10x Model Fine-Tuning Using Synthetic Data with Unsloth on AMD GPUs
Oct 15, 2025

Please consider leaving a ⭐️ on the Unsloth Repo if you enjoy working on OSS LLMs. We will also use Synthetic-Data-Kit repo for this example
Please find all associated code with this blog here
When was the last time you fine-tuned a 70B model with batch_size 128 on a single GPU?
Don’t worry, we change that by showing you how to add reasoning behaviour to a model using SFT on the 192GB HBM memory of AMD Instinct™ MI300X GPU to fine-tune Llama-3.3-70B with LoRA(16 bit) using Unsloth and some magic it comes with out of box.
What Will You Learn?
In this blog, we will teach you how to generate synthetic data and then fine-tune the same model on these outputs to help it answer and generate logical puzzles.
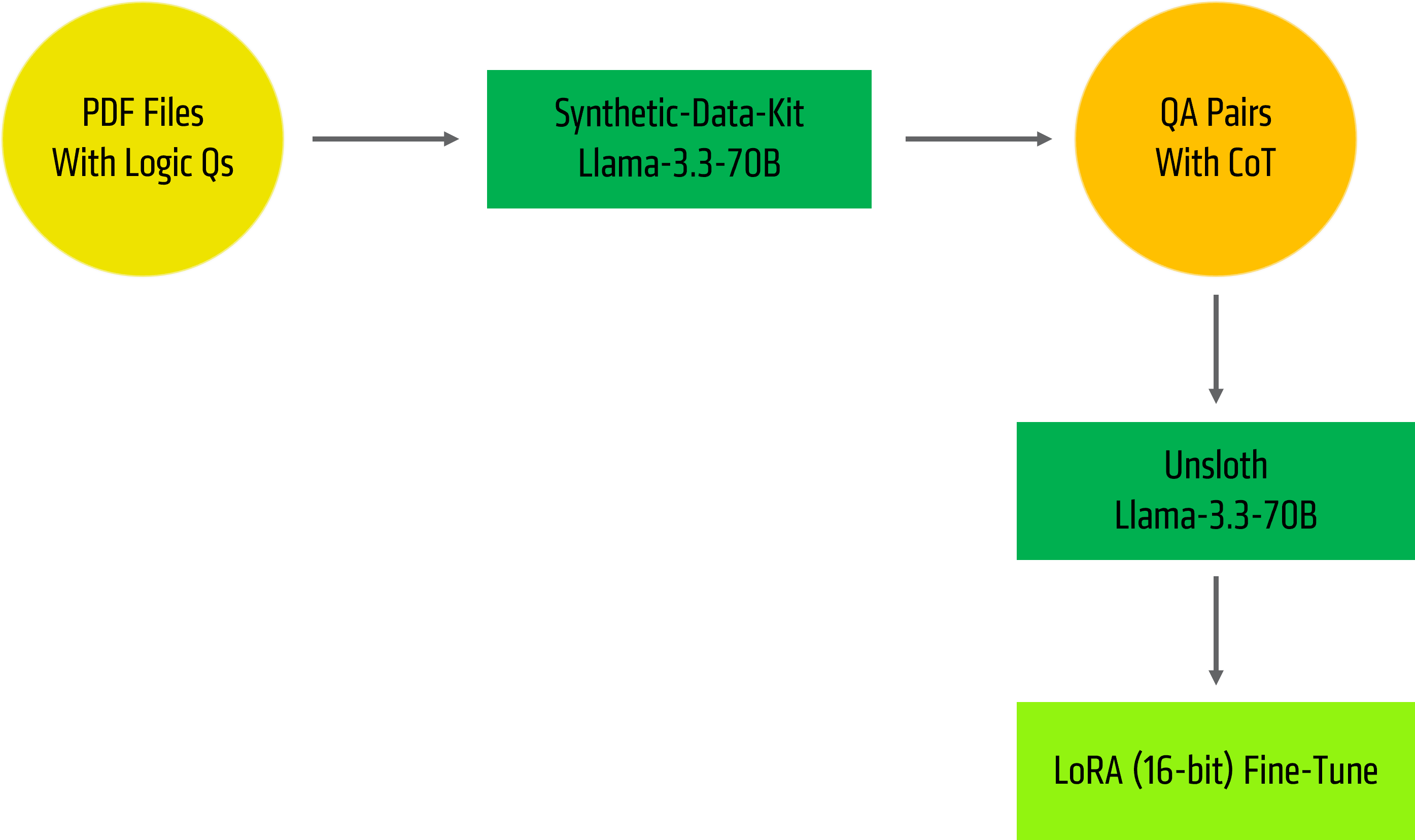
Figure 1: Pipeline Overview
We will use Llama-3.3-70B-Instruct and Unsloth for these experiments.
