algorithms, export formats, and quantization scenarios. Quark has support for post-training quantization (PTQ), fine-tuning, and quantization aware training (QAT). For PTQ, Quark supports dynamic quantization, full ahead-of-time (AOT) static quantization and anything in-between as needed by the user. Quark has support for a wide range of datatypes - in general, it supports various integer and floating-point precisions for weights and activations, INT4/8/16, FP8, BF16, BFP16. It also supports advanced low-precision formats such as OCP Microscaling (MX) formats (e.g. mxFP4, mxFP6). For LLMs, KVCache quantization is also supported for various datatypes. Weights can be quantized at different granularities, including per tensor, per channel, and per group. Quark has a wide range of quantization algorithms, ranging from simple ones such as Min-Max, Percentile, to advanced ones such as SmoothQuant, AWQ, GPTQ, to the latest cutting-edge algorithms, such as rotation algorithms (e.g. QuaRot). Quark flexible API allows the users to compose multi-algorithm quantization pipelines to get the quantized model.
Quark is closely integrated with the PyTorch and ONNX ecosystems. This is highlighted in the following sections. In addition, Quark has a close integration with open-source ecosystem. For example, Quark is integrated with Hugging Face (HF) Transformer library and is a first-class quantization tools in HF. Quark has strong integration with the popular vLLM inference and serving library in that Quark models can be loaded and executed in open source vLLM. We plan to expand integration with other popular OSS libraries soon.
Additionally, Quark provides tooling to users for the end-to-end quantization flow. For example, users can specify their own calibration dataset for quantization. Also, model evaluation is a critical step in assessing compressed large language models (LLMs) to ensure they meet accuracy, fluency, and safety requirements before deployment. Quark provides practical and efficient evaluation tooling designed to meet the needs of modern LLM evaluation. It provides support for diverse evaluation metrics, especially for LLMs, such as Perplexity (PPL) for text generation, Rouge and Meteor for summarization and translation. Finally, Quark integrates the popular lm-evaluation-harness which provides additional metrics, enabling additional benchmarks such as HellaSwag, Winogrande, ARC Challenge, and Open LLM Leaderboard.
AMD Quark is being used extensively in production deployment scenarios for both internal and external AMD customers. Details of various AMD stacks and their customers are captured in the following sections. AMD Quark has also served high-accuracy models for AMD MLPerf Inference submissions in the past, including the latest one MLPerf 5.0.
AI Hardware Backends
AMD Instinct MI300x GPU
AMD Instinct GPU series serves as high-performance data center accelerators, engineered to meet the significant computational demands of modern AI workloads. To effectively leverage MI GPUs, AMD provides a comprehensive open-source software ecosystem. In this ecosystem, AMD Quark is a key tool that provides robust quantization pipelines designed for large-scale models like LLMs and VLMs running on MI GPUs. It facilitates seamless PyTorch-to-PyTorch quantization, enabling developers to efficiently optimize transformer-based models. Furthermore, Quark supports inference workloads executed via widely used frameworks, such as vLLM and SGLang.
Quark offers a diverse set of quantization techniques for MI-series GPUs, including support for FP8 and INT8 data types across activations, weights, and the KV cache. It also provides FP8 attention quantization, all aimed at maximizing performance by leveraging the computational power and memory bandwidth of AMD GPUs while maintaining high accuracy—typically above 99%. For extremely large models, Quark adopts a two-level INT4-FP8 quantization scheme, combining compact INT4 weight storage with efficient FP8 GEMM to achieve nearly 4× model compression. The library demonstrates excellent scalability through its multi-GPU quantization capabilities, efficiently handling ultra-large models like Llama-3.1-405B. Additionally, Quark incorporates structured pruning methods to further optimize model performance.
To broaden user access, Quark provides optimized models on Hugging Face (under the AMD organization), where pre-quantized FP8 versions of popular models (e.g., Llama, Mixtral, Grok-1) are available. These models can be directly loaded and deployed via vLLM. For more details, see the vLLM documentation.
The production-readiness of Quark is underscored by its role in the AMD MLPerf LLM submissions. In these benchmarks, Quark provided quantized model pipelines that satisfied strict accuracy and runtime requirements, demonstrating its reliability. Benchmark results, such as those for Mistral 7B v0.3 detailed in the AMD ROCm blog, show significant throughput improvements (up to 2.1x) with minimal accuracy loss using FP8 quantization.
