LLM on AMD GPU: Memory Footprint and Performance Improvements on AMD Ryzen™ AI and Radeon™ Platforms
May 23, 2024

Written by:Hisham Chowdhury (AMD),Sonbol Yazdanbakhsh (AMD),Lucas Neves (AMD)

Prerequisites
- Installed Git (Git for Windows)
- InstalledAnaconda
- onnxruntime_directml==1.18.0 or newer
- Platform with AMD Radeon Graphics (GPUs)
- Driver: AMD Software: preview release or Adrenalin Edition™ 24.6.1 or newer (https://www.amd.com/en/support)
Introduction
Over the past year, AMD with close partnership with Microsoft has made significant advancement on accelerating generative AI workloads via ONNXRuntime with DirectML on AMD platforms. As a follow up to our previous releases, we are happy to share that with close collaboration with Microsoft, we are bringing 4-bit quantization support and acceleration for LLMs (Large Language Models) to integrated and discrete AMD Radeon GPU platforms running with ONNXRuntime->DirectML.
LLMs are invariably bottlenecked by memory bandwidth and memory availability on the system. Depending on the number of parameters used by the LLM (7B, 13B, 70B etc), the memory consumption on the system increases significantly, which makes some of the system out of contention in running such workloads. To solve that problem and to make a large set of integrated and discrete GPUs accessible to such LLM workloads, we are introducing 4-bit quantization for LLM parameters to execute these workloads with large memory reduction at the same time increasing the performance.
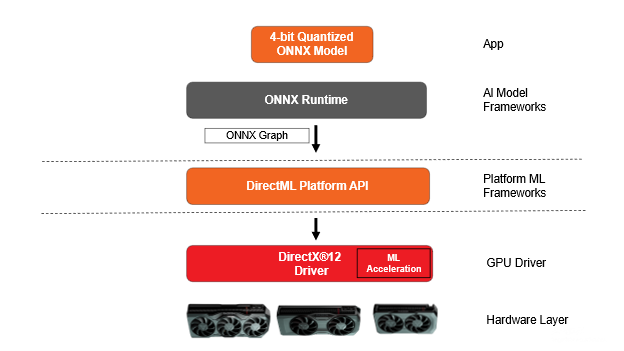
Fig: Software Stack on AMD Radeon platform with DirectML
NEW! Activation-Aware Quantization
With the latest DirectML and AMD driver preview release, Microsoft and AMD are happy to introduce Activation-Aware Quantization (AWQ) based LM acceleration accelerated on AMD GPU platforms. The AWQ technique compresses weights to 4-bit wherever possible with minimal impact to accuracy, thus reducing the memory footprint of running these LLM models significantly while increase the performance at the same time.
The AWQ technique can achieve this compression while maintaining accuracy by identifying the top 1% of salient weights that are necessary for maintaining model accuracy and quantizing the remaining 99% of weight parameters. This technique takes the actual data distribution in the activations into account to decide which weights to quantize from 16-bit to 4-bit resulting in up to 3x memory reduction for the quantized weights/LLM parameters. By taking the data distribution in activations into account it can also maintain the model accuracy compared to traditional weight quantization techniques that doesn’t consider activation data distributions.
This 4-bit AWQ quantization is performed by using Microsoft Olive toolchains for DirectML and at runtime AMD driver resident ML layers dequantize the parameters and accelerates on the ML hardware to achieve the perf boost on AMD Radeon GPUs. The quantization process mentioned here is post training quantization and performed offline before the model is deployed for inference. This technique now makes it possible to run these language models (LM) on device on low memory equipped system which was not possible before.
