AMD Ryzen™ AI Max+ Upgraded: Run up to 128 Billion parameter LLMs on Windows with LM Studio
Jul 29, 2025

During CES 2025, AMD introduced the world’s first windows AI PC processor to run Llama 70b locally. Powered by llama.cpp and LM Studio – this was a key capability for LLM deployment in thin and light windows systems.
Today, we are announcing a significant upgrade to AMD Variable Graphics Memory to enable up to 128 billion parameters in Vulkan llama.cpp on Windows. The upgrade will be housed in the upcoming Adrenalin Edition™ 25.8.1 WHQL drivers and unlock AI workloads that are even more memory intensive and can take full use of the 96GB VGM available on a Ryzen™ AI MAX+ 395 128GB machine on Windows.

Readers can try out this capability, today, by downloading the preview driver and LM Studio:
To learn more about how AMD Variable Graphics Memory works, why consumers should care about running large LLMs, quantization sizes, MCP, tool calling and other frequently asked questions read more by clicking here.
This key capability upgrade also makes the AMD Ryzen™ AI Max+ 395 (128GB) the world’s first windows AI PC processor to run Meta’s Llama 4 Scout 109B (17B active) with full vision and MCP support.
This is a critical milestone that further entrenches AMD as the only vendor providing full-stack, cloud to client solutions for bleeding edge AI workloads. What was previously possible only on dataceneter-grade hardware is now available in thin and light. You can learn more about running Meta Llama 4 on Instinct over here.

This furthers the lead of the AMD Ryzen™ AI Max+ as the premiere, industry-leading, windows platform for LLM deployment in thin and light systems. Through llama.cpp, the AMD Ryzen™ AI Max+ 395 (128GB) processor supports models all the way from tiny 1B models to massive models like Mistral Large with flexible quantization options via GGUF.

