REAPPEAR – Real-time, Edge-optimized, AI-powered, Parallel Pixel-upscaling Engine on AMD Ryzen AI
Aug 21, 2025

Introduction
With the advent of AMD Ryzen™ AI, a new class of edge-capable devices has emerged—featuring the powerful trifecta of CPU, iGPU, and NPU on a single SoC. Initially released as laptop chips, these heterogeneous systems are now making their way into portable handhelds, such as the ROG XBOX ALLY X, powered by the AMD Ryzen AI Z2 Extreme. This evolution opens tremendous new opportunities for real-time, on-device AI workloads.
One particularly exciting application is video upscaling—a classic computer vision task that improves visual quality by increasing resolution. Despite its usefulness, high-quality upscaling has traditionally demanded expensive GPU hardware, making it impractical for users who would benefit from it most. Ironically, those with high-end GPUs typically also enjoy fast internet, great displays, and high-quality webcams—making upscaling redundant for them.
Our work targets the other end of the spectrum: users with limited bandwidth, low-resolution webcams, or budget-friendly Ryzen AI devices. By leveraging the full breadth of the Ryzen AI heterogeneous compute resources, we enable real-time video upscaling that balances performance and power efficiency—tailored to use cases like streaming, video calls, and offline media playback. We demonstrate how these affordable edge devices can intelligently shift workloads between the iGPU and NPU, adapting to user context—whether maximizing real-time fidelity or saving power in background tasks. Our system focuses on upscaling video content to 1080p, aligning with the native resolution of most of these handheld and thin-and-light devices.
In this blog post, we describe the engineering decisions, architecture, and optimizations behind our solution—and present real-world performance benchmarks that validate our approach on Ryzen AI platforms.
Motivation
According to this blog post by NVIDIA, “Nearly 80% of internet bandwidth today is streaming video. And 90% of that content streams at 1080p or lower, including from popular sources like Twitch.tv, YouTube, Netflix, Disney+ and Hulu.”
NVIDIA’s solution—RTX Video Super Resolution—targets users upscaling 1080p to 4K, which makes perfect sense for that class of premium hardware owners. However, no such equivalent exists for users on thin-and-light PCs or portable handhelds, where hardware limitations make real-time upscaling infeasible using traditional approaches. This is a missed opportunity, because it's precisely these users—on limited bandwidth connections or with low-quality cameras—who stand to benefit the most from efficient video upscaling.
Streaming 1080p video can be highly demanding on bandwidth, with a 10-minute H.264 (AVC) clip at 30 FPS typically requiring around 375 MB at 5 Mbps. By reducing the resolution to one-quarter in each dimension (e.g., 480×270), the bitrate drops proportionally, resulting in a ~16× smaller file size—about 23 MB for the same duration. This dramatic reduction enables smooth streaming in bandwidth-constrained environments such as handhelds or edge devices.
Resolution |
Bitrate |
Size of 10 min (MB) |
Relative Size |
Target User |
1920×1080 (Full HD) |
5 Mbps |
375 MB |
100% |
High-speed internet, high-end hardware |
480×270 (¼ res) |
0.3125 Mbps |
23.4 MB |
~6.25% |
Low-speed internet, budget hardware |

In this work, we focus on unlocking the latent potential of low-power heterogeneous systems by carefully engineering for the capabilities of modern edge hardware. We specifically explore the possibilities enabled by devices like the ROG XBOX ALLY X, powered by the AMD Ryzen AI Z2 Extreme. While we perform our evaluations on a Strix Point-based AMD Ryzen AI Mini PC—a development platform with similar architecture—we design our solution to generalize to this emerging class of AI-capable edge systems.
By leveraging a carefully optimized software stack that exploits the CPU, iGPU, and NPU in parallel, we demonstrate how these constrained systems can achieve real-time, power-efficient video upscaling. Beyond the technical contributions, we also explore new use cases uniquely enabled by this platform class, from real-time webcam enhancement to offline movie upscaling in bandwidth-starved environments.
Background
Ryzen AI enables efficient deployment of AI models across heterogeneous compute units—specifically, the CPU, iGPU, and the integrated NPU. To support real-time, edge-friendly AI inference, AMD leverages the ONNX Runtime execution environment, which provides flexible and optimized support for multiple execution providers (EPs).

At the top of the stack, models can be trained using standard frameworks such as TensorFlow, PyTorch, or exported directly in the ONNX format. These models are then passed through a quantization and optimization pipeline, typically using tools like the Microsoft Olive Quantizer or the AMD Vitis™ AI Quantizer, depending on the target device.