Performance
Memory footprint reduction compared to running 16-bit variant of the weights on AMD Radeon™ RX 7900 XTX systems, similar reduction on AMD Radeon™ 780m based AMD Ryzen™ AI platforms as well:
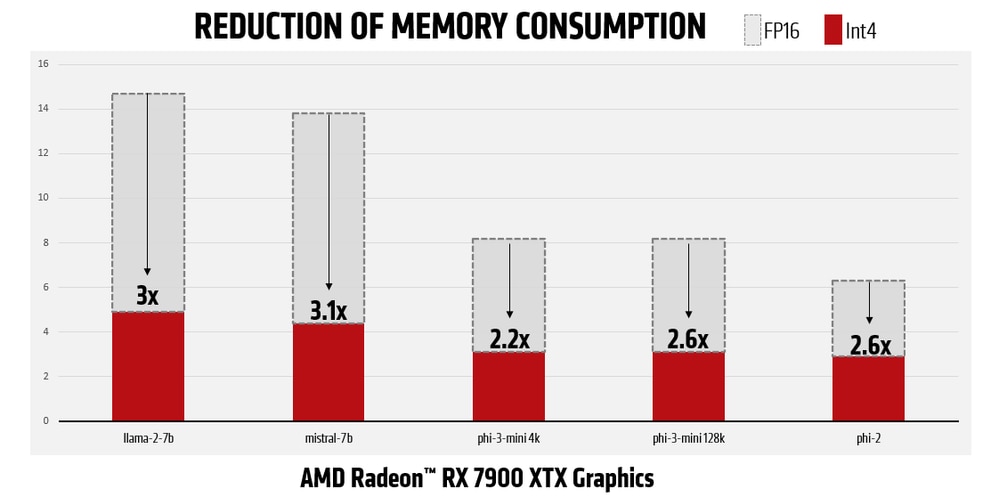
*Figures in charts are averages (see endnote RX-1107)
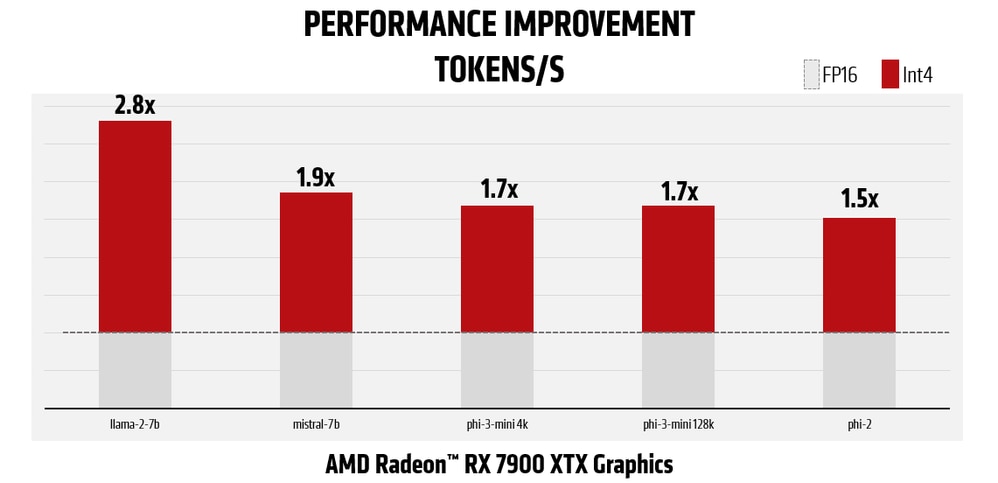
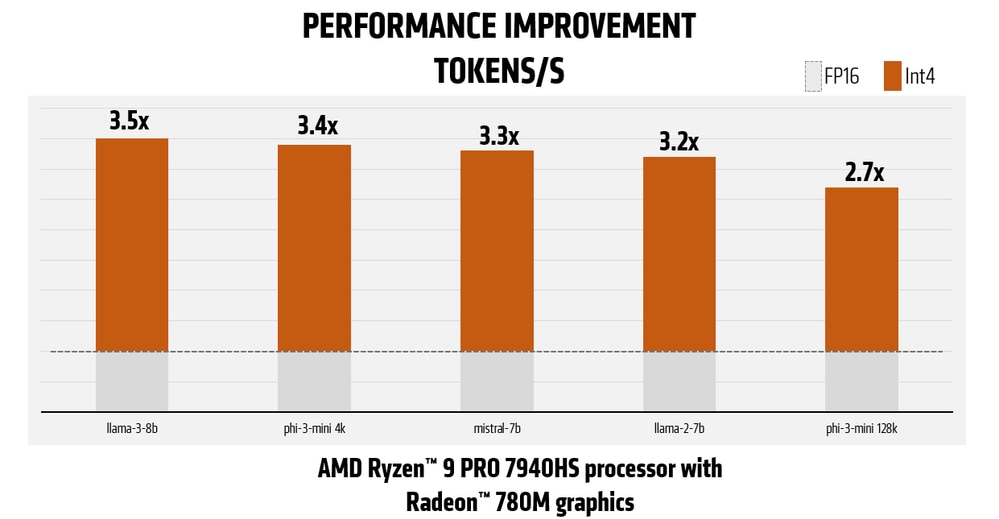
As mentioned earlier, transition to the 4bit quantization technique for LM parameters not only improves memory utilization, but also improves performance by reducing bandwidth significantly:
*Figures in charts are averages(see endnote RX-1108)
*Figures in charts are averages(see endnote RM-159)
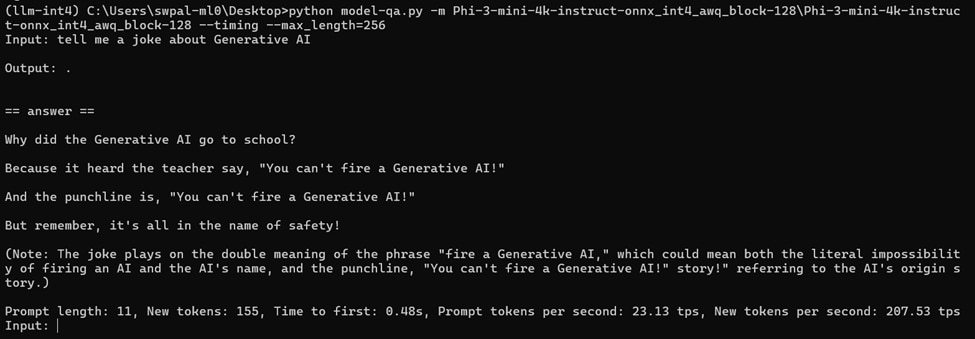
Running Sample Application of LLM using 4-bit quantized models
Run Question-Answer Models Using ONNXRuntime GenAI backend:
Download the 4-bit quantized onnx model from here (e.g. phi-3-mini-4k)
git clone https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnxconda create --name=llm-int4 pythonconda activate llm-int4pip install numpy onnxruntime-genai-directmlcurl https://raw.githubusercontent.com/microsoft/onnxruntime-genai/main/examples/python/model-qa.py -o model-qa.pypython model-qa.py -m Phi-3-mini-4k-instruct-onnx\directml\directml-int4-awq-block-128 --timing --max_length=256


Related Blogs
-
The Importance of Open Ecosystems for Agentic AI Deployment
Enterprise agents need access to applications and data across the business. Open ecosystems help prevent AI vendor lock-in from standing in their way