![Figure 1: Mistral 7B v0.3 FP16 throughput Vs latency with TP1 ISL 2048, OSL 2048, BS 64[1]](/content/dam/amd/en/images/blogs/designs/projects/technical-blogs/amd-quark-model-optimization-library-now-available-as-open-source/fig-1-mistral-7B.png)
Figure 1: Mistral 7B v0.3 FP16 throughput Vs latency with TP1 ISL 2048, OSL 2048, BS 64[1]
![Figure 2: Mistral 7B v0.3 FP8 throughput Vs latency with TP1 ISL 2048, OSL 2048 [1]](/content/dam/amd/en/images/blogs/designs/projects/technical-blogs/amd-quark-model-optimization-library-now-available-as-open-source/fig-2-mistral7b.png)
Figure 2: Mistral 7B v0.3 FP8 throughput Vs latency with TP1 ISL 2048, OSL 2048 [1]
To assist users, Quark provides an quick start guide along with example scripts and recipes, facilitating the deployment of quantized models on MI GPUs with minimal setup. For developers who have limited GPU resources to optimize large models or prefer to skip the optimization steps, we currently offer quantized checkpoints of popular models in the Quark quantized OCP FP8 models collection. Quark will expand its feature set by adding support for new data types like MXFP4 and MXFP6, enabling on-the-fly quantization in vLLM and SGLang, and delivering more community-focused recipes and open benchmarks.
AMD Ryzen AI Processor
AMD Ryzen AI represents a significant evolution in PC architecture, integrating dedicated AI acceleration hardware directly onto Ryzen processors alongside traditional CPU (Zen) and GPU (RDNA) cores. This dedicated engine, based on AMD XDNA Neural Processing Unit (NPU) architecture unlocks the ability to run AI workloads directly on the device with better performance and power efficiency as compared to the CPU or GPU. AMD Ryzen AI software is specifically optimized for lower-precision data types like FP16, BF16, BFP16, as well as INT16, INT8, and even INT4. These compressed models can deliver significantly better performance. Quark gets distributed with Ryzen AI releases and provides high-accuracy models for Ryzen workloads that maintain accuracy while providing substantial performance gains.
Quark provides at least two quantization flows to serve the Ryzen AI architecture. The two flows are:
1. ONNX-to-ONNX quantization. AMD Quark quantizer can quantize models already in the ONNX format, making it an effective solution for optimizing a wide range of workloads—including vision, audio, and language models. This capability allows developers to take pre-existing ONNX models (such as those used for image classification, object detection, segmentation, audio processing, or BERT-based natural language tasks often in FP32 precision) and apply Quark's post-training quantization techniques to convert them into lower-precision formats like INT16, INT8, BF16, BFP16 or FP16. Quark intelligently analyzes the ONNX graph, applying quantization strategies that significantly reduce the computational complexity and memory footprint inherent in convolutional neural networks. The resulting quantized ONNX model can then be directly executed using the ONNX Runtime, yielding great performance improvements. This direct ONNX-to-ONNX quantization workflow streamlines the optimization process for diverse applications, leading to substantial gains in inference speed and efficiency, especially when deployed on hardware with strong support for low-precision computations via ONNX Runtime execution providers.
In addition to standard quantization options such as symmetric/asymmetric modes, per-tensor/per-channel granularity, and common calibration methods like minmax, percentile, and minMSE, Quark also supports BF16 and BFP16 quantization and mixed-precision quantization. It integrates multiple advanced accuracy-preserving strategies such as CLE, AdaQuant, AdaRound, QuaRot and auto-search-based tuning. These features work together to ensure minimal accuracy drop while enabling aggressive low-precision quantization. To make things easier, AMD Quark includes an "Auto Search" feature within its ONNX-to-ONNX workflow. This feature provides automation for determining an effective quantization configuration, requiring minimal user intervention, in some common scenarios.
2. OnnxRuntime GenAI (OGA) Flow for LLM models. AMD Ryzen AI architecture seamlessly integrates dedicated NPUs, AMD Radeon™ Graphics (iGPU), and AMD Ryzen processing cores (CPU) to enable advanced AI capabilities on a heterogeneous processor. This hybrid architecture optimizes the deployment of Large Language Models (LLMs), leveraging state-of-the-art hardware across various computational engines within the processor to deliver exceptional performance in AI applications. The AMD Quark quantization tool and Microsoft's ONNX Runtime Generative AI Model Builder (aka OGA Model builder) provide a powerful workflow for deploying LLMs efficiently on PCs equipped with AMD Ryzen AI hardware. Developers typically begin with an LLM implemented in PyTorch and then leverage AMD Quark to apply post-training quantization, significantly compressing the model’s weights to INT4 and reducing the computational footprint in a way that is optimized for AMD's underlying architecture. Finally, the next step involves using the OGA Model Builder to export this quantized PyTorch model into the ONNX format. The model builder is essential because it is designed to handle the complex structures and dynamic operations inherent in modern LLMs, such as key-value cache management and specialized attention mechanisms, which often pose significant challenges or are unsupported by the standard PyTorch ONNX exporter. By successfully packaging the quantized model and its intricate generative components into an optimized ONNX graph, this workflow enables the creation of deployable LLM artifacts that can subsequently be run with high performance and power efficiency on Ryzen AI hardware, utilizing the dedicated NPU and iGPU through ONNX Runtime. Check out this blog post showing how AMD Quark and OGA enable smooth DeepSeek distilled LLM deployment on Ryzen AI PCs.
![Figure 3: DeepSeek Performance on Ryzen AI 300 [2]](/content/dam/amd/en/images/blogs/designs/projects/technical-blogs/amd-quark-model-optimization-library-now-available-as-open-source/fig-3-deepseek-perf-rai.png)
Figure 3: DeepSeek Performance on Ryzen AI 300 [2]
AMD Quark and OnnxRuntime-GenAI Model Builder are active projects. Our roadmap includes exciting items, such as quantization recipes for Llama 4 and DeepSeek for local AI assistants and optimized deployment for multilingual and VLM models on-device. For developers who have limited GPU resources to optimize large models or prefer to skip the optimization steps, we currently offer quantized checkpoints of popular models in the Quark quantized INT4 ONNX models collection and Quark quantized INT8 ONNX models collection.
AMD EPYC Processor
The AMD EPYC is a line of high-performance server processors designed to provide excellent performance and scalability for a wide range of demanding workloads in data centers and cloud computing environments. To put it in perspective, AMD EPYC processors have seen significant growth, with their Server CPU market share reaching a record high of 34% in Q2 2024, up from nearly zero in 2017.
To leverage the EPYC CPU capabilities, AMD Quark is integrated with torch.compile(), which is a cornerstone feature introduced in PyTorch 2.0, that offers a way to significantly accelerate PyTorch code execution with minimal code changes. Quark’s torch.compile integration unblocks critical use cases, such as significantly improving inference performance, leading to lower latency and higher throughput for deployed models. The performance gains are achieved through AMD ZenTorch (AMD ZenDNN PyTorch plugin) serving as a specialized backend within the PyTorch torch.compile ecosystem, specifically designed to optimize and accelerate the execution of PyTorch models on AMD hardware platforms. ZenTorch operates on the torch.compile produced computational graph, which translates this graph into highly efficient machine code tailored for AMD's Zen CPU architectures. It employs optimization strategies like kernel fusion and optimized memory access patterns. For CPU execution, ZenTorch leverages specific AMD hardware instructions and memory hierarchies, often incorporating highly tuned low-level routines from the AMD Optimizing CPU Libraries (AOCL) to maximize performance. This integrated approach ultimately enables users to achieve significant speedups for their PyTorch workloads running on AMD systems.
By leveraging Quark to quantize a model before the torch.compile workflow, developers can seamlessly apply post-training quantization to models, such as DLRMv2, converting them from FP32 precision down to INT8. Subsequently, the ZenTorch backend takes the computation graph, incorporating the INT8 quantization specifics, and generates highly optimized kernels tailored for AMD architectures. This synergistic approach—combining Quark's precision reduction, torch.compile's graph capture, and ZenTorch's hardware-specific code generation—drastically reduces computational demands and memory bandwidth. As illustrated in the accompanying chart, this yielded substantial performance improvements for the DLRMv2 model during inference, achieving throughput gains of at least 2x for the INT8 quantized model compared to the original FP32 baseline when executed via the optimized ZenTorch runtime.
