Harnessing Dify + Local LLMs on AMD Ryzen AI PCs for Private Workflows
Oct 06, 2025
Introduction
The use of large language models (LLMs) is increasingly integrated into our everyday work. With tools like Dify and Lemonade, developers can quickly build and deploy AI applications using an intuitive, node-based interface. Lemonade Server enables efficient execution of LLMs locally on AMD Ryzen™ AI PCs, taking advantage of built-in acceleration for faster performance. Paired with Dify, you can visually orchestrate AI workflows without needing deep machine learning expertise.
In this blog, we’ll show the following example using Dify:
- Ask My Docs: Upload reference materials like FAQs or README files in markdown format, and Dify will automatically index them. The indexed content becomes contextual input for the language model, enabling document-aware responses.
This example highlights how Dify, when paired with Ryzen AI PCs running Lemonade Server, enables powerful local LLM applications. This is a simple example to get started with, but Dify can be extended to support more complex and varied AI applications.
What Is Dify?
Dify is an open-source platform designed to make building AI applications powered by large language models easy. It lets you design workflows visually with nodes (inputs, retrieval, agents, tools) and swap models without rewriting code.
Key features:
- Visual Workflow Builder: Drag-and-drop interface for designing AI pipelines.
- Knowledge Base Integration: Ingest and index documents to provide contextual grounding for LLMs.
- Built-in Connectors & API Access: Easily integrate external tools and services.
- Flexible Deployment: Supports both self-hosted and remote LLM endpoints.
What is Lemonade?
Lemonade is a client-side inference framework for Windows and Linux that simplifies LLM deployment using NPU and GPU acceleration. It supports models like Qwen, Llama, and DeepSeek and includes support for different hardware backends. By running models locally, Lemonade enhances data privacy and security, keeping sensitive information on your device while leveraging hardware acceleration for high performance. Lemonade Server offers a local runtime with an API compatible with OpenAI, making it easy to integrate local LLMs into existing applications.
Dify integrates with Lemonade Server to enable LLM inference, text embedding, and reranking — making it easy to build private, high-performance AI workflows .
Getting Started with Dify
The following instructions are a simplified version of the official guide for enabling Lemonade as a custom model provider in Dify. For full setup details, refer to the documentation here.
Prerequisites:
First, make sure you have Docker Desktop installed — it includes both Docker and Docker Compose, which are required to run Dify.
Next, download and install Lemonade Server, which will serve as your local model provider.
Install Dify
1. Clone the Dify repository:
git clone https://github.com/langgenius/dify.git
2. Navigate to the Docker setup folder
cd dify/docker
3. Copy the environment configuration file
cp .env.example .env
4. Start the services using Docker Compose
docker compose up -d
Launch Dify
Open your preferred browser and navigate to: http://localhost/plugins?category=discover
From there, search for and install Lemonade as a model provider.
Add Models to Lemonade in Dify
- Go to: Settings > Model Providers > Lemonade > Add a Model.
- Fill in the following fields:
Field |
Value / Description |
Model Name |
Name of Model Ex. Qwen2.5-7B-Instruct-Hybrid (To find more models, use Lemonade Server’s Model Manager. Note: Models must be downloaded before adding them to Dify) |
Model Type |
LLM |
Authorization Name |
(Leave Blank) |
API endpoint URL |
http://host.docker.internal:8000 |
Model context size |
Ex. 2048 (Increase if you need a larger context window) |
Agent Thought |
Select "Support" if your model supports reasoning chains. (Look for models labeled “Reasoning” in Lemonade Model Manager.) |
Vision Support |
Select "Support" if your model supports image understanding. (Look for models labeled “Vision” in Lemonade Model Manager.) |
Repeat this process for each model you want to add to Dify.
Note: Ensure that the models added to Dify have been downloaded prior to using them in your workflow. This can be done by click the Lemonade Server icon in your system tray, navigating to "Model Manager" and downloading the desired models.
Example Workflow: Ask My Docs
We created a workflow that allows querying documentation — such as guides and FAQs — in Markdown format. Dify supports a wide range of file types including .txt, .md, .pdf, .html, .xlsx, .docx, .csv, and more.
Here’s how it works:
1. Upload or sync your documents: Add your reference files as a Dify Knowledge source. For this example, we used the Readme.md and FAQ.md from the Lemonade-SDK repository. These documents serve as the context for the LLM.
2. Create Chatbot Workflow: Create the workflow for a chatbot using the built in Chatflow. This will be what we update with our knowledge source and local LLM.
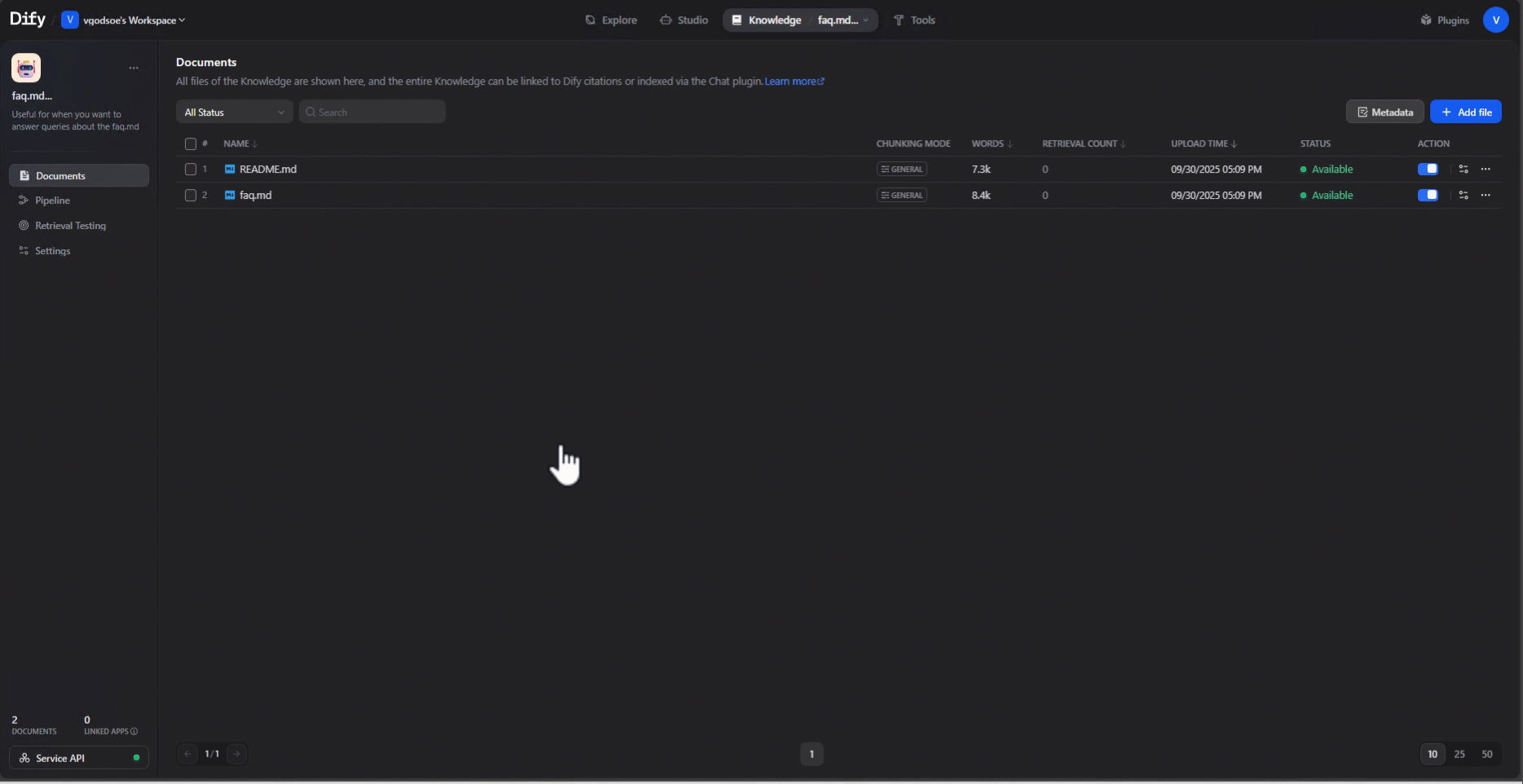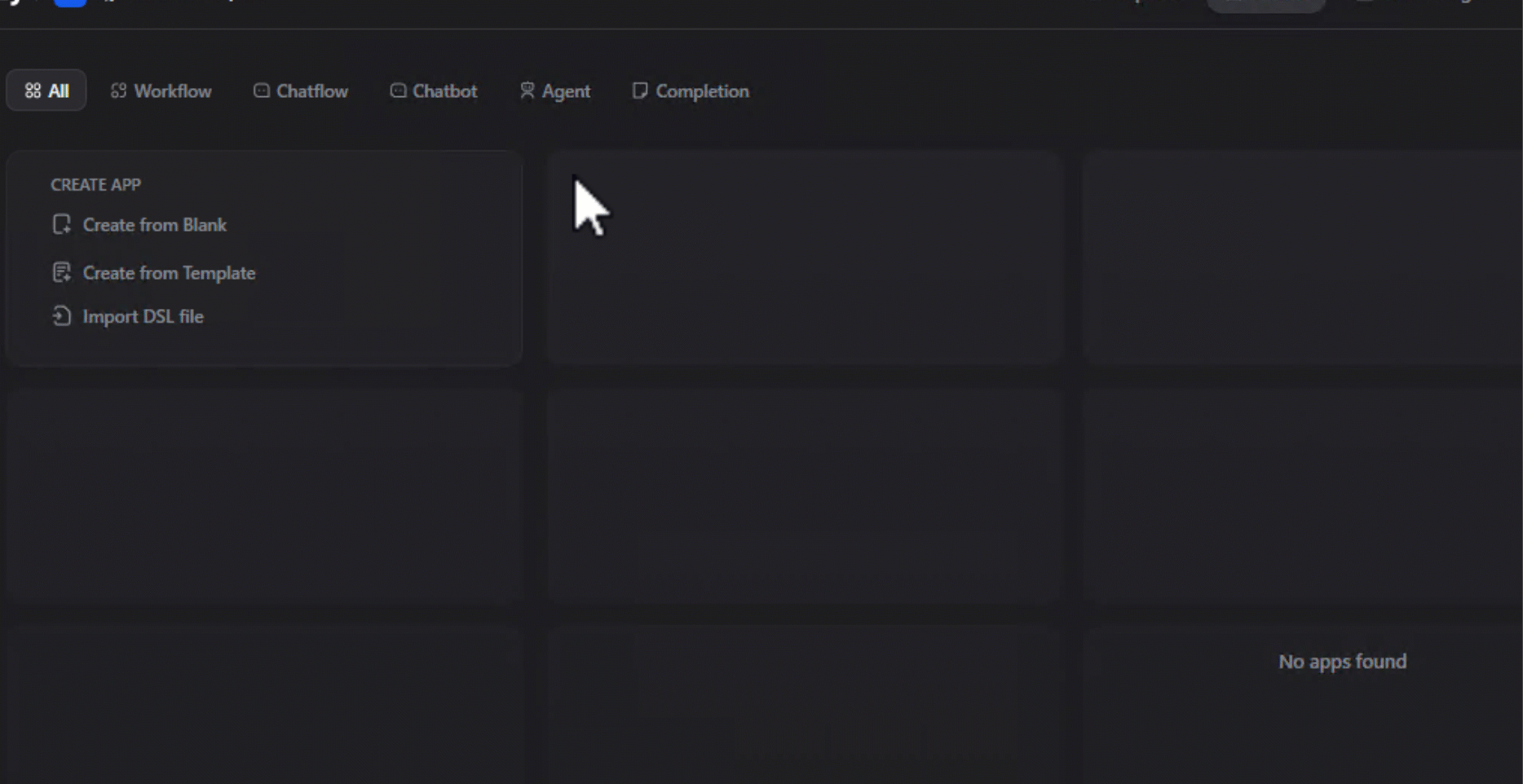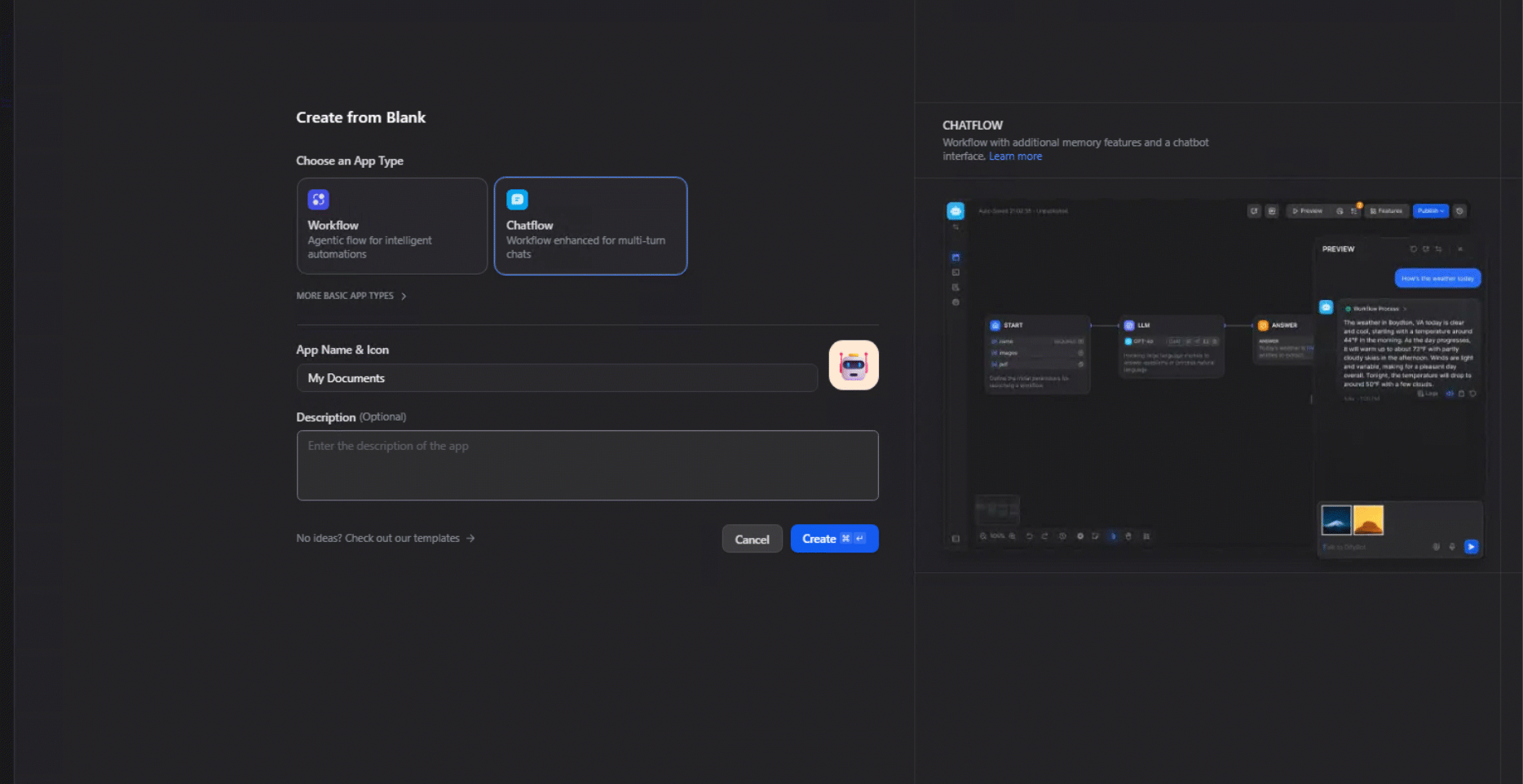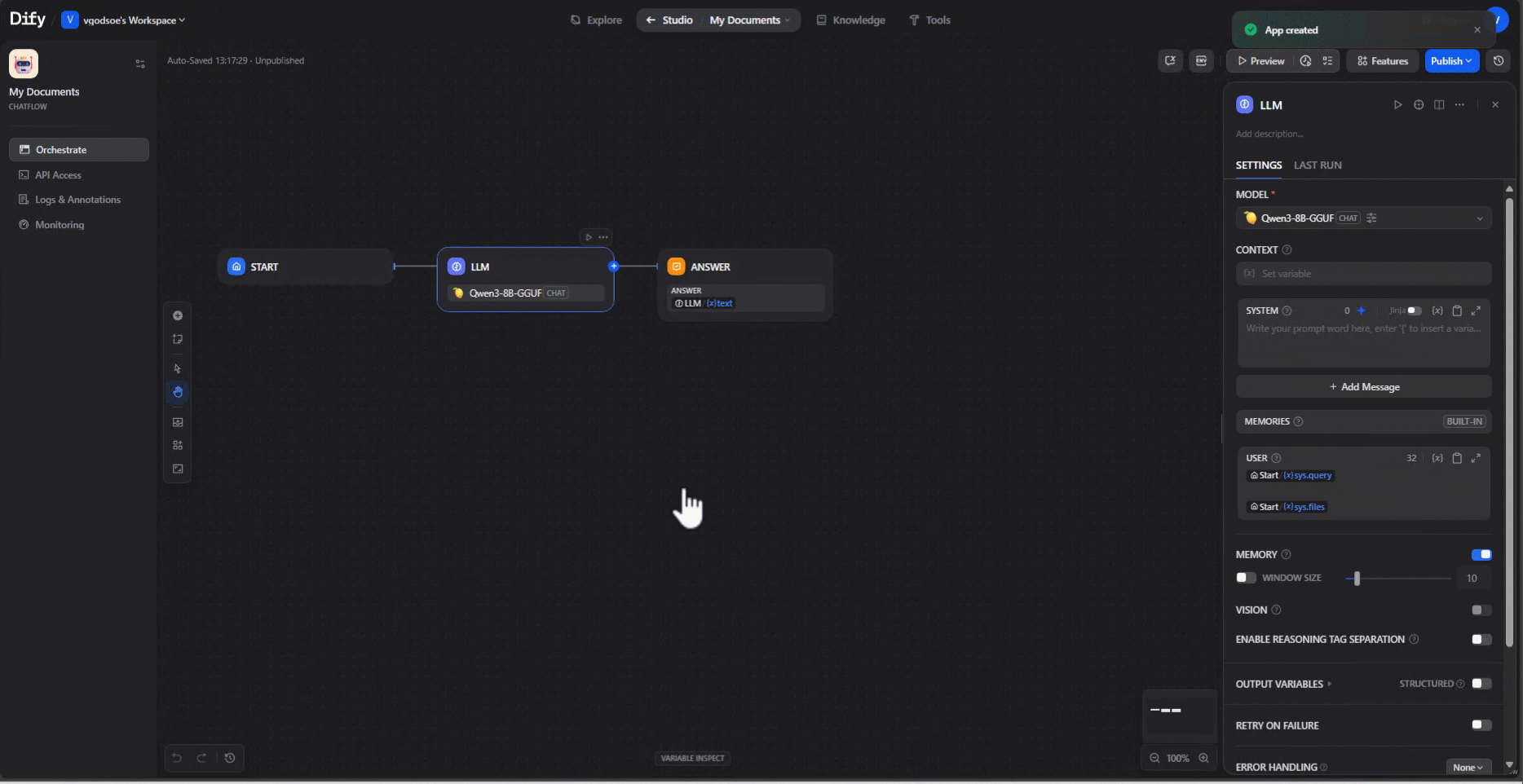
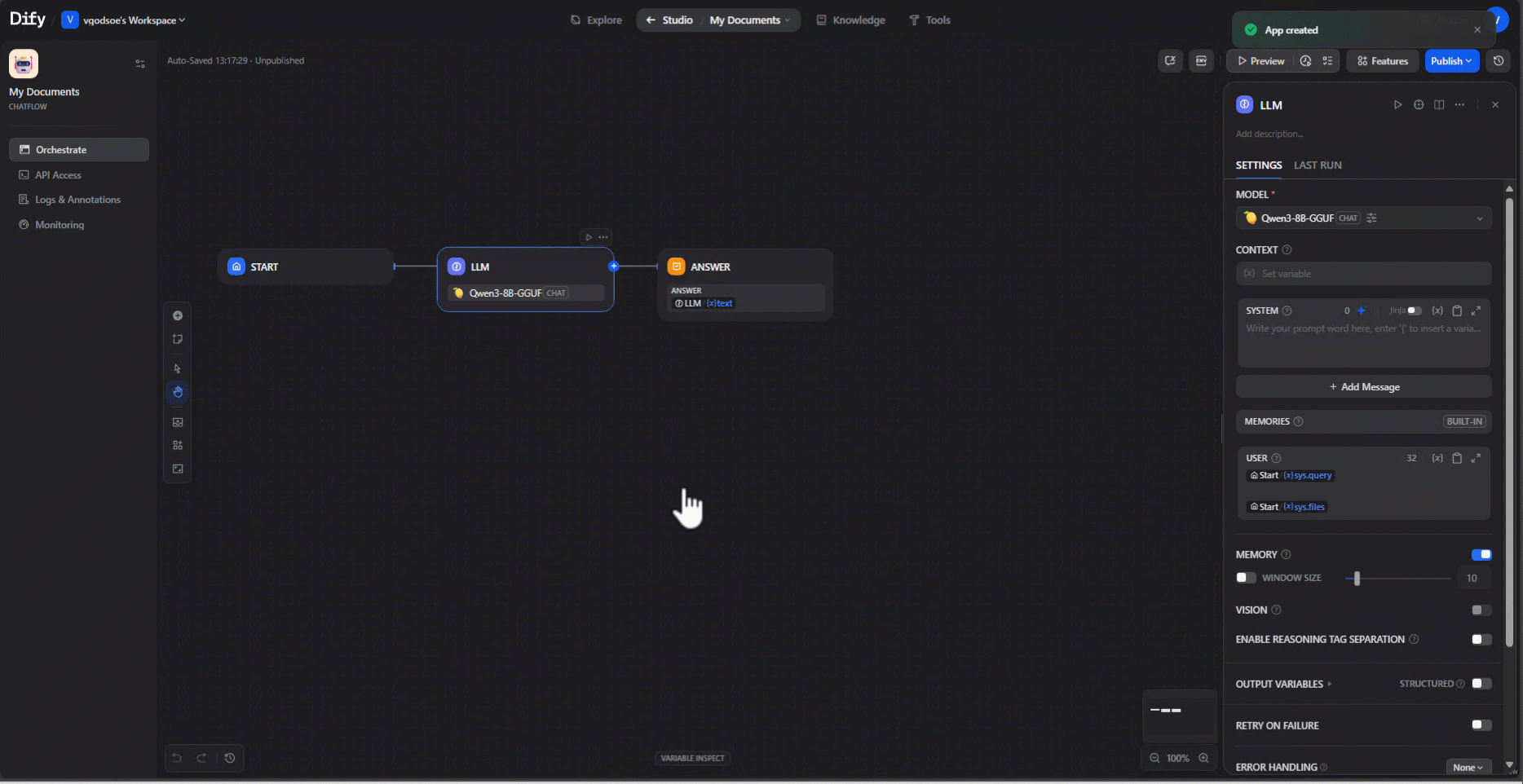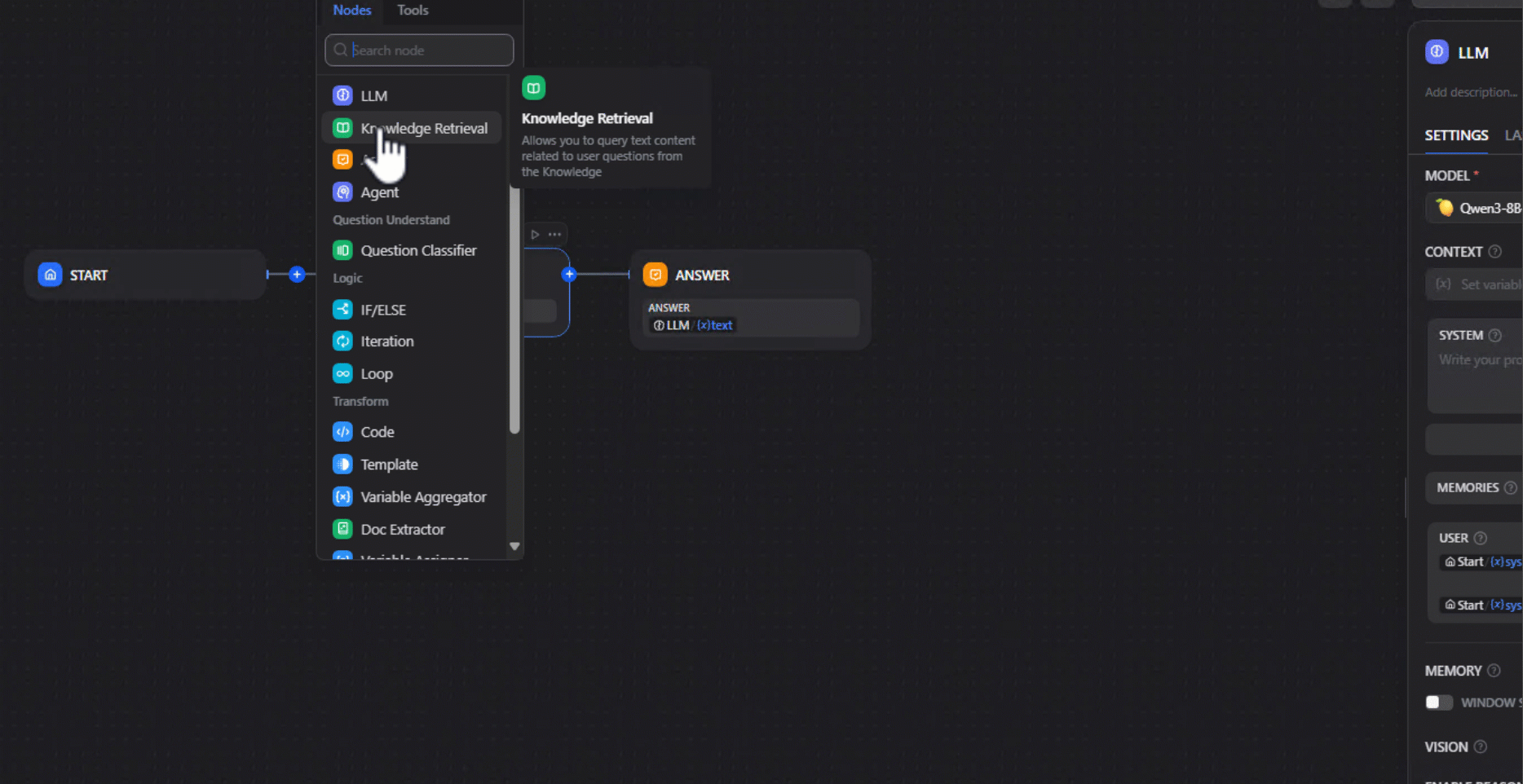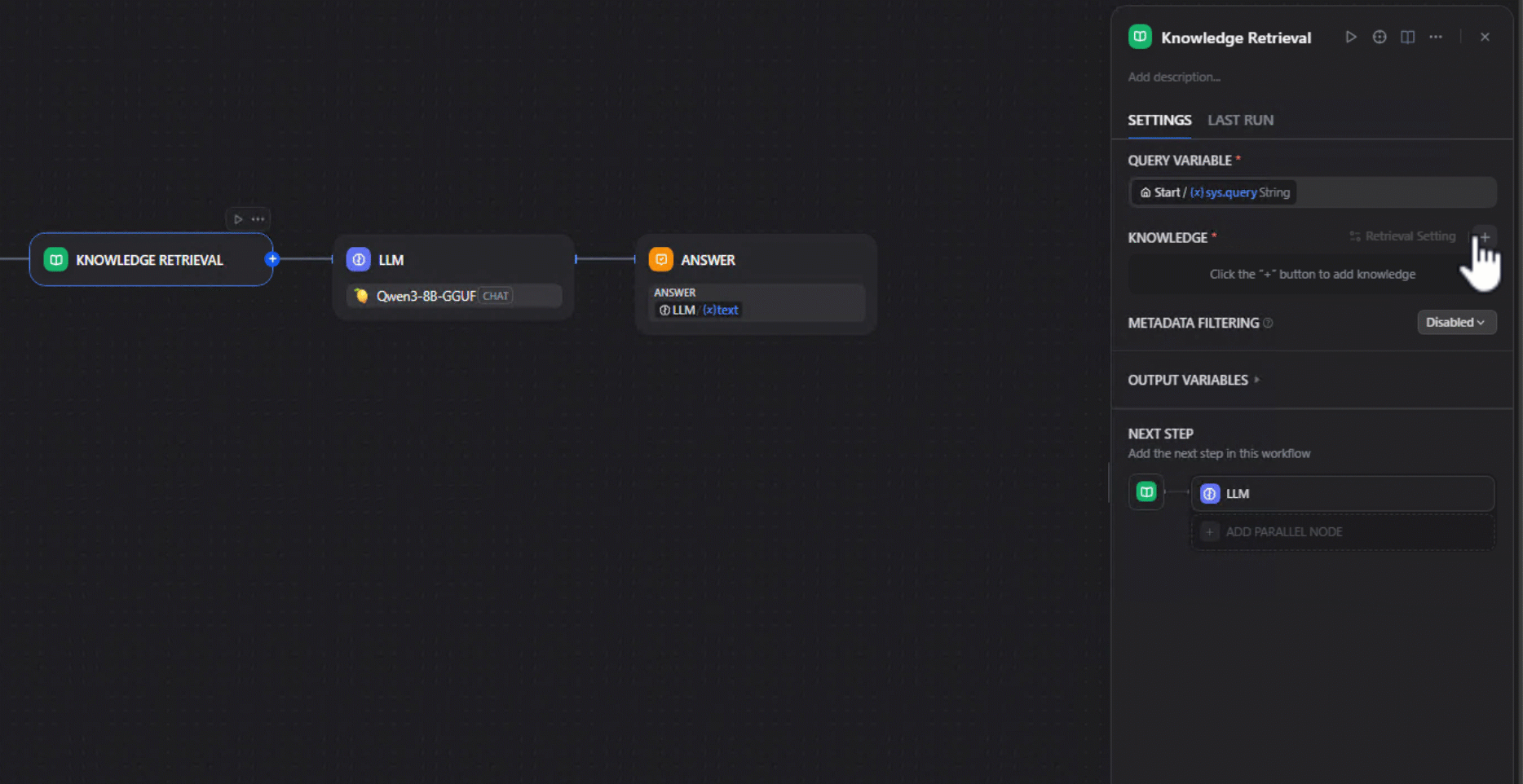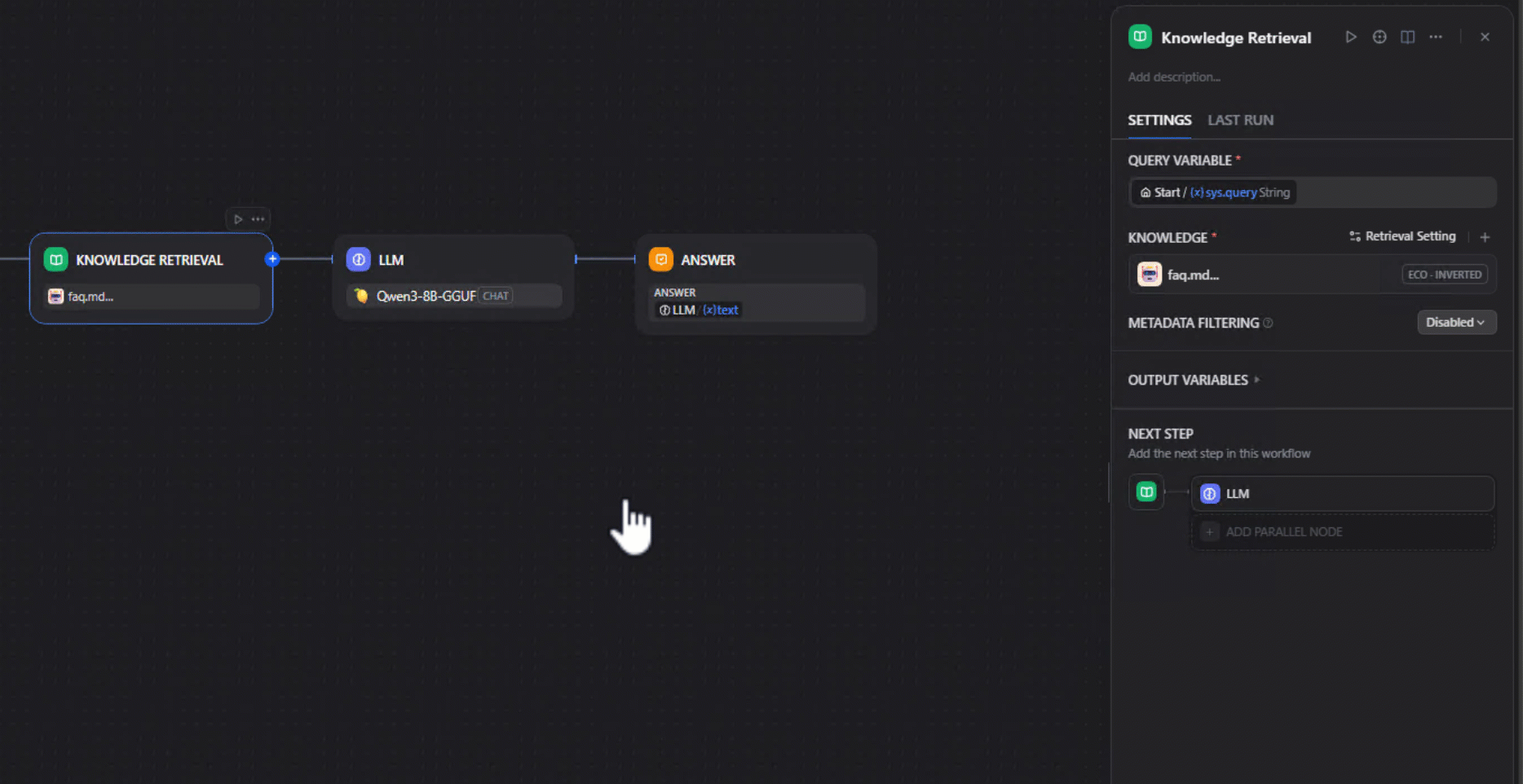
3. Add a Knowledge Retrieval node: In your workflow, insert a Knowledge Retrieval node and link it to the dataset created in step 1.
4. Choose your local model: Choose a locally hosted model — for instance, an ONNX-converted model running on an AMD GPU/NPU. We used Qwen2.5-7B-Instruct-Hybrid, which optimizes performance by using the NPU for the prefill phase and the GPU for token generation. Be sure that the model has been downloaded prior to using it. This can be done by click the Lemonade Server icon in your system tray, navigating to "Model Manager" and downloading the model.
5. Configure the System Prompt: Provide a system prompt to guide the model’s behavior. Below is what was used in this example.
You are a helpful and knowledgeable chatbot. Your primary task is to answer user questions using only the information provided in the {{#context#}}. Do not rely on external knowledge, assumptions, or prior training data. If the context does not contain enough information to answer a question, respond clearly that the answer is not available in the provided context.
Guidelines:
Use clear, concise, and friendly language.
Reference specific parts of the context when answering.
Do not fabricate or infer information beyond what is explicitly stated.
If asked for information not present in the context, say:
“I’m sorry, but I don’t have enough information in the provided context to answer that.”
Example Behavior:
✅ If the context includes a document about “Project Aurora,” and the user asks “What is Project Aurora?”, summarize the relevant section.
❌ If the user asks “What is Project Borealis?” and it’s not in the context, do not guess or answer from prior knowledge.
