AMD Instinct MI355X GPU Sets a New Bar for DeepSeek Inference
Jun 10, 2026

DeepSeek V4 was one of the most demanding open-model inference launches to date, stressing every part of the serving stack: sparse attention, MoE execution, quantization, multi-token prediction, scheduling, graph capture, and distributed inference. In less than a month, AMD Instinct™ MI355X GPU performance improved by more than 100x on the same silicon through systematic kernel and framework engineering (Figure 1). Today, MI355X GPU delivers leading per-GPU throughput and strong cost-per-token economics on DeepSeek models.
Image Zoom
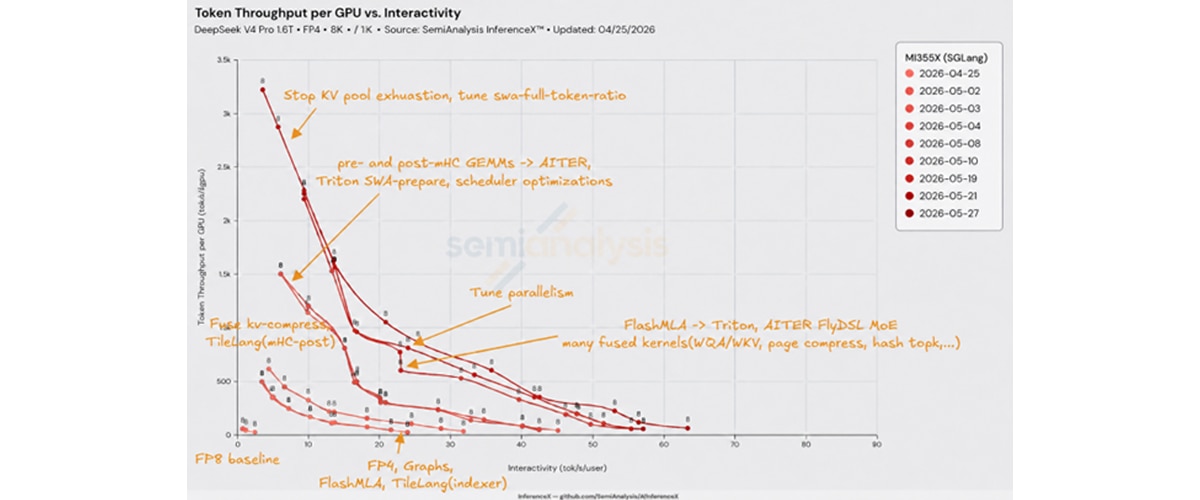
Production Serving Performance
For production inference, the important question is not peak tokens per second alone. It is the throughput a system can deliver while maintaining the interactivity users expect. On DeepSeek V4 Pro, MI355X GPU with ATOM matches or exceeds B200 and B300 with Dynamo vLLM on per-GPU throughput across most of the interactivity range (Figure 2). Results are based on a PR submitted to InferenceX, not yet merged upstream.
Image Zoom
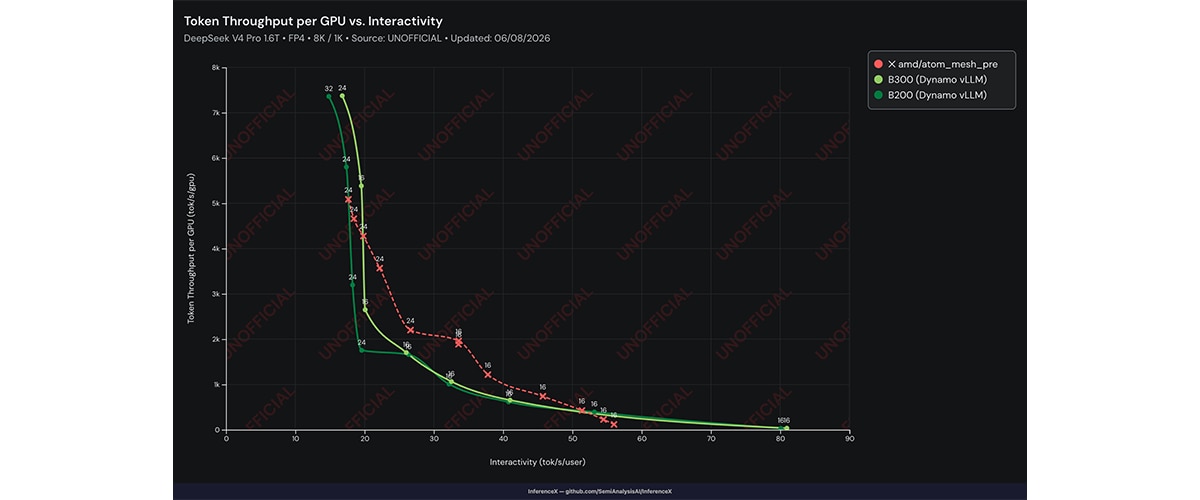
Cost per Token and Fleet Economics
Cost per token is where infrastructure decisions become business decisions. The right evaluation uses a transparent ownership model at the interactivity target each application requires.