Thanks to the 192GB VRAM we can set the following configurations:
- Seq Length 1024
- Batch_Size 128
- LoRA(16 bit) rank 64
Note: There are many tricks that are auto-activated from Unsloth: Automatic Gradient offloading for a small overhead and many more kernel optimisations that make this possible!
The below is for QLoRA but thanks to MI300X, we are able to run LoRA (16-bit)
Llama 3.3 (70B) finetuning fits in 41GB
Llama 3.3 (70B) max. context length
| GPU VRAM | Unsloth (+ Apple CCE) |
Unsloth (Old) |
Hugging Face+FA2 |
| 48 GB | 12,106 | 7,385 | OOM |
| 80 GB | 89,389 | 48,447 | 6,916 |
Unsloth tested Llama 3.3 (70B) Instruct on a 80GB A100 and did 4bit QLoRA on all linear layers (Q, K, V, O, gate, up and down) with rank = 32 with a batch size of 1. They padded all sequences to a certain maximum sequence length to mimic long context finetuning workloads. Source: Unsloth

Figure 2: Long Context Examples from Unsloth
The Task
These following steps will take you through generating logic puzzles, and also then teaching the same model how to generate these questions along with answers with reasoning:
- Download PDFs containing Logical puzzles etc
- Create Fine-Tuning Dataset with reasoning using Llama 3.3-70B
- Prepare the dataset and create a LoRA(16 bit) fine-tuning pipeline
- Run experiments
Note: We are showing a SOTA example here but this is rather a getting started guide on a small subset of 30-50 conversation examples to get you started with experimentations and inspire ideas.
Data Generation
We will use Synthetic-Data-Kit for this part. It lets you use a config or a CLI with either local LLM or a hosted endpoint to create reasoning traces, FT dataset and convert files (PDF/PPT/DOCX) to these using a simple CLI.
The real magic is we use an LLM to convert your data into QA pairs and then use an LLM as a judge to curate it.
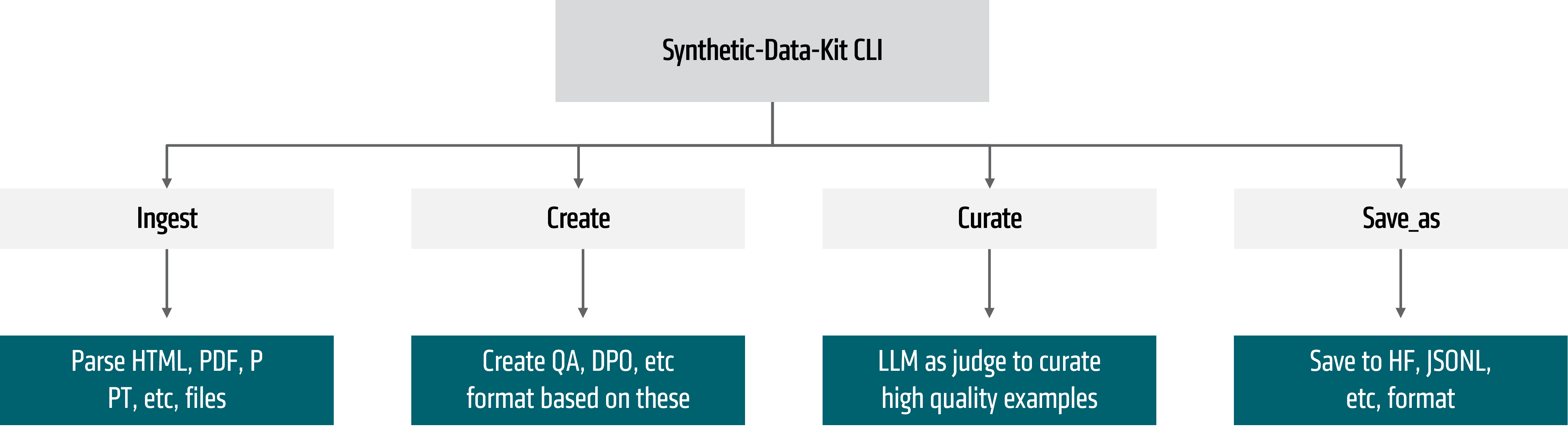
Figure 3: Synthetic-Data-Kit Pipeline
In our case, thanks to the large vRAM we can run 70B on a single GPU via vLLM and generate datasets using this endpoint.
vllm serve Unsloth/Llama-3.3-70B-Instruct --port 8001 --max-model-len 48000 --gpu-memory-utilization 0.85
Now we need to create a config.yaml that Synthetic-Data-Kit will use. You can find the entire config in the repo linked at top, otherwise Synthetic-Data-Kit will pick the defaults.
