Accelerating AI Training: How AMD Instinct™ MI350 Series GPUs Delivered Breakthrough Performance and Efficiency in MLPerf™ Training v5.1
Nov 13, 2025

Breakthrough AI Training Performance Showcased with First MLPerf™ 5.1 Training Submission on AMD Instinct™ MI350 Series GPUs
The latest MLPerf™ 5.1 Training results mark an important milestone — the first MLPerf training submission using AMD Instinct™ MI350 Series GPUs. These new benchmarks demonstrate breakthrough generational performance gains and highlight broad ecosystem participation across some of today’s most demanding AI training workloads.
Building on the strong MLPerf 5.1 Inference results released earlier this year, this submission represents the first time the AMD Instinct MI350 Series — including both the MI355X and MI350X GPUs — have been publicly benchmarked for AI training. The results show clear progress in scalability, efficiency, and compute performance, underscoring how the AMD Instinct MI350 Series is accelerating the development of next-generation generative AI models.
Up to 2.8X Generational Performance Gain for AI Training
The new AMD Instinct™ MI350 Series GPUs deliver breakthrough generational performance, achieving up to 2.8X faster time-to-train compared to the AMD Instinct™ MI300X, and 2.1X faster compared to the Instinct MI325X platform.

Measured on the Llama 2-70B LoRA (FP8) benchmark in the latest MLPerf™ 5.1 Training round, the AMD Instinct MI355X GPU significantly accelerates model convergence — cutting training time from nearly 28 minutes on MI300X to just over 10 minutes. Even against the MI325X GPU, training completes in nearly half the time.
These gains reflect a combination of architectural improvements, HBM3E memory bandwidth leadership, and AMD ROCm™ 7.1 software optimizations that enhance kernel performance and communication efficiency. Together, they enable faster model fine-tuning and improved energy efficiency across large-scale generative AI workloads.
With each generation, AMD Instinct GPUs continue to set new performance standards for AI training — accelerating innovation from model design to deployment.
Competitive Performance Across Industry Benchmarks
The AMD Instinct™ MI355X platform delivers highly competitive training performance across leading generative AI workloads when compared to an average of all NVIDIA partner submissions using the FP8 datatype on both B200 and B300 GPUs in the MLPerf™ 5.1 Training round.
For this comparison, every partner submission utilizing NVIDIA B200-SXM or B300-SXM hardware with FP8 precision was aggregated and averaged — providing a balanced, system-level view of performance across the competitive landscape.
On the Llama 2-70B LoRA (FP8) benchmark, the MI355X completed training in 10.18 minutes, closely matching the averaged performance of NVIDIA B200 and B300 systems, which finished in 9.85 and 9.59 minutes, respectively. On Llama 3.1-8B (FP8) pre-training, the MI355X completed in 99.7 minutes, compared to 93.69 and 95.10 minutes for the averaged NVIDIA GPU-based results.

It’s also worth noting that no FP8 submissions were made by NVIDIA in the current MLPerf Training v5.1 round — only FP4 results were provided. AMD chose not to submit in FP4 for this round because FP4 remains not yet production-ready for training workloads. The format currently introduces tradeoffs in numerical accuracy and often requires switching back to FP8 precision midway through the training to reach training accuracy goal. Instead, AMD continues to focus optimization efforts on FP8 training, the datatype most widely adopted by customers today and best suited for large-scale, high-accuracy model training while working on FP4 algorithmic development to make it usable in real life scenarios in near future.
The latest FP8 training number published by Nvidia is from the previous MLPerf Training v5.0 round where 8 GB200 GPUs reached an 11.15-minute training time on Llama 2-70B LoRA (Submission ID 5.0-0076). In this round, MD Instinct MI355X (Submission ID 5.1-0018) completed the same workload in 10.18 minutes — nearly a 10% performance improvement in FP8 training.
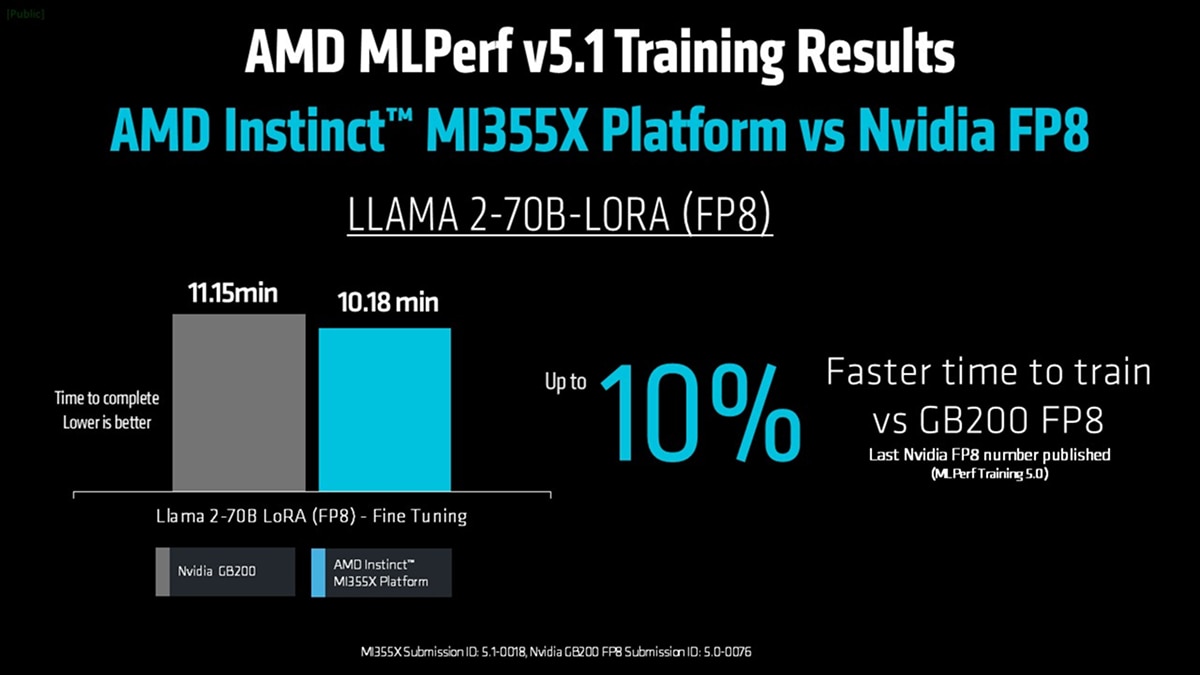
These results highlight how the MI355X platform continues to deliver competitive, efficient, and scalable training performance, reinforcing the growing strength of the AMD Instinct and ROCm™ ecosystem in enabling next-generation generative AI workloads.
Record-Level Ecosystem Participation
The latest MLPerf™ 5.1 Training round also demonstrated record-level ecosystem participation across the AMD Instinct™ platform family — including the MI300X, MI325X, MI350X, and MI355X GPUs.
In total, nine key partners — Asus, Cisco, Dell, Giga Computing, Krai, MangoBoost, MiTAC, QCT, and Supermicro — submitted training results on AMD Instinct hardware, marking the broadest industry engagement to date for AMD in MLPerf Training.
What makes this achievement especially noteworthy is that every partner submission represented their first time submitting on the new MI355X platform — yet all results landed within just 1% of AMD’s own submissions on the same benchmarks.

