AMD Instinct™ MI350 Series GPUs: A Game Changer for Inference, Training and HPC Workloads
Sep 08, 2025

There’s no shortage of AI hardware out there. But when you’re deploying massive models, accelerating inference at scale, or pushing HPC workloads to the edge—raw performance alone doesn’t cut it. You need performance that shows up in the real world, works with the infrastructure you already have, and delivers tangible ROI.
That’s exactly what the brand-new AMD Instinct™ MI350 Series GPUs were built to do. Unveiled at Advancing AI in June 2025, MI350 Series GPUs represent the latest leap forward in AI and HPC acceleration from AMD. Built for today’s most demanding compute environments—from generative AI to scientific simulation—these GPUs offer next-level performance, efficiency, and deployment flexibility you can count on from day one.
Performance Built for Real-World AI
Powered by the latest 4th Gen AMD CDNA™ architecture, the AMD Instinct™ MI350X and MI355X GPUs bring serious upgrades where it counts—throughput, memory, efficiency, and compatibility—so you can move faster, train bigger, and get more done without reinventing your data center.
The flagship AMD Instinct™ MI355X platform delivers up to 4X peak theoretical performance over the previous generation MI300X platform1, based on architectural improvements and supported precision formats.

In AMD real-world inference testing with the Llama 3.1 405B model, the MI355X platform demonstrated substantial throughput gains compared to the MI300X platform across key generative AI tasks:
- Up to 4.2X better performance in AI agent and chatbot workloads2
- Up to 2.9X better performance in content generation2
- Up to 3.8X better performance in summarization2
- Up to 2.6X better performance in conversational AI2

When compared to today’s most powerful competitive GPUs, the AMD Instinct™ MI355X platform continues to lead the way in some of today’s most popular AI workloads.
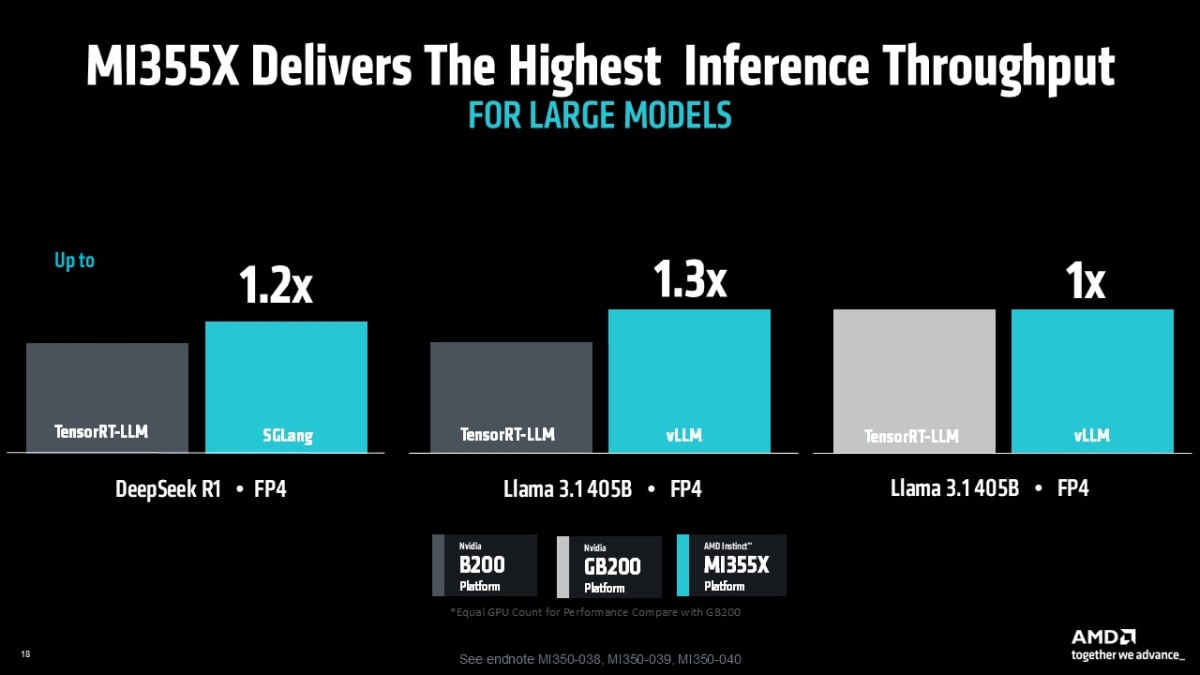
In FP4 inference tests across large language models like Llama 3.1 405B and DeepSeek R1, the MI355X platform consistently delivers higher throughput than the latest NVIDIA B200 platforms—highlighting real performance gains in the environments that matter most.
