[How-To] Running Optimized Llama2 with Microsoft DirectML on AMD Radeon Graphics
Nov 15, 2023

Prepared byHisham Chowdhury (AMD)and Sonbol Yazdanbakhsh (AMD).
Microsoft and AMD continue to collaborate enabling and accelerating AI workloads across AMD GPUs on Windows platforms. Following up to our earlier improvements made to Stable Diffusion workloads, we are happy to share that Microsoft and AMD engineering teams worked closely to optimize Llama2 to run on AMD GPUs accelerated via the Microsoft DirectML platform API and AMD driver ML metacommands. AMD driver resident ML metacommands utilizes AMD Matrix Processing Cores wavemma intrinsics to accelerate DirectML based ML workloads including Stable Diffusion and Llama2.
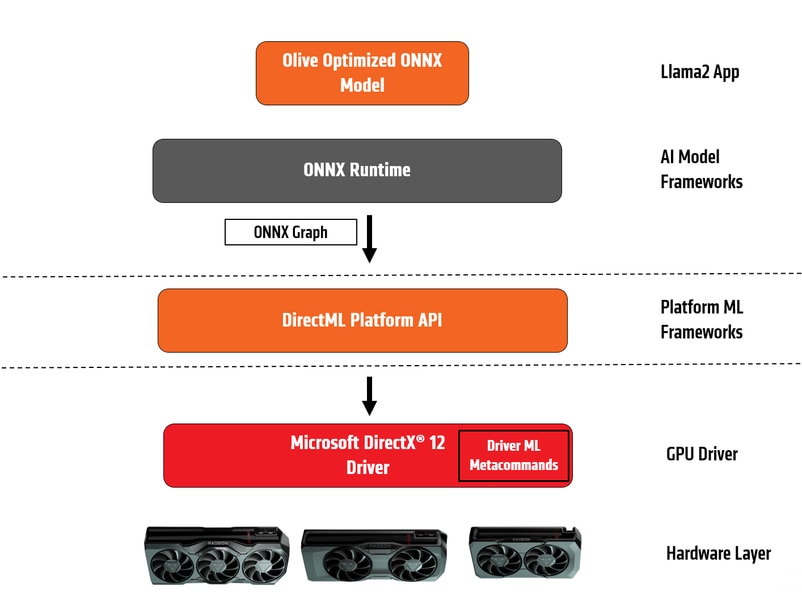
Fig 1:OnnxRuntime-DirectML on AMD GPUs
As we continue to further optimize Llama2, watch out for future updates and improvements via Microsoft Olive and AMD Graphicsdrivers.
Below are brief instructions on how to optimize the Llama2 model with Microsoft Olive, and how to run the model on any DirectML capable AMD graphics card with ONNXRuntime, accelerated via the DirectML platform API.
If you have already optimized the ONNX model for execution and just want to run the inference, please advance to Step 3 below.
1.Prerequisites
- Installed Git (Git for Windows)
- Installed Anaconda
- onnxruntime_directml==1.16.2 or newer
- Platform having AMD Graphics Processing Units (GPU)
- Driver: AMD Software: Adrenalin Edition™ 23.11.1 or newer (https://www.amd.com/en/support)
2.Convert Llama2 model to ONNX format and optimize the models for execution
Download the Llama2 models from Meta’s release, use Microsoft Olive to convert it to ONNX format and optimize the ONNX model for GPU hardware acceleration.
Using the instructions from Microsoft Olive, download Llama model weights and generate optimized ONNX models for efficient execution on AMD GPUs
Open Anaconda terminal and input the following commands:
- conda create --name=llama2_Optimize python=3.9
- conda activate llama2_Optimize
- git clone https://github.com/microsoft/Olive.git
- cd olive
- pip install -r requirements.txt
- pip install -e .
- cd examples/directml/llama_v2
- pip install -r requirements.txt
Request accessto the Llama 2 weights from Meta, Convert to ONNX, and optimize the ONNX models
- python llama_v2.py --optimize
- Note: The first time this script is invoked can take some time since it will need to download the Llama 2 weights from Meta. When requested, paste the URL that was sent to your e-mail address by Meta (the link is valid for 24 hours)
3. Run Optimized Llama2 Model on AMD GPUs
Once the optimized ONNX model is generated from Step 2, or if you already have the models locally, see the below instructions for running Llama2 on AMD Graphics.
3.1Run Llama 2 using Python Command Line
Open Anaconda terminal
- conda create --name=llama2 python=3.9
- conda activate llama2
- pip install gradio==3.42.0
- pip install markdown
- pip install mdtex2html
- pip install optimum
- pip install tabulate
- pip install pygments
- pip install onnxruntime_directml // make sure it’s 1.16.2 or newer.
- git clone https://github.com/microsoft/Olive.git
- cd Olive\examples\directml\llama_v2
Copy the optimized models here (“Olive\examples\directml\llama_v2\models” folder). The optimized model folder structure should look like this:

The end result should look like this when using the following prompt:
- Python run_llama_v2_io_binding.py --prompt="what is the capital of California and what is California famous for?"

3.2Run Llama2 using the Chat App
To use Chat App which is an interactive interface for running llama_v2 model, follow these steps:
Open Anaconda terminal and input the following commands:
- conda create --name=llama2_chat python=3.9
- conda activate llama2_chat
- pip install gradio==3.42.0
- pip install markdown
- pip install mdtex2html
- pip install optimum
- pip install tabulate
- pip install pygments
- pip install onnxruntime_directml // make sure it’s 1.16.2 or newer.
- git clone https://github.com/microsoft/Olive.git
- cd Olive\examples\directml\llama_v2
Copy the optimized models here (“Olive\examples\directml\llama_v2\models” folder). The optimized model folder structure should look like this:

Launch the Chat App
- python chat_app/app.py
- Click on open local URL

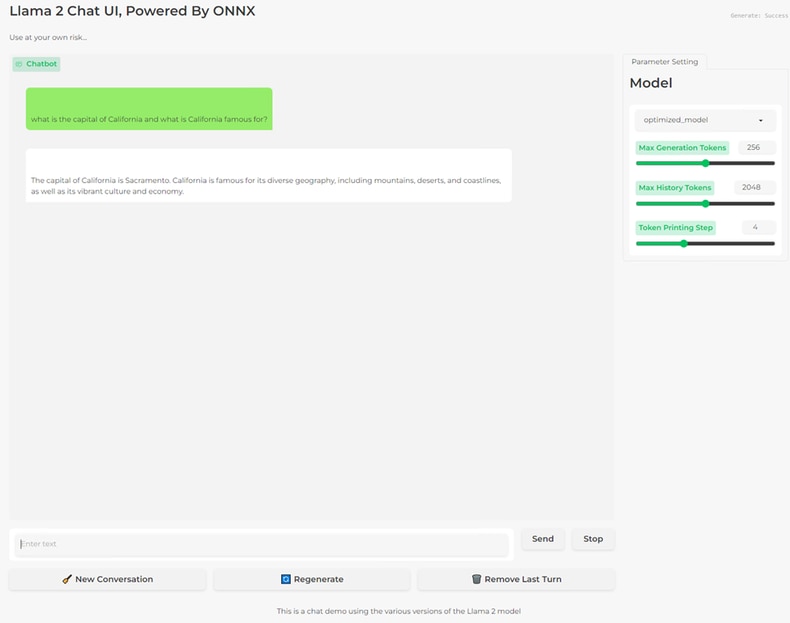
It opens the below page. Add your prompt and start chatting.