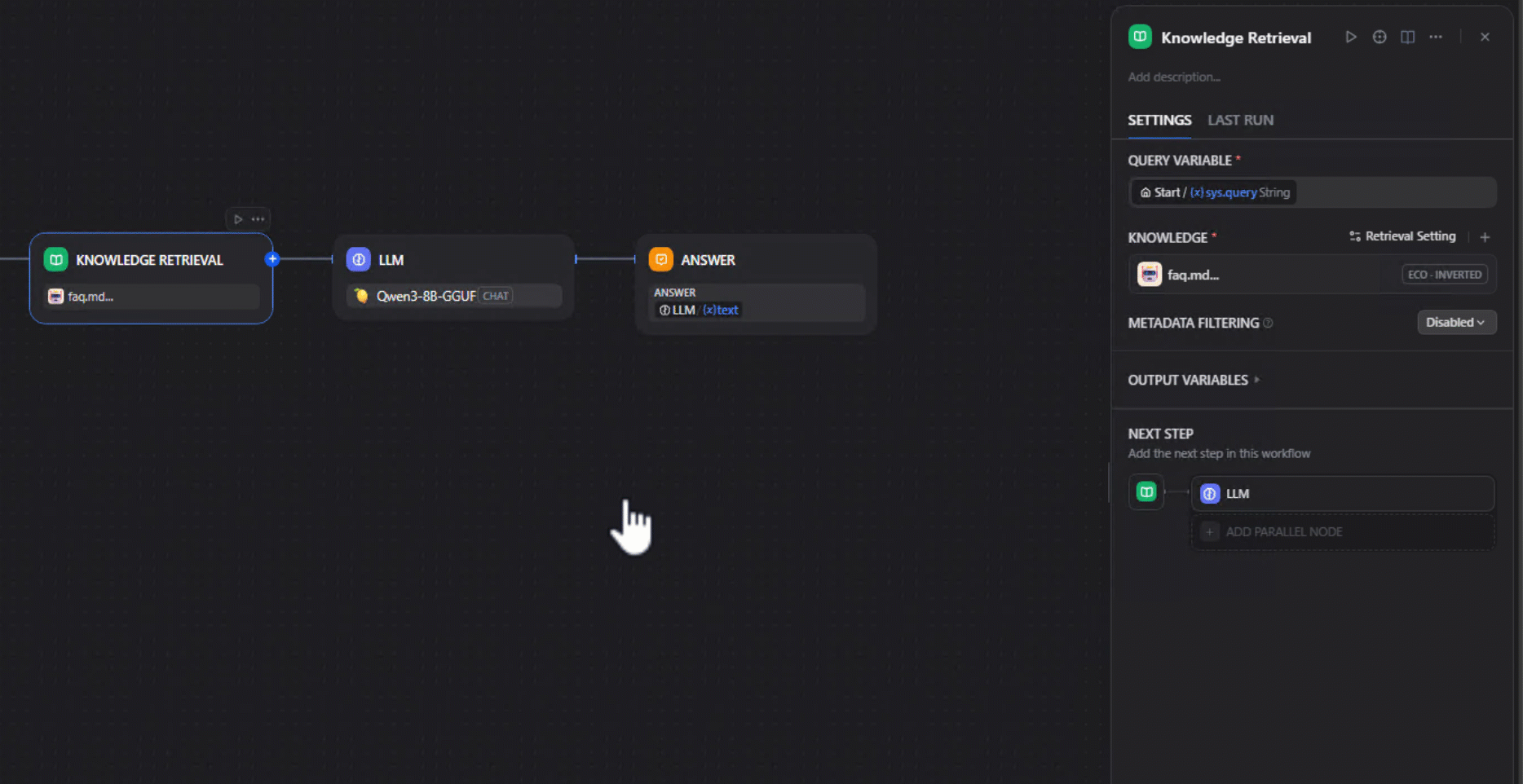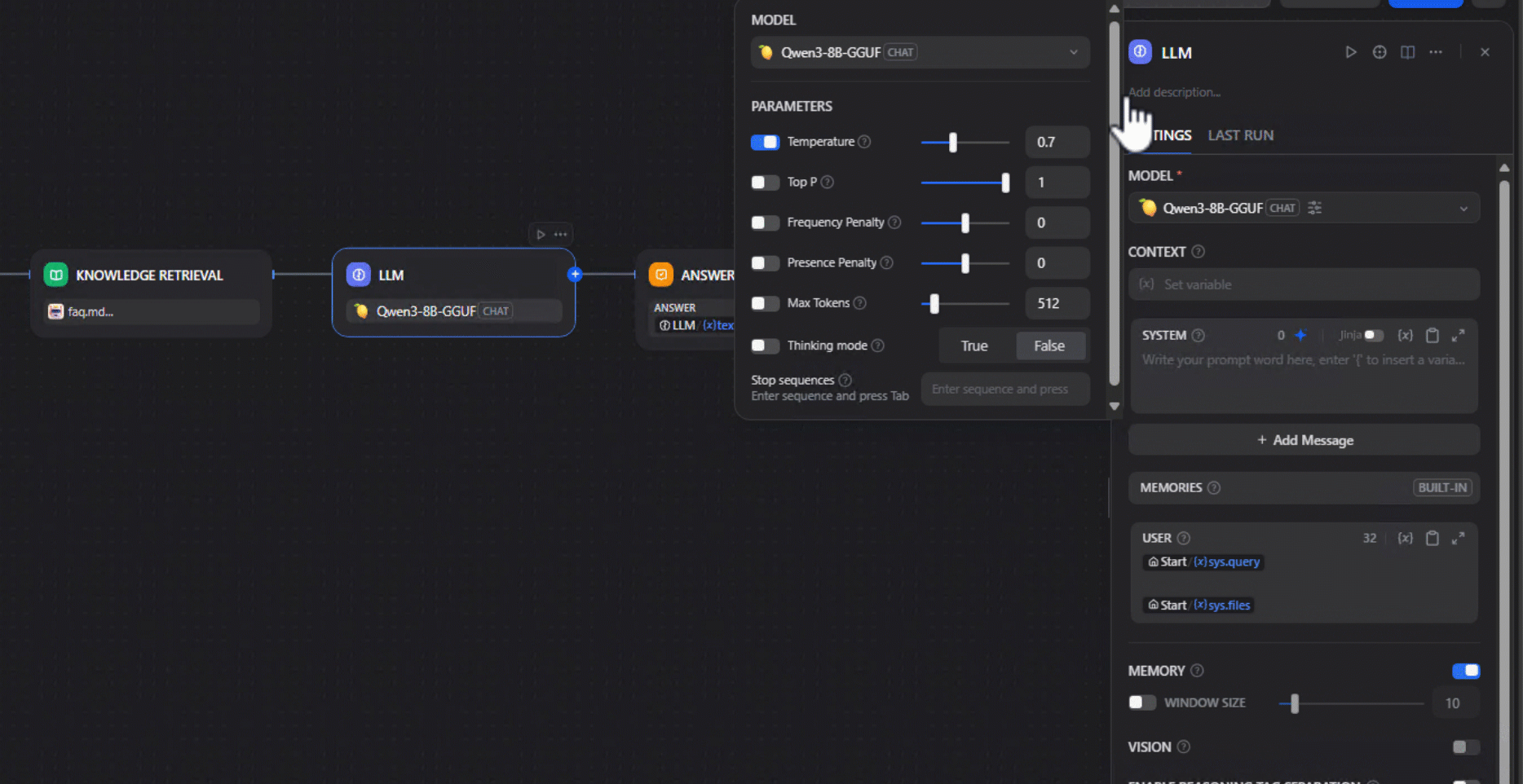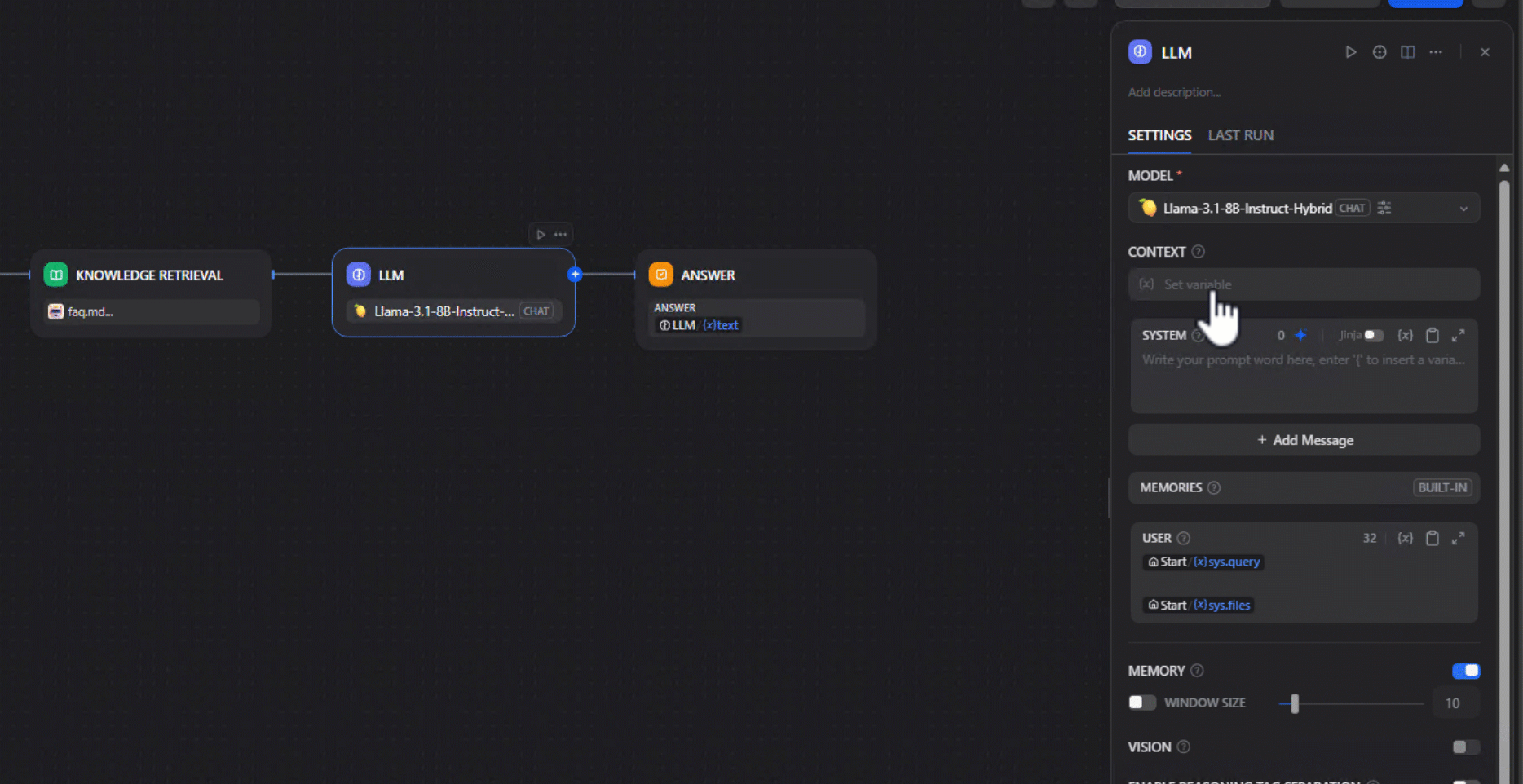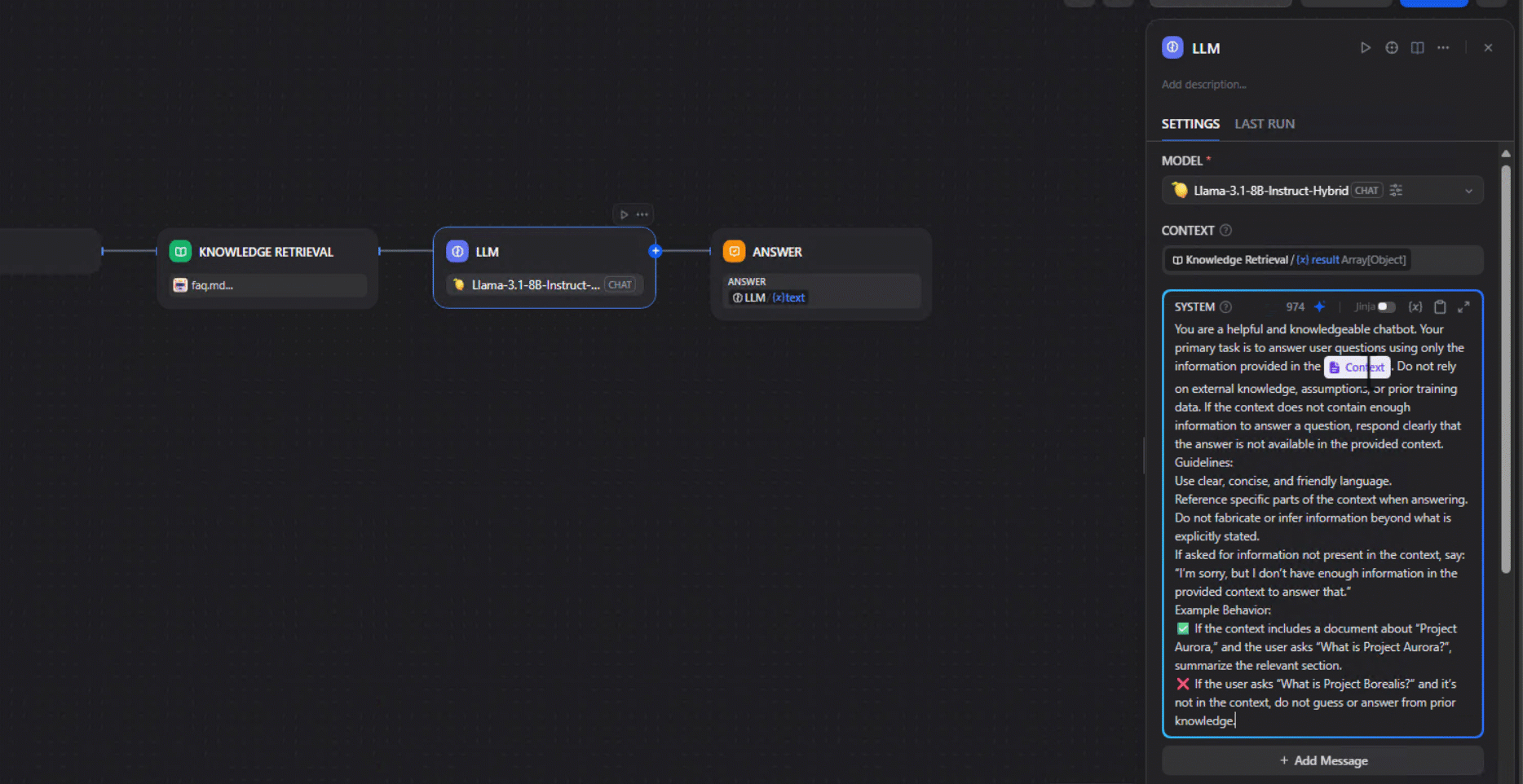
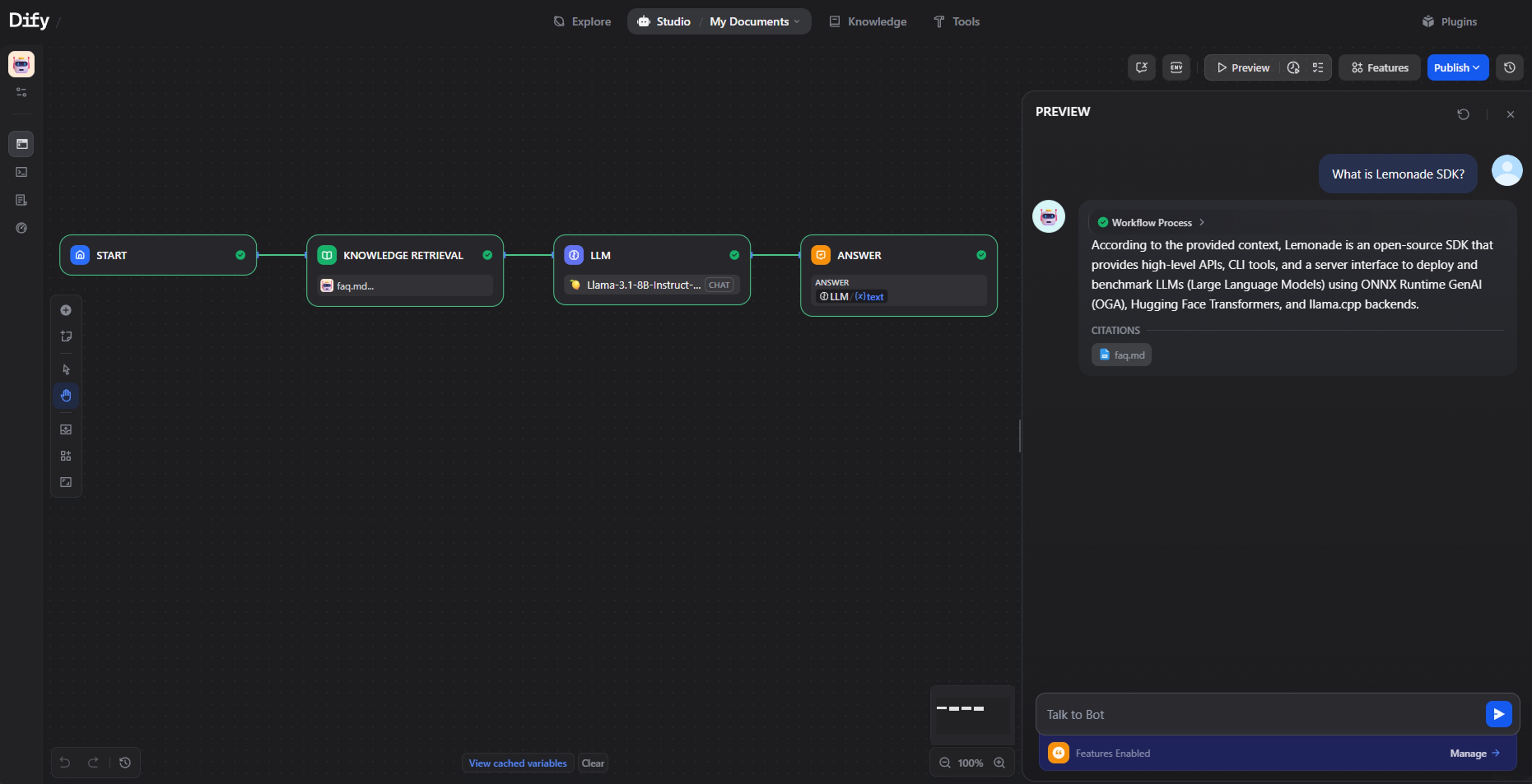
6. Map the Workflow: The nodes should be connected as follows: Input → Retrieval → LLM → Output. This ensures that queries return accurate answers with citations to the source documents.

Because the model runs entirely on your local machine, no data leaves your environment. You can ask questions about Lemonade, and the LLM will respond with answers and cite the specific document used for context.

Putting It All Together
With Dify, you don’t need to be a machine learning expert to build powerful local AI workflows. The process is simple:
- Select your model endpoint: Point to a locally hosted model via Lemonade Server.
- Create datasets: Upload documents, chat logs, or other reference materials.
- Build your flow: Connect Input → Retrieval → LLM → Output using Dify’s visual workflow editor.
- Automate updates: Use the REST API from Dify to keep datasets in sync with live data sources.
Everything runs privately on your AMD-powered PC, ensuring full control over performance and data security.
