Unlocking Peak AI Performance with MLPerf Client v1.0 on AMD Ryzen AI Processors
Aug 15, 2025

Key Takeaways
- AMD Ryzen™ Al Max+ 395 iGPU sets the bar – Achieves up to 61 tokens per second (TPS) , delivering top-tier client-side LLM performance and plenty of headroom for future, larger models.
- AMD Ryzen AI 9 HX 375 punches above its weight, achieving over 27 TPS on Phi-3.5.
- Hybrid (NPU + iGPU) excels across workloads – Consistently low Time to First Token (TTFT) and high TPS across Llama2 7B, Llama3.1 8B, and Phi-3.5, demonstrating a balanced latency and throughput approach.
- Real-world responsiveness – All tested configurations deliver TTFT near or under 1 second for most tasks, enabling fluid, interactive AI experiences on-device.
Introduction
AMD Ryzen AI Max Series processors deliver exceptional client-side large language model (LLM) performance, reaching up to 61 TPS on Phi-3.5 with sub-second TTFT for most workloads. These KPIs—TTFT and TPS—are critical for fast, responsive, and seamless AI experiences in real-world applications.
To put this performance to the test, we used MLPerf Client v1.0 from MLCommons®, a benchmark suite designed to measure client-side AI inference in realistic scenarios. It evaluates workloads such as summarization, creative writing, code analysis, and content generation, providing clear, comparable metrics for responsiveness and sustained throughput.
In this blog, we evaluated MLPerf Client on two powerful AMD systems: the Ryzen AI 9 HX 375, and the flagship Ryzen AI Max+ 395. You’ll learn:
- How to run MLPerf Client on Ryzen AI 9 Series processors
- How to configure for optimal performance
- What kind of results you can expect from leading models including Llama2 7B, Llama3.1 8B, and Phi3.5
Execution Paths and Systems Tested
AMD provides two execution paths for ML Perf Client LLM benchmarks: an iGPU-only path and a Hybrid path that leverages both the NPU and iGPU. The AMD NPU, delivering over 50 TOPS, is optimized for compute-intensive tasks, making it particularly effective for prompt processing during the prefill phase. Meanwhile, the iGPU offers the highest available bandwidth, making it well-suited for bandwidth-sensitive operations such as the decode phase. The Hybrid approach uniquely enables the distribution of model execution across heterogeneous system resources, maximizing both power efficiency and performance.
Below are the systems and devices used in testing of the ML Perf Client v1.0 benchmark in this blog.
Processor |
Device |
AMD Ryzen AI 9 HX 375 |
|
AMD Ryzen AI Max+ 395 |
|
Benchmarking Setup
Prerequisites
Supported hardware: AMD Ryzen AI 9 series processors with 32GB or more system memory. (see note below on Optimal Shared Memory Allocation)
Other requirements
- MLPerf Client v1.0 - The latest release of MLPerf Client can be downloaded from the GitHub release page. The latest version of MLPerf Client benchmark at the time this blog was published is here.
- AMD GPU driver version 32.0.21013.1000 or newer
- AMD NPU driver version 32.0.203.280 or newer
- Windows 11 x86-64 (latest updates recommended)
- See https://mlcommons.org/benchmarks/client/ for full list of requirements
Optimal Shared Memory Allocation on 32GB Systems
NOTE: This step is only necessary on some 32 GB systems.
You can improve performance by increasing the GPU’s memory commit limit. See instructions in the Known Issues in v1.0 release notes https://mlcommons.org/benchmarks/client/.
Optimizing Performance
To run LLMs in best performance mode, follow these steps:
- Ensure you are connected to AC wall power
- Go to Windows -> Settings -> System -> Power and set the power mode to Best Performance
- Open a terminal and run:
cd C:\Windows\System32\AMD
xrt-smi configure --pmode performance
Running the Benchmarks
The MLPerf Client benchmark is distributed as a Zip file. After extracting the .zip archive file to your local hard drive, open a terminal inside the extracted path (both Powershell and Command Prompt work).