Related Blogs
-
Agent Computers: The PC Era, Amplified
"Discover the Agent Computer: a new AI-powered computer category designed to run autonomous agents locally using AMD Ryzen™ AI Max+ processors.
March 13, 2026
-
AMD Silo AI and UniMoRe to Advance Physical AI
AImagelab (University of Modena and Reggio Emilia) and AMD Silo AI to collaborate on multimodal VLA systems for robotics and autonomous driving.
March 13, 2026
-
ZenDNN 5.2: Accelerating vLLM Inference on AMD EPYC™ CPUs
Accelerate AI inference on CPUs with ZenDNN 5.2. Achieve faster vLLM performance and efficient LLM workloads on AMD EPYC processors.
March 13, 2026
-
AMD Enterprise AI Suite Version 1.8
AMD Enterprise AI Suite Expands with DeepSeek and Mistral AI models, and adds Support for AMD Instinct™ MI350X and MI355X GPUs.
March 10, 2026
-
Propelling Aerospace Innovation
In this blog, we’ll look at how Xanadu and PennyLane are driving development of practical quantum algorithms with industry partners alongside AMD hardware.
March 10, 2026
-
FP8 GEMM Optimization on AMD CDNA™4 Architecture — ROCm Blogs
Learn how to build high-performance FP8 GEMM kernels on AMD CDNA™4 GPUs using MFMA, LDS swizzling, and double-buffering.
March 09, 2026
-
New GPU MODE Virtual Hackathon: E2E Model Speedrun
We are excited to announce the launch of the GPU MODE Virtual Hackathon: E2E Model Speedrun, sponsored by AMD. This global competition challenges developers, researchers, and performance engineers to push the limits of large language model (LLM) inference performance on open models optimized for AMD Instinct™ MI355X GPUs.
March 09, 2026
-
Getting Started with ComfyUI on AMD Radeon™ RX 9000 Series GPUs — ROCm Blogs
Learn how to set up and optimize ComfyUI on AMD Radeon RX 9000 GPUs with ROCm 7.1 — solve common issues and start generating.
March 08, 2026








Footnotes
4.Disclaimers and Footnotes
Links to third-party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites, and no endorsement is implied. GD-98Microsoft Olive is an active branch which changes often, so the interfaces and setup may look slightly different depending on when the branch is downloaded.ATTRIBUTIONSThe information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions, and typographical errors. The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. Any computer system has risks of security vulnerabilities that cannot be completely prevented or mitigated. AMD assumes no obligation to update or otherwise correct or revise this information. However, AMD reserves the right to revise this information and to make changes from time to time tothe content hereof without obligation of AMD to notify any person of such revisions or changes. GD-18. THIS INFORMATION IS PROVIDED ‘AS IS.” AMD MAKES NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE CONTENTS HEREOF AND ASSUMES NO RESPONSIBILITY FOR ANY INACCURACIES, ERRORS, OR OMISSIONS THAT MAY APPEAR IN THIS INFORMATION. AMD SPECIFICALLY DISCLAIMS ANY IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR ANY PARTICULAR PURPOSE. IN NO EVENT WILL AMD BE LIABLE TO ANY PERSON FOR ANY RELIANCE, DIRECT, INDIRECT, SPECIAL, OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF AMD IS EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.Copyright 2023 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, [insert all other AMD trademarks used in the material IN ALPHABETICAL ORDER here per AMD's Guidelines on Using Trademark Notice and Attribution] and combinations thereof are trademarks of Advanced Micro Devices, Inc. Microsoft is a registered trademark of Microsoft Corporation in the US and/or other countries. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners.
Footnotes
4.Disclaimers and Footnotes
Links to third-party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites, and no endorsement is implied. GD-98Microsoft Olive is an active branch which changes often, so the interfaces and setup may look slightly different depending on when the branch is downloaded.ATTRIBUTIONSThe information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions, and typographical errors. The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. Any computer system has risks of security vulnerabilities that cannot be completely prevented or mitigated. AMD assumes no obligation to update or otherwise correct or revise this information. However, AMD reserves the right to revise this information and to make changes from time to time tothe content hereof without obligation of AMD to notify any person of such revisions or changes. GD-18. THIS INFORMATION IS PROVIDED ‘AS IS.” AMD MAKES NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE CONTENTS HEREOF AND ASSUMES NO RESPONSIBILITY FOR ANY INACCURACIES, ERRORS, OR OMISSIONS THAT MAY APPEAR IN THIS INFORMATION. AMD SPECIFICALLY DISCLAIMS ANY IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR ANY PARTICULAR PURPOSE. IN NO EVENT WILL AMD BE LIABLE TO ANY PERSON FOR ANY RELIANCE, DIRECT, INDIRECT, SPECIAL, OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF AMD IS EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.Copyright 2023 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, [insert all other AMD trademarks used in the material IN ALPHABETICAL ORDER here per AMD's Guidelines on Using Trademark Notice and Attribution] and combinations thereof are trademarks of Advanced Micro Devices, Inc. Microsoft is a registered trademark of Microsoft Corporation in the US and/or other countries. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners.