

概要
AMD CDNA™ アーキテクチャは、AMD Instinct™ GPU および APU の基盤となる、専用演算アーキテクチャです。このアーキテクチャは、AMD チップレット テクノロジと高スループットの Infinity アーキテクチャ ファブリックである広帯域幅メモリ (HBM) を統合する高度なパッケージを備えており、AI および HPC データ形式の包括的なセットをサポートする高度なマトリックス コア テクノロジを提供します。このテクノロジはデータ移動のオーバーヘッドを削減し、電力効率を向上させるように設計されたものです。
世代間比較表:
| CDNA | CDNA 2 | CDNA 3 | CDNA 4 | |
| プロセス テクノロジ | 7 nm FinFET | 6 nm FinFET | 5 nm + 6 nm FinFET | 3 nm + 6 nm FinFET |
| トランジスタ | 256 億 | 最大 580 億 | 最大 1,460 億 | 最大 1,850 億 |
| CU | マトリックス コア | 120 | 440 | 最大 220 | 880 | 最大 304 | 1216 | 256 | 1024 |
| メモリ タイプ | 32GB HBM2 | 最大 128 GB HBM2E | 最大 256 GB HBM3 | HBM3E | 288GB HBM3E |
| メモリ帯域幅 (ピーク) | 1.2 TB/秒 | 最大 3.2 TB/秒 | 最大 6 TB/秒 | 8 TB/秒 |
| AMD Infinity Cache™ | N/A | N/A | 256 MB | 256 MB |
| GPU コヒーレンシ | N/A | キャッシュ | キャッシュおよび HBM | キャッシュおよび HBM |
| サポートするデータ型 | INT4、INT8、BF16、FP16、FP32、FP64 | INT4、INT8、BF16、FP16、FP32、FP64 | Matrix: INT8、FP8、BF16、FP16、TF32、FP32、FP64 Vector: FP16、FP32、FP64 Sparsity: INT8、FP8、BF16、FP16 |
Matrix: MXFP4、MXFP6、INT8、MXFP8、OCP FP8、BF16、FP16、TF32*、FP32、FP64 Vector: FP16、FP32、FP64 Sparsity: OCP-FP8、INT8、FP16、BF16 |
| 製品 | AMD Instinct™ MI100 シリーズ | AMD Instinct™ MI200 シリーズ | AMD Instinct™ MI300 シリーズ | AMD Instinct™ MI350 シリーズ |
* TF32 はソフトウェア エミュレーションを通じてサポートされます。

利点
マトリックス コア テクノロジ
AMD CDNA 4 には、前世代のアーキテクチャと比較して低精度行列データ型に対する計算性能を 2 倍に向上させたマトリックス コア テクノロジが搭載されています。AMD CDNA 4 では、命令レベルの並列化が向上し、共有 LDS リソースが拡大されて帯域幅が 2 倍になりました。さらに、MXFP4 および MXFP6 に加え、OCP-FP8、INT8、FP16、BF16 向けのスパース マトリックス データ (スパース性) も含む、幅広い精度をサポートします。
AI アクセラレーションの強化
AMD CDNA 4 は、レイテンシの短縮による GEMM パフォーマンスの向上、より低精度の製品による電力効率の向上、モデルの精度、速度、電力効率の優先順位のバランスに基づく混合精度 AI プロジェクトの柔軟性の向上など、LLM 向けの新しい強化された AI アクセラレーション機能を提供します。


HBM メモリ、キャッシュ、コヒーレンシ
AMD Instinct MI350 シリーズ GPU は、必要なすべての帯域幅でより大規模のモデルをサポートできるように、業界をリードする 256 GB の HBM3E メモリ容量を備えているほか、共有メモリと AMD Infinity Cache™ (共有ラスト レベル キャッシュ) も備えているため、データ コピーがなくなり、レイテンシが改善されています。