Following quantization, models undergo conversion and optimization to make them suitable for efficient edge deployment. The ONNX Runtime then handles execution using one of several available Execution Providers (EPs):
- CPU EP – for general-purpose inference
- DirectML EP – targeting the iGPU for high-throughput compute
- AMD Vitis™ AI EP – for executing on the NPU, offering the highest energy efficiency
This flexible setup allows developers to target the most suitable hardware unit based on workload characteristics—balancing between performance, power efficiency, and thermal constraints.
Contributions
Our solution builds upon the excellent open-source work in Real-ESRGAN, a popular AI-based video and image upscaling framework. While Real-ESRGAN delivers impressive visual quality, it is not optimized for real-time execution, especially on resource-constrained or edge devices.
To address this gap, we undertook a series of targeted engineering efforts, each aimed at improving performance, portability, power efficiency, or user accessibility.
1. Porting to C++
The original Real-ESRGAN codebase is written in Python. While Python’s ONNX Runtime APIs can offer good inference performance in isolation, we found that real-time video upscaling—especially with tiling, as described later—demands significantly more control over memory and threading. In particular, the Global Interpreter Lock (GIL) in Python became a major bottleneck when processing tiles in parallel, due to the heavy memory movement involved in coordinating tasks across heterogeneous compute units.
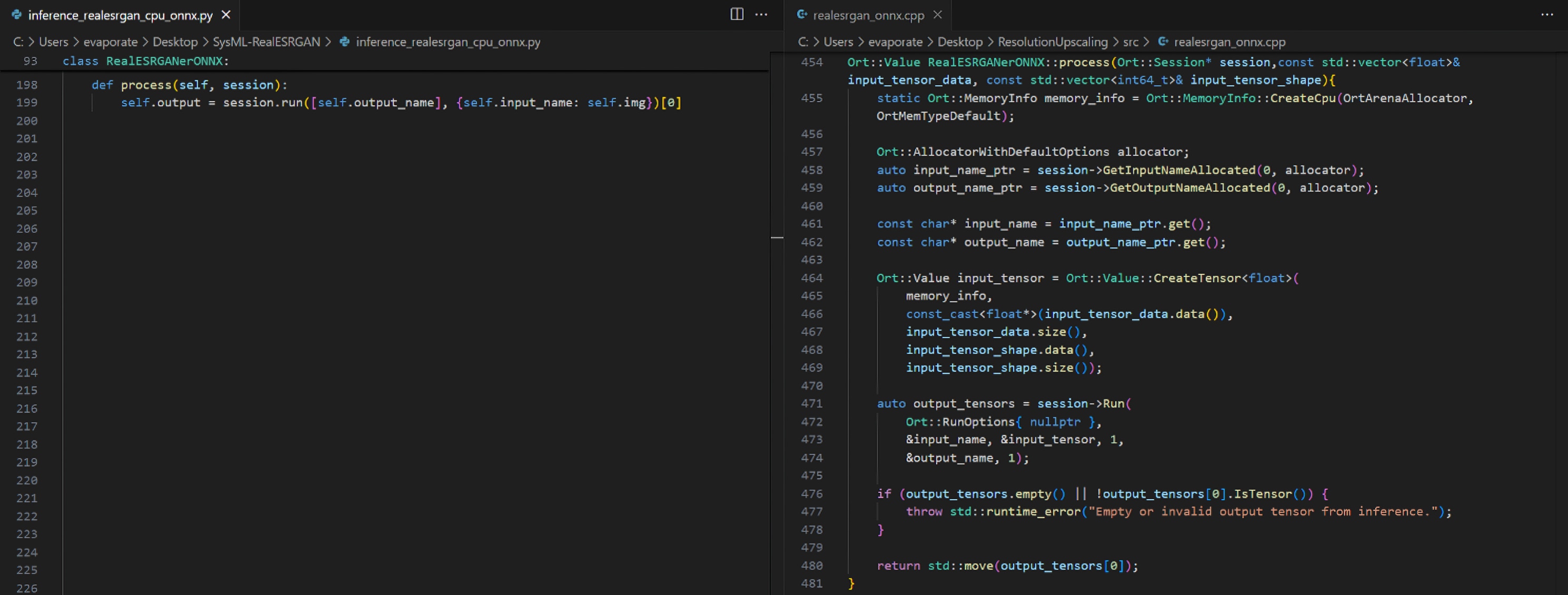
This limitation was especially painful in our context, where CPU, iGPU, and NPU may all be active at once. The cost of moving memory in and out of Python-managed objects far outweighed any convenience offered by its APIs. To solve this, we completely rewrote the entire inference pipeline in C++.
The C++ implementation allows us to take full advantage of native compiler optimizations such as -O2, AVX2 vectorization, and OpenMP-based multithreading—critical for achieving real-time throughput under tight power and thermal constraints. This rewrite also unlocks finer control over memory allocation, tensor creation, and low-latency execution on AMD ONNX Runtime EPs.
