FAQs: AMD Variable Graphics Memory, VRAM, AI Model Sizes, Quantization, MCP and More!
Jul 29, 2025

As state-of-the-art AI workloads become more advanced, the amount of memory available for AI accelerators has become a key bottleneck. Running the latest LLM, VLM or image generation model locally requires ever-increasing amounts of memory. The AMD Ryzen™ AI Max+ 395 (128GB) processor with 96GB of Variable Graphics Memory offers an incredibly versatile way to solve this problem.
In order to run up to 128 billion parameter models on AMD Ryzen™ AI Max+ 395 with 128GB memory, you need the right bits. Learn more about running very large models like Meta's Llama 4 109 Billion (17 Billion active) on the AMD Ryzen™ AI Max+ 395 (128GB) processor here: How to run up to 128 billion parameter models on Windows.
This article will explore a key capability of AMD Ryzen™ AI Max+ systems to convert system RAM into discrete graphics memory and why consumers should care about running larger sized models – as well as answer some frequently asked questions about LLMs, parameters, quantization and agentic workflow.
AMD Ryzen™ AI processors and Model support matrix (4-bit)
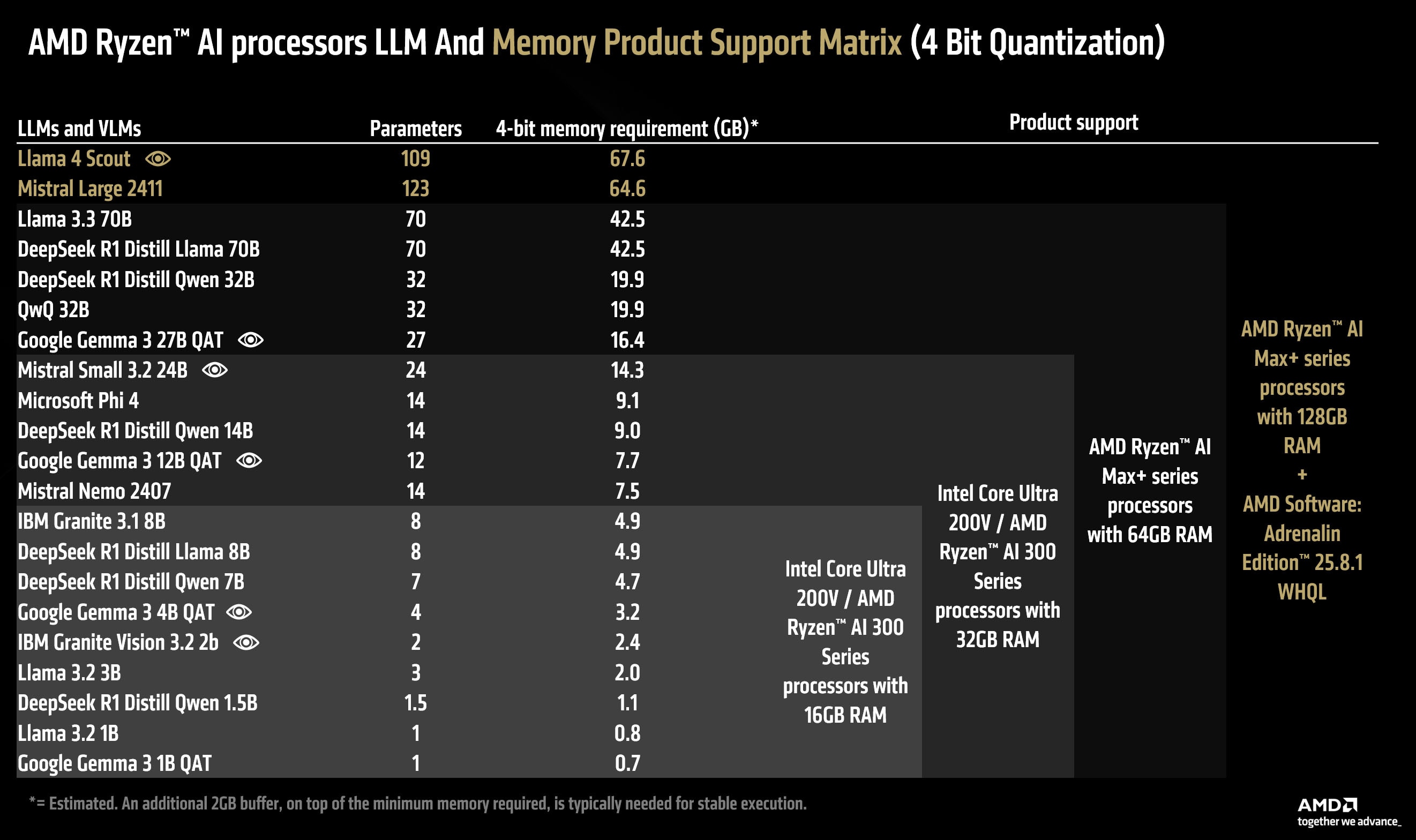
For the casual user that just needs an offline, on-device, vision-capable AI assistant, the AMD Ryzen™ AI 9 300 series processors with 16GB of RAM are a great, cost-effective solution. At the time of writing, AMD recommends Google Gemma 3 4B QAT with LM Studio as the perfect AI companion for those that want AI processing, secure on their device.