- Up to 1.3X better inference throughput vs B200 on Llama 3.1 405B using vLLM3
- Up to 1.2X better inference throughput vs B200 on DeepSeek R1 using SGLang4
- Comparable performance vs GB200 on Llama 3.1 405B, showing broad software parity5
For training, the MI355X platform delivered up to 1.13X faster time-to to-train when compared to the Nvidia B200 platform6, and up to 1.12X faster time-to-train than the more expensive and more complicated NVIDIA GB200 platform on Llama 2-70B-LoRA6 AI training workloads running in FP8 datatypes.
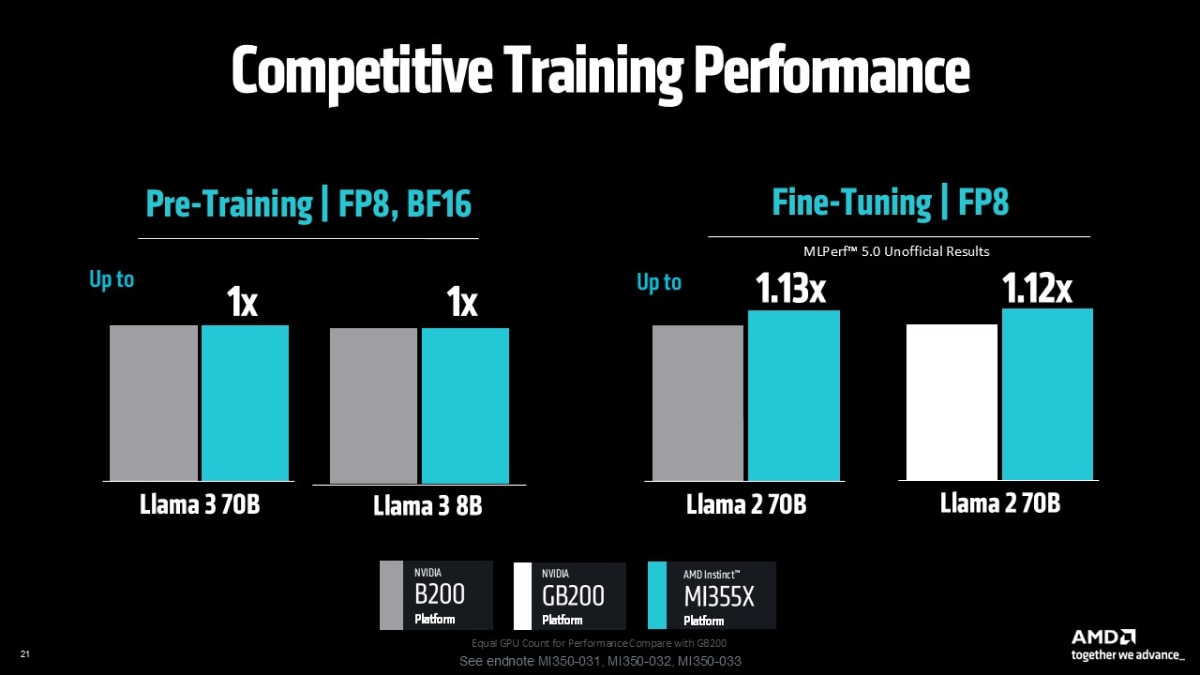
These results demonstrate that the AMD Instinct MI355X platform not only delivers architectural and efficiency gains—it’s also a top-tier choice for customers demanding the highest throughput on today’s largest generative AI models. Whether you're deploying with vLLM, TensorRT-LLM, or SGLang, AMD Instinct MI350 Series GPUs deliver leadership results.
Better Throughput. Smarter Economics.
The MI355X GPU isn’t just about being faster, it’s about being more efficient. On Llama 3.1 405B inference in FP4, it delivers up to 40% better tokens-per-dollar than B2007. This translates directly into lower operational costs and better returns on overall investment in AI infrastructure.

If you care about cost savings, and who doesn’t, that’s a difference worth paying attention to.
Plug In and Scale
AMD Instinct™ MI350 Series GPUs are designed to drop into existing AMD platforms built on the UBB (Universal Base Board) infrastructure used for MI300 Series—no forklift upgrades or system re-architecture required. That means you can unlock next-gen performance with minimal friction, using the existing server chassis, power, and cooling infrastructure.