Starting with DeepSeek R1 0528 (FP4, 8K/1K, MTP enabled), MI355X GPU (with MoRI + SGLang + MTP) delivers equivalent or lower cost per million output tokens compared to GB300, GB200, B200, and B300 (running Dynamo + TRT + MTP) at production interactivity levels under a hyperscaler ownership cost model (Figure 3).
On DeepSeek V4 Pro (FP4, 8K/1K), MI355X GPU (with ATOM) delivers equivalent or lower cost per million output tokens compared to GB300, GB200, B200, and B300 (running Dynamo + vLLM) at production interactivity levels under a hyperscaler ownership cost model (Figure 4). Results are based on a PR submitted to InferenceX, not yet merged upstream.
Image Zoom
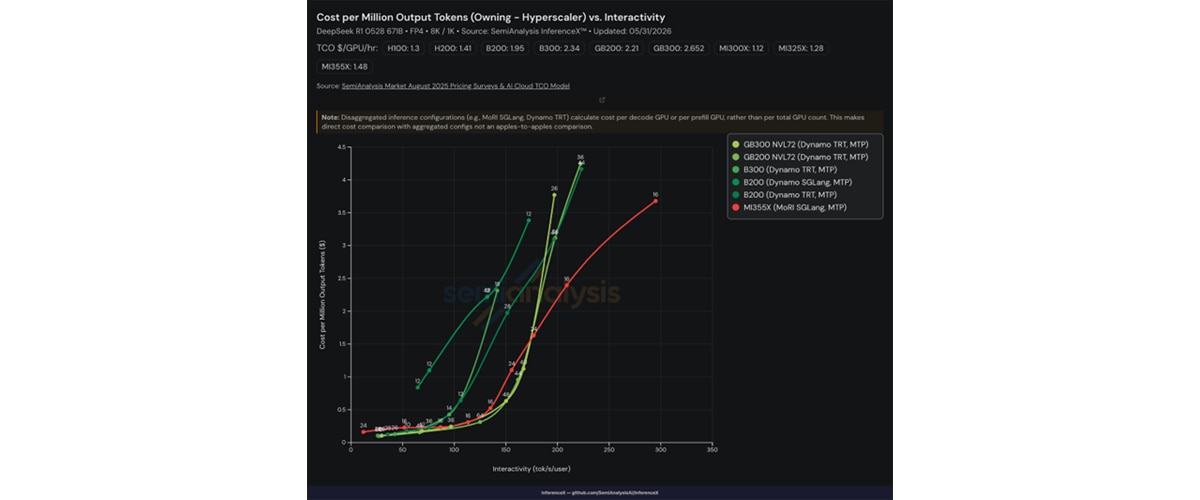
Image Zoom
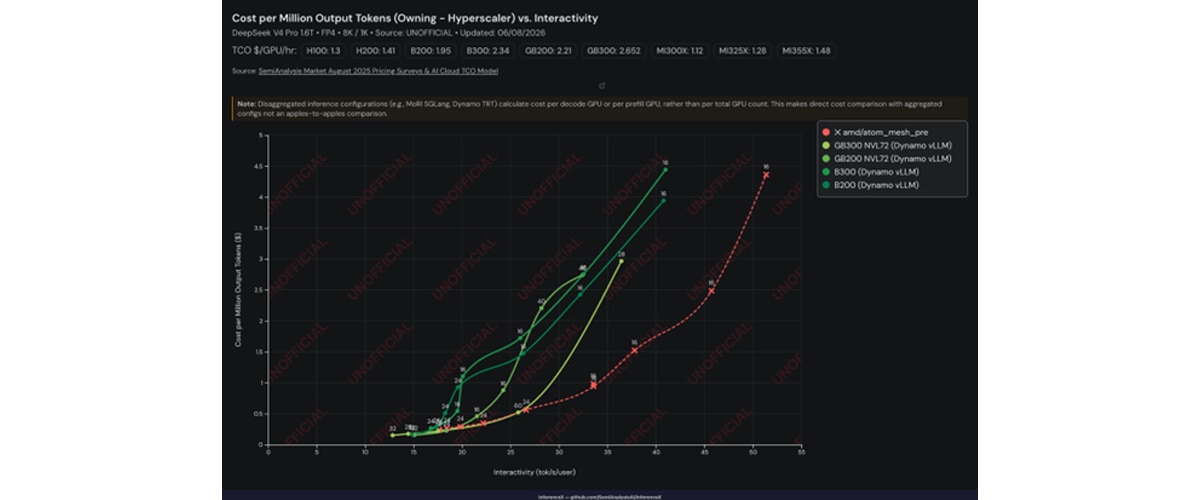
The Path Forward
The MI355X GPU improvement curve showed that the software stack can move fast when kernel engineering, framework integration, and benchmark feedback loops are aligned. vLLM and SGLang are top priorities for AMD Instinct GPUs. ATOM, which is open source, gives us a speed-of-light path for experimentation and optimization before upstreaming improvements to vLLM and SGLang.
Day 0 is one day. Production is every day after that. MI355X GPU wins where it matters.


Related Blogs
-
Train and Run Models on AMD GPUs with Unsloth
Train, fine-tune, run AI models with Unsloth on AMD GPUs across Windows, WSL and Linux, with native inference for leading models.
July 20, 2026
-
Microsoft Azure Expanding AI Infra Choice with AMD Helios™