That level of alignment on a first attempt underscores the maturity and consistency of the ROCm™ software stack, as well as the readiness of AMD Instinct hardware for immediate deployment across diverse partner configurations.
Partners showcased results on demanding workloads such as Llama 2-70B LoRA fine-tuning and Llama 3.1-8B pre-training — proving that AMD Instinct MI355X GPU systems reproduce, high-performance results across a range of real-world training scenarios. One example includes MangoBoost’s MLPerf 5.1 Training blog, where the company highlights its own multi-node AMD Instinct submission and the scalability achieved in large AI workloads.
This wave of first-time submissions reinforces how the AMD AI ecosystem is scaling rapidly and collaboratively, empowering partners to deliver robust, production-ready AI training platforms from day one.
AMD ROCm™ 7.1 Software: Enabling High-Performance, Scalable, and Efficient AI Training
AMD ROCm™ 7.1 is the software engine behind all MLPerf™ 5.1 training submissions on AMD Instinct™ GPUs, enabling the high performance, scalability, and efficiency seen across every AMD-based result. This latest ROCm release delivers end-to-end advancements across the stack — from kernel and compiler optimizations to communication efficiency and framework integration — designed to accelerate real-world workloads and improve scalability across multi-node systems.

With optimized training throughput, AMD ROCm software accelerates model convergence using high-efficiency FP8 precision, providing the performance and numerical stability required for today’s most demanding generative AI models. Its kernel and compiler optimizations, including tuned GEMM operations, fused attention, and updated compiler stacks such as XLA and TorchInductor, drive higher throughput and more consistent performance across a range of training workloads.
Enhanced memory and communication efficiency improves bandwidth utilization and overlap of compute and communication tasks, delivering better scaling from single GPU to multi-node configurations. And with day-0 model support, AMD ROCm software is ready for leading frameworks and models — including Llama 3.1-8B, Mistral, and SD-XL — giving developers the tools they need to train and fine-tune the latest AI workloads immediately.
The consistency and performance achieved across AMD Instinct™ MI355X partner submissions all trace back to AMD ROCm software. This release continues to demonstrate that software innovation is every bit as critical as silicon performance — together, they form the foundation of efficient, scalable, and production-ready AI training.
Final Takeaway: Advancing AI Training Leadership on an Annual Cadence
The MLPerf™ 5.1 Training results mark a defining moment for the AMD Instinct™ MI350 Series, showcasing breakthrough generational performance, strong competitive positioning, and record ecosystem participation — all powered by the open and rapidly evolving ROCm™ 7.1 software platform.
With up to 2.8X faster training performance compared to the previous generation, near-parity results against NVIDIA’s latest FP8-based submissions, and partner outcomes within 1% of the official AMD submission, the AMD Instinct MI355X platform demonstrates both leadership and consistency across real-world AI training workloads.
Behind these results is a deliberate and steady innovation rhythm. The AMD Instinct roadmap continues to advance on an annual cadence — from the MI300X in 2023 to the MI325X in 2024, and now to the MI350 Series in 2025, delivering new levels of compute density, memory bandwidth, and software optimization with each generation. Looking ahead, the MI450 Series and next-generation CDNA™ architecture are already positioned to extend this momentum into 2026 and beyond.