And when it comes to deployment, you’ve got options. AMD Instinct™ MI350X and MI355X platforms are available in both air-cooled and direct liquid-cooled versions, so you can scale based on your thermal and density goals, not your hardware limitations.

288GB of HBM3E Memory. No Compromises.
Each AMD Instinct™ MI350 Series GPU comes with 288GB of high-bandwidth HBM3E memory, enabling you to run a 520B+ parameter model on a single GPU8. That’s huge!
No model splitting, no interconnect bottlenecks, no extra layers of complexity, just faster time to results and simplified scaling.
AMD ROCm™ Software Keeps Getting Better
Software matters, and AMD ROCm™ continues to prove it. With optimized support for Flash Attention, Transformer Engine, and tuned GEMM operations, AMD ROCm™ 7 software is driving meaningful gains across the stack.
For example, when comparing AMD ROCm 6 to ROCm 7 software, the AMD Instinct™ MI300X GPU shows:
- 3.5X average uplift in inference performance across a suite of industry-standard AI models9
- 3X average uplift in training performance across commonly used AI training workloads10
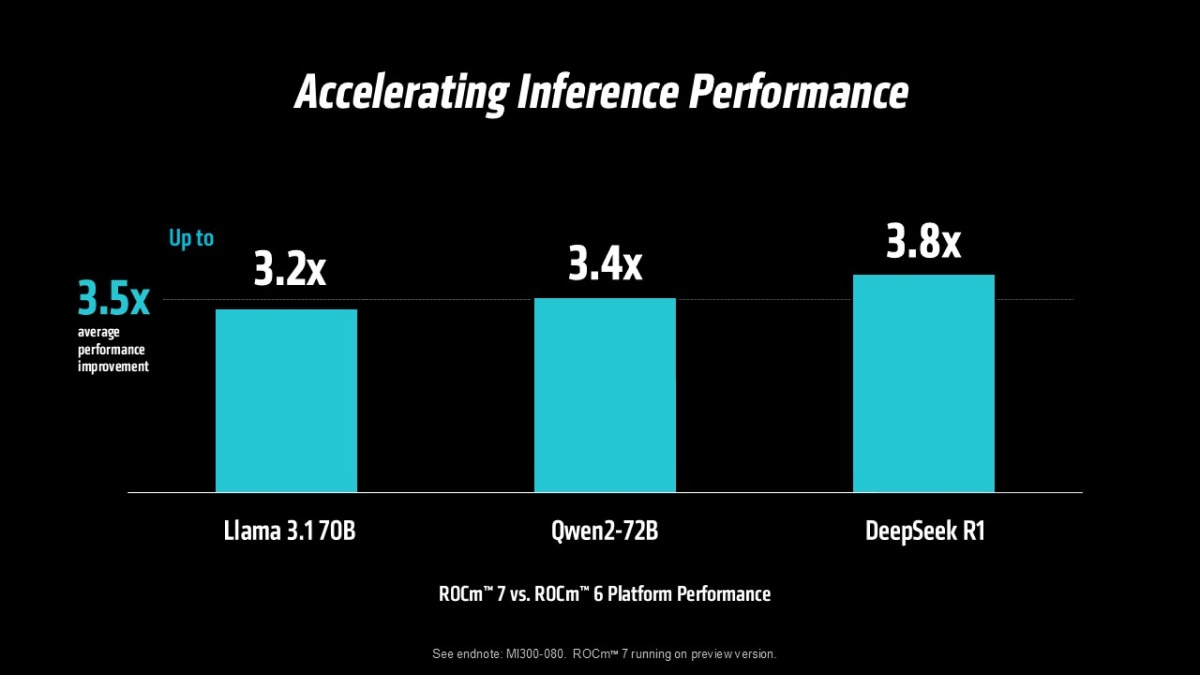
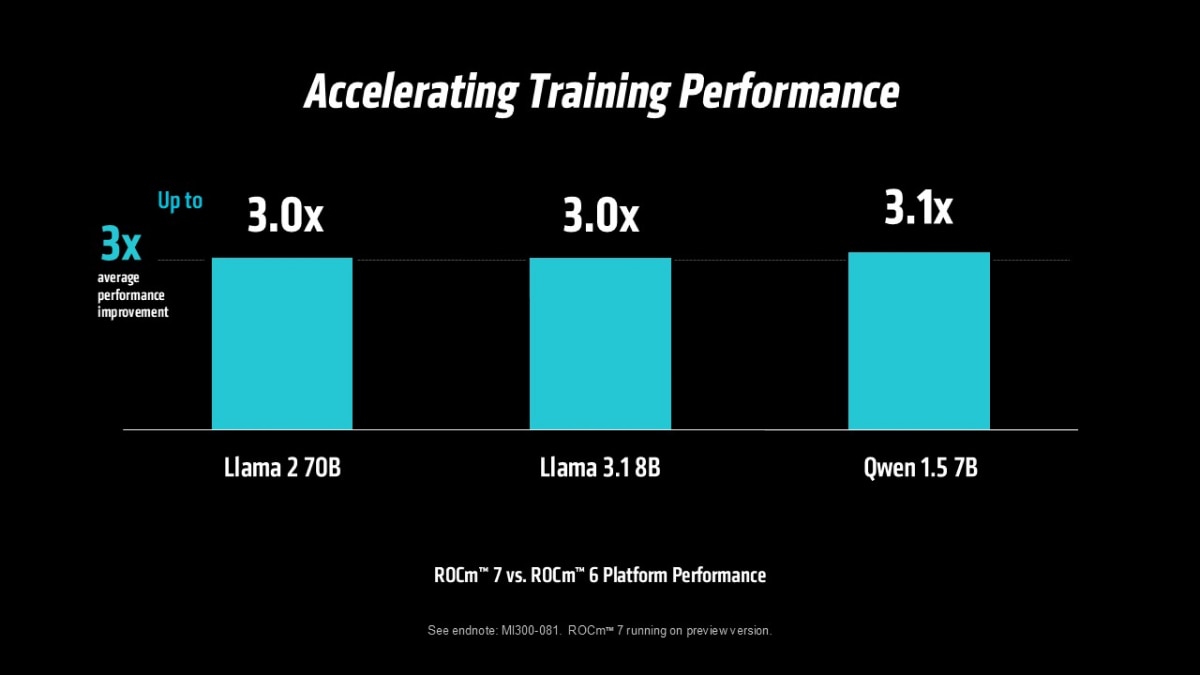
These improvements reflect the ongoing AMD investment in software optimization, enabling customers to unlock significantly more performance from the same hardware over time. As a result, AMD Instinct MI350 Series GPUs benefit not only from architectural advancements, but also from major software-driven gains, delivering faster inference throughput and reduced time-to-train across key AI workloads.
Trusted Performance That Scales Forward
The AMD Instinct MI350 Series is already driving AI at scale for some of the most influential names in AI, designed to scale forward and power the next wave of breakthroughs.
“Oracle Cloud Infrastructure continues to benefit from its strategic collaboration with AMD. We will be one of the first to provide the MI355X rack-scale infrastructure using the combined power of EPYC, Instinct, and Pensando. We've seen impressive customer adoption for AMD-powered bare metal instances, underscoring how easily customers can adopt and scale their AI workloads with OCI AI infrastructure. In addition, Oracle relies