Advanced users that want higher quality answers (with a speed tradeoff) can choose the AMD Ryzen™ AI 9 300 series processors with 32GB of RAM with Google Gemma 3 12B QAT and LM Studio. This significantly more capable model can output far more sophisticated answers with a much higher degree of accuracy than its 4 billion parameter counterpart.
For the power user that does not want to compromise on performance or upgrade to even-higher quality responses – we recommend the AMD Ryzen™ AI Max+ series processors with 64GB of RAM. This platform, codenamed "Strix Halo", doubles the bandwidth to 256 GB/s (roughly doubling the tokens/s) available to the user while allowing up to 48GB dedicated graphics memory through VGM. Users with this setup can run Google Gemma 3 27b QAT – which is a vision language model capable of on-device radiology or run Google Gemma 3 12b QAT two times faster than the competing products of the lower tier. The AMD Ryzen™ AI Max+ platform can also run image generation models with up to 12B parameters (like FLUX Schnell in FP16) effortlessly.
Finally, for the AI enthusiast/developer that absolutely must run the highest quality model and values a high accuracy of answers over rapid-fire speed – the AMD Ryzen™ AI Max+ 395 (128GB) processor with up to 96GB of dedicated graphics memory is the ultimate choice. This platform can run 4-bit LLMs/VLMs up to 128B parameters or LLMs/VLMs in FP16 up to 32B parameters (such as Google Gemma 3 27b in FP16).
What is AMD Variable Graphics Memory?
AMD Variable Graphics Memory is a BIOS-level feature introduced in AMD Ryzen™ AI 300 series processors (and beyond) which allows the user to reallocate a % of the system RAM to integrated graphics. This change – a BIOS level reallocation made possible because of the unified memory architecture of modern AMD Ryzen™ AI processors – allows the user to essentially trade spare system RAM for dedicated graphics memory.
Note that Variable Graphics Memory or “dedicated” graphics memory should not be confused with “shared” graphics memory. In typical Windows systems, 50% of your RAM is already shared with the integrated graphics card and shows up as “shared graphics memory” in the task manager. You can quickly identify this memory as shared because it remains accessible to the CPU in the form of system RAM.
How do I turn on AMD Variable Graphics Memory?
In order to turn on VGM, right click anywhere on your desktop and click on "AMD Software: Adrenalin Edition".
Click on the "Performance" Tab. Click on the "Tuning" Tab. From there you should be able to set Variable Graphics Memory using the drop down menu. Doing so will require a restart. It is important to note that VGM will subtract from the system RAM that the CPU has access to, is typically a power-user feature and may deteriorate system performance if used incorrectly. AMD recommendations for casual users, gamers, power users and AI enthusiasts are: Default, Medium, High and Custom (75%) respectively.
Variable Graphics Memory requires a restart and is virtually identical to VRAM from the perspective of the operating system. Any % of RAM that is converted to VRAM using this feature will become “dedicated graphics memory” from the perspective of the OS – and will no longer be available for use as system RAM. This allows a single, contiguous, dedicated memory block to become available for the iGPU for massive AI workloads. Since a good chunk of AI applications are designed with VRAM in mind – this allows GenAI workloads to run out of the box and eliminates the need for app-side management of shared memory as well as reducing performance penalties due to overflow (from the smaller dedicated block to the larger shared memory pool).
It is also helpful to consider the term “Total Graphics Addressable Memory” where Total Graphics Addressable Memory = Shared Graphics Memory + Discrete Graphics Memory (aka VRAM).
Using VGM not only enables a single, contiguous, dedicated block of VRAM to become available for the iGPU but also increases the total graphics addressable memory available for use to the iGPU (for applications that can make use of shared memory).