![Figure 4: Speedups with Quark + ZenTorch (INT8, Quark 0.8) [3]](/content/dam/amd/en/images/blogs/designs/projects/technical-blogs/amd-quark-model-optimization-library-now-available-as-open-source/fig-4-speedup-w-quark.png)
Figure 4: Speedups with Quark + ZenTorch (INT8, Quark 0.8) [3]
Summary
Quark represents a significant step forward in the commitment from AMD to provide comprehensive and flexible solutions for model optimization. By offering multiple user-centric flows, a rich feature set, and a focus on broad compatibility, Quark aims to empower researchers and developers to efficiently deploy high-performance quantized models across diverse hardware and software ecosystems. We are excited about the potential of Quark and look forward to sharing more updates as it evolves.

Contributors

Related Blogs
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026
-
Enabling Language-specific Reasoning in Multilingual Models with Reinforcement Learning — ROCm Blogs
Learn how to train multilingual reasoning models with reinforcement learning and extend context windows on AMD Instinct GPUs.
July 23, 2026
-
Introducing AMD ROCm™ Infera: Scaling Goodput for Agentic AI with Distributed Inference Orchestration — ROCm Blogs
Explore how AMD ROCm Infera orchestrates distributed inference to scale goodput for agentic AI on AMD Instinct GPUs.
July 22, 2026
-
Onboard and Deploy Custom Models in AMD AI Workbench — ROCm Blogs
Learn how to deploy custom models in AMD AI Workbench, utilizing the AIM Engine, orchestration, scaling, profile parameters and API keys.
July 22, 2026
-
Serve Kimi-K2.5-MXFP4 on MI355X with ATOM — ROCm Blogs
Serve Kimi-K2.5-MXFP4 on MI355X with ATOM and gfx950 block-scaled FP4 kernels for optimized LLM inference.
July 22, 2026
-
Hyperloom - Autonomous Agentic Inference Optimization for AMD GPUs — ROCm Blogs
Hyperloom is a new open-source, agentic system aimed at automating the time-consuming task of optimizing end-to-end inference workloads.
July 22, 2026
-
Introducing ROCm™ AMD Infinity Context: A Purpose-Built KV Cache Tier for Distributed Inference — ROCm Blogs
Explore ROCm AMD Infinity Context (AIC), AMD's open KV cache tier built on AMD Infinity Storage for distributed LLM inference.
July 21, 2026








尾註
[1] A system configured with an AMD Instinct™ MI300X GPUs shows a 2.1x performance improvement when comparing FP8 to FP16 for Mistral 7B v0.3 model inference using TP = 1 (specifically achieving around 11,000 tps vs 5,200 tps at a 60,000ms latency). Testing conducted by AMD Performance Labs as of January 15, 2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
AMD: Supermicro AS - 8125GS-TNMR2 with 2x AMD EPYC 9654 Processors, 8x AMD MI300X (192GB, 750W) GPUs, 1 NUMA node per socket, 2.2 TiB (24 DIMMs, 4800 mts, 96 GiB/DIMM), Root drive + Data drive combined: 2x 960GB Samsung MZ1L2960HCJR-00A07 4x 3.84TB Samsung MZQL23T8HCLS-00A07, Ubuntu 22.04.4 LTS with Linux kernel 5.15.0-116-generic, host GPU driver 6.2.1, System BIOS 1.8 GPU: SMC FW 00.85.112.142.
Nvidia: Supermicro AS -8125GS-TNHR with 2x AMD EPYC 9654 Processors, 8x NVIDIA H100 (80GiB, 700W) GPUS, 1 NUMA node per socket, 2.3 TiB (24 DIMMS, 4800 mts, 96 GB/DIMM), Data drives: 8x 7 TiB INTEL SSDPF2KX076T1 NVMe SSDs, Root drive: 1.75 TiB Micron MTFDDAK1T9TDS-1AW1ZA, Ubuntu 22.04.5 LTD with Linux kernel titan 6.8.0-51-generic, CUDA 12.6.r12.6/compiler.35059454_0+ NVIDIA-SMI 560.35.03, VBIOS 96.00.74.00.01.
[2] Performance tested by AMD on February 2025, using a CRB System with the following specifications. PC manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers.