2. Simplifying the End-User Experience
Running any model on the NPU using the Vitis AI Execution Provider (EP) typically involves a complex and error-prone multi-step pipeline: the model must be converted from PyTorch to ONNX Runtime format, reshaped from NCHW (the default format in PyTorch) to NHWC (required by the NPU), calibration samples must be collected, and then the model is quantized using Quark. Adding to this complexity, the AMD NPU only supports fixed-shape ONNX models, which means models must be exported specifically for the video resolution being processed. This makes it impossible to precompute and ship generic, resolution-agnostic models.
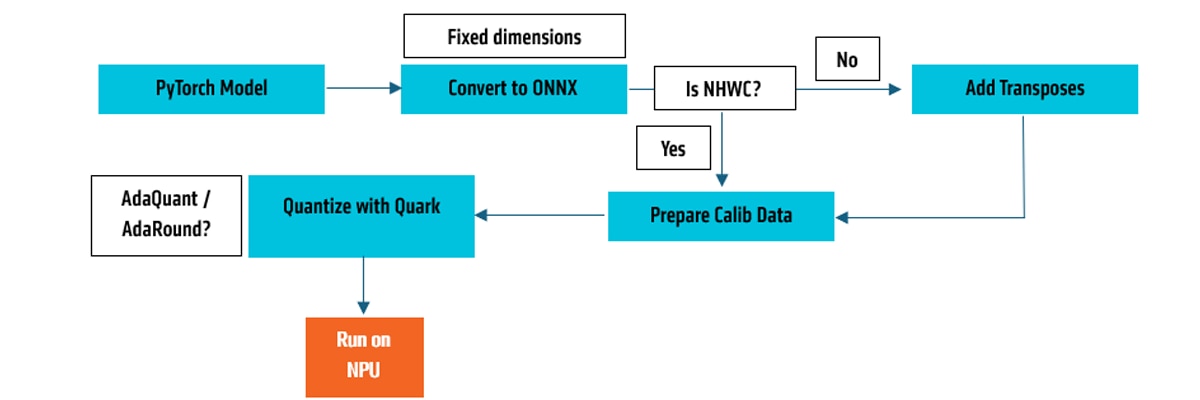
To make our system usable by non-expert users, we fully automated this entire pipeline. All necessary conversions, calibrations, and quantizations are performed just-in-time—triggered when the input source is known and its specifications (e.g., resolution) are available. This eliminates the need for manual setup and enables real-time, dynamic adaptation to varied input sources.
This automation also makes it feasible to support multiple tiling configurations on the fly. Rather than shipping dozens of statically compiled quantized models, we only ship the base .pth PyTorch model. Everything else—ONNX export, calibration, quantization, tiling—happens dynamically at the user’s end.
For example, if the input is a web URL, the system uses FFmpeg to inspect and decode the video stream, extracting the resolution. Based on these dimensions, the PyTorch model is exported to ONNX with the appropriate static shapes. Simultaneously, 7–10 representative frames are extracted from the video and stored locally to serve as calibration data. If tiling is enabled, these frames are further cropped into tile-sized segments. The Quark quantizer is then invoked to quantize the model, optionally using Fast Finetuning techniques such as Adaround or AdaQuant to improve accuracy.
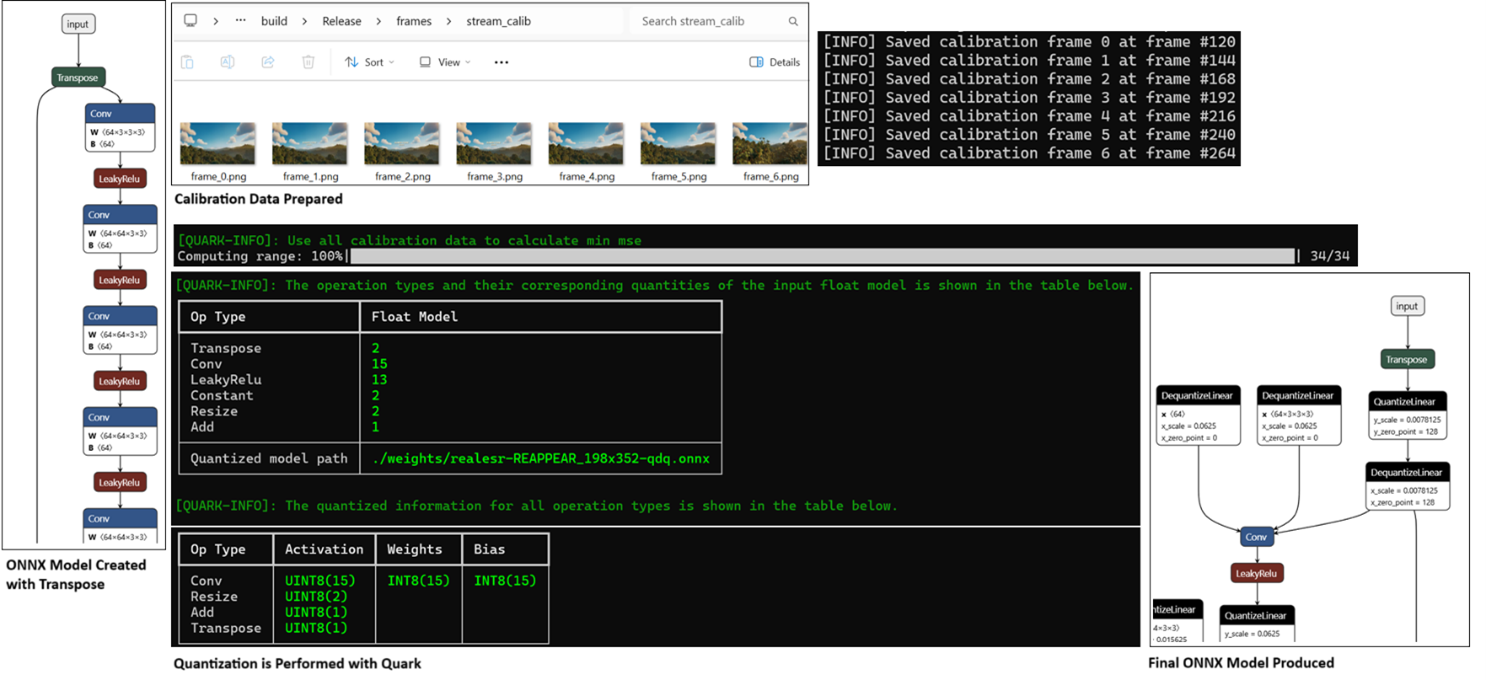
Once these steps complete, inference begins automatically. The result is a seamless user experience that hides the complexities of hardware-aware AI deployment behind a clean interface—without sacrificing flexibility or performance.