All we care about here is the system prompt which will inform Llama to create the QA pairs.
Note: This config might have copy paste errors, it’s best to refer to the Github repo here
# Logical Reasoning Training Configuration for Synthetic Data Kit
# Global paths configuration
paths:
input: "data/input" # Source PDFs and text files
output:
parsed: "data/parsed" # Extracted text files (.txt)
generated: "data/generated" # Generated QA pairs and CoT (.json)
curated: "data/curated" # Quality-filtered data (.json)
final: "data/final" # Training-ready format (.json)
# LLM Provider configuration
llm:
provider: "vllm"
# vLLM server configuration
vllm:
api_base: "http://localhost:8001/v1"
port: 8001
model: "unsloth/Llama-3.3-70B-Instruct"
max_retries: 3
retry_delay: 1.0
sleep_time: 0.1 # Small delay between batches to avoid rate limits
# Specialized prompts for logical reasoning domains
prompts:
# Summary generation for logical reasoning content
summary: |
Summarize this logical reasoning content in 3-5 sentences, focusing on:
1. The type of logical problems covered
2. Key solving strategies mentioned
3. Important concepts and principles
# QA pair generation optimized for logical reasoning
qa_generation: |
Create {num_pairs} high-quality logical reasoning question-answer pairs from this educational content.
Focus on problems that require:
1. Step-by-step logical deduction
2. Testing assumptions and eliminating contradictions
3. Clear reasoning explanations
4. Progressive difficulty (basic → intermediate → advanced)
Domain Guidelines:
- Knights & Knaves: Focus on truth-teller/liar logic, contradiction testing
- Seating Arrangements: Focus on constraint satisfaction, systematic placement
- Blood Relations: Focus on family tree deduction, relationship mapping
Return ONLY valid JSON in this exact format:
[
{{
"question": "Clear, specific logical reasoning question requiring step-by-step thinking?",
"answer": "Complete step-by-step solution showing the reasoning process, testing assumptions, and reaching the final answer.",
"difficulty": "basic",
"domain": "knights_knaves"
}},
{{
"question": "Another logical reasoning question with different complexity?",
"answer": "Detailed answer showing each deduction step, how contradictions are resolved, and verification of the solution.",
"difficulty": "intermediate",
"domain": "seating"
}}
]
Text:
{text}
# Chain of Thought generation for complex logical reasoning
cot_generation: |
Create {num_pairs} complex logical reasoning problems with detailed chain-of-thought solutions from this content.
Each problem should:
1. Require multiple reasoning steps and careful analysis
2. Show how to test different possibilities systematically
3. Demonstrate how to identify and resolve contradictions
4. Include verification that the solution satisfies all constraints
5. Explain the reasoning behind each step
Chain-of-Thought Structure:
- Identify what is known and what needs to be found
- Break down the problem into manageable steps
- Test different cases or assumptions
- Show how contradictions eliminate invalid options
- Verify the final answer against all given conditions
Return ONLY valid JSON:
[
{{
"question": "Complex multi-step logical reasoning problem that requires systematic analysis?",
"reasoning": "Step 1: First, let me identify what we know from the problem statement...\\nStep 2: Now I need to consider the possible cases. If we assume X is true, then...\\nStep 3: This assumption leads to a contradiction because...\\nStep 4: So X must be false. Let me try the opposite assumption...\\nStep 5: Testing this new assumption: if Y is true, then...\\nStep 6: This works! Let me verify by checking all constraints...\\nStep 7: Checking constraint 1: ✓... Checking constraint 2: ✓...",
"answer": "Final answer with summary: The solution is [answer] because [key insight that makes this the only valid solution].",
"domain": "knights_knaves"
}}
]
Text:
{text}
We can now use this endpoint to confirm CLI connects with vLLM:
Note: This config might have copy paste errors, it’s best to refer to the Github repo here
synthetic-data-kit -c config.yaml system-check
Next, we can grab some open licensed examples for our purpose:
#create the repositories where we will use the PDF and save the examples to
mkdir -p logical_reasoning/{sources,data/{input,parsed,generated,curated,final}}
cd logical_reasoning
wget -P sources/ -q --show-progress "https://www.csus.edu/indiv/d/dowdenb/4/logical-reasoning-archives/logical-reasoning-2017-12-02.pdf" "https://people.cs.umass.edu/~pthomas/solutions/Liar_Truth.pdf"
cp sources/* data/input/
Now, Synthetic-Data-Kit can take an entire folder filled with files and parse them to text with “ingest command”:
synthetic-data-kit ingest ./data/input/ --verbose
After ingestion, we want to either create QA pairs or CoT QA Pairs for that:
We can use the “create command with –type mentioned as QA or CoT”:
synthetic-data-kit -c ../config.yaml create ./data/parsed/ --type qa --num-pairs 15 --verbose
# OR
synthetic-data-kit -c ../config.yaml create ./data/parsed/ --type cot --num-pairs 15 --verbose
Note: In the above, you can ask for the # of QA pairs you want from SDKit. If you don’t specify anything, SDKit will convert all documents into max QA Pairs.