July 30, 2026
-
Advancing AI 2026 Developer Sessions
See how Advancing AI 2026 brought together 2,000+ developers for workshops, technical sessions, and hands-on demos.
July 30, 2026
-
Closing the GPU Cluster Validation Gap: A Kubernetes-Native Approach with CVF — ROCm Blogs
Learn how to validate AMD GPU clusters end-to-end with CVF: hardware acceptance, mesh bandwidth, RDMA, and RCCL testing in one pipeline.
July 28, 2026
-
AMD GPU Operator v1.5.0: DRA Support, Automated GPU Node Recovery, and Expanded Kubernetes Infrastructure Control — ROCm Blogs
Discover how AMD GPU Operator v1.5.0 improves GPU scheduling, automates node recovery, and expands Kubernetes control.
July 27, 2026
-
Kimi-K3 on AMD Instinct GPUs
Day 0 support for Kimi-K3 on AMD Instinct MI355X GPUs with validated TP8 setups.
July 27, 2026
-
Attention Decode on AMD MI450 GPUs: A Gluon Kernel Optimization Guide — ROCm Blogs
Learn how to design a high-performance attention decode kernel on AMD MI450 GPUs using Gluon.
July 26, 2026
-
Accelerating OpenCV with Portable SIMD
Discover how AMD improved OpenCV performance for millions of developers with upstream CPU optimizations across platforms.
July 24, 2026
-
Introducing Instella-MoE: A State-of-the-Art Fully Open Mixture-of-Experts Language Model — ROCm Blogs
Explore Instella-MoE-16B-A3B, AMD’s fully open 16B MoE LLM with 2.8B active params per token, trained on AMD Instinct™ MI300 & MI325 GPUs.