3. Model Retraining to Support More Tasks and Hardware Constraints
We begin with the realesr-animev3 model from Real-ESRGAN—a lightweight, VGG-style upscaling model designed for anime. While the architecture is well-suited for low-resource environments, it is not directly compatible with current AMD NPU capabilities. To make it viable for deployment and broader use, we made several targeted modifications and retrained the model from scratch.
First, the AMD NPU does not support certain operations such as PReLU and PixelShuffle. We replaced these with LeakyReLU and an Upsample + Convolution alternative that retains functional equivalence while maintaining compatibility. Additionally, we reduced the number of convolutional layers in the model's body from 16 to 12. This yields a significant performance boost with minimal impact on visual quality—a trade-off that aligns well with real-time inference goals. We use the original realesr-animev3 weights for transfer learning, enabling faster convergence during retraining.
Beyond hardware compatibility, we also sought to broaden the model's domain generalization. The original model was trained exclusively on anime-style imagery, but our use cases span general video content. To this end, we curated a new training corpus that combines several established datasets—including DIV2K, Flickr2K, and OST (the full collection can be obtained from here)—with a custom-built "Blender" dataset, containing frames from five open-source 3D animated films we curated. This hybrid dataset enables the model to generalize well across stylized, natural, and synthetic content, making it suitable for a wide range of real-world video enhancement tasks.

We then perform model retraining using Real-ESRGAN’s training infrastructure, adapted to our modified architecture and dataset. The framework allows for flexible dataset integration and checkpointing, which we extended to support our custom Blender dataset and tiling-compatible export formats.
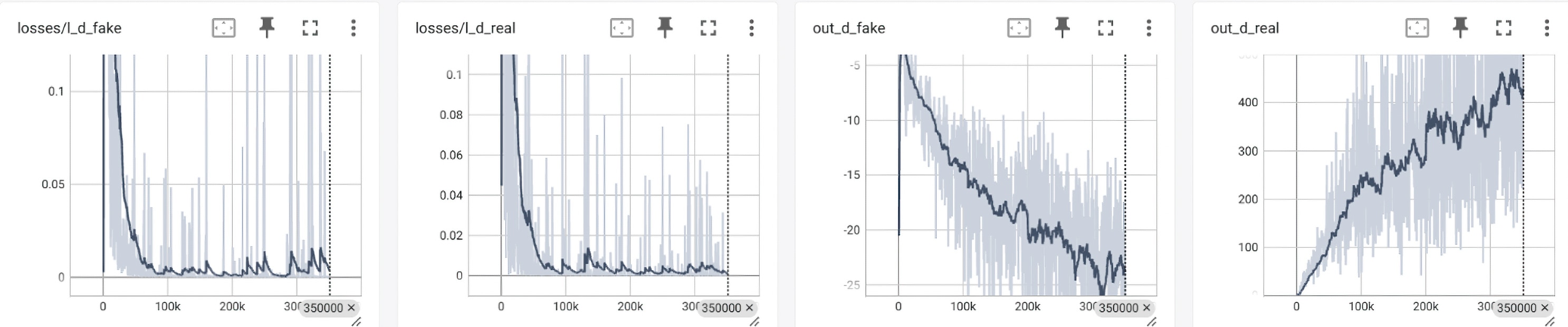
The graphs below illustrate training progress, including loss convergence and validation quality over time.