Let’s look at this simple example below:
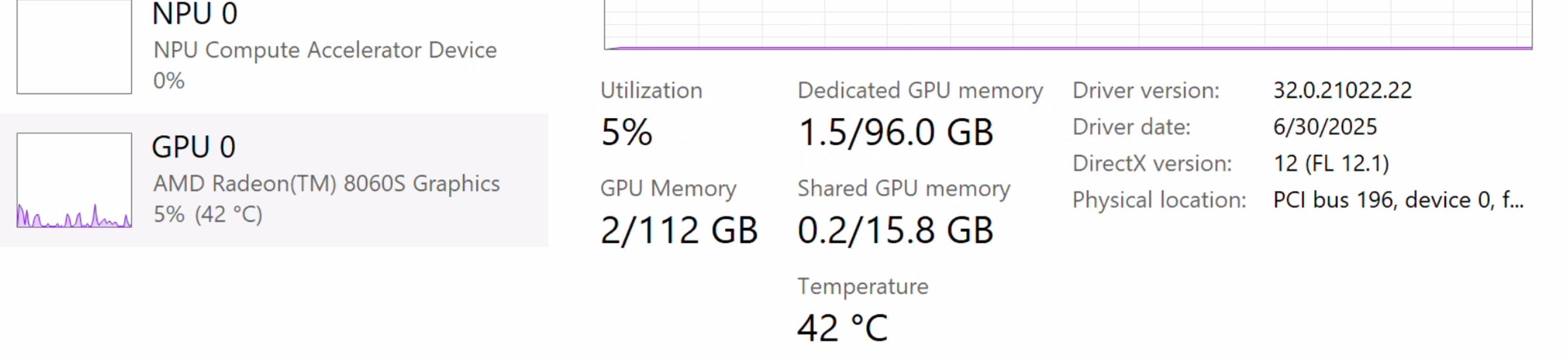
A 128GB system by default would be set to 512 MB discrete graphics memory with the remaining memory split into shared and CPU reserved blocks. The memory breakdown would be as follows with a total of 512 MB dedicated memory and 64.3 total graphics addressable memory available to the iGPU:

A 128GB system with VGM set to 96GB on the other hand would have:

The highest performance can be unlocked by limiting workloads to 96GB – but if needed – the iGPU (set to 96GB VGM) can technically access a total graphics memory size of 112GB on AMD Ryzen™ AI MAX+ powered 128GB systems.
Why should users care about running AI models with large parameter sizes?
A larger parameter size, all other variables held constant, will increase the quality of the output at the cost of increased processing time and higher memory utilization.
If, for example, you are dealing with large language models, a model with a higher parameter count will generally be smarter than one with a lower count (of the same architecture/release/precision etc.). Similarly, language models with vision support (called vision language models or VLMs) will demonstrate higher visual reasoning capability in the variants with higher number of parameters.
Let's see a practical example of this in action:
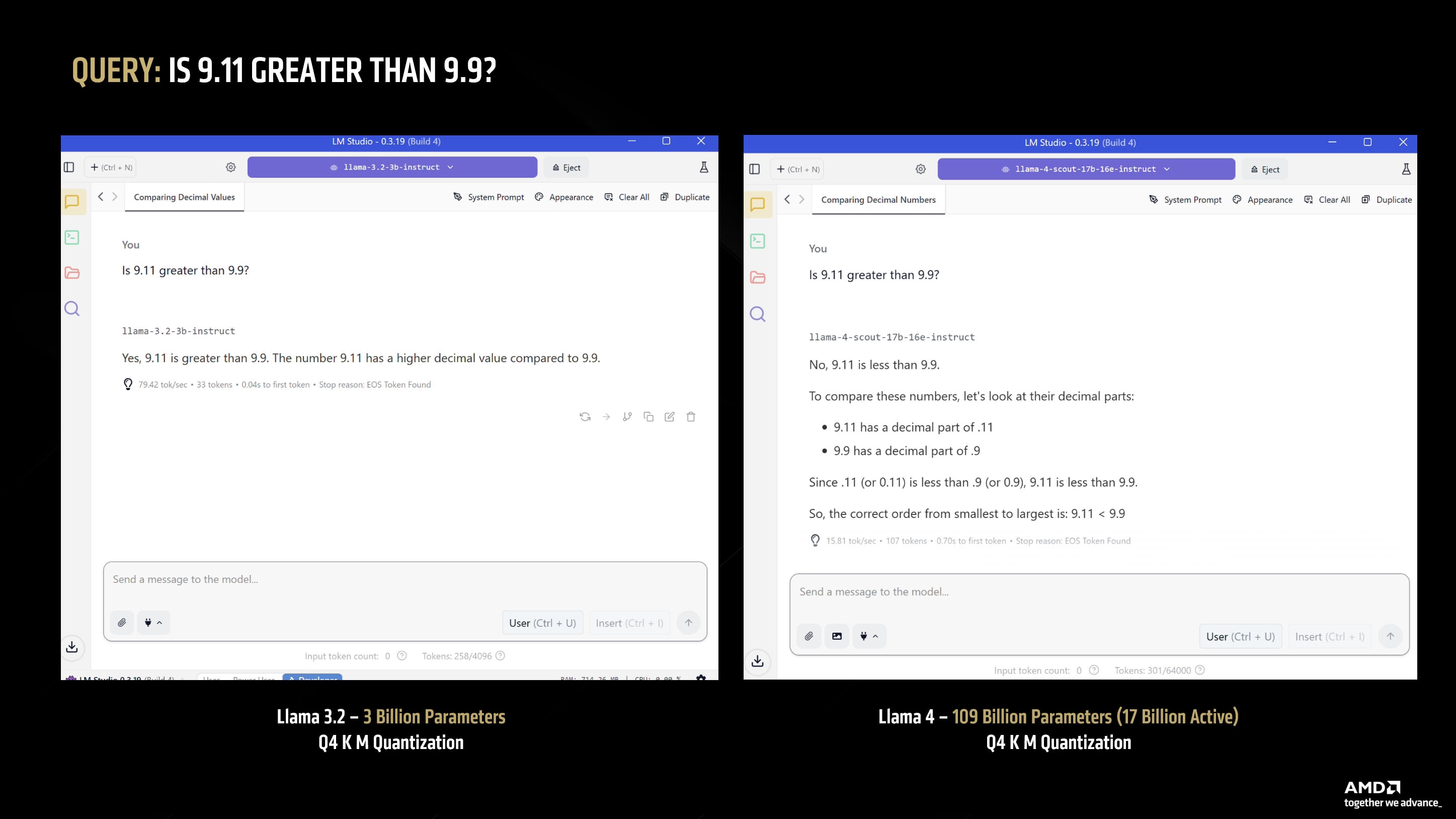
In the example above, the 3B model is a light weight model that can run on most machines – while the 109b (17b active) model requires roughly 96GB of VRAM (in Q4 K M – which is a 4-bit quantization).
This “higher parameter is better” rule isn’t limited to language models either – a very visual example of this is image generation models. Below, we compare Stable Diffusion 1.5 – which is a very old model released in 2022 and constituting 0.9B parameters – versus SD 3 Medium – an 8.1 Billion parameter diffusion model released in 2024.

The SD 1.5 model can run on most modern laptops (and needs 5-7GB of VRAM), but the SD 3 Medium model requires 18GB of VRAM in FP16. The difference in output quality is readily apparent between the two. Scaling to even higher parameter models like FLUX. Schnell can require 32GB VRAM just to run the model in partial offload (UNET offload) mode. The AMD Ryzen™ AI Max+ 395 (128GB) processor can run models like FLUX.Schnell with full offload support.
What about precision and quantization?
Quantization converts the weights of AI models from higher precision formats (say FP16) to lower precision formats (like Q8 or lower). Different quantization types – even at the same bit depth – are not identical in characteristics, accuracy or performance.
The most common (and generally the most deployed) form of LLM quantization is 4-bit. In local solutions, and through the widely adopted llama.cpp framework, this takes the form of Q4 K M quantization. The entrenchment of this standard can be traced back to the following llama.cpp documentation (created in 2023) which established 4-bit (and specifically Q4 K M) as the “minimum acceptable” standard for LLM quantization.
quantize --help
Allowed quantization types:
2 or Q4_0 : 3.50G, +0.2499 ppl @ 7B - small, very high quality loss - legacy, prefer using Q3_K_M
3 or Q4_1 : 3.90G, +0.1846 ppl @ 7B - small, substantial quality loss - legacy, prefer using Q3_K_L
8 or Q5_0 : 4.30G, +0.0796 ppl @ 7B - medium, balanced quality - legacy, prefer using Q4_K_M
9 or Q5_1 : 4.70G, +0.0415 ppl @ 7B - medium, low quality loss - legacy, prefer using Q5_K_M
10 or Q2_K : 2.67G, +0.8698 ppl @ 7B - smallest, extreme quality loss - not recommended
12 or Q3_K : alias for Q3_K_M
11 or Q3_K_S : 2.75G, +0.5505 ppl @ 7B - very small, very high quality loss
12 or Q3_K_M : 3.06G, +0.2437 ppl @ 7B - very small, very high quality loss
13 or Q3_K_L : 3.35G, +0.1803 ppl @ 7B - small, substantial quality loss
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 3.56G, +0.1149 ppl @ 7B - small, significant quality loss
15 or Q4_K_M : 3.80G, +0.0535 ppl @ 7B - medium, balanced quality - *recommended*
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 4.33G, +0.0353 ppl @ 7B - large, low quality loss - *recommended*
17 or Q5_K_M : 4.45G, +0.0142 ppl @ 7B - large, very low quality loss - *recommended*
18 or Q6_K : 5.15G, +0.0044 ppl @ 7B - very large, extremely low quality loss
7 or Q8_0 : 6.70G, +0.0004 ppl @ 7B - very large, extremely low quality loss - not recommended
1 or F16 : 13.00G @ 7B - extremely large, virtually no quality loss - not recommended
0 or F32 : 26.00G @ 7B - absolutely huge, lossless - not recommended
As we can see, perplexity loss (which, in simplified terms, is a measure of how confused the model is when predicting the next token) is acceptable for most tasks at Q4 K M and officially recommended in this documentation.
Note that Llama.cpp is typically used in conjunction with GGUF – a binary format developed by @ggerganov (the same developer that created the Llama.cpp framework) which decouples quantization from hardware support of data types. Readers interested in reading about how GGUF allows the deployment of data types without hardware support can read the technical documentation here.
This documentation, however, was created before models became capable of performing highly sophisticated coding tasks. So while Q4 K M (for llama.cpp) is perfectly acceptable for general purpose interactions with LLMs, it starts to show deteriorated responses in coding examples (unless you offset this by going to very large parameter sizes). Because of this reason Q6 is generally the minimum viable level for coding – with Q8 offering almost lossless quality (albeit with proportionally higher memory requirements and corresponding performance penalty). Note that specialized quantization techniques like Google’s 4-bit QAT (Quantization Aware Training) used in Gemma 3 models is superior to Q4 K M in terms of perplexity loss but is not widely supported nor available for the vast majority of models out there.
In short: the casual user will be fine with Q4 K M but consumers requiring a high degree of accuracy in the model answers (such as coding or on-device radiology) should use at least Q6 (wherever a specialized weight like QAT is not available) or upgrade to the highest parameter size available.
What is Model Context Protocl (MCP) and Tool Calling 🛠?
Model Context Protocol or MCP allows LLMs to use “tools” – these tools can range from something as simple as the capability of opening your browser or reading your files to complicated API access to code snippets that can execute pre-defined programming when called.
This term will usually always be used in the context of agentic workflows. Standardized by Anthropic, this “plugin” capability allows the LLM to become an “active” agent that is capable of effecting changes – locally on your personal system or online – instead of being confined to the limits of the chat window.
MCP installations usually consist of an underlying code block – whether its an NPX package, UV or a Docker based pathway along with instructions that instruct the LLM on how to use the tools.
It is worth paying attention to this latter part – because using any MCP will typically add thousands to your input prompt as the documentation required by the LLM to understand and use the tool – significantly increasing the prompt processing phase of LLMs. On top of that, tool call returns can incrementally add tens of thousands of tokens to the context that the LLM has to parse. Running multiple tool calls concurrently can therefore add a tremendous amount of tokens for the LLM to process, require lots of memory, and make the workload almost completely compute bound.
Not all LLMs will be proficient at reading the instructions, understanding them and proficiently using the tools (or knowing what to do with the tool call returns) – so your mileage will vary depending on the model type. Generally speaking, LLMs released recently have a particular focus on tool calling ability and should fare well.
A well curated list of Docker-based MCP implementations can be found here: Docker Hub
Legal Disclaimer: Giving a Large Language Model tool access to your system may result in the AI acting in unpredictable ways with unpredictable outcomes. Only install implementations from trusted sources, and failure to exercise appropriate caution may result in damages (foreseen or unforeseen). Use such implementations at your own risk, AMD makes no representations/warranties in this context.


Related Blogs
-
Day 0 Support for MiniMax-H3 on AMD GPUs
Learn how MiniMax-H3 delivers unified multimodal AI video generation with day-0 support on AMD Instinct™ GPUs.
August 02, 2026
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Closing the GPU Cluster Validation Gap: A Kubernetes-Native Approach with CVF — ROCm Blogs
Learn how to validate AMD GPU clusters end-to-end with CVF: hardware acceptance, mesh bandwidth, RDMA, and RCCL testing in one pipeline.
July 28, 2026
-
AMD GPU Operator v1.5.0: DRA Support, Automated GPU Node Recovery, and Expanded Kubernetes Infrastructure Control — ROCm Blogs
Discover how AMD GPU Operator v1.5.0 improves GPU scheduling, automates node recovery, and expands Kubernetes control.
July 27, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026







