ZenDNN 4.2: Introducing a New Plugin Architecture
Aug 02, 2024
Author: Shailen Sobhee, Sr. Product Marketing Manager, AI Group
What is AMD ZenDNN?
At the heart of ZenDNN lies a toolbox comprising of highly optimized low-level math libraries which are highly tuned for AMD EPYC™ CPUs. However, we hear you: a day-to-day AI Developer probably wouldn’t want to experiment with low-level libraries. That is why AMD expanded ZenDNN’s toolbox with easy-to-use Plug-ins for the popular frameworks on the market, notably PyTorch, TensorFlow and ONNX Runtime.
In the upcoming chapters, you will peek further into what we’ve done behind the scenes in ZenDNN. We will then continue with how to get the Plug-ins, how to install them and finally explore some code snippets to help get you started. We then wrap-up this blog with some performance results to entice you to give our plug-ins a try.
Let’s begin!
ZenDNN: under the hood
To boost inference performance on AMD EPYC CPUs, AMD implemented optimizations in ZenDNN at multiple levels. For instance, at the graph-level, we looked into graph pattern identification in order to find best recipes to reorder and fuse graphs for efficient graph compilation and execution. At the operator level, we exploit as much multi-threading as possible and seek avenues to fuse operations for best performance. At the micro-kernel level, we leverage the highly-optimized AOCL (AMD-Optimized Compute Library) BLIS library including third-party performance libraries such as FBGEMM to ensure we squeeze out the last bits of performance from the CPU.
The optimizations are provided to our users through the plug-ins and from a high-level, the architecture boils down to:
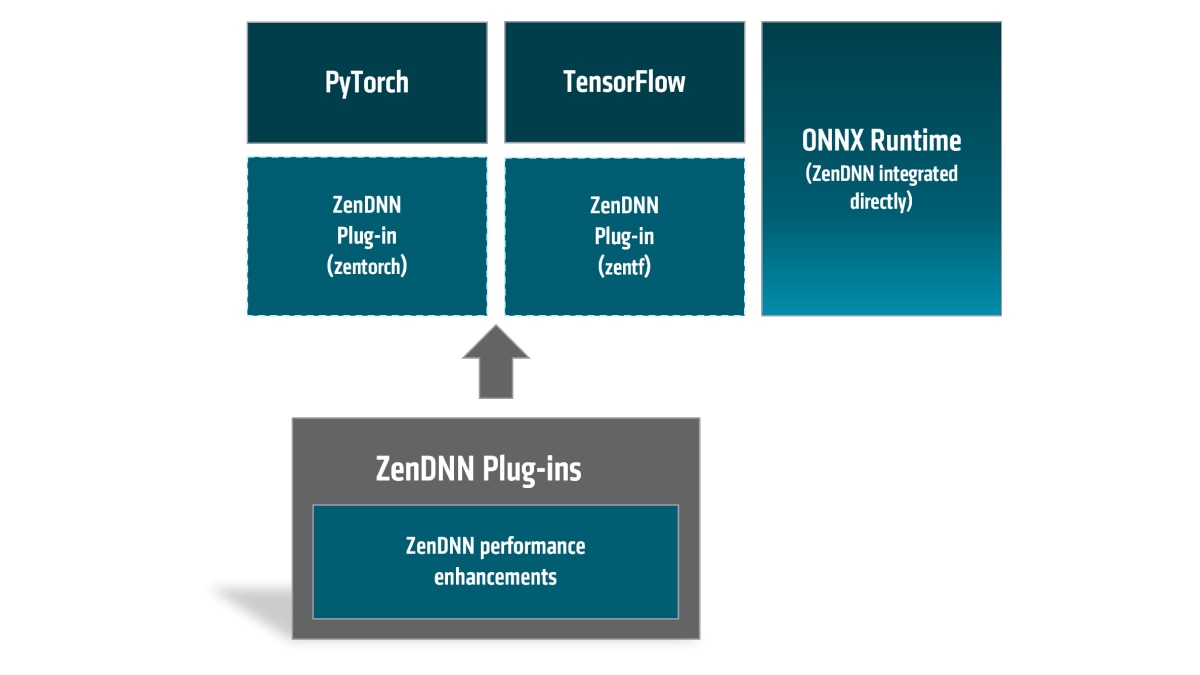
Getting Started with the ZenDNN Plug-ins
To keep the length of this blog digestible, we will focus on the ZenDNN plug-in for PyTorch also known as zentorch.