extensively on AMD technology, both internally for its own workloads and externally for customer-facing applications. We plan to continue to have deep engagement across multiple AMD product generations, and we maintain strong confidence in the AMD roadmap and their consistent ability to deliver to expectations.” - Mahesh Thiagarajan, Executive Vice President, Oracle Cloud Infrastructure
"Building on nearly two decades of collaboration, Dell Technologies and AMD are helping organizations leverage the full potential of AI—while reimagining data centers to be more agile, sustainable and future-ready. Joint innovations like high-performance, dense rack solutions for AMD Instinct™ MI350 Series GPUs and optimized AI Scale-Out networking drive real-world breakthroughs for smarter, more efficient AI environments.” - Ihab Tarazi, SVP and CTO for ISG, Dell Technologies
“Hewlett Packard Enterprise delivers some of the world’s largest and highly-performant AI clusters with the HPE ProLiant Compute XD servers and we look forward to delivering even greater performance with the new AMD Instinct MI355X GPUs. Our latest collaboration with AMD expands our decades-long joint engineering efforts, from the edge to exascale, and continues to advance AI innovation.” - Trish Damkroger, Senior Vice President and General Manager, HPC & AI Infrastructure Solutions, Hewlett Packard Enterprise
“We are seeing per device best-in-class performance, the linear scaling characteristics are extremely exciting to scale our large training workloads.” - Ashish Vaswani, CEO, Essential AI
"AMD MI355X GPUs are designed to meet the diverse and complex demands of today’s AI workloads, delivering exceptional value and flexibility. As AI development continues to accelerate, the scalability, security, and efficiency these GPUs deliver are more essential than ever. We are proud to be among the first cloud providers worldwide to offer AMD MI355X GPUs, empowering our customers with next-generation AI infrastructure.” - J.J. Kardwell, CEO, Vultr
Built on a proven foundation, the MI350 Series delivers greater throughput, higher efficiency, and software-driven acceleration for today’s largest AI workloads—scaling seamlessly to tackle even more complex demands ahead.