Because Meta Llama 4 Scout is a mixture-of-experts model, only 17B parameters are activated at a given time (although all 109 billion parameters need to be held in memory – so the footprint is the same as a dense 109 billion parameter model). This means that users can expect a very usable tokens per second (relative to the size of the model) output rate of up to 15 tokens per second.
This should allow the Llama 4 Scout to be utilized as a highly capable AI assistant on-the-go. If the user wants to switch to a smaller (and faster) model, then they can do that as well (note that performance will be correlated with the number of active parameters for MoE models and all parameters for dense models).
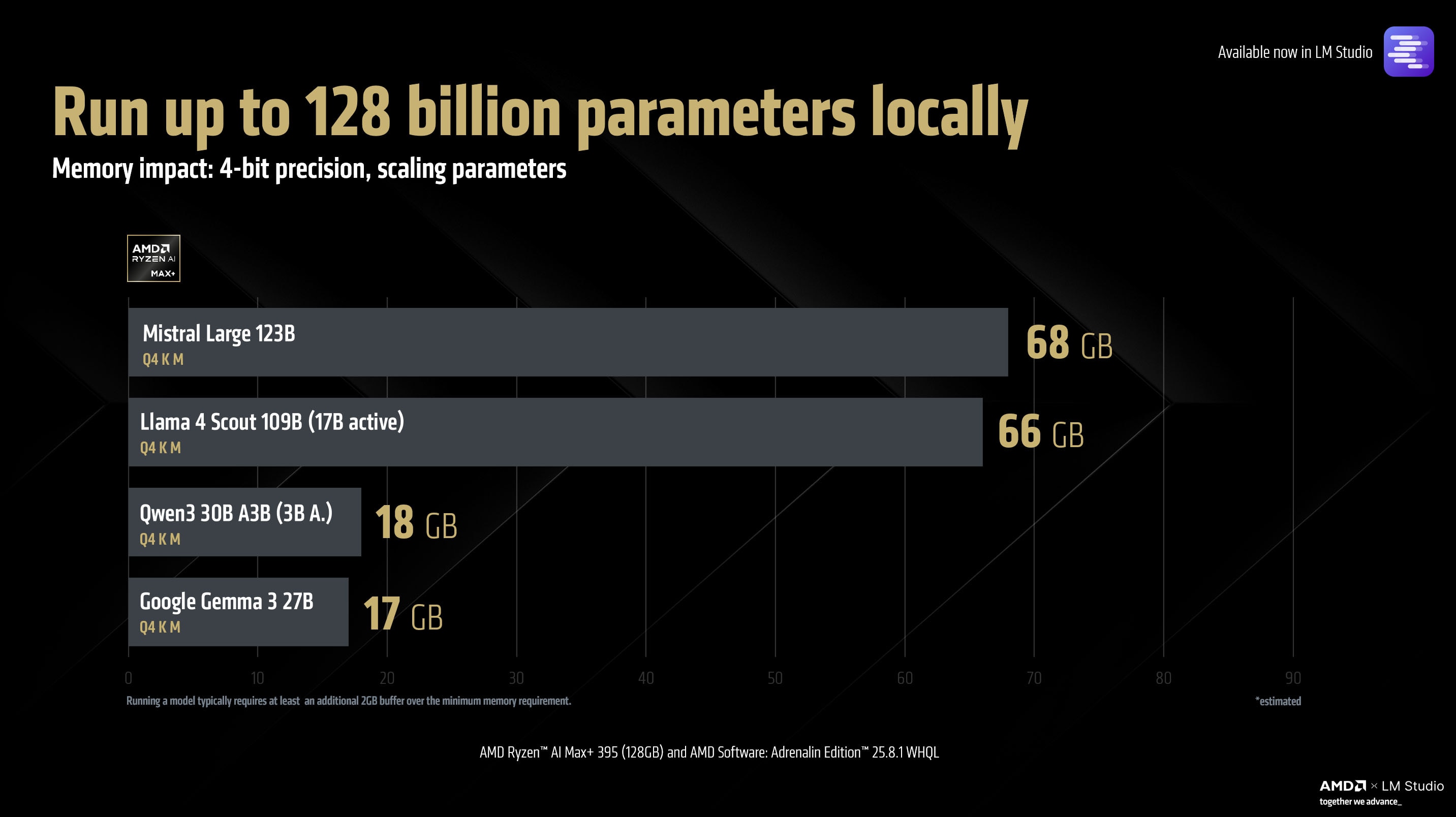
Using models with higher parameter sizes, everything else held constant, increases the quality of their output, and the AMD Ryzen™ AI Max+ 395 (128GB) processor allows complete flexibility in running most of the models supported by llama.cpp.