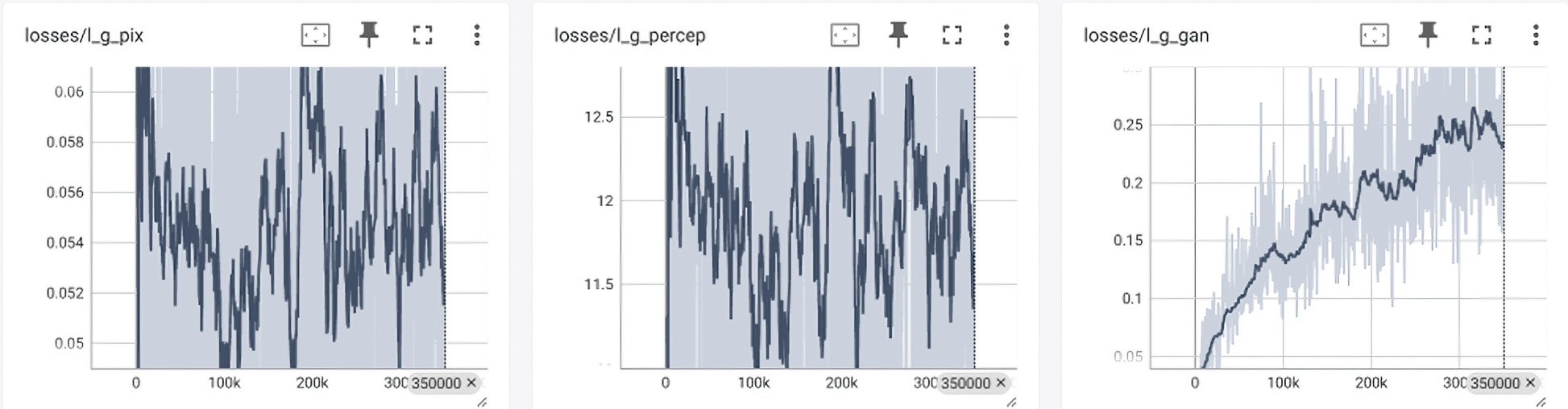
Unlike traditional supervised learning, where a model directly minimizes a loss function against ground truth labels (e.g., MSE or cross-entropy), Generative Adversarial Networks (GANs) involve a two-player game between a generator and a discriminator. The generator learns to produce realistic outputs (e.g., high-resolution images), while the discriminator learns to distinguish between real and generated examples. The generator improves by trying to fool the discriminator, while the discriminator improves by trying to catch the generator's mistakes. This adversarial setup leads to a dynamic and often unstable training process, as the optimization targets are constantly shifting. Instead of a single loss function, GAN training typically involves a combination of pixel-wise loss, perceptual loss, and adversarial loss—each guiding different aspects of output quality. While more complex to train, this method enables GANs to produce sharper, more perceptually convincing results than conventional models that optimize only for numerical accuracy.
4. Deployment on AMD NPU with Tiling
One might assume that it's sufficient to send an entire input image directly to the NPU for processing. However, doing so significantly underutilizes the hardware’s full capacity. The AMD NPU is composed of 8 columns, each containing 4 cores, and it can only be accessed in specific compute granularities: either as two 4×4 blocks or eight 1×4 blocks. To fully exploit the compute potential, we go a step further and run multiple instances of the model in parallel. This also enables internal pipelining of I/O and computation, improving throughput.
But there's a challenge: how can we run several model instances concurrently when we only receive one image at a time? This is where tiling comes into play.

We divide each input image into N×N tiles, where N is the chosen tiling level (from 1 to 5). Each tile is then processed by a separate model instance. Naturally, this also means that we must export a dedicated ONNX model for the specific tile shape, as required by the NPU’s fixed input size constraints.
Tiling introduces two key challenges, that we solve with padding:
- External Padding: When slicing an image into a grid, edge tiles will be smaller unless the dimensions are divisible by N. To resolve this, we apply external padding to the entire image so that each tile is uniform in size.
- Internal Padding: Around 10 pixels of extra padding are added around the borders of each tile. This helps avoid edge artifacts caused by convolution layers near the tile boundaries, and ensures that the outputs can be seamlessly reassembled.