The Bottom Line
- AMD Instinct™ MI350 Series GPUs deliver what matters most:
- Performance that shows up in the workloads you actually run
- Massive memory that simplifies how you scale
- Efficiency that delivers strong ROI
- Compatibility that lets you deploy without delay
This is what modern AI infrastructure demands: streamlined deployment, open software, and performance that scales with your demands. With AMD Instinct™ MI350 Series GPUs and platforms, you can accelerate innovation, simplify growth, and deliver results—on your terms.
Footnotes
- MI350-004 - Based on calculations by AMD Performance Labs in May 2025, to determine the peak theoretical precision performance of eight (8) AMD Instinct™ MI355X and MI350X GPUs (Platform) and eight (8) AMD Instinct MI325X, MI300X, MI250X and MI100 GPUs (Platform) using the FP16, FP8, FP6 and FP4 datatypes with Matrix. Server manufacturers may vary configurations, yielding different results. Results may vary based on use of the latest drivers and optimizations. - MI350-004
- MI350-042 - Based on AMD internal testing as of 6/5/2025. Using 8 GPU AMD Instinct™ MI355X Platform measuring text generated offline inference throughput for Llama 3.1-405B chat model (FP4) compared 8 GPU AMD Instinct™ MI300X Platform performance with (FP8). MI355X ran 8xTP1 (8 copies of model on 1 GPU) compared to MI300X running 2xTP4 (2 copies of model on 4 GPUs). Tests were conducted using a synthetic dataset with different combinations of 128 and 2048 input tokens, and 128 and 2048 output tokens. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers and optimizations. MI350-042
- MI350-038 - Based on testing by AMD internal labs as of 6/6/2025 measuring text generated throughput for LLaMA 3.1-405B model using FP4 datatype. Test was performed using input length of 128 tokens and an output length of 2048 tokens for AMD Instinct™ MI355X 8xGPU platform compared to NVIDIA B200 HGX 8xGPU platform published results. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers and optimizations. MI350-038
- MI350-040 - Based on testing (tokens per second) by AMD internal labs as of 6/6/2025 measuring text generated online serving throughput for DeepSeek-R1 chat model using FP4 datatype. Test was performed using input length of 3200 tokens and an output length of 800 tokens with concurrency up to 64 looks, serviceable with 30ms ITL threshold for AMD Instinct™ MI355X 8xGPU platform median total tokens compared to NVIDIA B200 HGX 8xGPU platform results. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers and optimizations. MI350-040
- MI350-039 - Based on Lucid automation framework testing by AMD internal labs as of 6/6/2025 measuring text generated throughput for LLaMA 3.1-405B model using FP4 datatype. Test was performed using 4 different combinations (128/2048) of input/output lengths to achieve a mean score of tokens per second for AMD Instinct™ MI355X 4xGPU platform compared to NVIDIA DGX GB200 4xGPU platform. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of latest drivers and optimizations. MI350-039
- MI350-033 - Based on calculations by AMD internal testing as of 6/5/2025. Using 8 GPU AMD Instinct™ MI355X Platform for overall GPU-normalized Training Throughput (time to complete) for fine-tuning using the Llama2-70B LoRA chat model (FP8) compared to published 8 GPU Nvidia B200 and 8 GPU Nvidia GB200 Platform performance (FP8). Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers and optimizations. MI350-033
- MI350-049 - Based on performance testing by AMD Labs as of 6/6/2025, measuring the text generated inference throughput on the LLaMA 3.1-405B model using the FP4 datatype with various combinations of input, output token length with AMD Instinct™ MI355X 8x GPU, and published results for the NVIDIA B200 HGX 8xGPU. Performance per dollar calculated with current pricing for NVIDIA B200 available from Coreweave website and expected Instinct MI355X based cloud instance pricing. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers and optimizations. Current customer pricing as of June 10, 2025, and subject to change. MI350-049
- MI350-012 - Based on calculations by AMD Performance Labs as of April 17, 2025, on the published memory specifications of the AMD Instinct MI350X / MI355X GPU (288GB) vs MI300X (192GB) vs MI325X (256GB). Calculations performed with FP16 precision datatype at (2) bytes per parameter, to determine the minimum number of GPUs (based on memory size) required to run the following LLMs: OPT (130B parameters), GPT-3 (175B parameters), BLOOM (176B parameters), Gopher (280B parameters), PaLM 1 (340B parameters), Generic LM (420B, 500B, 520B, 1.047T parameters), Megatron-LM (530B parameters), LLaMA ( 405B parameters) and Samba (1T parameters). Results based on GPU memory size versus memory required by the model at defined parameters plus 10% overhead. Server manufacturers may vary configurations, yielding different results. Results may vary based on GPU memory configuration, LLM size, and potential variance in GPU memory access or the server operating environment. *All data based on FP16 datatype. For FP8 = X2. For FP4 = X4. MI350-012.