After that, we can use LLM as a judge to curate, here we set the threshold rating at 7.
synthetic-data-kit -c ../config.yaml curate ./data/generated/ --threshold 7.0 --verbose
Finally, we save the output:
synthetic-data-kit save-as ./data/curated/ --format ft --verbose
Data Prep
Now that we have the QA Pairs ready, we can prepare these to a format Unsloth expects.
See the conversion script here, but essentially we wrap our ‘messages’ into ‘conversations’.
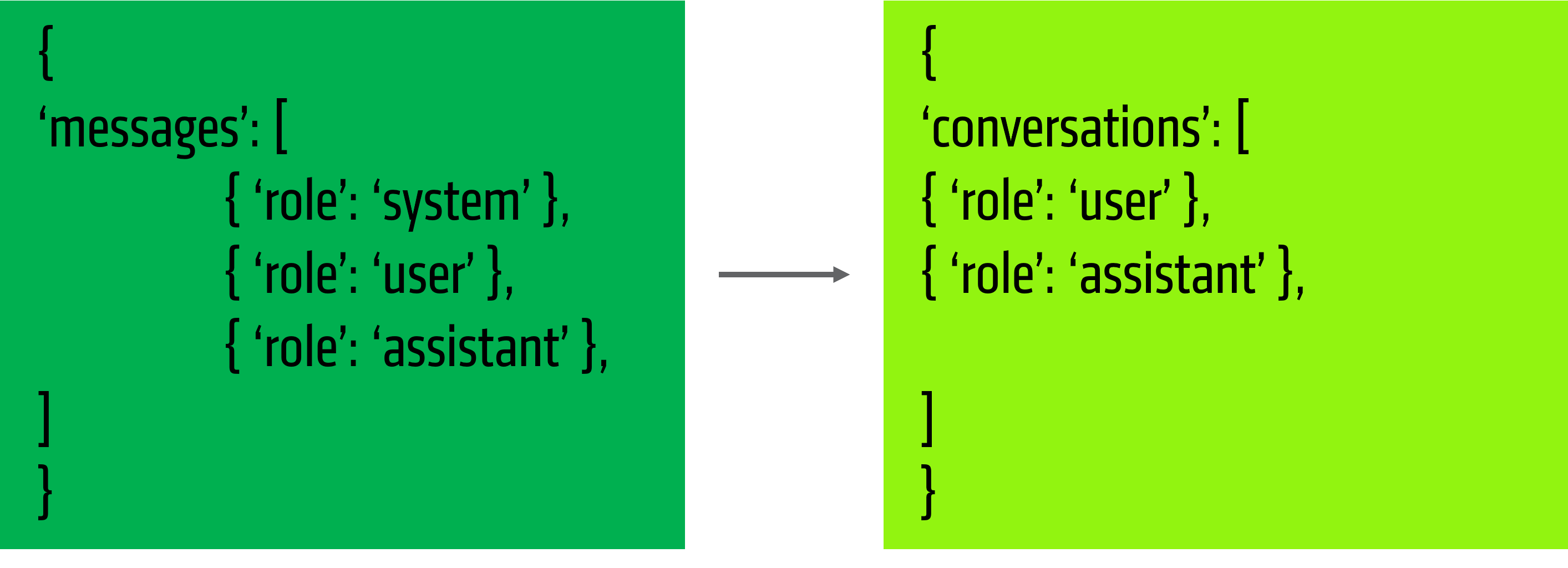
Figure 4: Data Conversion Details
Now we have the different files combined into a single JSON file that we can send to Unsloth for teaching our LLM.