Through this method, we achieve high levels of parallelism on the NPU and maximize its utilization, all while preserving visual quality.
5. Parallel Heterogeneous Execution with iGPU
In real-world tasks such as upscaling from low resolutions like 480x270p to 1920x1080p (4x), we observe that the NPU is not fast enough to meet real-time performance requirements. On the other hand, the integrated GPU (iGPU) is well-suited for such workloads and can handle them smoothly—but at the cost of significantly higher power consumption.
So, what if we could use both?
This is where heterogeneous execution comes into play. By distributing the workload across both the NPU and iGPU, we can achieve an optimal balance between performance and efficiency.
For example, consider a tiling level of 4, which breaks an image into 16 tiles. Rather than processing all 16 tiles on a single accelerator, we can send 6 tiles to the NPU and the remaining 10 tiles to the iGPU. This strategy dramatically boosts performance compared to using the NPU alone, while still reducing the computational load—and consequently the power draw—on the iGPU.

An example of where this may be used is detailed in the next section.
Applications and Use Cases
We demonstrate the versatility of our solution across multiple real-world and experimental scenarios. By enabling dynamic execution on the NPU, iGPU, or both, our approach unlocks flexible deployment strategies across different constraints such as latency, power, or network bandwidth.
Use Case 1a: Real-Time Video Game Streaming
In scenarios like cloud gaming or handheld game streaming, incoming frames may arrive at a lower resolution to reduce network load or meet processing constraints. These frames can be upscaled on-device in real-time, enabling smoother visuals with increased perceived frame rates.
This video demonstrates GPU-based upscaling for cloud-based gaming. We first show the original full-resolution server-side stream, followed by the low-resolution client-side stream alongside the real-time upscaled output. Notice the spike in GPU usage as the upscaling kicks in.
Use Case 1b: Real-Time Movie Streaming
Streaming providers often reduce resolution during network congestion to prevent buffering. With our system, such low-resolution video can be upscaled in real-time during playback, allowing the service to reduce bandwidth usage without compromising user experience.
This video demonstrates GPU-based upscaling for online movie streaming. It begins with the original full-resolution server-side stream, followed by the low-resolution client-side stream alongside the real-time upscaled output. A noticeable spike in GPU usage is observed as the upscaling process runs.
Execution target: iGPU
Use Case 2a: Offline Movie Upstreaming in Bandwidth-Limited Regions
In areas with limited or expensive internet connectivity, users can upscale and cache content in advance when bandwidth is available. Here, the NPU can be utilized to minimize power consumption, making this a viable solution for extended usage on battery-powered devices like the ROG XBOX ALLY X.
This video demonstrates NPU-based upscaling for local video enhancement. It begins with the original low-resolution video file, followed by the upscaling process over several frames, and concludes with the high-resolution output saved to disk. A clear improvement in visual quality is observable when comparing the two. The tile lines are overlaid solely for visualization purposes.
Use Case 2b: Video Archival
In many scenarios—such as surveillance footage from security cameras—recorded video is only relevant for a short window, typically a week or two. After this period, the footage may be moved to cold storage for long-term archival. To minimize storage costs, one practical strategy is to reduce the resolution by a factor of 4, which leads to a 16x reduction in file size (since storage scales quadratically with resolution).
If this video is ever required again—for instance, during law enforcement investigations—it can be restored offline using our upscaling engine. By running the restoration process on the NPU, the archival video can be selectively upscaled back to a usable resolution with acceptable levels of distortion, enabling effective analysis while maintaining minimal storage overhead.
This video shows original high-resolution security camera footage and how it can be archived efficiently by downscaling—reducing storage size by 16x. We first display the low-resolution archived version, followed by the upscaled output processed offline using the NPU.
Execution target: NPU
Use Case 3: Real-Time Webcam Footage Upscaling
In future applications such as video conferencing on handhelds, users may transmit low-resolution webcam video due to hardware or camera constraints. With high bandwidth but low input resolution, real-time upscaling on the iGPU enhances the received visual quality for recipients.
Execution target: iGPU
This video demonstrates how low-resolution webcam footage from entry-level cameras can be upscaled to high-resolution in real-time before transmission. This approach is particularly beneficial for low-cost handheld devices where camera quality is often limited.
Use Case 4: Experimental – Heterogeneous Inference for Live Buffering
We explore a novel execution strategy where iGPU and NPU are used cooperatively based on user context. During active playback, the iGPU handles upscaling for real-time performance. If the user minimizes the video, the system dynamically shifts more tile processing to the NPU to reduce power usage. Over time, as frames are buffered in advance, the iGPU can be idled and all upscaling is handled by the NPU. This hybrid mode enables both responsiveness and energy efficiency.