- MI300-080 - Testing by AMD Performance Labs as of May 15, 2025, measuring the inference performance in tokens per second (TPS) of AMD ROCm 6.x software, vLLM 0.3.3 vs. AMD ROCm 7.0 preview version SW, vLLM 0.8.5 on a system with (8) AMD Instinct MI300X GPUs running Llama 3.1-70B (TP2), Qwen 72B (TP2), and Deepseek-R1 (FP16) models with batch sizes of 1-256 and sequence lengths of 128-204. Stated performance uplift is expressed as the average TPS over the (3) LLMs tested. Hardware Configuration: 1P AMD EPYC™ 9534 CPU server with 8x AMD Instinct™ MI300X (192GB, 750W) GPUs, Supermicro AS-8125GS-TNMR2, NPS1 (1 NUMA per socket), 1.5 TiB (24 DIMMs, 4800 mts memory, 64 GiB/DIMM), 4x 3.49TB Micron 7450 storage, BIOS version: 1.8. Software Configuration(s): Ubuntu 22.04 LTS with Linux kernel 5.15.0-119-generic Qwen 72B and Llama 3.1-70B - ROCm 7.0 preview version SW PyTorch 2.7.0. Deepseek R-1 - ROCm 7.0 preview version, SGLang 0.4.6, PyTorch 2.6.0 vs. Qwen 72 and Llama 3.1-70B - ROCm 6.x GA SW PyTorch 2.7.0 and 2.1.1, respectively, Deepseek R-1: ROCm 6.x GA SW SGLang 0.4.1, PyTorch 2.5.0 Server manufacturers may vary configurations, yielding different results. Performance may vary based on configuration, software, vLLM version, and the use of the latest drivers and optimizations. MI300-080
- MI300-081: Testing conducted by AMD Performance Labs as of May 15, 2025, to measure the training performance (TFLOPS) of ROCm 7.0 preview version software, Megatron-LM, on (8) AMD Instinct MI300X GPUs running Llama 2-70B (4K), Qwen1.5-14B, and Llama3.1-8B models, and a custom docker container vs. a similarly configured system with AMD ROCm 6.0 software. Hardware Configuration: 1P AMD EPYC™ 9454 CPU, 8x AMD Instinct MI300X (192GB, 750W) GPUs, American Megatrends International LLC BIOS version: 1.8, BIOS 1.8. Software Configuration: Ubuntu 22.04 LTS with Linux kernel 5.15.0-70-generic ROCm 7.0., Megatron-LM, PyTorch 2.7.0 vs. ROCm 6.0 public release SW, Megatron-LM code branches hanl/disable_te_llama2 for Llama 2-7B, guihong_dev for LLama 2-70B, renwuli/disable_te_qwen1.5 for Qwen1.5-14B, PyTorch 2.2. Server manufacturers may vary configurations, yielding different results. Performance may vary based on configuration, software, vLLM version, and the use of the latest drivers and optimizations. MI300-081
Footnotes
- MI350-004 - Based on calculations by AMD Performance Labs in May 2025, to determine the peak theoretical precision performance of eight (8) AMD Instinct™ MI355X and MI350X GPUs (Platform) and eight (8) AMD Instinct MI325X, MI300X, MI250X and MI100 GPUs (Platform) using the FP16, FP8, FP6 and FP4 datatypes with Matrix. Server manufacturers may vary configurations, yielding different results. Results may vary based on use of the latest drivers and optimizations. - MI350-004
- MI350-042 - Based on AMD internal testing as of 6/5/2025. Using 8 GPU AMD Instinct™ MI355X Platform measuring text generated offline inference throughput for Llama 3.1-405B chat model (FP4) compared 8 GPU AMD Instinct™ MI300X Platform performance with (FP8). MI355X ran 8xTP1 (8 copies of model on 1 GPU) compared to MI300X running 2xTP4 (2 copies of model on 4 GPUs). Tests were conducted using a synthetic dataset with different combinations of 128 and 2048 input tokens, and 128 and 2048 output tokens. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers and optimizations. MI350-042