ZenDNN plug-in for PyTorch (zentorch)
The zentorch extension to PyTorch has been developed to leverage the torch.compile graph compilation flow, and all optimizations can be enabled by a call to torch.compile with zentorch as the backend. Multiple passes of graph level optimizations run on the torch.fx graph and provide further performance acceleration.
With version 4.2 of the plug-in, zentorch is compatible with base versions of PyTorch v2.0 onwards. This release supports FP32 and BF16 as datatypes, including Auto Mixed Precision (AMP).
AMP leverages both FP32 and BF16 data types for different operations. Certain operations, such as linear layers and convolutions, perform significantly faster with bfloat16. Conversely, operations like reductions benefit from the wider dynamic range of float32. By assigning the optimal data type to each operation, mixed precision can effectively reduce the runtime and memory usage of your network.
To install zentorch, you can either use the Binary Release or build from source. For the purpose of this blog, we will use the binary release since it’s the easiest method.
You can get the binaries either on PyPI or from our the ZenDNN landing page: https://www.amd.com/en/developer/zendnn.html
For a full overview of the supported version of Python and operating systems, please consult the Support Matrix table.
Step 1: Prepare your Python environment
If you do not have a Python environment already, execute the commands below to create one. For this blog, we use Anaconda.
conda create -n zentorch-v4.2.0-zendnn-v4.2-rel-env python=3.11 -y
conda activate zentorch-v4.2.0-zendnn-v4.2-rel-env
Step 2: Install PyTorch and zentorch
conda install pytorch==2.1.2 cpuonly -c pytorch
pip install zentorch==4.2.0
You may wish to test the installation by calling, in a Python prompt:
import zentorch
zentorch.__version__
Expected output: '4.2.0'
Examples:
In the example below, you can see the minimal code changes needed to leverage zentorch.
import torch
from PIL import Image
import requests
import numpy as np
import zentorch
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224")
model = torch.compile(model, backend='zentorch')
processed_input = processor(image, return_tensors='pt').to(device="cuda")
with torch.no_grad():
_ = model(**processed_input)
Recommendations
It is recommended you use torch.no_grad() for optimal inference performance with zentorch.
CNN-based models
For torchvision CNN models, set dynamic=False when calling for torch.compile as follows:
model = torch.compile(model, backend='zentorch', dynamic=False)
with torch.no_grad():
output = model(input)
NLP & RecSys
If you are using Hugging Face NLP models, optimize as follows:
model = torch.compile(model, backend='zentorch')
with torch.no_grad():
output = model(input)
Large Language Models (LLMs)
For Hugging Face LLM models, there are a few more points to consider.
If output is generated through a call to the model directly, optimize it as follows:
model = torch.compile(model, backend='zentorch')
with torch.no_grad():
output = model(input)
If output is generated through a call to model.forward, optimize it as follows:
model.forward = torch.compile(model.forward, backend='zentorch')
with torch.no_grad():
output = model.forward(input)
If output is generated through a call to model.generate, optimize it as follows:
First, optimize the model.forward with torch.compile instead of model.generate. However, you proceed with generating the output through a call to model.generate
model.forward = torch.compile(model.forward, backend='zentorch')
with torch.no_grad():
output = model.generate(input)
Note: If the same model is optimized with torch.compile for multiple backends within a single script, it is recommended you use torch._dynamo.reset() before calling torch.compile on that model.
Performance results
We stress-tested zentorch through a range of popular models and compared the performance with the stock framework, meaning, PyTorch without any extensions or modifications. The results are telling – with an impressive 1.7x performance boost on some workloads.
We ran the benchmarks on a dual socket system sporting AMD EPYC™ 9654 CPUs with SMT turned off. Each socket has 96 physical cores and therefore, in total, we had 192 physical cores. This system offered a whopping 768MB of L3 cache. While the hardware out-of-the-box provides solid performance, we want to show that with software, there is always a possibility to squeeze even more performance.