To run MLPerf Client from the command line, use these commands for Hybrid (NPU + iGPU) or iGPU-only for the corresponding models.
# llama2 hybrid
mlperf-windows.exe -c llama2\AMD_OrtGenAI-RyzenAI_NPU_GPU.json
# llama3.1 hybrid
mlperf-windows.exe -c llama3.1\AMD_OrtGenAI-RyzenAI_NPU_GPU.json
# phi3.5 hybrid
mlperf-windows.exe -c phi3.5\AMD_OrtGenAI-RyzenAI_NPU_GPU.json
# llama2 iGPU for AMD Ryzen AI Max+ 395
mlperf-windows.exe -c llama2\AMD_ORTGenAI-DML_GPU.json
# llama3.1 iGPU for AMD Ryzen AI Max+ 395
mlperf-windows.exe -c llama3.1\AMD_ORTGenAI-DML_GPU.json
# phi3.5 iGPU for AMD Ryzen AI Max+ 395
mlperf-windows.exe -c phi3.5\AMD_ORTGenAI-DML_GPU.json
Each model run outputs a summary like this:
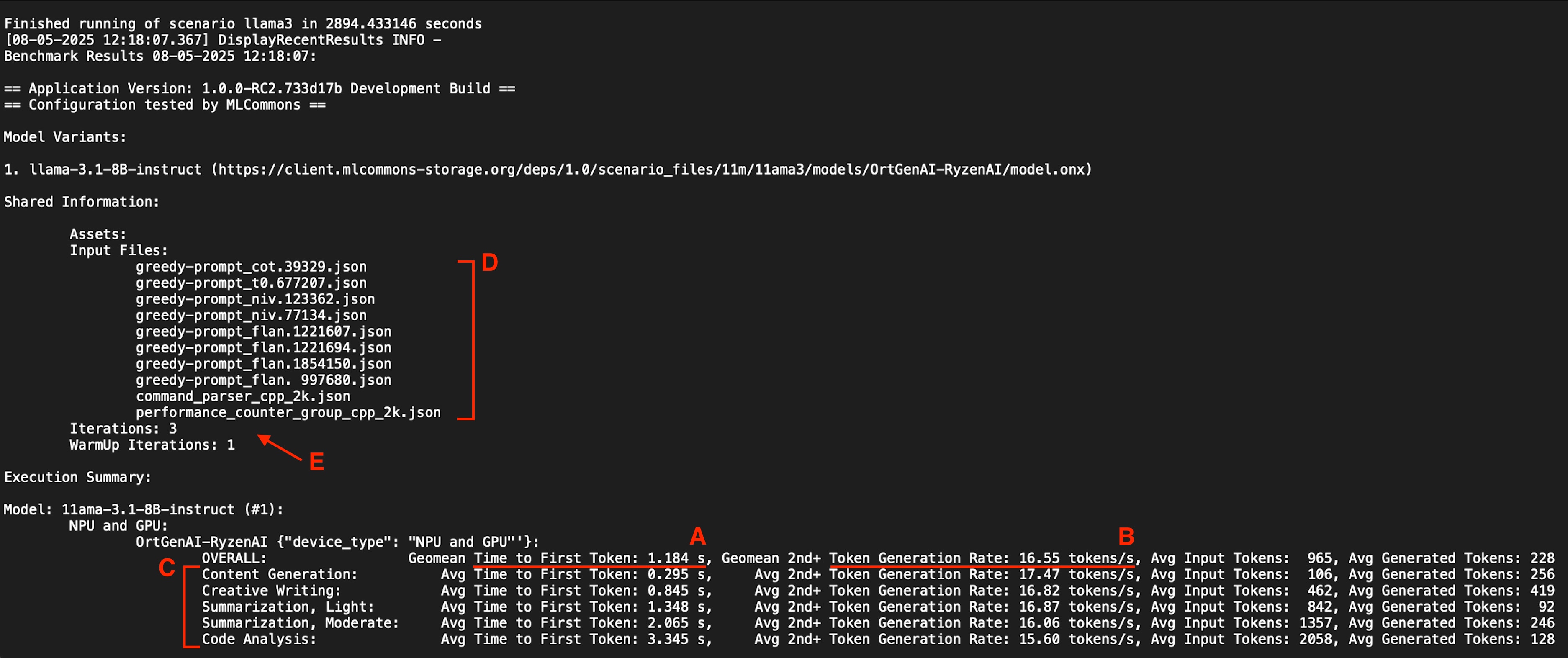
Figure 1- Benchmark Output Screenshot - A) Overall Geomean TTFT, B) Overall Geomean TPS, C) Results of all five categories, D) all 10 prompt files, E) 3 iterations counting to score and 1 warmup not counted in score
Results and Analysis
Each model reports a summary of five prompt categories showing TTFT in seconds and TPS for each category, along with a geometric mean (geomean) overall score. TTFT is the time to generate the first token – lower is better. TPS is the average token generation rate (excluding the first token) – higher is better. Each category has two prompts with approximate input/output token counts as follows:
Category |
Approximate input tokens |
Approximate output tokens |
Content generation |
128 |
256 |
Creative writing |
512 |
512 |
Summarization, Light |
1024 |
128 |
Summarization, Moderate |
1566 |
256 |
Code Analysis |
2059 |
128 |
Performance Summary
- AMD Ryzen AI Max+ 395 excels in token generation due to its powerful iGPU and memory bandwidth, producing 61 TPS on Phi-3.5. For reference, that’s roughly 2-3 times as fast as a human speed-reader can consume text.
- TTFT is driven by the Neural Processing Unit (NPU) in Hybrid mode. The AMD Ryzen AI Max+ 395 produces the first token in under 0.7 seconds for Phi-3.5 and just over 1 second for larger models.
- AMD Ryzen AI in Hybrid mode excels in token throughput measured as TPS, and the AMD Ryzen AI Max+ 395 increases TPS by ~75%, again due to its powerful GPU and memory bandwidth.
Visualizing the Results
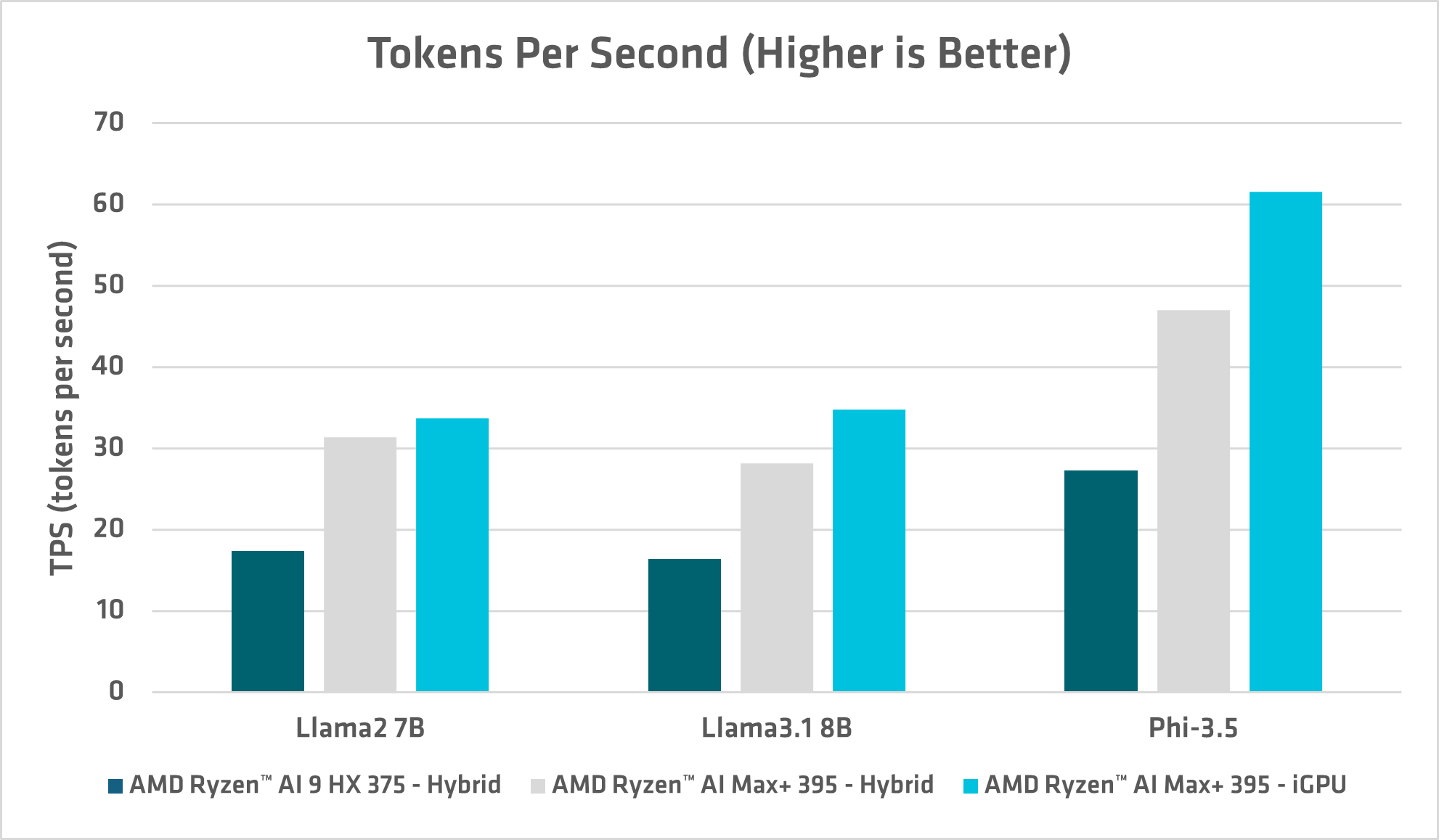
Figure 2 - Token Generation Rate measured as TPS[1]
Conclusion
MLPerf Client v1.0 testing shows AMD Ryzen™ AI Max Series delivers fast, responsive on-device LLM performance. The Ryzen™ AI Max+ 395 hits 61 TPS on Phi-3.5—several times faster than human reading speed—while the Ryzen™ AI 9 HX 375 delivers strong results for Premium Thin and Light systems. With low latency TTFT across models, Ryzen AI enables smooth, interactive AI experiences today and has headroom for larger models ahead.
Contributors:
Rajeev Patwari, Ashish Sirasao, Varun Sharma, Manasa Bollavaram, Alex Minooka, Sanket Shukla, Pooja Ganesh, Aaron Ng, Namal Rajatheva, Yue Gao, OIeksandr Kholodnyi, Anjul Gurmukhani, Tejus Siddagangaiah, Zhenhong Guo, Booker Yang, Tianping Li, Jianlong Yi


Related Blogs
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026
-
Enabling Language-specific Reasoning in Multilingual Models with Reinforcement Learning — ROCm Blogs
Learn how to train multilingual reasoning models with reinforcement learning and extend context windows on AMD Instinct GPUs.
July 23, 2026
-
Agentic AI Workflows Simplified
Rocm.AI simplifies how developers build and serve with ROCm on AMD GPU’s
July 23, 2026








Footnotes
The TPS performance gap in Figure-2 between Hybrid and iGPU on Max+ 395 is expected to close in a future AMD iGPU driver release.
Footnotes
The TPS performance gap in Figure-2 between Hybrid and iGPU on Max+ 395 is expected to close in a future AMD iGPU driver release.