SYSTEM CONFIGURATION
AMD Ryzen AI 9 HX 370, Radeon 890M graphics @ 2.6GHz and 32G DDR5@75000MT/s, NPU Driver version: 32.0.203.240, and GPU Driver version: 32.0.12010.8007.
[3] On average, a system configured with an AMD EPYC 9554 shows 2.19% speedup across different batch sizes when compared to PyTorch 2.5.0 Eager mode. Testing done by AMD on 04/09/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
AMD Instinct ™ MI300X GPU platform, System Model: Supermicro AS-8125GS-TNMR2, CPU: 2x AMD EPYC 9554 64-Core Processor, NUMA: 2 NUMA node per socket. NUMA auto-balancing disabled/ Memory: 1536 GiB (24 DIMMs x 64 GiB Micron Technology MTC40F2046S1RC48BA1 MGCC DDR5 4800 MT/s), Disk: 61,448 GiB (8x NTEL SSDPF2KX076T1 7,681 GB), GPU: 8x AMD Instinct MI300X 192GB HBM3 750W, Host OS: Ubuntu 24.04, BMD Firmware version: 01.03.35, System BIOS: 3.2, Host GPU Driver: (amdgpu version): ROCm 6.3.3
尾註
[1] A system configured with an AMD Instinct™ MI300X GPUs shows a 2.1x performance improvement when comparing FP8 to FP16 for Mistral 7B v0.3 model inference using TP = 1 (specifically achieving around 11,000 tps vs 5,200 tps at a 60,000ms latency). Testing conducted by AMD Performance Labs as of January 15, 2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
AMD: Supermicro AS - 8125GS-TNMR2 with 2x AMD EPYC 9654 Processors, 8x AMD MI300X (192GB, 750W) GPUs, 1 NUMA node per socket, 2.2 TiB (24 DIMMs, 4800 mts, 96 GiB/DIMM), Root drive + Data drive combined: 2x 960GB Samsung MZ1L2960HCJR-00A07 4x 3.84TB Samsung MZQL23T8HCLS-00A07, Ubuntu 22.04.4 LTS with Linux kernel 5.15.0-116-generic, host GPU driver 6.2.1, System BIOS 1.8 GPU: SMC FW 00.85.112.142.
Nvidia: Supermicro AS -8125GS-TNHR with 2x AMD EPYC 9654 Processors, 8x NVIDIA H100 (80GiB, 700W) GPUS, 1 NUMA node per socket, 2.3 TiB (24 DIMMS, 4800 mts, 96 GB/DIMM), Data drives: 8x 7 TiB INTEL SSDPF2KX076T1 NVMe SSDs, Root drive: 1.75 TiB Micron MTFDDAK1T9TDS-1AW1ZA, Ubuntu 22.04.5 LTD with Linux kernel titan 6.8.0-51-generic, CUDA 12.6.r12.6/compiler.35059454_0+ NVIDIA-SMI 560.35.03, VBIOS 96.00.74.00.01.
[2] Performance tested by AMD on February 2025, using a CRB System with the following specifications. PC manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers.
SYSTEM CONFIGURATION
AMD Ryzen AI 9 HX 370, Radeon 890M graphics @ 2.6GHz and 32G DDR5@75000MT/s, NPU Driver version: 32.0.203.240, and GPU Driver version: 32.0.12010.8007.
[3] On average, a system configured with an AMD EPYC 9554 shows 2.19% speedup across different batch sizes when compared to PyTorch 2.5.0 Eager mode. Testing done by AMD on 04/09/2025, results may vary based on configuration, usage, software version, and optimizations.
SYSTEM CONFIGURATION
AMD Instinct ™ MI300X GPU platform, System Model: Supermicro AS-8125GS-TNMR2, CPU: 2x AMD EPYC 9554 64-Core Processor, NUMA: 2 NUMA node per socket. NUMA auto-balancing disabled/ Memory: 1536 GiB (24 DIMMs x 64 GiB Micron Technology MTC40F2046S1RC48BA1 MGCC DDR5 4800 MT/s), Disk: 61,448 GiB (8x NTEL SSDPF2KX076T1 7,681 GB), GPU: 8x AMD Instinct MI300X 192GB HBM3 750W, Host OS: Ubuntu 24.04, BMD Firmware version: 01.03.35, System BIOS: 3.2, Host GPU Driver: (amdgpu version): ROCm 6.3.3