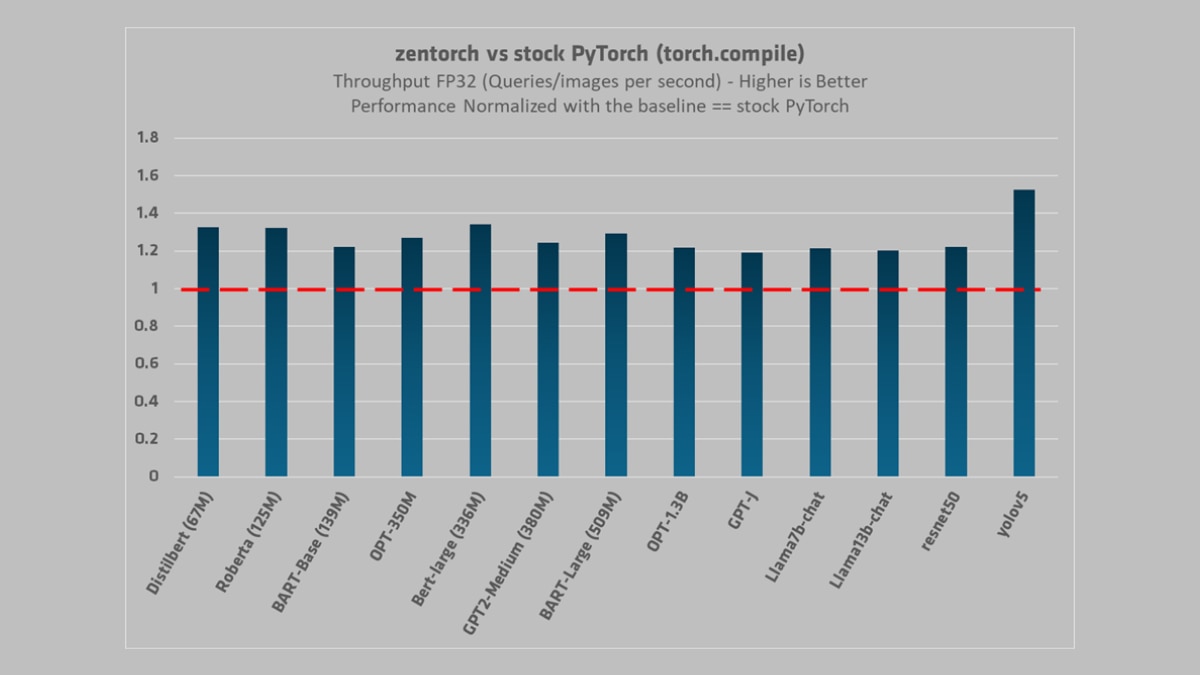
Below are some results, with FP32:
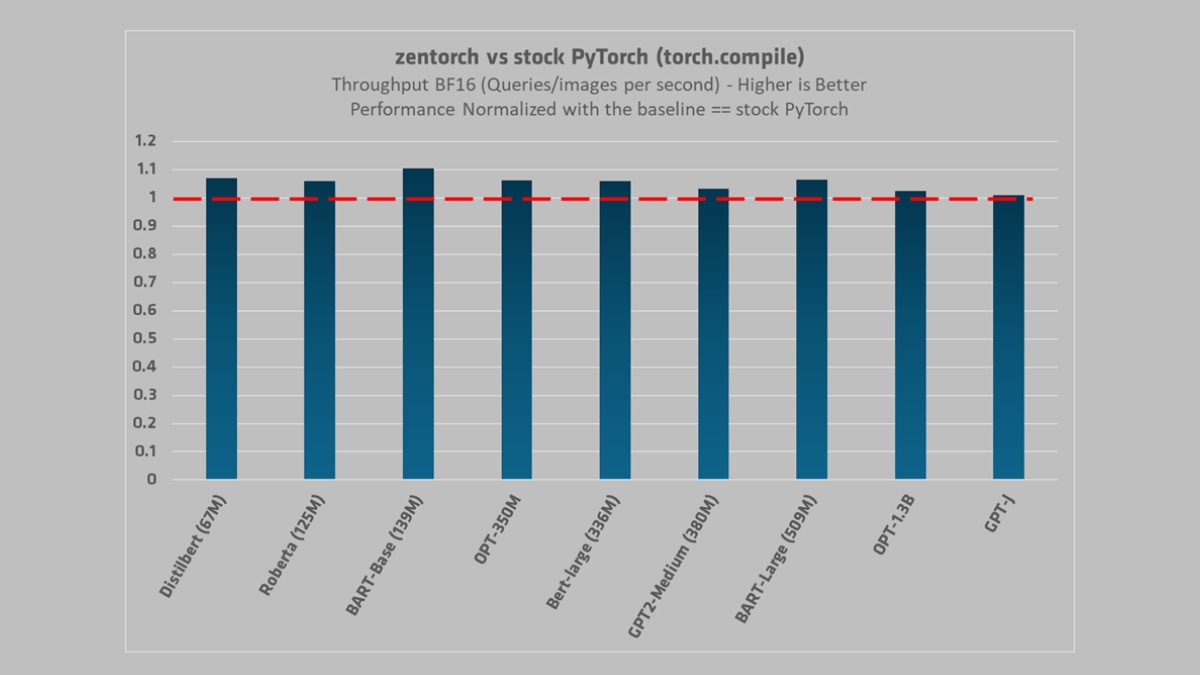
With BFloat16:
Future Work
Quantization is an active area of research and a popular compression technique to accelerate neural network performance. zentorch provides support for BF16 models through casting and AMP. In future releases, we will add INT8 and INT4 support. If you need more information on AMD AI and plans for developers, please send an email to amd_ai_mkt@amd.com.