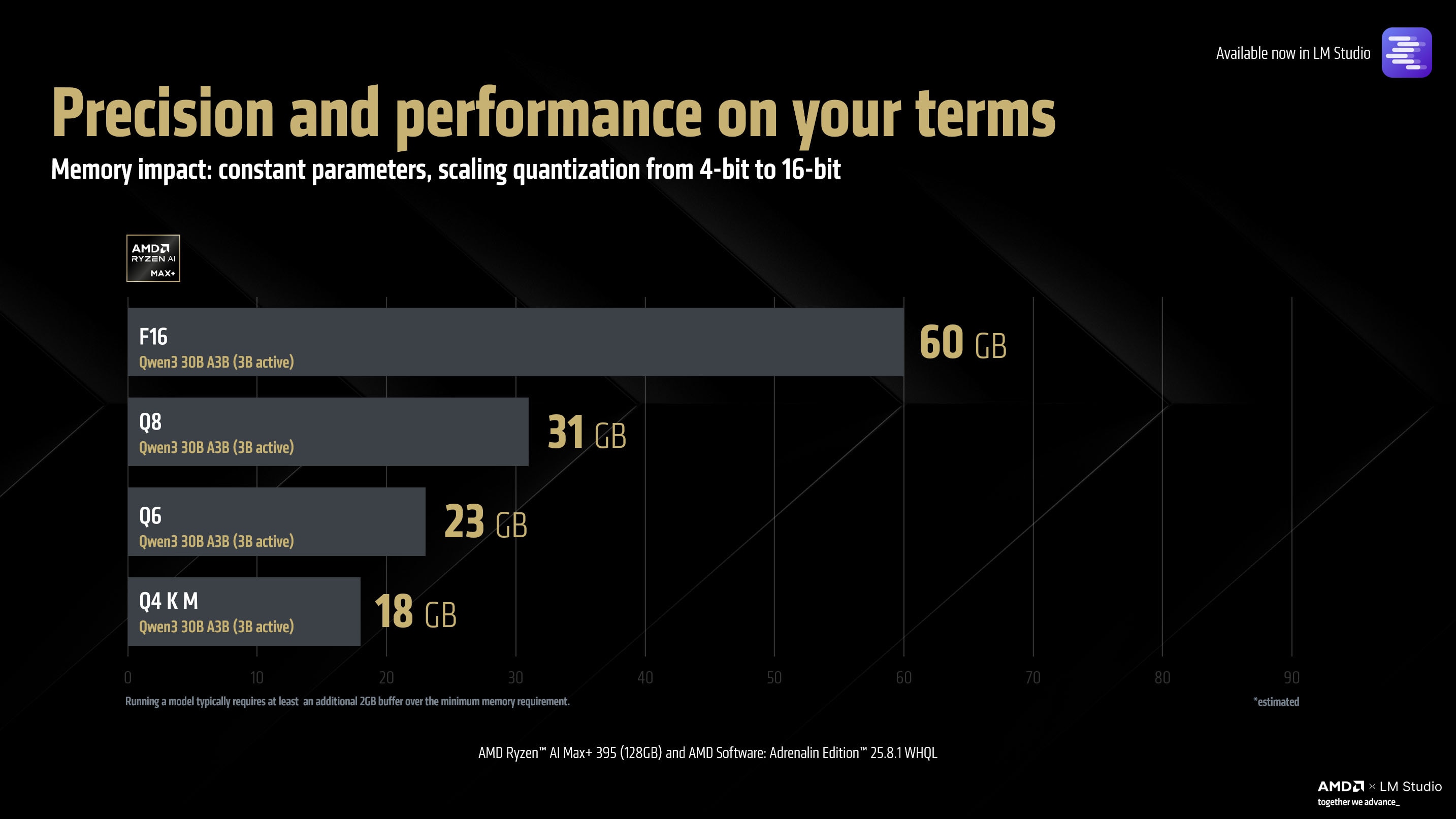
On the other hand, increasing the quantization (while keeping the model constant) can also result in higher quality outputs (with diminishing returns) and if the user is willing to make the tradeoff between performance – the AMD Ryzen™ AI Max+ platform has the memory capability to support up to 16-bit models through llama.cpp.
One variable that has received little attention over the last few months is model context size. The default context, for example, in LM Studio is set to 4096 tokens. A token can be thought of as being roughly equivalent to a single word. With LLM use cases increasingly shifting to token-heavy tasks – whether through RAG or through MCP – having ever larger context lengths supported by your local LLM instance is very important.