Microsoft and AMD expand Azure AI infrastructure with AMD Instinct MI455X and Helios, delivering more choice, scale, and efficiency.
July 20, 2026
-
GEAK V3: Agent-Driven, Repository-Level GPU Kernel Optimization across HIP, Triton, and FlyDSL on AMD GPUs — ROCm Blogs
Explore GEAK v3: agent-driven, repository-level GPU kernel optimization across HIP, Triton, and FlyDSL on AMD Instinct™ GPUs.
July 19, 2026
-
Open Standards, Real Solutions: AMD at SIGGRAPH 2026
AMD heads to DigiPro and SIGGRAPH 2026 to discuss open standards, production technology, and the fine art of Gaussian splatting.
July 17, 2026
-
FastFlowLM Joins AMD to Advance AI Inference
The FastFlowLM team has joined AMD, marking another key step in AMD’s strategy to advance AI performance and efficiency across the stack.
July 17, 2026
-
Running Cloud Agents? Your Most Important Upgrade Could be an AMD Zen 5 CPU
As agents begin navigating applications, coordinating tools and completing real work, the local CPU is becoming a critical part of the AI execution pipeline.
July 16, 2026
-
From Vector Search to Agentic RAG: Building an Enterprise Research Analyst with hipVS — ROCm Blogs
Learn how to build an agentic RAG research assistant using hipVS GPU-accelerated vector search on AMD Instinct GPUs, with multi-query decomposition, parallel retrieval, and cited sources synthesis.
July 14, 2026
-
When a Faster Kernel Doesn’t Speed Up Serving: Profiling FP8 KV Cache on AMD Instinct MI308X — ROCm Blogs
Learn how a 34% faster FP8 KV cache kernel delivered 0% E2E speedup, and how profiling attribution exposed the hidden dtype-cast cost on MI308X.
July 14, 2026