脚注
Testing configuration details:
ZD-052: Testing conducted internally by AMD as of 05/15/2023. 2P AMD EPYC 9654 (192 Total Cores, 1536GB Total Memory w/ 24x64GB DIMMs, 2x960GB SSD RAID 1, HT Off, Ubuntu® 22.04, GCC 11.4.0) powered server running AI benchmarks with ZenDNN Plugin for PyTorch 4.2.0 (zentorch) and IPEX 2.1.2 compared to Native PyTorch Compile 2.1.2 (torch.compile) throughput (Queries/images per second, average of 3 runs)
Test (Data Type, Batch Size, Sequence Length) | zentorch 4.2.0 | PyTorch 2.1.2 | IPEX 2.1.2 | zentorch v PyTorch | zentorch v IPEX
yolov5 (FP32, 960, NA) | 335.19 | 219.87 | 291.28 | 1.52 | 1.15
Bert-large (336M) (FP32, 96, 384) | 29.78 | 22.19 | 22.2 | 1.34 | 1.34
Distilbert (67M) (FP32, 96, 384) | 180 | 135.87 | 142.78 | 1.32 | 1.26
Roberta (125M) (FP32, 96, 384) | 104.41 | 79.04 | 79.21 | 1.32 | 1.32
BART-Large (509M) (FP32, 96, 384) | 21.27 | 16.48 | 20.26 | 1.29 | 1.05
OPT-350M (FP32, 96, 384) | 23.15 | 18.23 | 18.25 | 1.27 | 1.27
GPT2-Medium (380M) (FP32, 96, 384) | 25.31 | 20.33 | 18.78 | 1.24 | 1.35
BART-Base (139M) (FP32, 96, 384) | 68.38 | 55.92 | 65.1 | 1.22 | 1.05
resnet50 (FP32, 960, NA) | 978.19 | 801.19 | 801.69 | 1.22 | 1.22
OPT-1.3B (FP32, 96, 384) | 6.65 | 5.46 | 5.46 | 1.22 | 1.22
Llama7b-chat (FP32, 96, 384) | 1.13 | 0.93 | 0.94 | 1.22 | 1.2
Llama13b-chat (FP32, 96, 384) | 0.59 | 0.49 | 0.5 | 1.2 | 1.18
GPT-J (FP32, 96, 384) | 1.62 | 1.36 | 1.39 | 1.19 | 1.17
yolov5 (BF16, 960, NA) | 609.05 | 362.31 | 485.62 | 1.68 | 1.25
BART-Base (139M) (BF16, 96, 384) | 120.09 | 108.81 | 106.29 | 1.1 | 1.13
Distilbert (67M) (BF16, 96, 384) | 154.24 | 144.18 | 159.47 | 1.07 | 0.97
BART-Large (509M) (BF16, 96, 384) | 36.47 | 34.3 | 33.14 | 1.06 | 1.1
OPT-350M (BF16, 96, 384) | 42.04 | 39.61 | 35.57 | 1.06 | 1.18
Bert-large (336M) (BF16, 96, 384) | 47.17 | 44.51 | 48.37 | 1.06 | 0.98
Roberta (125M) (BF16, 96, 384) | 153.4 | 144.93 | 159.62 | 1.06 | 0.96
GPT2-Medium (380M) (BF16, 96, 384) | 40.65 | 39.37 | 41.05 | 1.03 | 0.99
OPT-1.3B (BF16, 96, 384) | 12.53 | 12.23 | 11.55 | 1.02 | 1.08
GPT-J (BF16, 96, 384) | 3.38 | 3.35 | 3.36 | 1.01 | 1.01
Results may vary based on factors such as software versions and BIOS settings.