- MI350-038 - Based on testing by AMD internal labs as of 6/6/2025 measuring text generated throughput for LLaMA 3.1-405B model using FP4 datatype. Test was performed using input length of 128 tokens and an output length of 2048 tokens for AMD Instinct™ MI355X 8xGPU platform compared to NVIDIA B200 HGX 8xGPU platform published results. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers and optimizations. MI350-038
- MI350-040 - Based on testing (tokens per second) by AMD internal labs as of 6/6/2025 measuring text generated online serving throughput for DeepSeek-R1 chat model using FP4 datatype. Test was performed using input length of 3200 tokens and an output length of 800 tokens with concurrency up to 64 looks, serviceable with 30ms ITL threshold for AMD Instinct™ MI355X 8xGPU platform median total tokens compared to NVIDIA B200 HGX 8xGPU platform results. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers and optimizations. MI350-040
- MI350-039 - Based on Lucid automation framework testing by AMD internal labs as of 6/6/2025 measuring text generated throughput for LLaMA 3.1-405B model using FP4 datatype. Test was performed using 4 different combinations (128/2048) of input/output lengths to achieve a mean score of tokens per second for AMD Instinct™ MI355X 4xGPU platform compared to NVIDIA DGX GB200 4xGPU platform. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of latest drivers and optimizations. MI350-039
- MI350-033 - Based on calculations by AMD internal testing as of 6/5/2025. Using 8 GPU AMD Instinct™ MI355X Platform for overall GPU-normalized Training Throughput (time to complete) for fine-tuning using the Llama2-70B LoRA chat model (FP8) compared to published 8 GPU Nvidia B200 and 8 GPU Nvidia GB200 Platform performance (FP8). Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers and optimizations. MI350-033
- MI350-049 - Based on performance testing by AMD Labs as of 6/6/2025, measuring the text generated inference throughput on the LLaMA 3.1-405B model using the FP4 datatype with various combinations of input, output token length with AMD Instinct™ MI355X 8x GPU, and published results for the NVIDIA B200 HGX 8xGPU. Performance per dollar calculated with current pricing for NVIDIA B200 available from Coreweave website and expected Instinct MI355X based cloud instance pricing. Server manufacturers may vary configurations, yielding different results. Performance may vary based on use of the latest drivers and optimizations. Current customer pricing as of June 10, 2025, and subject to change. MI350-049
- MI350-012 - Based on calculations by AMD Performance Labs as of April 17, 2025, on the published memory specifications of the AMD Instinct MI350X / MI355X GPU (288GB) vs MI300X (192GB) vs MI325X (256GB). Calculations performed with FP16 precision datatype at (2) bytes per parameter, to determine the minimum number of GPUs (based on memory size) required to run the following LLMs: OPT (130B parameters), GPT-3 (175B parameters), BLOOM (176B parameters), Gopher (280B parameters), PaLM 1 (340B parameters), Generic LM (420B, 500B, 520B, 1.047T parameters), Megatron-LM (530B parameters), LLaMA ( 405B parameters) and Samba (1T parameters). Results based on GPU memory size versus memory required by the model at defined parameters plus 10% overhead. Server manufacturers may vary configurations, yielding different results. Results may vary based on GPU memory configuration, LLM size, and potential variance in GPU memory access or the server operating environment. *All data based on FP16 datatype. For FP8 = X2. For FP4 = X4. MI350-012.