ユニファイド ファブリック
次世代 AMD Infinity アーキテクチャは、AMD Infinity Fabric™ テクノロジと組み合わせることで、AMD GPU チップレット テクノロジとスタックド HBM3E メモリのコヒーレントで高スループットの統合を、単一デバイスおよびマルチデバイス プラットフォームで実現します。また、PCIe® 5 との互換性により、I/O も強化されています。
AMD CDNA™ 4 のご紹介
AMD CDNA™ 4 は、AMD Instinct™ MI350 シリーズ GPU の基盤となる、専用演算アーキテクチャです。データ移動のオーバーヘッドを削減し、電力効率を高めるように設計されたチップレット テクノロジによる、高度なパッケージングを特徴としています。

AMD Instinct MI350 シリーズ GPU
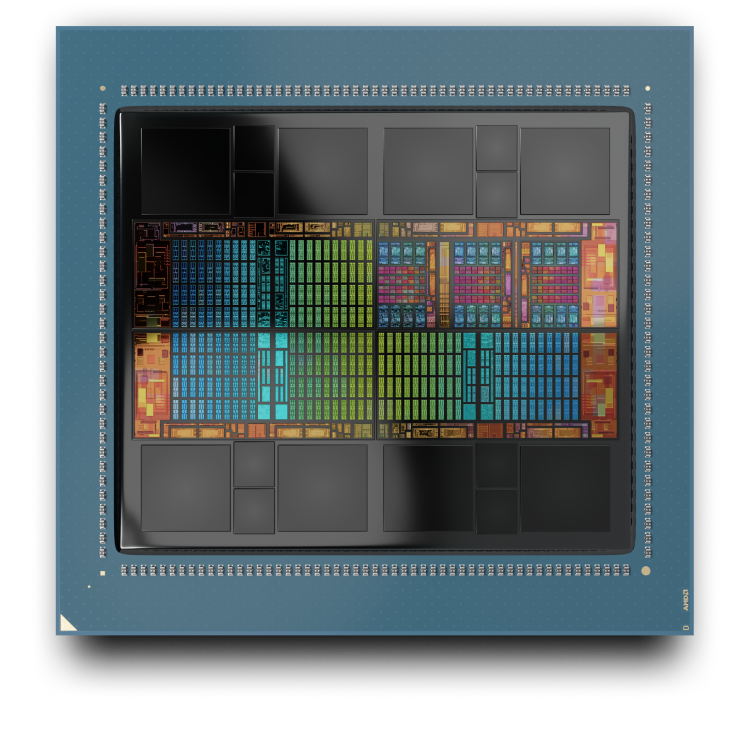


AMD CDNA 3
AMD CDNA 3 アーキテクチャは、AMD Instinct™ MI300 シリーズ GPU の基盤となる、専用演算アーキテクチャです。データ移動のオーバーヘッドを削減し、電力効率を高めるように設計されたチップレット テクノロジによる、高度なパッケージングを特徴としています。
AMD Instinct MI300A APU
AMD Instinct MI325X GPU



AMD CDNA 2
AMD CDNA 2 アーキテクチャは、最も負荷のかかる科学演算ワークロードや機械学習アプリケーションでも、高速化できるように設計されています。AMD Instinct MI200 シリーズ GPU の基盤となっています。
AMD CDNA
AMD CDNA アーキテクチャは、GPU ベースの演算専用アーキテクチャで、エクサスケール級の演算の時代を切り開くために設計されました。AMD Instinct MI100 シリーズ GPU の基盤となっています。


AMD Instinct アクセラレータ
AMD Instinct GPU が生成 AI、トレーニング、HPC の新しい標準をどのように確立しているかについて説明します。

AMD ROCm™ ソフトウェア
AMD CDNA アーキテクチャは、オープン ソフトウェア スタックである AMD ROCm™ ソフトウェアによってサポートされています。この AMD ROCm には、AMD Instinct GPU をターゲットとする、AI および HPC ソリューション開発のためのプログラミング モデル、ツール、コンパイラ、ライブラリ、ランタイムの幅広いセットが含まれています。