Execution target: Dynamic mix of iGPU + NPU
Tiling |
Split (NPU:GPU) |
Latency per Frame |
Approx. Frame Rate |
|
GPU Only |
No Tiling |
- |
33.57 ms |
29.79 fps |
GPU Only |
4×4 Tiling |
0:16 |
91.80 ms |
10.89 fps |
GPU + NPU |
4×4 Tiling |
1:15 |
102.22 ms |
9.78 fps |
GPU + NPU |
4×4 Tiling |
2:14 |
99.64 ms |
10.04 fps |
GPU + NPU |
4×4 Tiling |
3:13 |
94.61 ms |
10.57 fps |
GPU + NPU |
4×4 Tiling |
4:12 |
91.25 ms |
10.96 fps |
GPU + NPU |
4×4 Tiling |
5:11 |
87.51 ms |
11.43 fps |
GPU + NPU |
4×4 Tiling |
6:10 |
85.57 ms |
11.69 fps |
GPU + NPU |
4×4 Tiling |
7:9 |
81.34 ms |
12.30 fps |
GPU + NPU |
4×4 Tiling |
8:8 |
82.00 ms |
12.20 fps |
GPU + NPU |
4×4 Tiling |
9:7 |
87.76 ms |
11.39 fps |
GPU + NPU |
4×4 Tiling |
10:6 |
94.52 ms |
10.58 fps |
GPU + NPU |
4×4 Tiling |
11:5 |
97.59 ms |
10.25 fps |
GPU + NPU |
4×4 Tiling |
12:4 |
101.76 ms |
9.82 fps |
GPU + NPU |
4×4 Tiling |
13:3 |
102.65 ms |
9.75 fps |
GPU + NPU |
4×4 Tiling |
14:2 |
109.52 ms |
9.13 fps |
GPU + NPU |
4×4 Tiling |
15:1 |
119.16 ms |
8.39 fps |
NPU Only |
4×4 Tiling |
16:0 |
121.12 ms |
8.26 fps |
NPU Only |
No Tiling |
- |
167.87 ms |
5.96 fps |
- Latency per Frame refers to the time taken to upscale one frame. Lower latency implies higher responsiveness.
- Frame Rate (fps) is the inverse of latency: fps ≈ 1000 / latency. This gives an idea of how many frames per second the setup can handle, and directly relates to perceived smoothness.
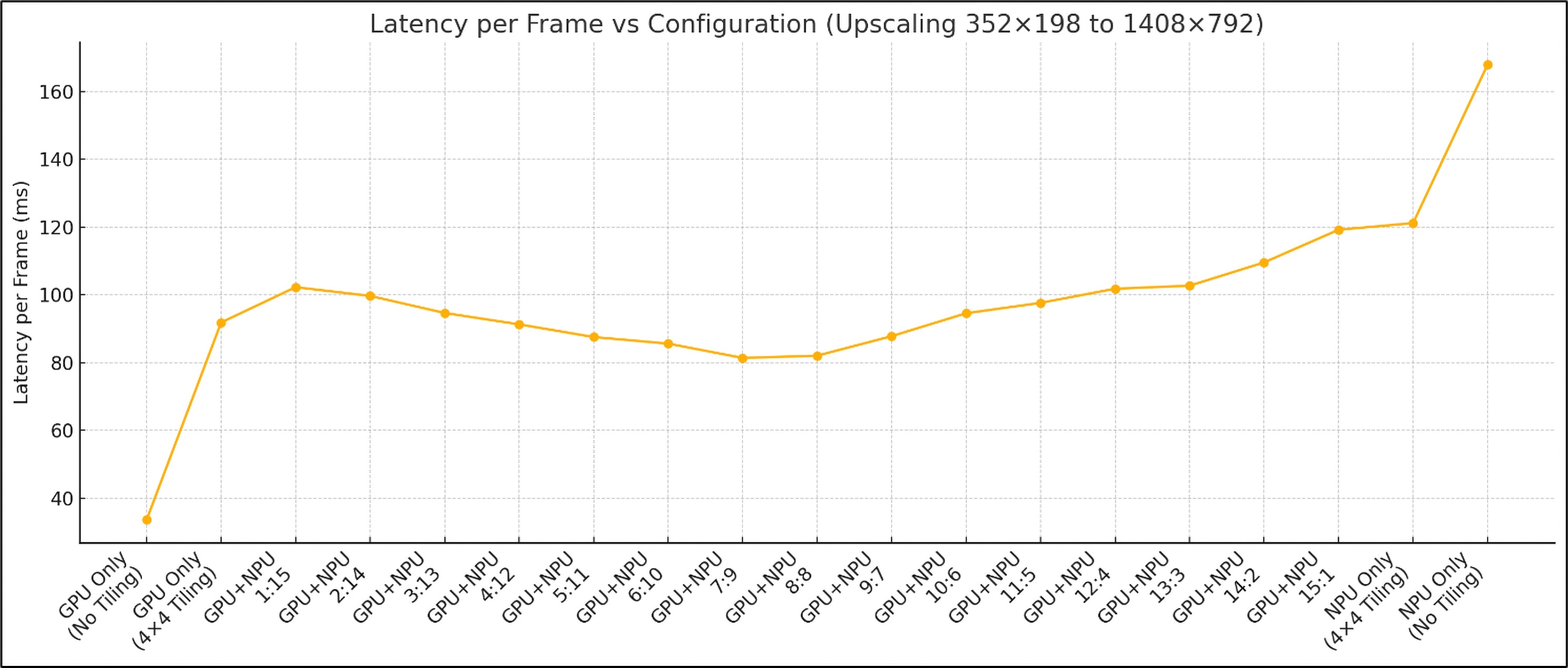
- The heterogeneous mode offers a balanced trade-off: slightly higher latency than GPU-only, but greatly reduces power usage by sharing the load with the NPU.