July 23, 2026








Footnotes
DISCLAIMERS AND FOOTNOTES
Links to third-party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites, and no endorsement is implied. GD-98
Testing conducted by AMD as of May 12th, 2024, on a test system configured with a Ryzen 9 7950X CPU, 32GB DDR5, Radeon RX 7900 XTX GPU, and Windows 11 Pro, with AMD Software: Adrenalin Edition, Performance may vary. System manufacturers may vary configurations, yielding different results. RS-621
Testing done by AMD Lab, as of May 16, 2024, on a test system configured AMD Ryzen 9 7950X and AMD Radeon RX 7900 XTX, 64GB 2133MHz RAM, Driver package 23.40.27.06, Microsoft Win11 23H2 22631.3447. Testing performance across: llama-2-7b, mistral-7b, phi-3 4k, phi-3 128k, and phi-2. System manufacturers may vary configurations, yielding different results. Performance may vary. RX-1107
Testing done by AMD Lab, as of May 16, 2024, on a test system configured AMD Ryzen 9 7950X and AMD Radeon RX 7900 XTX, 64GB 2133MHz RAM, Driver package 23.40.27.06, Microsoft Win11 23H2 22631.3447. Testing performance across: llama-2-7b, mistral-7b, phi-3 4k, phi-3 128k, and phi-2. System manufacturers may vary configurations, yielding different results. Performance may vary. RX-1108
Testing done by AMD Lab, as of May 16, 2024, on a HP Zbook Power G10 configured with AMD Ryzen™ 9 PRO 7940HS Processor with AMD Radeon™ 780M graphics, 64GB 2133MHz RAM, Driver package 23.40.27.06 , Microsoft Win11 Pro 22H2 (22621.3447). Testing performance across: llama-2-7b, llama-3-8b, mistral-7b, phi-3 4k, and phi-3 128k. System manufacturers may vary configurations, yielding different results. Performance may vary. RM-159
Ryzen™ AI is defined as the combination of a dedicated AI engine, AMD Radeon™ graphics engine, and Ryzen processor cores that enable AI capabilities. OEM and ISV enablement is required, and certain AI features may not yet be optimized for Ryzen AI processors. Ryzen AI is compatible with: (a) AMD Ryzen 7040 and 8040 Series processors except Ryzen 5 7540U, Ryzen 5 8540U, Ryzen 3 7440U, and Ryzen 3 8440U processors; and (b) all AMD Ryzen 8000G Series desktop processors except the Ryzen 5 8500G/GE and Ryzen 3 8300G/GE. Please check with your system manufacturer for feature availability prior to purchase. GD-220b.
Links to third-party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites, and no endorsement is implied. GD-98
Radeon™ RX 6000 and RX 7000 Series graphics cards (and later models) are not designed, marketed nor recommended for datacenter usage. Use in a datacenter setting may adversely affect manageability, efficiency, reliability, and/or performance. GD-240.
ATTRIBUTIONS
The information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions, and typographical errors. The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. Any computer system has risks of security vulnerabilities that cannot be completely prevented or mitigated. AMD assumes no obligation to update or otherwise correct or revise this information. However, AMD reserves the right to revise this information and to make changes from time to time tothe content hereof without obligation of AMD to notify any person of such revisions or changes. GD-18.
THIS INFORMATION IS PROVIDED ‘AS IS.” AMD MAKES NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE CONTENTS HEREOF AND ASSUMES NO RESPONSIBILITY FOR ANY INACCURACIES, ERRORS, OR OMISSIONS THAT MAY APPEAR IN THIS INFORMATION. AMD SPECIFICALLY DISCLAIMS ANY IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR ANY PARTICULAR PURPOSE. IN NO EVENT WILL AMD BE LIABLE TO ANY PERSON FOR ANY RELIANCE, DIRECT, INDIRECT, SPECIAL, OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF AMD IS EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
© 2024 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, Radeon, Ryzen, and combinations thereof are trademarks of Advanced Micro Devices, Inc. Microsoft is a registered trademark of Microsoft Corporation in the US and/or other countries. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners. Certain AMD technologies may require third-party enablement or activation. Supported features may vary by operating system. Please confirm with system manufacturer for specific features. No technology or product can be completely secure.
Footnotes
Ryzen™ AI is defined as the combination of a dedicated AI engine, AMD Radeon™ graphics engine, and Ryzen processor cores that enable AI capabilities. OEM and ISV enablement is required, and certain AI features may not yet be optimized for Ryzen AI processors. Ryzen AI is compatible with: (a) AMD Ryzen 7040 and 8040 Series processors except Ryzen 5 7540U, Ryzen 5 8540U, Ryzen 3 7440U, and Ryzen 3 8440U processors; and (b) all AMD Ryzen 8000G Series desktop processors except the Ryzen 5 8500G/GE and Ryzen 3 8300G/GE. Please check with your system manufacturer for feature availability prior to purchase. GD-220b.