Together, AMD Instinct GPUs and ROCm software form a unified platform for AI training and inference — one built to scale with the demands of next-generation generative AI. As MLPerf continues to evolve, AMD remains committed to open benchmarking, collaboration, and continuous innovation, driving the performance and efficiency that define modern AI infrastructure.
For those interested in the deeper technical story behind these results, two new AMD ROCm blogs detail the work behind the MLPerf Training submissions. The first, “Inside MLPerf Training v5.1”, explores how AMD ROCm software optimizations enabled these performance gains, while the second, “Reproducing MLPerf Training v5.1 Results”, walks through the process of replicating these benchmarks on AMD Instinct hardware — reflecting the AMD commitment to openness and reproducibility in AI performance.
Footnotes
- https://mlcommons.org/benchmarks/training/
- MI350-021 - Calculations by AMD Performance Labs in May 2025, based on the published memory capacity specifications of AMD Instinct™ MI350X / MI355X OAM 8xGPU platform vs. an NVIDIA Blackwell B200 8xGPU platform. Server manufacturers may vary configurations, yielding different results. MI350-021
- MI350-012 - Based on calculations by AMD as of April 17, 2025, using the published memory specifications of the AMD Instinct MI350X / MI355X GPUs (288GB) vs MI300X (192GB) vs MI325X (256GB). Calculations performed with FP16 precision datatype at (2) bytes per parameter, to determine the minimum number of GPUs (based on memory size) required to run the following LLMs: OPT (130B parameters), GPT-3 (175B parameters), BLOOM (176B parameters), Gopher (280B parameters), PaLM 1 (340B parameters), Generic LM (420B, 500B, 520B, 1.047T parameters), Megatron-LM (530B parameters), LLaMA ( 405B parameters) and Samba (1T parameters). Results based on GPU memory size versus memory required by the model at defined parameters, plus 10% overhead. Server manufacturers may vary configurations, yielding different results. Results may vary based on GPU memory configuration, LLM size, and potential variance in GPU memory access or the server operating environment. *All data based on FP16 datatype. For FP8 = X2. For FP4 = X4. MI350-012.
- The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.
Footnotes
- https://mlcommons.org/benchmarks/training/
- MI350-021 - Calculations by AMD Performance Labs in May 2025, based on the published memory capacity specifications of AMD Instinct™ MI350X / MI355X OAM 8xGPU platform vs. an NVIDIA Blackwell B200 8xGPU platform. Server manufacturers may vary configurations, yielding different results. MI350-021
- MI350-012 - Based on calculations by AMD as of April 17, 2025, using the published memory specifications of the AMD Instinct MI350X / MI355X GPUs (288GB) vs MI300X (192GB) vs MI325X (256GB). Calculations performed with FP16 precision datatype at (2) bytes per parameter, to determine the minimum number of GPUs (based on memory size) required to run the following LLMs: OPT (130B parameters), GPT-3 (175B parameters), BLOOM (176B parameters), Gopher (280B parameters), PaLM 1 (340B parameters), Generic LM (420B, 500B, 520B, 1.047T parameters), Megatron-LM (530B parameters), LLaMA ( 405B parameters) and Samba (1T parameters). Results based on GPU memory size versus memory required by the model at defined parameters, plus 10% overhead. Server manufacturers may vary configurations, yielding different results. Results may vary based on GPU memory configuration, LLM size, and potential variance in GPU memory access or the server operating environment. *All data based on FP16 datatype. For FP8 = X2. For FP4 = X4. MI350-012.
- The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.

Contributors

Related Blogs
-
Running Cloud Agents? Your Most Important Upgrade Could be an AMD Zen 5 CPU
As agents begin navigating applications, coordinating tools and completing real work, the local CPU is becoming a critical part of the AI execution pipeline.
July 16, 2026
-
From Vector Search to Agentic RAG: Building an Enterprise Research Analyst with hipVS — ROCm Blogs
Learn how to build an agentic RAG research assistant using hipVS GPU-accelerated vector search on AMD Instinct GPUs, with multi-query decomposition, parallel retrieval, and cited sources synthesis.
July 14, 2026
-
When a Faster Kernel Doesn’t Speed Up Serving: Profiling FP8 KV Cache on AMD Instinct MI308X — ROCm Blogs
Learn how a 34% faster FP8 KV cache kernel delivered 0% E2E speedup, and how profiling attribution exposed the hidden dtype-cast cost on MI308X.
July 14, 2026
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026
-
Local Image and Video Generation on AMD Ryzen™ AI Max+ Processor (Windows) — ROCm Blogs
Run ComfyUI natively on Windows on AMD Ryzen AI Max+ with ROCm 7.2.1—SDXL, Flux, and video workflows on the Radeon 8060S, no WSL.
July 13, 2026
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026
-
GEAK Agent-Driven Optimization of the DeepSeekV4 MLA Kernel — ROCm Blogs
GEAK Agent accelerates DeepSeekV4 MLA kernel optimization with Triton and delivers SGLang E2E gains on AMD GPUs.
July 12, 2026
-
ZenDNN 6.0 FP16 Inference and MoE Acceleration
ZenDNN 6.0 takes the next step: FP16 functional support for AMD’s 6th Gen EPYC™ processors, MoE model optimization, and the vLLM compatibility window.
July 10, 2026