Fine-Tuning with Unsloth
Note: We are setting up LoRA(16 bit) in 16 bit here. Entire script is in the repo linked at top.
NOTE: PLEASE REMEMBER TO SWITCH OFF YOUR VLLM SERVER BEFORE PROCEEDING, You will get OOMs!
Once we have our Fine-Tuning dataset ready to go, we move onto the fun-part! Unsloth makes it super intuitive to setup our experiments and thanks to a lot of memory optimisations we can experiment fast with MI300x.
Unsloth makes it super intuitive to experiment and fine-tune LLMs:
First we start with the necessary imports for training.
from unsloth import FastLanguageModel
from unsloth.chat_templates import get_chat_template, standardize_sharegpt, train_on_responses_only
from trl import SFTConfig, SFTTrainer
from transformers import DataCollatorForSeq2Seq, TextStreamer
Next, we setup the model and tokeniser.
We set this for SFTTrainer to work with and pass them to the trainer later.
Here we focus on just training on the QA responses.
Note: you need to keep the dtype explicit for RoCM GPU and we set seq_len to 1024
After that we setup the LoRA (16 bit) hparams to:
- r=64
- lora_alpha=64
- use_gradient_checkpointing=”unsloth”
def train_model_rocm(model, tokenizer, dataset, max_seq_length):
"""Train model with ROCm-optimized settings"""
# Setup trainer with ROCm-friendly settings and proper data handling
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
packing=False,
args=SFTConfig(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=5,
num_train_epochs=1,
learning_rate=1e-4,
logging_steps=1,
optim="adamw_8bit", # Pure torch optimizer
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="logical_reasoning_rocm_outputs",
report_to="none",
bf16=True,
dataloader_pin_memory=False,
remove_unused_columns=True, # Remove unused columns to avoid tensor issues
gradient_checkpointing=True,
dataloader_num_workers=0, # Single worker for ROCm stability
),
)
# Train only on responses
trainer = train_on_responses_only(
trainer,
instruction_part="<|start_header_id|>user<|end_header_id|>\n\n",
response_part="<|start_header_id|>assistant<|end_header_id|>\n\n",
)
print(f"\n🔥 Starting ROCm training on {len(dataset)} examples...")
FastLanguageModel.for_training(model)
trainer_stats = trainer.train()
return trainer_stats
We are all set to call our trainer:
FastLanguageMode.for_training(model)
trainer_stats=trainer.train()
Finally, we are ready to save our model.
def save_model_rocm(model, tokenizer):
"""Save the trained model"""
lora_path = "logical_reasoning_rocm_lora"
model.save_pretrained(lora_path)
tokenizer.save_pretrained(lora_path)
# Save merged model
merged_path = "logical_reasoning_rocm_merged"
model.save_pretrained_merged(merged_path, tokenizer, save_method="merged_16bit")
print(f"✅ Merged model saved to: {merged_path}")
Beyond First Example
Both Synthetic-Data-Kit and Unsloth allow you to experiment really fast on MI300X. Our entire experiment here took<30 minutes to run on 50 examples to generate and fine-tune for 1 epoch.
We recommend trying out more datasets and kicking off example runs with Unsloth. Happy tuning!
Acknowledgements: This blog was a collaboration with Daniel Han, Michael Han, Sanyam Bhutani, Eda Zhou, Guruprasad MP, Hamid Shojanazeri, Mark Saroufim, Anita Katahoire and Emre Guven.
Contributors


Related Blogs
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Closing the GPU Cluster Validation Gap: A Kubernetes-Native Approach with CVF — ROCm Blogs
Learn how to validate AMD GPU clusters end-to-end with CVF: hardware acceptance, mesh bandwidth, RDMA, and RCCL testing in one pipeline.
July 28, 2026
-
AMD GPU Operator v1.5.0: DRA Support, Automated GPU Node Recovery, and Expanded Kubernetes Infrastructure Control — ROCm Blogs
Discover how AMD GPU Operator v1.5.0 improves GPU scheduling, automates node recovery, and expands Kubernetes control.
July 27, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Run Hugging Face Models
Launch Hugging Face models instantly with One-Click notebooks on AMD GPUs.
July 23, 2026