脚注
Testing configuration details:
ZD-052: Testing conducted internally by AMD as of 05/15/2023. 2P AMD EPYC 9654 (192 Total Cores, 1536GB Total Memory w/ 24x64GB DIMMs, 2x960GB SSD RAID 1, HT Off, Ubuntu® 22.04, GCC 11.4.0) powered server running AI benchmarks with ZenDNN Plugin for PyTorch 4.2.0 (zentorch) and IPEX 2.1.2 compared to Native PyTorch Compile 2.1.2 (torch.compile) throughput (Queries/images per second, average of 3 runs)
Test (Data Type, Batch Size, Sequence Length) | zentorch 4.2.0 | PyTorch 2.1.2 | IPEX 2.1.2 | zentorch v PyTorch | zentorch v IPEX
yolov5 (FP32, 960, NA) | 335.19 | 219.87 | 291.28 | 1.52 | 1.15
Bert-large (336M) (FP32, 96, 384) | 29.78 | 22.19 | 22.2 | 1.34 | 1.34
Distilbert (67M) (FP32, 96, 384) | 180 | 135.87 | 142.78 | 1.32 | 1.26
Roberta (125M) (FP32, 96, 384) | 104.41 | 79.04 | 79.21 | 1.32 | 1.32
BART-Large (509M) (FP32, 96, 384) | 21.27 | 16.48 | 20.26 | 1.29 | 1.05
OPT-350M (FP32, 96, 384) | 23.15 | 18.23 | 18.25 | 1.27 | 1.27
GPT2-Medium (380M) (FP32, 96, 384) | 25.31 | 20.33 | 18.78 | 1.24 | 1.35
BART-Base (139M) (FP32, 96, 384) | 68.38 | 55.92 | 65.1 | 1.22 | 1.05
resnet50 (FP32, 960, NA) | 978.19 | 801.19 | 801.69 | 1.22 | 1.22
OPT-1.3B (FP32, 96, 384) | 6.65 | 5.46 | 5.46 | 1.22 | 1.22
Llama7b-chat (FP32, 96, 384) | 1.13 | 0.93 | 0.94 | 1.22 | 1.2
Llama13b-chat (FP32, 96, 384) | 0.59 | 0.49 | 0.5 | 1.2 | 1.18
GPT-J (FP32, 96, 384) | 1.62 | 1.36 | 1.39 | 1.19 | 1.17
yolov5 (BF16, 960, NA) | 609.05 | 362.31 | 485.62 | 1.68 | 1.25
BART-Base (139M) (BF16, 96, 384) | 120.09 | 108.81 | 106.29 | 1.1 | 1.13
Distilbert (67M) (BF16, 96, 384) | 154.24 | 144.18 | 159.47 | 1.07 | 0.97
BART-Large (509M) (BF16, 96, 384) | 36.47 | 34.3 | 33.14 | 1.06 | 1.1
OPT-350M (BF16, 96, 384) | 42.04 | 39.61 | 35.57 | 1.06 | 1.18
Bert-large (336M) (BF16, 96, 384) | 47.17 | 44.51 | 48.37 | 1.06 | 0.98
Roberta (125M) (BF16, 96, 384) | 153.4 | 144.93 | 159.62 | 1.06 | 0.96
GPT2-Medium (380M) (BF16, 96, 384) | 40.65 | 39.37 | 41.05 | 1.03 | 0.99
OPT-1.3B (BF16, 96, 384) | 12.53 | 12.23 | 11.55 | 1.02 | 1.08
GPT-J (BF16, 96, 384) | 3.38 | 3.35 | 3.36 | 1.01 | 1.01
Results may vary based on factors such as software versions and BIOS settings.