ATTRIBUTIONS
DISCLAIMERS AND FOOTNOTES
Links to third-party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites, and no endorsement is implied. GD-98
Testing conducted by AMD as of May 12th, 2024, on a test system configured with a Ryzen 9 7950X CPU, 32GB DDR5, Radeon RX 7900 XTX GPU, and Windows 11 Pro, with AMD Software: Adrenalin Edition, Performance may vary. System manufacturers may vary configurations, yielding different results. RS-621
Testing done by AMD Lab, as of May 16, 2024, on a test system configured AMD Ryzen 9 7950X and AMD Radeon RX 7900 XTX, 64GB 2133MHz RAM, Driver package 23.40.27.06, Microsoft Win11 23H2 22631.3447. Testing performance across: llama-2-7b, mistral-7b, phi-3 4k, phi-3 128k, and phi-2. System manufacturers may vary configurations, yielding different results. Performance may vary. RX-1107
Testing done by AMD Lab, as of May 16, 2024, on a test system configured AMD Ryzen 9 7950X and AMD Radeon RX 7900 XTX, 64GB 2133MHz RAM, Driver package 23.40.27.06, Microsoft Win11 23H2 22631.3447. Testing performance across: llama-2-7b, mistral-7b, phi-3 4k, phi-3 128k, and phi-2. System manufacturers may vary configurations, yielding different results. Performance may vary. RX-1108
Testing done by AMD Lab, as of May 16, 2024, on a HP Zbook Power G10 configured with AMD Ryzen™ 9 PRO 7940HS Processor with AMD Radeon™ 780M graphics, 64GB 2133MHz RAM, Driver package 23.40.27.06 , Microsoft Win11 Pro 22H2 (22621.3447). Testing performance across: llama-2-7b, llama-3-8b, mistral-7b, phi-3 4k, and phi-3 128k. System manufacturers may vary configurations, yielding different results. Performance may vary. RM-159
Ryzen™ AI is defined as the combination of a dedicated AI engine, AMD Radeon™ graphics engine, and Ryzen processor cores that enable AI capabilities. OEM and ISV enablement is required, and certain AI features may not yet be optimized for Ryzen AI processors. Ryzen AI is compatible with: (a) AMD Ryzen 7040 and 8040 Series processors except Ryzen 5 7540U, Ryzen 5 8540U, Ryzen 3 7440U, and Ryzen 3 8440U processors; and (b) all AMD Ryzen 8000G Series desktop processors except the Ryzen 5 8500G/GE and Ryzen 3 8300G/GE. Please check with your system manufacturer for feature availability prior to purchase. GD-220b.
Links to third-party sites are provided for convenience and unless explicitly stated, AMD is not responsible for the contents of such linked sites, and no endorsement is implied. GD-98
Radeon™ RX 6000 and RX 7000 Series graphics cards (and later models) are not designed, marketed nor recommended for datacenter usage. Use in a datacenter setting may adversely affect manageability, efficiency, reliability, and/or performance. GD-240.
ATTRIBUTIONS
The information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions, and typographical errors. The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. Any computer system has risks of security vulnerabilities that cannot be completely prevented or mitigated. AMD assumes no obligation to update or otherwise correct or revise this information. However, AMD reserves the right to revise this information and to make changes from time to time tothe content hereof without obligation of AMD to notify any person of such revisions or changes. GD-18.
THIS INFORMATION IS PROVIDED ‘AS IS.” AMD MAKES NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE CONTENTS HEREOF AND ASSUMES NO RESPONSIBILITY FOR ANY INACCURACIES, ERRORS, OR OMISSIONS THAT MAY APPEAR IN THIS INFORMATION. AMD SPECIFICALLY DISCLAIMS ANY IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR ANY PARTICULAR PURPOSE. IN NO EVENT WILL AMD BE LIABLE TO ANY PERSON FOR ANY RELIANCE, DIRECT, INDIRECT, SPECIAL, OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF AMD IS EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
© 2024 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, Radeon, Ryzen, and combinations thereof are trademarks of Advanced Micro Devices, Inc. Microsoft is a registered trademark of Microsoft Corporation in the US and/or other countries. Other product names used in this publication are for identification purposes only and may be trademarks of their respective owners. Certain AMD technologies may require third-party enablement or activation. Supported features may vary by operating system. Please confirm with system manufacturer for specific features. No technology or product can be completely secure.