The AMD Ryzen™ AI Max+ 395 (128GB) with AMD Software: Adrenalin Edition™ 25.8.1 WHQL can not only run Meta’s Llama 4 Scout but do it at a context length of 256,000 (Flash Attention ON, KV Cache Q8). This allows a large number of tokens to be held in-context and enables powerful agentic workflows.
Take for example this demo of an SEC EDGAR MCP where the LLM is pulling AMD’s most recent quarterly filling and summarizing it. Between the back and forth and downloading the data from SEC – the action required 19,642 tokens to be held in-context – something that would simply fail on the default context window limit of 4096.
Another example, this time querying the ARXIV database, showcases the model querying the most recent research paper published on cosmology and then when prompted – summarizing the paper in just a few lines. This action took a total of 21, 445 tokens from inception to output.
Note that the demos above are single-action demos for a specific use case and some workflows might require a huge number of tokens held in-context or multiple actions running sequentially – each calling multiple tools. Because of this reason, MCP is a huge drain on context resources and agentic workflows will require large amounts of context lengths to be useful.

So the average user that requires occasional MCP capability will want to set context length to 32,000 (which is the typical maximum of some LLMs) and use a light-weight model but power users will need sophisticated LLMs that support large context lengths as well as the hardware to contain that much context in-memory (such as the AMD Ryzen™ AI Max+ 395 128GB).

The universe of MCP is constantly expanding and over the next year, AI Agents will become more prevalent in local inferencing. Model creators like Meta, Google and Mistral are also taking tool calling into account when doing their training runs so as time passes, models will become more adept at understanding and calling tools – paving the way for LLM-as-personal-assistant in a local instance.
Legal Disclaimer: Giving a Large Language Model tool access to your system may result in the AI acting in unpredictable ways with unpredictable outcomes. Only install implementations from trusted sources, and failure to exercise appropriate caution may result in damages (foreseen or unforeseen). Use such implementations at your own risk, AMD makes no representations/warranties in this context.
The AMD Ryzen™ AI Max+ (128GB) is available from the following partners:

ASUS ROG Flow Z13

HP ZBook Ultra G1a

Corsair AI Workstation 300

HP Z2 Mini G1a

Framework Desktop

Endnotes
GD-97 - Links to third party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites and no endorsement is implied.


Related Blogs
-
Larger-Than-Ever Single-GPU Quantum Simulation: How AMD and Qibo Are Pushing the Boundaries of Quantum Simulation and Control
In this blog, we highlight our ongoing synergy with Qibo, an end-to-end open-source framework for quantum computing, and In this blog post, we present the largest single‑GPU quantum simulation achieved on AMD hardware to date, running on Qibo—an exact 35‑qubit state‑vector simulation on AMD Instinct™ MI355X GPUs, setting a new milestone for quantum workflows.
May 12, 2026
-
Reimagining AI-Native Education Through Multi-Agent Interactive Classroom on AMD ROCm
Reimagining AI-Native education to AMD ROCm: multi-agent classrooms across Instinct, Radeon, Ryzen AI with OpenMAIC
May 11, 2026
-
Accelerating ComfyUI Workflows on AMD Instinct™ MI355X GPUs with ROCm — ROCm Blogs
We show that the MI355X delivers better performance than the B200 for ComfyUI after enabling PyTorch attention for gfx950.
May 10, 2026
-
Agentic AI Changes the CPU/GPU Equation
Dan McNamara of AMD describes the changes enterprise IT leaders face as agentic AI rewrites the CPU-to-GPU ratio in the AI infrastructure equation.
May 07, 2026
-
AMD Instinct MI350P PCIe GPUs: Run Enterprise AI on Your Existing Infrastructure
Learn how the AMD Instinct™ MI350P PCIe® card delivers exceptional performance, leadership costs, and simplified deployment for enterprises.
May 07, 2026
-
Next Gen Networking Transport for Large Scale AI Training
AMD, OpenAI and partners advance AI networking with MRC—boosting scalability, resilience and real-world performance for large AI clusters.
May 06, 2026
-
AMD AI DevDay San Fransico Recap
AMD AI DevDay 2026 in San Francisco featured keynotes, workshops, and demos, highlighting AMD’s push for an open, full-stack AI ecosystem.
May 06, 2026
-
AMD and OpenAI Advance AI Networking at Scale with MRC
AMD, OpenAI and partners advance AI networking with MRC—boosting scalability, resilience and real-world performance for large AI clusters.
May 06, 2026