Closing Thoughts
By combining Dify’s node-based orchestration with the local acceleration of AMD Ryzen AI and Radeon GPUs, you unlock a secure, high-performance path to generative AI inside your organization. Whether you're:
- Searching internal knowledge bases
- Summarizing chat conversations
- Automating customer support
…you can build it visually, run it locally, and keep your data entirely under your control.
Thanks for learning about Dify and Lemonade Server. If you have any questions or feedback, ou can reach out to us at lemonade@amd.com.
Until next time, you can:
- Try Lemonade Server at https://lemonade-server.ai
- Star our GitHub
- Learn more on our YouTube channel
- Try Dify with Lemonade


Related Blogs
-
Agentic AI Workflows Simplified
Rocm.AI simplifies how developers build and serve with ROCm on AMD GPU’s
July 23, 2026
-
AMD Launches Helios™: The Highest Performing Rackscale AI Infrastructure Solution
AMD launches Helios, an open rack-scale AI platform connecting 72 AMD Instinct™ MI455X GPUs for frontier AI inference and training
July 23, 2026
-
Agentic AI: AMD EPYC™ 9005 CPUs Wins Today, EPYC 9006, formerly code-named “Venice”, Takes It to a New Level
AMD EPYC 9006 Series Server CPUs deliver up to 256 cores, faster memory and I/O, and a strong foundation for enterprise AI workloads, helping advance your data center for the agentic era.
July 23, 2026
-
AI Networking Built for Scale
AMD AI networking unifies front-end, scale-up, and scale-out infrastructure to accelerate training, inference, and agentic AI.
July 23, 2026
-
AMD Helios™: Resilient Scale-Up Networking for AI
Discover how AMD Helios™ delivers resilient scale-up networking for production AI with UALoE, AFM, AFOS, and vPods.
July 23, 2026
-
AMD Pensando™ Vulcano 800 AI NIC: Built to Scale-Out and Across
How AMD Pensando™ Vulcano 800 AI NIC addresses scale-out and scale-across connectivity demands for modern AI training and inference deployments.
July 23, 2026
-
AMD AI NIC™ Technology and the Future of AI Networking
Learn five key AI networking lessons from IDC and discover how AMD AI NIC™ technology supports scalable, open AI infrastructure.
July 23, 2026
-
The Agentic Era Runs on a CPU Foundation — and It's Called AMD EPYC™ 9006 Series Server CPUs
Agentic AI needs more than GPUs and AMD EPYC™ 9006 Server CPUs power planning, orchestration, and enterprise workloads at scale efficiently.
July 23, 2026