- MI300-080 - Testing by AMD Performance Labs as of May 15, 2025, measuring the inference performance in tokens per second (TPS) of AMD ROCm 6.x software, vLLM 0.3.3 vs. AMD ROCm 7.0 preview version SW, vLLM 0.8.5 on a system with (8) AMD Instinct MI300X GPUs running Llama 3.1-70B (TP2), Qwen 72B (TP2), and Deepseek-R1 (FP16) models with batch sizes of 1-256 and sequence lengths of 128-204. Stated performance uplift is expressed as the average TPS over the (3) LLMs tested. Hardware Configuration: 1P AMD EPYC™ 9534 CPU server with 8x AMD Instinct™ MI300X (192GB, 750W) GPUs, Supermicro AS-8125GS-TNMR2, NPS1 (1 NUMA per socket), 1.5 TiB (24 DIMMs, 4800 mts memory, 64 GiB/DIMM), 4x 3.49TB Micron 7450 storage, BIOS version: 1.8. Software Configuration(s): Ubuntu 22.04 LTS with Linux kernel 5.15.0-119-generic Qwen 72B and Llama 3.1-70B - ROCm 7.0 preview version SW PyTorch 2.7.0. Deepseek R-1 - ROCm 7.0 preview version, SGLang 0.4.6, PyTorch 2.6.0 vs. Qwen 72 and Llama 3.1-70B - ROCm 6.x GA SW PyTorch 2.7.0 and 2.1.1, respectively, Deepseek R-1: ROCm 6.x GA SW SGLang 0.4.1, PyTorch 2.5.0 Server manufacturers may vary configurations, yielding different results. Performance may vary based on configuration, software, vLLM version, and the use of the latest drivers and optimizations. MI300-080
- MI300-081: Testing conducted by AMD Performance Labs as of May 15, 2025, to measure the training performance (TFLOPS) of ROCm 7.0 preview version software, Megatron-LM, on (8) AMD Instinct MI300X GPUs running Llama 2-70B (4K), Qwen1.5-14B, and Llama3.1-8B models, and a custom docker container vs. a similarly configured system with AMD ROCm 6.0 software. Hardware Configuration: 1P AMD EPYC™ 9454 CPU, 8x AMD Instinct MI300X (192GB, 750W) GPUs, American Megatrends International LLC BIOS version: 1.8, BIOS 1.8. Software Configuration: Ubuntu 22.04 LTS with Linux kernel 5.15.0-70-generic ROCm 7.0., Megatron-LM, PyTorch 2.7.0 vs. ROCm 6.0 public release SW, Megatron-LM code branches hanl/disable_te_llama2 for Llama 2-7B, guihong_dev for LLama 2-70B, renwuli/disable_te_qwen1.5 for Qwen1.5-14B, PyTorch 2.2. Server manufacturers may vary configurations, yielding different results. Performance may vary based on configuration, software, vLLM version, and the use of the latest drivers and optimizations. MI300-081


Related Blogs
-
What to Expect at AMD Advancing AI 2026
Get a preview of AMD Advancing AI 2026, including key themes, sessions, and innovations shaping the future of AI. Discover how industry leaders are coming together to explore real-world use cases and strategies for scaling AI across the enterprise.
July 14, 2026
-
Local Image and Video Generation on AMD Ryzen™ AI Max+ Processor (Windows) — ROCm Blogs
Run ComfyUI natively on Windows on AMD Ryzen AI Max+ with ROCm 7.2.1—SDXL, Flux, and video workflows on the Radeon 8060S, no WSL.
July 13, 2026
-
Announcing the ROCm Certification Program
Build AI and HPC expertise on AMD Instinctt™ GPUs. Earn the ROCmt™ Certification with hands-on, production-ready skills.
July 13, 2026
-
GEAK Agent-Driven Optimization of the DeepSeekV4 MLA Kernel — ROCm Blogs
GEAK Agent accelerates DeepSeekV4 MLA kernel optimization with Triton and delivers SGLang E2E gains on AMD GPUs.
July 12, 2026
-
ZenDNN 6.0 FP16 Inference and MoE Acceleration
ZenDNN 6.0 takes the next step: FP16 functional support for AMD’s 6th Gen EPYC™ processors, MoE model optimization, and the vLLM compatibility window.
July 10, 2026
-
Fast Image Generation and Editing with SGLang Diffusion on AMD GPUs — ROCm Blogs
Serve and benchmark diffusion models for image generation and editing on AMD Instinct GPUs using SGLang Diffusion on ROCm.
July 09, 2026
-
AMD Instinct™ Network Traffic, Congestion Trends, and Harmonics in Scale-Out Networks for AI Training Clusters — ROCm Blogs
Explore how synchronized GPU collectives create harmonic congestion in AI clusters and the strategies to diagnose and mitigate it.
July 08, 2026
-
Porting High-Performance HIP Kernels to FlyDSL — ROCm Blogs
This blog post shows how to port HIP C++ GPU kernels to FlyDSL, AMD's new Python DSL, matching hand-tuned C++ performance with less code.
July 08, 2026