Interestingly, the GPU-only configuration with no tiling (tile = 1) delivers the best performance, with a latency of ~33 ms. This is because DirectML kernels seem better optimized for small-batch, large-input scenarios, as opposed to the large-batch, small-input patterns seen with 4×4 tiling. When tiling is enabled in GPU-only mode, latency increases significantly to ~91 ms.
However, in the hybrid GPU+NPU configuration, performance initially improves as tile splits are distributed—reaching a minimum latency of ~81 ms near the halfway point (8 GPU:8 NPU). Beyond this, NPU saturation causes the latency to rise again, showing a clear trade-off between GPU load balancing and NPU compute capacity.
This video demonstrates the progressive handover from the iGPU to the NPU using tiled execution. Observe the shifting device utilization reflected in the Task Manager, as well as the increase in CPU+NPU power draw, indicating how the workload gradually transitions from the iGPU to the NPU. Note that the iGPU power draw is not being measured here, but it reduces as the load shifts.
- Ideally, tiling should be used exclusively for the NPU, while the GPU should handle a non-tiled, full-resolution input, since that's where it performs best. However, supporting both modes simultaneously would significantly complicate the codebase and scheduling logic.
- Note that only the GPU-only configuration without tiling is designed for high-performance real-time scenarios, delivering smooth frame rates with low latency. The other configurations—while slower—are intended to maximize hardware utilization for offline processing or buffered streaming, where performance can be traded off for efficiency and reduced power consumption.
Conclusion
In this work, we introduced REAPPEAR, a lightweight and adaptable AI-based upscaling framework tailored for AMD NPUs and integrated GPUs. Starting from a RealESRGAN baseline, we redesigned the model architecture to accommodate hardware constraints—replacing unsupported operations, minimizing computational load, and retraining the model on diverse datasets for general-purpose visual enhancement. We developed a fully automated pipeline for model export, calibration, and quantization, making deployment seamless for end users.
To further exploit the hardware, we implemented tiling-based inference to maximize NPU utilization, and extended our runtime to support heterogeneous execution across the NPU and iGPU—dynamically balancing performance and power. Through several real-world and experimental use cases, we demonstrated REAPPEAR’s versatility, spanning low-power offline upscaling, real-time webcam enhancement, and adaptive video buffering.
Future Work
An exciting future direction is to apply REAPPEAR in real-time gaming scenarios, where on AI PCs with both discrete GPU (dGPU) and iGPU, games running on the dGPU could render at lower resolutions (e.g., 540p or 720p), and offload real-time upscaling to the iGPU and/or NPU using REAPPEAR. This hybrid rendering pipeline could significantly improve frame rates and reduce power consumption, making high-end gaming more accessible on low-end or battery-constrained laptops.
Acknowledgments & Attribution
This project would not have been possible without the contributions of several open-source projects, libraries, and creative datasets. Below is a list of resources we gratefully acknowledge:
Project / Asset |
Link |
License / Notes |
RealESRGAN |
BSD 3-Clause |
|
CLI11 (Command-line parser) |
BSD 3-Clause |
|
Glass Half |
CC BY 4.0 |
|
Wing It |
CC BY 4.0 |
|
Coffee Run |
CC BY 4.0 |
|
Spring |
CC BY 4.0 |
|
Sintel |
CC BY 3.0 |

Contributors

Related Blogs
-
Day 0 Support for MiniMax-H3 on AMD GPUs
Learn how MiniMax-H3 delivers unified multimodal AI video generation with day-0 support on AMD Instinct™ GPUs.
August 02, 2026
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026
-
Enabling Language-specific Reasoning in Multilingual Models with Reinforcement Learning — ROCm Blogs
Learn how to train multilingual reasoning models with reinforcement learning and extend context windows on AMD Instinct GPUs.
July 23, 2026







